数据仓库与模型体系及相关概念
数据仓库与数据库的区别可参考:数据库与数据仓库的区别及关系_数据仓库和数据库-CSDN博客
总之,数据库是为捕获数据而设计,数据仓库是为分析数据而设计
数据仓库集成工具
在一些大厂中,其会有自己的数据仓库集成工具。如京东内部数仓集成工具为数据星图,我们可以通过该工具拿到各领域的模型,字段,实时消息,生产库表等数据。
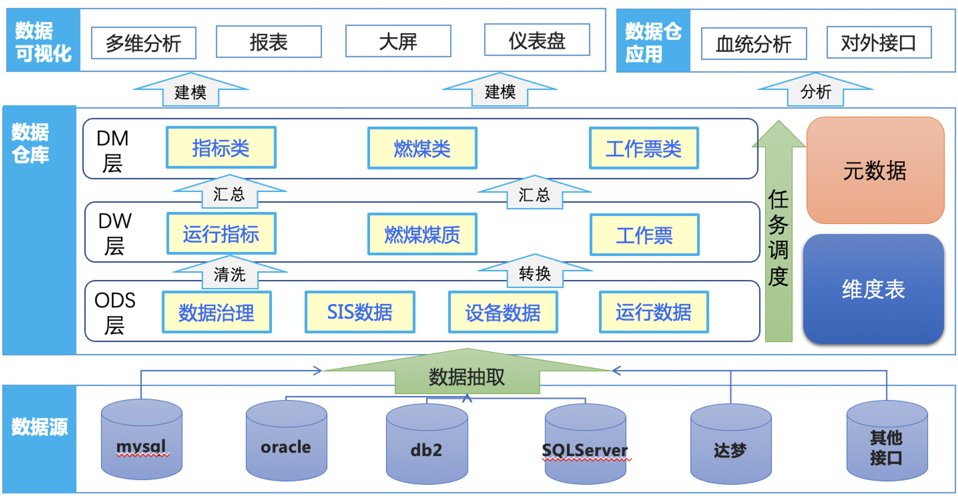
数据仓库架构
下图是一个标准数据仓库架构的示例图,可能不是很准确。
对于我们来讲只需要了解数仓数据提取的步骤:
- 数仓中的数据经数据源提测到一个缓存层(按天分区,大致保存7天数据)一般采用增量抽取策略
- 再由缓冲层提取至基础数据层。一般采用拉链抽取方式。
- 可定义表名以chain结尾的表示为拉链存储形式,不是所有数据都适合拉链更新,像流量这种没有变更概念的数据,比较适合采用增量存储的形式。
- 拉链表存储的数据较多,如何区分最新有效的数据?
答: 用dp=active分区中的数据,该分区标记最新且有效的数据
什么是增量抽取,全量抽取,拉链抽取?请接着往下看!
数据仓库抽取策略
数据仓库中的数据由数据集成平台将源数据库中的表,数据抽取过来。我们需要定义抽取策略,主要抽取策略有全量抽取,增量抽取,拉链抽取这三类。
全量抽取比较好理解每次将源数据库中所有数据全部抽取到数据仓库,会覆盖数据仓库之前的数据。
主要讲下增量抽取,拉拉链抽取二者的区别
- 增量抽取 :增量抽取是指每次只抽取自上次抽取以来源数据库中新增或修改的数据 。通常需要源数据库中存在能够标识数据变化的字段,如时间戳字段(记录数据的创建时间或最后修改时间)或自增的版本号字段等。例如,在一个订单表中,有一个
update_time字段记录订单的最后修改时间,增量抽取时可以通过比较这个时间戳,只抽取update_time大于上次抽取时间的数据。 - 拉链抽取 :拉链抽取不是基于数据的增量变化,而是基于数据的生命周期来记录数据的历史变化。它会在数据仓库中为每一条数据记录维护一个生效时间和失效时间(或截止时间),通过这两个时间字段来标识数据在历史上的有效性。例如,员工的职位信息可能会发生变化,每次变化时,拉链抽取会在数据仓库中插入一条新记录,记录变化后的职位信息,并更新上一条记录的失效时间,同时新记录的生效时间为变化发生的时间,失效时间为无穷大(或一个特定的未来时间)。