1 什么是Spark?
Apache Spark 是一个开源的分布式计算框架,专为处理大规模数据而设计。它提供了高效、通用的集群计算能力,支持内存计算,能够显著提高数据处理和分析的速度。Spark 已经成为大数据处理领域的重要工具,广泛应用于机器学习、图计算、流处理和 SQL 查询等场景。
2 Spark的核心组件
Apache Spark作为一个统一的大数据分析引擎,其架构由多个紧密协作的核心组件构成。
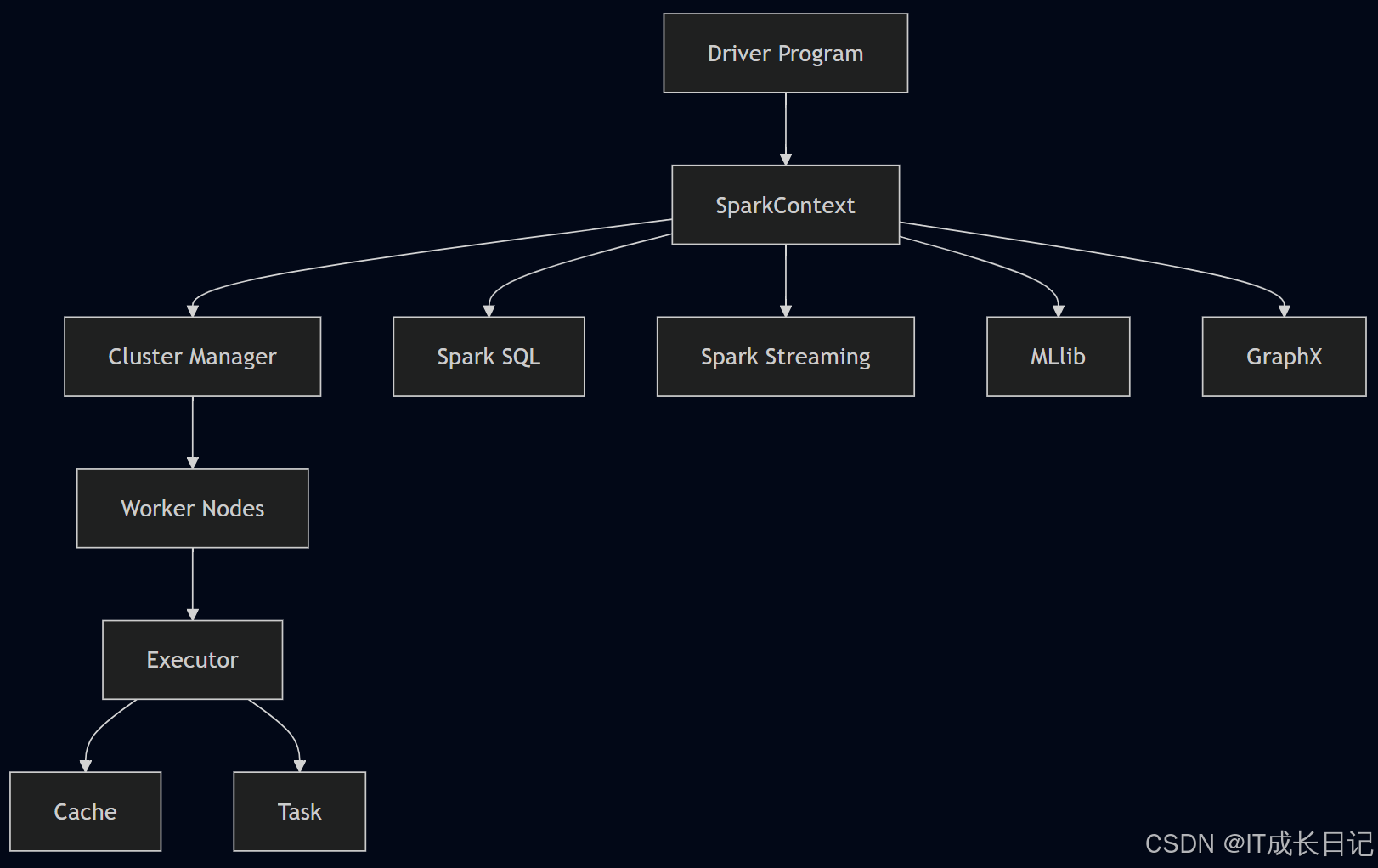
2.1 Spark Core(核心引擎)
基础执行框架:
- 提供任务调度、内存管理、故障恢复等基础功能
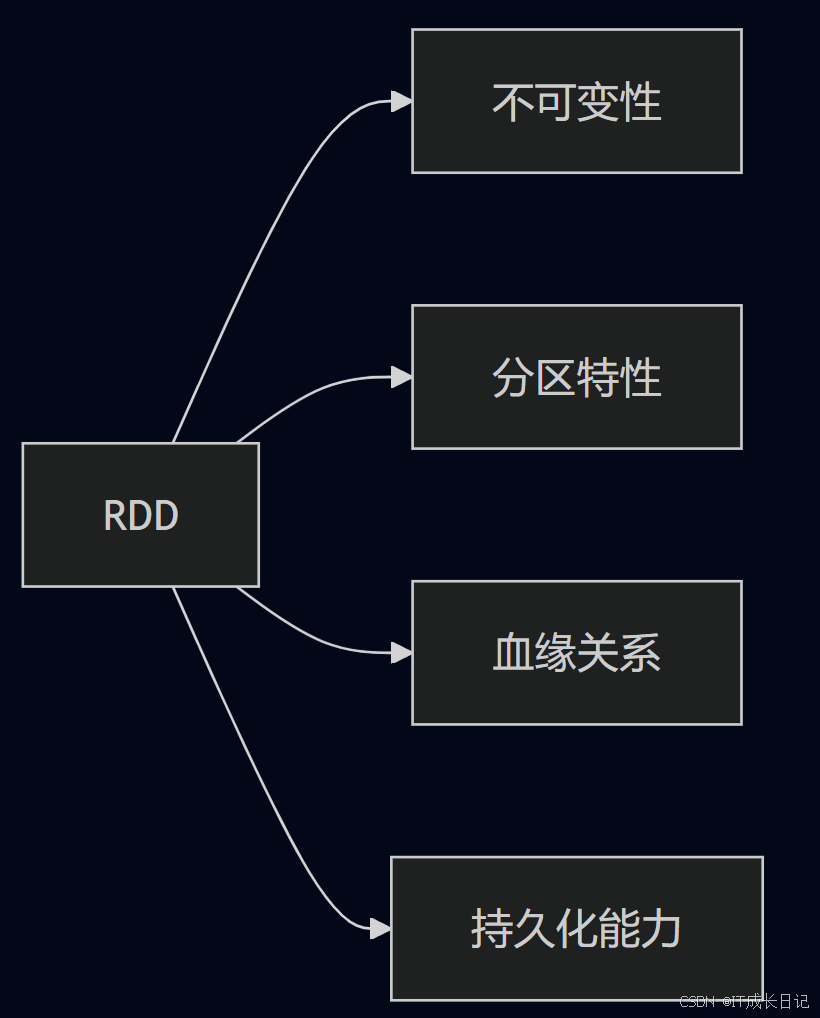
- 包含弹性分布式数据集(RDD)这一基本抽象
- 支持多种资源管理器(Yarn/Mesos/Standalone)
- 关键特性
2.2 Spark SQL
结构化数据处理:
- 支持SQL查询和DataFrame API
- 兼容Hive的HQL语法
- 内置Catalyst优化器:逻辑优化、物理执行计划生成、代码生成
2.3 Spark Streaming
实时流处理:
- 微批处理架构(准实时)
- 支持DStream抽象
- 与Kafka/Flume等消息系统集成
2.4 MLlib(机器学习库)
分布式机器学习:
- 包含50+算法
- 分类/回归
- 聚类
- 协同过滤
- 特征工程工具
- 模型评估方法
2.5 GraphX(图计算)
图处理能力:
- 基于属性图模型
- 实现Pregel API
- 内置常用算法:
- PageRank
- 连通组件
- 三角计数
3 Spark的工作流程

3.1 应用提交阶段
-
触发动作
spark-submit --master yarn --class com.example.MyApp myapp.jar
-
内部过程
- 客户端生成包含如下信息的SparkSubmit请求:
- 应用JAR包路径
- Main类名
- 资源配置参数
- 集群管理器(YARN/Mesos)收到请求
3.2 Driver启动阶段
关键组件:
- SparkContext:整个应用的入口点
- DAGScheduler:将逻辑执行计划转为Stage
-
TaskScheduler:分配Task到Executor
-
内存分配示例
val conf = new SparkConf()
.setAppName("MyApp")
.setMaster("yarn")
.set("spark.executor.memory", "8g")
val sc = new SparkContext(conf)
3.3 Executor分配阶段
资源协商过程:
- Driver向集群管理器申请Executor资源
- 集群管理器在Worker节点上分配Container
- 每个Container启动一个Executor进程
- 典型资源配置
|--------------------------|-----|--------------|
| 参数 | 示例值 | 说明 |
| spark.executor.instances | 10 | Executor数量 |
| spark.executor.cores | 4 | 每个Executor核数 |
| spark.executor.memory | 8g | 每个Executor内存 |
3.4 DAG构建与调度

3.5 Stage划分原理
划分规则:
- 遇到宽依赖(Shuffle操作)就划分Stage
- 窄依赖的操作合并到同一个Stage
常见宽依赖操作:- reduceByKey
- join
- repartition
3.6 Task执行流程
Task生成规则:
- 每个Partition生成一个Task
- 每个Stage生成一组TaskSet
执行时序:- Driver的TaskScheduler发送Task到Executor
- Executor启动线程执行Task
- 通过BlockManager进行数据交换
- 结果返回Driver或写入存储系统
3.7 容错处理机制
故障恢复策略:
- Executor故障:重新调度Task
- Driver故障:需启用检查点(checkpoint)恢复
- 数据丢失:通过RDD血缘(lineage)重新计算
4 Spark的特点与优势
4.1 核心特点
高性能:
- 内存计算:数据优先驻留内存,减少磁盘I/O,相比 Hadoop MapReduce 提速显著,尤其适合迭代计算(如机器学习)
- RDD弹性容错:通过弹性分布式数据集(RDD)实现高效并行处理,兼具容错能力与计算效率
全栈通用:- 多语言支持:提供Scala、Java、Python、R 等接口,适配多样开发需求
- 一体化生态:集成Spark SQL(批处理)、Spark Streaming(流计算)、MLlib(机器学习)、GraphX(图计算),覆盖全场景数据处理
开发友好:- 简洁API:低代码设计降低学习成本,提升开发效率
- 无缝兼容Hadoop:支持HDFS、YARN等组件,便于复用现有大数据架构
高可扩展:- 弹性扩缩容:从GB到PB级数据均可高效处理,适应业务增长
- 活跃社区:开源生态持续迭代,推动技术前沿创新
4.2 技术优势
高性能:
- 内存计算:大幅加速数据处理,适合实时场景(如实时推荐系统)
- 并行处理:高效利用集群资源,提升计算效率
强大的生态系统:
- 多组件支持:
- Spark SQL(结构化数据处理)
- Spark Streaming(实时流处理)
- MLlib(机器学习)
- GraphX(图计算)
- Hadoop 兼容:无缝集成 HDFS、YARN,降低迁移成本
开发高效:
- 简洁 API:易于学习,减少开发复杂度(如用 SQL 替代 MapReduce)
- 交互式分析:支持 Spark Shell,便于快速调试与验证
高容错性:
- RDD 容错:通过谱系信息(lineage)快速恢复数据
- 检查点机制:定期持久化数据,增强可靠性
成本效益:
- 高资源利用率:优化集群资源使用,降低硬件成本
- 开源免费:无软件授权费用,减少企业支出
5 Spark的应用场景
批处理:
- ETL 作业:使用 Spark SQL进行数据抽取、转换和加载
- 日志分析:处理服务器日志,生成报表和可视化结果
实时流处理:- 实时监控:实时处理传感器数据、日志流等,生成实时报表和告警
- 实时推荐:根据用户行为实时生成推荐结果,提高用户体验
机器学习与数据挖掘:- 模型训练:使用MLlib进行模型训练,如分类、回归和聚类等
- 特征工程:处理大规模数据,提取特征,为模型训练做准备
图计算:- 社交网络分析:分析社交网络中的关系等
- 知识图谱:构建和查询知识图谱,支持语义搜索和推理
6 总结
Apache Spark是一个功能强大、性能优越的分布式计算框架,具有速度、通用性、易用性和可扩展性等优势。它支持多种编程接口和丰富的API,适用于批处理、流处理、机器学习和图计算等多种应用场景。通过与 Hadoop生态系统的集成,Spark能够充分利用现有的大数据基础设施,为企业提供高效的数据处理和分析能力。