《Spark大数据开发与应用案例(视频教学版)(大数据技术丛书)》(段海涛,杨忠良,余辉)【摘要 书评 试读】- 京东图书
本节将对RDD的基本概念、特点、分类、使用方法进行详细讲解。RDD作为Spark的核心数据结构,承载着弹性分布式数据集的特性。本节将深入探讨RDD的特点、算子的精细分类以及多样化的创建方法,为Spark数据处理奠定坚实基础。
4.1.1 RDD的特点
RDD(Resilient Distributed Dataset,弹性分布式数据集)是Apache Spark中的一个核心概念,具有以下特点。
(1)不可变性(Immutability):RDD一旦创建,就不能被修改。这种不可变性确保了数据的一致性和容错性。如果需要修改数据,可以创建一个新的RDD。
(2)分布式存储:RDD中的数据是分布式存储的,可以跨多个节点进行存储和处理。这种分布式存储方式使得Spark能够处理大规模数据集。
(3)容错性(Fault Tolerance):由于RDD是不可变的,Spark可以记录RDD的创建过程(即lineage,血统)。当某个RDD的分区丢失时,Spark可以通过重新计算其依赖的RDD来恢复丢失的数据,而无需重新计算整个数据集。
(4)惰性计算(Lazy Evaluation):RDD的操作是惰性的,即只有在实际需要计算结果时(如调用collect()、count()等行动操作)才会执行。这种惰性计算机制使得Spark能够优化执行计划,提高计算效率。
(5)多种操作:RDD支持两种类型的操作,即转换(transformation)和行动(action)。转换操作会返回一个新的RDD,而行动操作会触发计算并返回结果到驱动程序。
(6)自定义分区:RDD允许用户自定义分区策略,以优化数据分布和计算性能。用户可以通过实现Partitioner接口来自定义分区方式。
(7)与存储系统的集成:RDD可以与多种存储系统(如HDFS、S3、Cassandra等)进行集成,方便地从这些存储系统中读取数据和写入数据。
(8)高效的内存计算:RDD支持将数据缓存在内存中,从而加速后续的计算操作。这种内存计算模式使得Spark在处理迭代计算、机器学习等任务时具有显著的性能优势。
(9)灵活性:RDD提供了丰富的API,允许用户以灵活的方式对数据进行处理。用户可以使用高阶函数(如map、filter、reduce等)来定义复杂的计算逻辑。
(10)扩展性:RDD的抽象层次较低,允许开发者根据需要创建自定义的RDD类型,以支持特定的数据处理需求。例如,Spark SQL中的DataFrame和Dataset都是基于RDD构建的更高层次的抽象。
这些特点使得RDD成为处理大规模数据集的强大工具,特别适用于需要高效、容错和灵活数据处理的应用场景。
RDD和RDD之间存在一系列依赖关系(参见图4-1)。RDD调用Transformation后会生成一个新的RDD,子RDD会记录父RDD的依赖关系,包括宽依赖(有shuffle)和窄依赖(没有shuffle)。下一节会对依赖关系中的算子分类进行详细讲解。
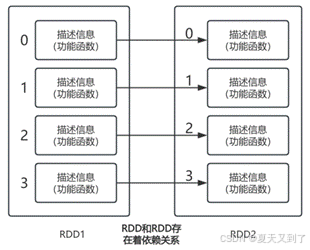
图4-1 RDD的依赖关系
4.1.2 RDD的算子分类
RDD中算子分为两大类,Transformation(即转换算子)和Action(即行动算子)。
- Transformation:即转换算子,调用转换算子会生成一个新的RDD,Transformation是Lazy的,不会触发job执行。
- Action:即行动算子,调用行动算子会触发job执行,本质上是调用了sc.runJob方法,该方法从最后一个RDD,根据其依赖关系,从后往前划分Stage,生成TaskSet。
RDD的算子通过转换和行动两类算子的组合,实现了对分布式数据的复杂处理。转换算子定义了数据的转换逻辑;而行动算子则触发了这些转换逻辑的执行,并产生了最终结果。这种设计使得Spark能够高效地处理大规模数据集。
4.1.3 RDD的创建方法
在Apache Spark中,RDD是一个容错、并行的数据结构,可以让用户在高层次上执行大规模的数据集操作。RDD可以通过多种方式在Spark应用程序中创建,以下介绍一些常见的RDD创建方法。
- 从集合中创建RDD
在Spark的Scala API中,你可以从一个已经存在的Scala集合(如List、Array等)中直接创建RDD。这是通过调用SparkContext的parallelize方法实现的。
// 定义数组
val data = Array(1, 2, 3, 4, 5)
// 创建RDD
val rdd = sc.parallelize(data)这里,sc是SparkContext的实例,data是一个包含整数的数组,rdd是由data转换而来的RDD。
- 从外部文件系统中读取数据创建RDD
Spark提供了多种从外部存储系统(如HDFS、Amazon S3、本地文件系统等)读取数据并创建RDD的方法。这些方法包括textFile(读取文本文件)、sequenceFile(读取Hadoop的SequenceFile文件)、wholeTextFiles(读取整个文件作为键值对,其中键是文件名,值是文件内容)等。
下面这行代码会读取指定HDFS路径下的文本文件,并将文件内容作为RDD中的元素。
// 读取HDFS文件为RDD
val rdd = sc.textFile("hdfs://path/to/textfile.txt")- 从其他RDD转换而来
RDD支持丰富的转换(Transformations)操作,这些操作会返回一个新的RDD。这些转换操作包括map、filter、flatMap、groupByKey等。因此,你可以通过在一个已存在的RDD上应用这些转换操作来创建新的RDD。
// 创建原始RDD
val originalRDD = sc.parallelize(Array(1, 2, 3, 4, 5))
// 映射转换RDD
val transformedRDD = originalRDD.map(x => x * 2)- 使用SparkContext的makeRDD方法
SparkContext的makeRDD方法允许你直接从Scala的并行集合(如ParSeq)或迭代器(Iterator)中创建RDD。这种方法不常用,但是对于从非标准数据源创建RDD特别有用。
// 本地数据集合
data = [1, 2, 3, 4, 5]
// 使用makeRDD方法从本地数据集合创建一个 RDD
rdd = sc.makeRDD(data)- 从数据库读取数据
虽然Spark SQL和DataFrame API通常是处理数据库数据的首选方法,但你也可以通过JDBC等接口从数据库中读取数据并转换为RDD。这通常涉及到使用JdbcRDD(在Spark 1.x版本中可用,但在Spark 2.x及更高版本中可能需要自定义实现或使用DataFrame API)。
下面示例演示Spark通过JDBC调用MySQL。
代码4-1 SparkJDBCReadMySQL.scala
import org.apache.spark.sql.SparkSession
object SparkJDBCReadMySQL {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark = SparkSession.builder()
.appName("Spark JDBC Read MySQL")
.config("spark.master", "local[*]") // 本地模式,使用所有可用核心
.getOrCreate()
// MySQL JDBC URL、用户名和密码,读者需要分局自己的数据库信息修改这些配置
val jdbcUrl = "jdbc:mysql://<hostname>:<port>/<database>"
val jdbcUsername = "<username>"
val jdbcPassword = "<password>"
// JDBC查询,可以根据MySQL 自带的示例数据库。修改下面SQL语句
val jdbcQuery = "(SELECT * FROM your_table) as table_alias" // 通常需要一个别名
// 读取MySQL数据为DataFrame
val df = spark.read
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", jdbcQuery) // 注意:这里使用jdbcQuery而不是直接表名
.option("user", jdbcUsername)
.option("password", jdbcPassword)
.load()
// 显示DataFrame内容
df.show()
// 停止SparkSession
spark.stop()
}
}请读者自行安装MySQL,并运行代码测试一下。RDD的创建通常与SparkContext实例紧密相关,因为大多数创建RDD的方法都是通过SparkContext的实例调用的。
在Spark 2.x及更高版本中,DataFrame和Dataset API提供了更加高级和灵活的数据处理功能,因此在可能的情况下,推荐使用这些API。然而,对于某些特定场景或遗留代码,RDD仍然是一个有用的选项。
