这几道题可以说是有一点难度的,但是掌握方法以后可以说非常简单了;
一、找到字符串中所有字母异位词
题目解析
题目给定了两个字符串
s和p,让我们在s中找到p的异位词的字串,并且返回这些字串的索引**异位词:**简单来说就是字母组成相同,位置不同;就比如
cba是abc的异位词。这里我们要找
s的异位词 ,那我们要找的子串长度一定等于s的长度
算法思路
这里看到这道题要找到子串,我们首先想到的肯定是暴力解法:枚举所有长度和s相等字符串,找到满足条件的字符串然后返回
这里对于枚举字符串,我们可以进行一下优化:
对于暴力解法,固定一个位置
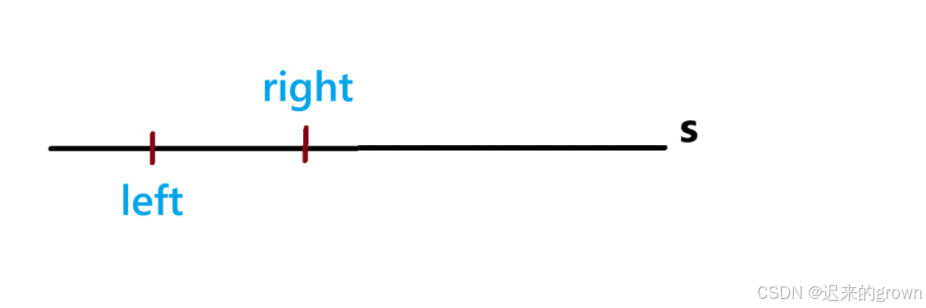
left,让right向后遍历,找到满足条件的子串时(如下图所示:)此时是满足条件的(当前区间
[left , right]的子串是p的异位词) ,那区间[left+1, right]就一定不是满足条件的(异位词要求字符的组成是相同的) ,所以我们就让left++后,就不必让right再从left开始向后遍历,而是继续从right当前的位置向后遍历。这是,
left和right就是一个同向双指针,我们就非常好想到要用滑动窗口来来解决问题了。
知道了这道题,我们要用同向双指针(滑动窗口),
那如何记录区间[left , right]内出现的字符串呢?
这里通过看题目,我们会发现:我们不仅要记录字符的种类,还要记录每一种字符的数量 ,这里就要使用
hash表来记录。
那现在来看如何使用滑动窗口呢?
首先就是
right向后进行遍历,进行入窗口操作。然后就是出窗口,那该什么时候进行出窗口操作呢?又该如何进行出窗口操作呢?
- 什么时候出窗口?:我们通过看题可以发现,我们要找的子串长度肯定等于字符串
s的长度 ,所以我们出窗口操作要在[left , right]长度大于s的长度之后再出窗口。- 那如何出窗口呢?:这里出窗口操作很简单,就是将
left位置的字符的数量-1即可。那什么时候更新结果呢?
更新结果,那肯定是满足条件的时候去更新,要想满足条件,区间
[left , right]长度肯定要等于p的长度且区间内出现字符的种类和数量要和p相等。(那这里我们也要使用hash来记录p字符串中出现字符的种类和数量)。
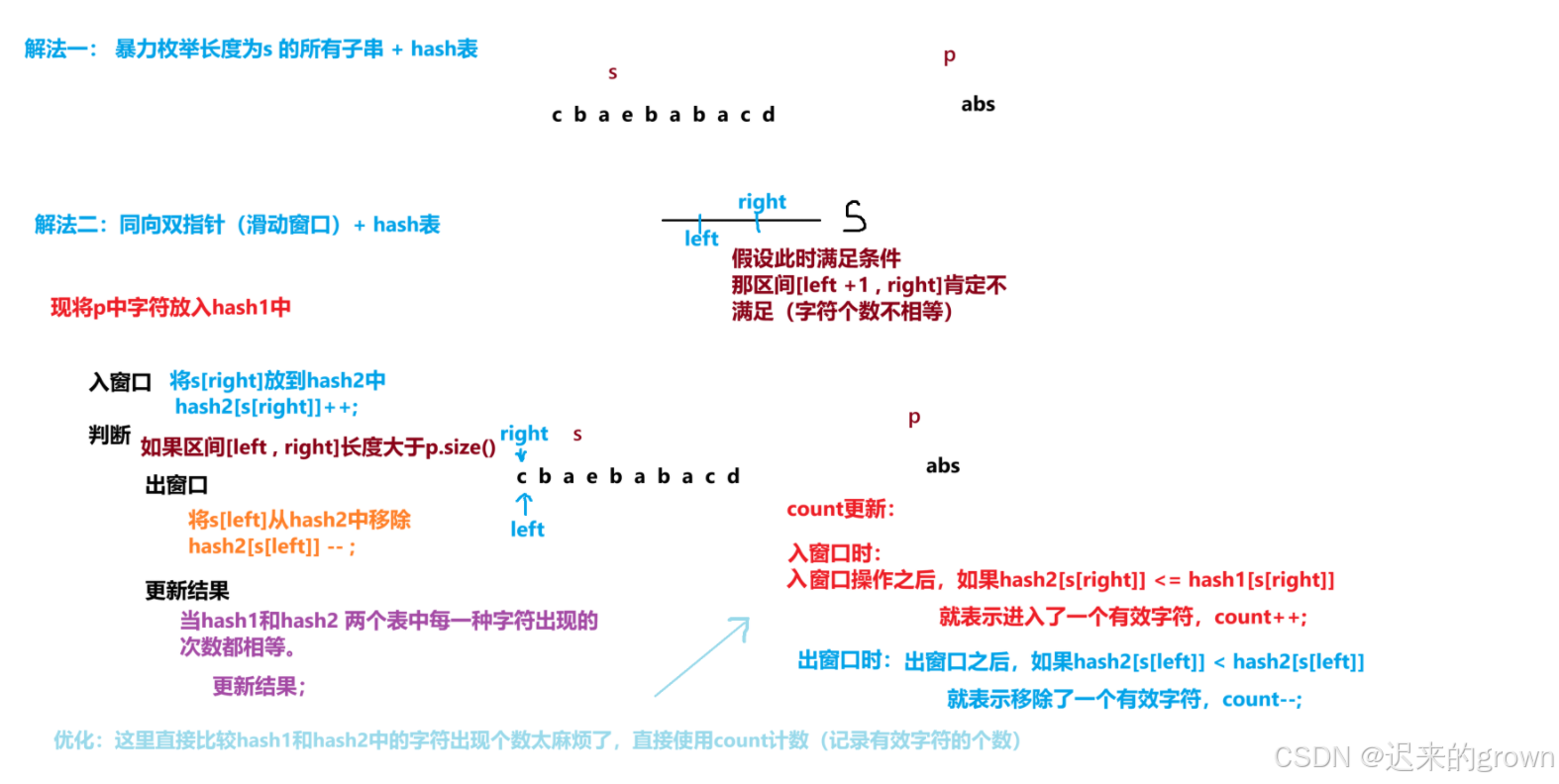
通过上述分析,我们要使用两个hash表来记录p和区间[left , right]出现字符的种类和数量。
这里我们思考一个问题:如何判断两个hash表中字符种类和数量是否相等?
看到这里可能会疑惑,直接去遍历两个
hash表,判断每一个字符出现的次数是否相等不就好了;遍历
hash表去判断每一个字符是否相等确实可以,但未免有些太麻烦了,有没有更加简单又好理解的方法?有的兄弟有的 ,我们不想要使用
hash表去比较,那我们可以使用一个count来计数;(count记录的是有效字符的个数)当区间长度等于
p的长度且count等于p的长度,那当前区间就是p的子串;我们只需要在入窗口和出窗口时,进行一下
count的更新即可
什么意思呢?
我们使用
count来记录区间[left , right]内有效字符的个数;那在如窗口和出窗口操作时如何更新呢?
在入窗口时: 我们将
right位置字符放入hash2后,如果hash2[s[right]]<=hash1[s[right]],那就说明right位置的字符就是有效字符,我们就让count++;在出窗口时: 我们将
left位置字符移除hash2,如果hash2[s[left]]<hash1[s[left]]时,那就说明left位置的字符是有效字符,我们就让count--。
那现在我们大体思路就理清楚了,现在来看整体的过程
现将
p中字符放入hash1;
- 入窗口:将
right位置的字符放入hash2;如果hash2[s[right]] <= hash1[s[right]],那就让count++;- 出窗口:当区间长度大于
p的长度时,进行出窗口操作;将left位置的字符移出hash2(让hash[s[left]]--即可),如果hash2[s[left] < hash1[s[left]],那就让count--;- 更新结果:因为我们会一直维持取长度,让区间长度等于
p的长度,所以只需要判断count == p.size()即可,相等时就更新结果。
代码实现
cpp
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int hash1[26] = {0};
int hash2[26] = {0};
for (auto& e : p)
hash1[e - 'a']++;
vector<int> ret;
int left = 0, right = 0, count = 0;
while (right < s.size()) {
// 进窗口
char in = s[right++];
hash2[in - 'a']++;
if (hash2[in - 'a'] <= hash1[in - 'a'])
count++;
// 出窗口
if (right - left > p.size()) {
char out = s[left++];
hash2[out - 'a']--;
if (hash2[out - 'a'] < hash1[out - 'a'])
count--;
}
// 更新结果
if (count == p.size()) {
ret.push_back(left);
}
}
return ret;
}
};二、串联所有单词的子串
题目解析

对于这道题,不要被它的难度吓到了啊;
题目给我们一个字符串
s和一个字符串数组words,其中words中每一个字符串的长度都是相同的(这个非常重要)。让我们在
s中找串联子串(words中所有字符串以任意的顺序排列),最后要返回所有串联子串的索引。
算法思路
这里如果我们直接来看这一道题,难入登天啊,这该咋去找啊?
这里大家可以先去看一下上面那一道找
异位词的题目 ,看过以后,你会发现一个问题,上面要找的是一个字符串的异位词,那我们这里是不是可以理解成找一个字符数组words的异位字符串。(把words中每一个字符串当成一个整体)就比如
words字符数组是["foo" , "bar"],那"foobar"和"barrfoo"就是它的异位字符串(按某种顺序排列)。
有了上述的理解,那这道题就简单了许多,但还是存在问题;
words中的字符串长度都是相等的,假设都等于len;我们把
words中的每一个字符串当成一整体,那我们遍历s的时候,应该如何去划分呢?
我们可以从0、1、2、3...... len-1位置开始,后面len个字符作为一个字符串(因为从len位置开始和从0位置开始,这样划分是一样的),那我们就一种划分,进行len次滑动窗口操作,就将所有的情况都计算了在内。
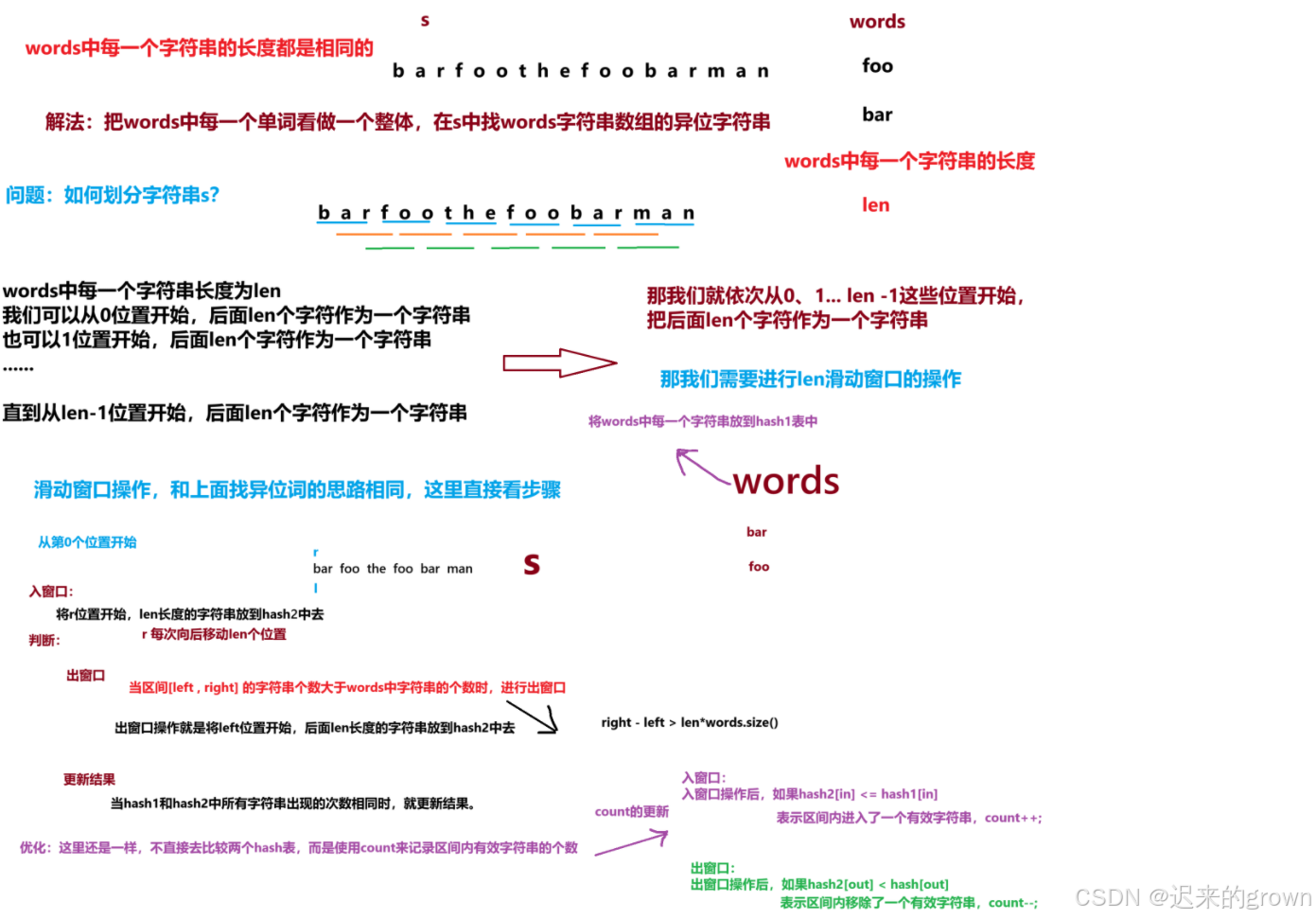
大致思路如上图所示,这里就不在重复了,直接来看代码。
代码实现
cpp
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
unordered_map<string, int> hash1;
for (auto& e : words)
hash1[e]++;
int n = words.size();
int len = words[0].size();
vector<int> ret;
for (int i = 0; i < len; i++) {
int left = i, right = i;
unordered_map<string, int> hash2;
int count = 0;
while (right < s.size()) {
// 进窗口
string in = s.substr(right, len);
hash2[in]++;
right += len;
if (hash1.count(in) && hash2[in] <= hash1[in])
count++;
// 出窗口
if (right - left > n * len) {
string out = s.substr(left, len);
hash2[out]--;
left += len;
if (hash1.count(out) && hash2[out] < hash1[out])
count--;
}
if (count == n)
ret.push_back(left);
}
}
return ret;
}
};三、最小覆盖子串
题目解析
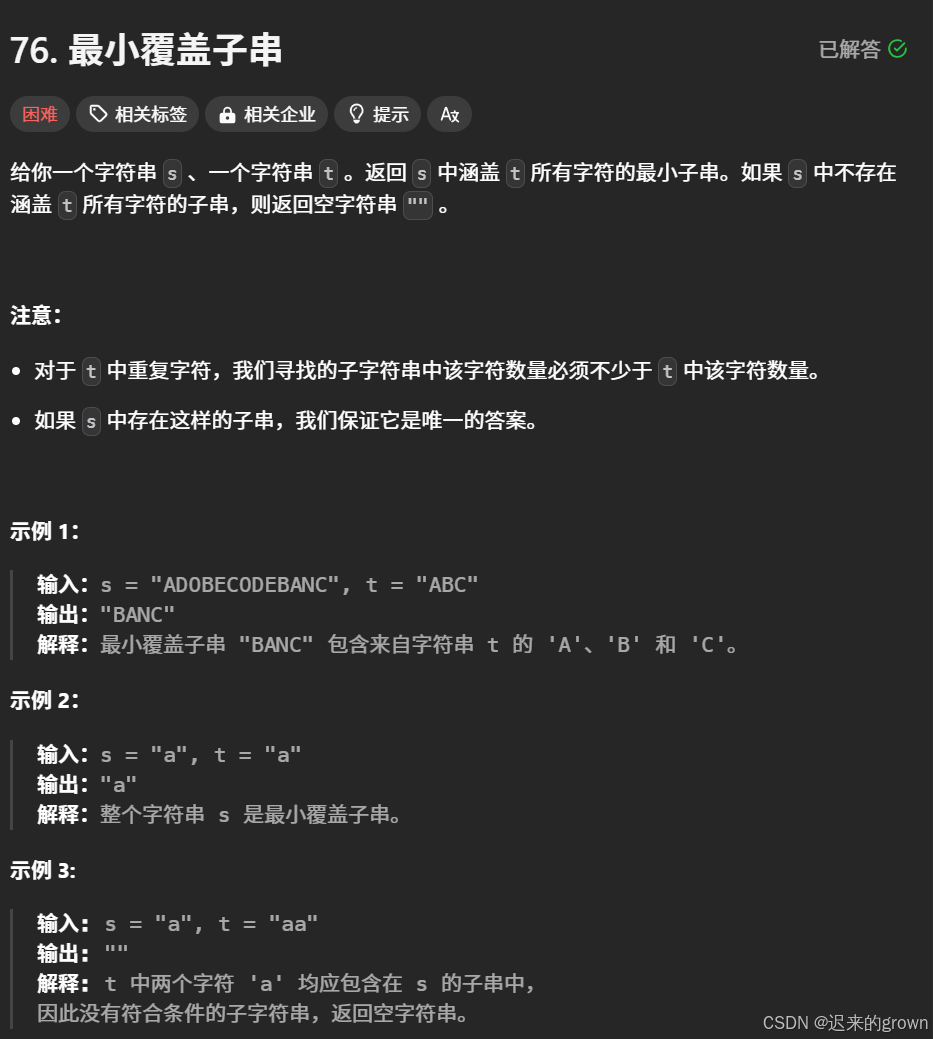
题目给我们字符串
s和字符串t,让我们在s中找到一个子串,这个子串要包含t串中的所有字符;然后让我们找到满足条件并且长度最小的子串并返回,如果不存在满足条件的子串,那就返回
""。
算法思路
这道题,整体思路呢还是和上面类似;
对于暴力解法,就是依次从每一个位置开始找满足条件的最短子串,然后返回长度最小的字串即可。
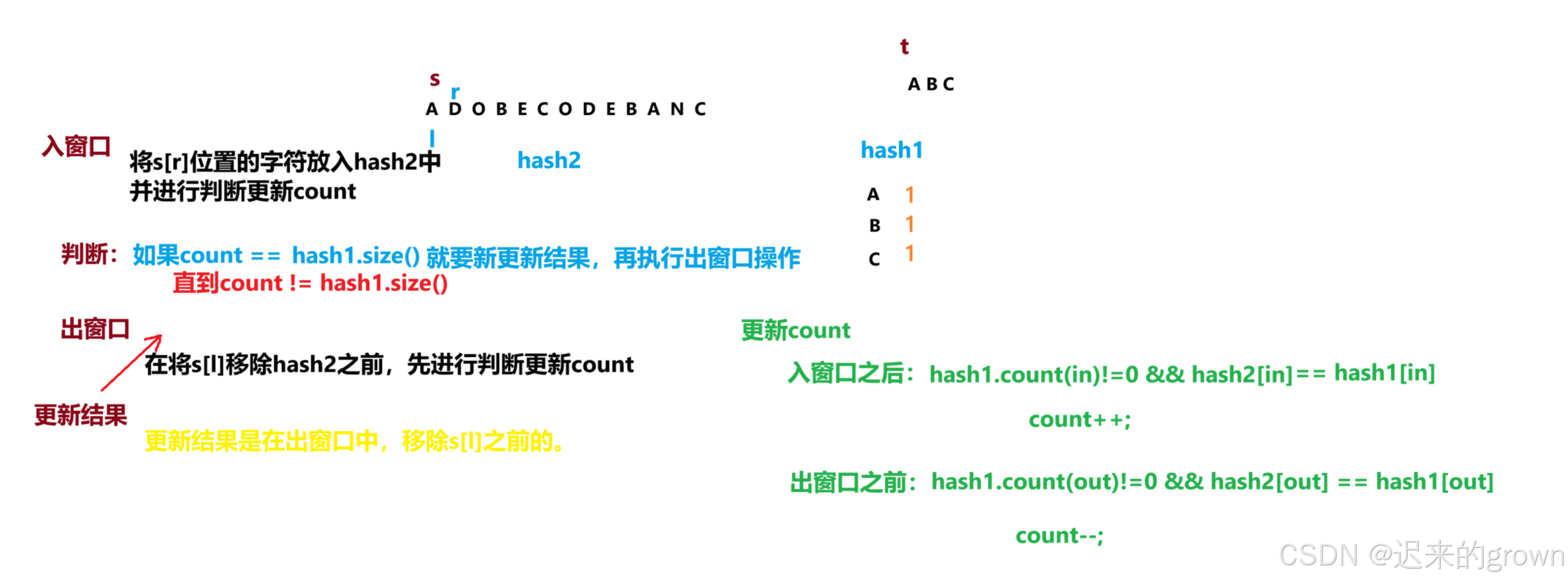
解法:滑动窗口+hash统计
首先,我们要先将
t字符串中所有字符出现的次数统计下来;放到hash1中。然后我们这里依旧是使用
count记录有效字符的种类;但是我们这里更新
count和上面题目中不一样:
- 入窗口时:在如窗口之后,进行判断如果
hash2[in] == hash1[in],则表示入的这个字符是一个有效字符,count++;- 出窗口时:在出窗口操作之前,进行判断,如果
hash2[out] == hash1[out],表示我们要出的这个字符是有效字符,count--。简单来说就是当我们入窗口操作之后,
hash2[in] == hash1[in]这就说明我们入完这一个字符之后,区间内这个字符出现的次数和t中这个字符出现的次数相等,就表示区间内有效字符的种类增加了一个。在入窗口操作之前,
hash2[out] == hash1[out]就说明此时区间内这字符出现的次数和t中这个字符出现的次数不相等了,我们出完这个字符之后就不相等了;就让区间内有效字符的数量减少了一个。
- 入窗口:将
right位置的字符放入hash2中,然后进行更新count的操作。- 出窗口:当
count == hash1.size()时,表示当前区间是覆盖了t的,此时是满足条件的,我们就要进行更新结果;然后在出窗口操作之前更新count,再执行出窗口操作。- 更新结果:据上面描述,更新结果是在出窗口操作之前的。
代码实现
这里实现代码时,有一个细节,就是我们使用unordered_map,它的[]是可以进行插入操作的 ,我们在使用[]之前(hash1[in]和hash1[out]),先进行判断,如果hash1中存在再进行次数的判断。
cpp
class Solution {
public:
string minWindow(string s, string t) {
unordered_map<char, int> hash1;
unordered_map<char, int> hash2;
for (auto& e : t)
hash1[e]++;
int ret = -1, len = s.size() + 1;
int left = 0, right = 0, count = 0;
while (right < s.size()) {
char in = s[right++];
hash2[in]++;
if (hash1.count(in) && hash2[in] == hash1[in])
count++;
while (count == hash1.size()) {
// 更新结果
if (right - left < len) {
ret = left;
len = right - left;
}
char out = s[left++];
if (hash1.count(out) && hash2[out] == hash1[out])
count--;
hash2[out]--;
}
}
if (ret == -1)
return "";
else
return s.substr(ret, len);
}
};到这里,滑动窗口算法思路的学习就结束了,简单总结:
滑动窗口这一思想,主要应用于我们找满足条件的子串或者子数组
思路很简单,最主要的还是我们需要通过分析,通过对暴力枚举的不断优化,来得出我们滑动窗口这一思路;
到这里本篇文章内容就结束了
感谢各位的支持
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=2oul0hvapjsws