语音识别part1

这是一篇名为 "Speech Recognition is Difficult?"(语音识别很难吗? )的文章。作者是 J.R. Pierce,来自贝尔电话实验室(Bell Telephone Laboratories, Inc.) 。文中提到语音识别虽有吸引力,但仅具备某些条件是不够的。还将其吸引力类比为水变汽油、从海水中提取黄金、治愈癌症、登月等极具吸引力的设想 ,暗示语音识别虽诱人但并非易事。
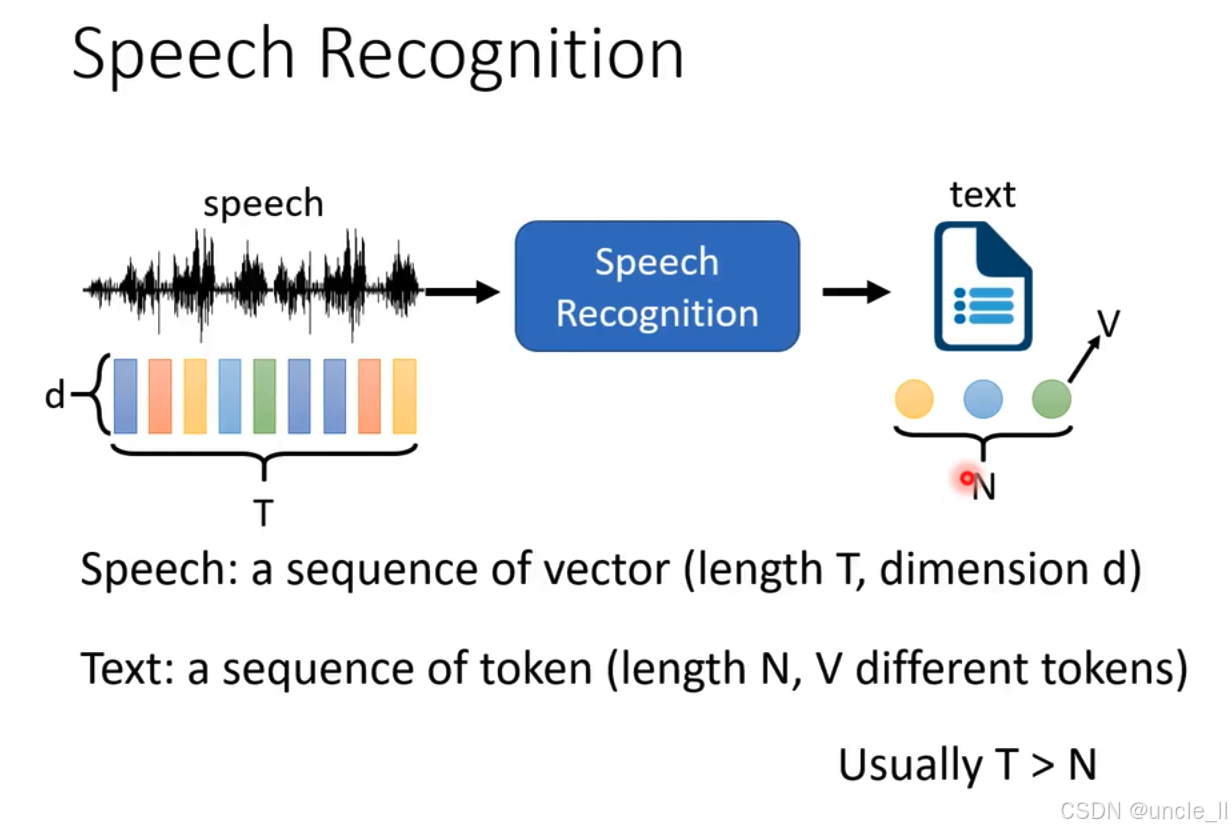
语音识别(Speech Recognition)的基本原理:
- 输入:左侧的波形代表语音(speech) ,语音被表示为一个向量序列,长度为 T,维度为 d 。
- 处理过程:语音信号进入 "Speech Recognition" 模块,该模块对语音进行处理。
- 输出:右侧的文档图标代表文本(text) ,文本是一个标记(token)序列,长度为 N ,有 V 种不同的标记。
- 补充说明:图中还指出通常语音向量序列的长度 T 大于文本标记序列的长度 N 。
介绍与语音识别相关的 "Token"(标记)概念,具体涉及音素(Phoneme)和字素(Grapheme) :
音素(Phoneme)
- 定义:声音的最小单位。
- 示例:图中展示了 "one punch man" 的音素表示分别为 "W AH N" "P AH N CH" "M AE N" 。右上角黄色框是一个词汇表(Lexicon)示例,呈现了单词到音素的映射,如 "cat" 对应 "K AE T" 、"good" 对应 "G UH D" 等 。
字素(Grapheme)
- 定义:书写系统的最小单位。
- 英文示例:以 "one_punch_man" 为例,其长度 N = 13 ,理论上不同字素数量 V 基于 26 个英文字母,再加上空格等可能的字符 。
- 中文示例:给出 "一 拳 超 人" ,长度 N = 4 ,不同字素数量 V 约 4000 ,并指出中文书写系统不需要空格来分隔字词 。
"lexicon free" 表示相关系统或方法不依赖预先设定的词汇表来进行处理,比如某些语音识别技术尝试直接对语音信号进行分析转换,不借助传统词汇表的辅助,以适应更灵活、未知的语言场景 。
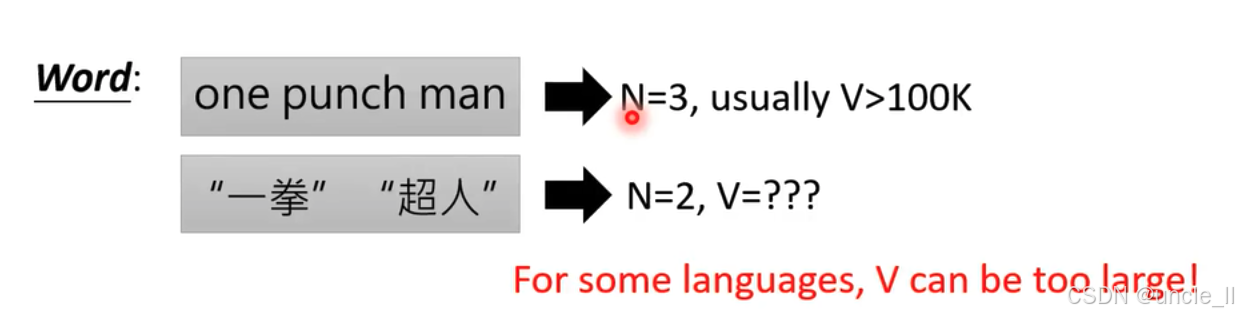
- 英文示例:"one punch man" 被视为一个由 3 个单词组成的序列(N = 3 ) ,一般情况下,英语中不同单词数量 V 通常大于 10 万(V > 100K ) 。
- 中文示例:"一拳超人" 是 2 个词组成的序列(N = 2 ) ,但具体不同字词数量 V 无法明确给出(V = ??? ) 。
- 对于某些语言来说,V(不同字词数量)可能会非常大,这在语音识别、自然语言处理等任务中,会给模型处理带来挑战 。

耳其语作为黏着语(Agglutinative language)的特点: - 信息来源:标明信息来自 "http://tkturkey.com/(土女時代)" 。
- 单词演变示例:以 "Müvaffak"(成功的 )为例,展示通过添加词缀进行词性和词义变化。如 "Müvaffakiyet" 转为名词;"Müvaffakiyetsiz" (添加 "siz" )变为 "不成功" ;"Müvaffakiyetsizleş"(添加 "leş" )是 "變得不成功" ;"Müvaffakiyetsizleştir" (添加 "ştir" )是 "使變得不成功" 。
- 超长单词展示:给出一个长达 70 个字符的单词 "Müvaffakiyetsizleştiricileştiriveremeyebileceklerimizdenmişsinizcesine" ,并附有中文翻译 "如果你是我們當中不容易變成不成功者的其中一個" ,体现黏着语通过不断添加词缀构成复杂长词的特性。

词素(Morpheme):
- 定义: 指出词素是最小的有意义的语言单位,其规模小于单词(word) ,大于字素(grapheme )。
- 示例: 以 "unbreakable" 为例,可拆分为 "un"(表示否定 )、"break"(打破 )、"able"(能够...... 的 ) 三个词素。以 "rekillable" 为例,可拆分为 "re"(表示重复 )、"kill"(杀死 )、"able"(能够...... 的 )三个词素 。
- 确定词素的角度可以是语言学(linguistic )层面或统计学(statistic )层面
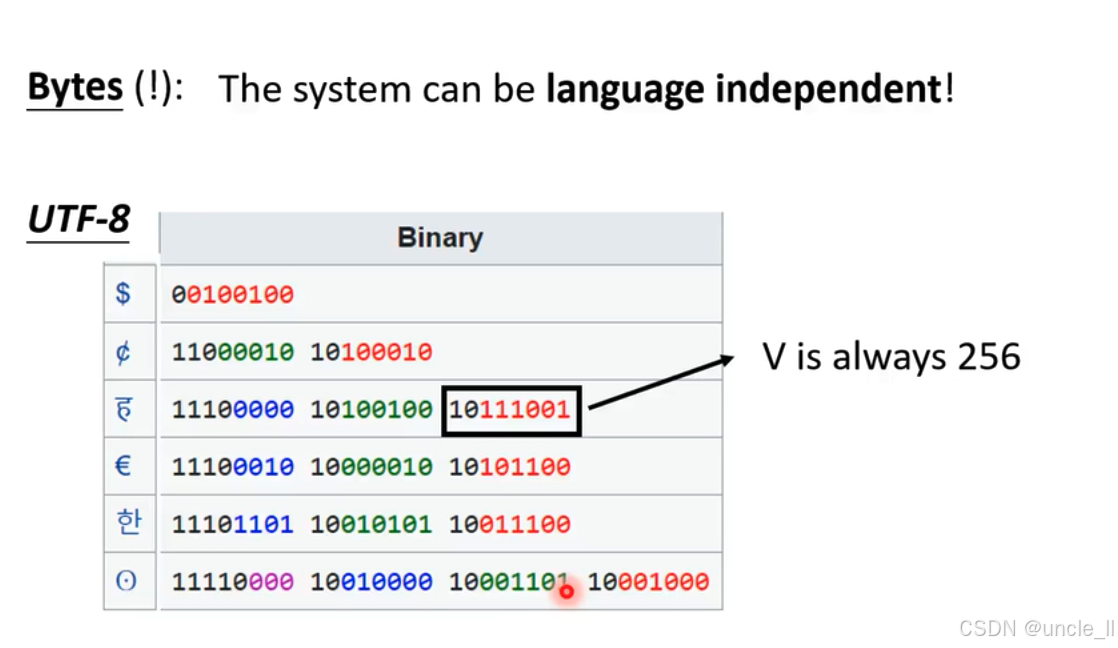
字节(Bytes)在实现语言无关性系统方面的作用,采用 UTF - 8 编码方式: - 标题 "Bytes (!): The system can be language independent!" 表明通过字节处理,系统能够实现语言无关性 。
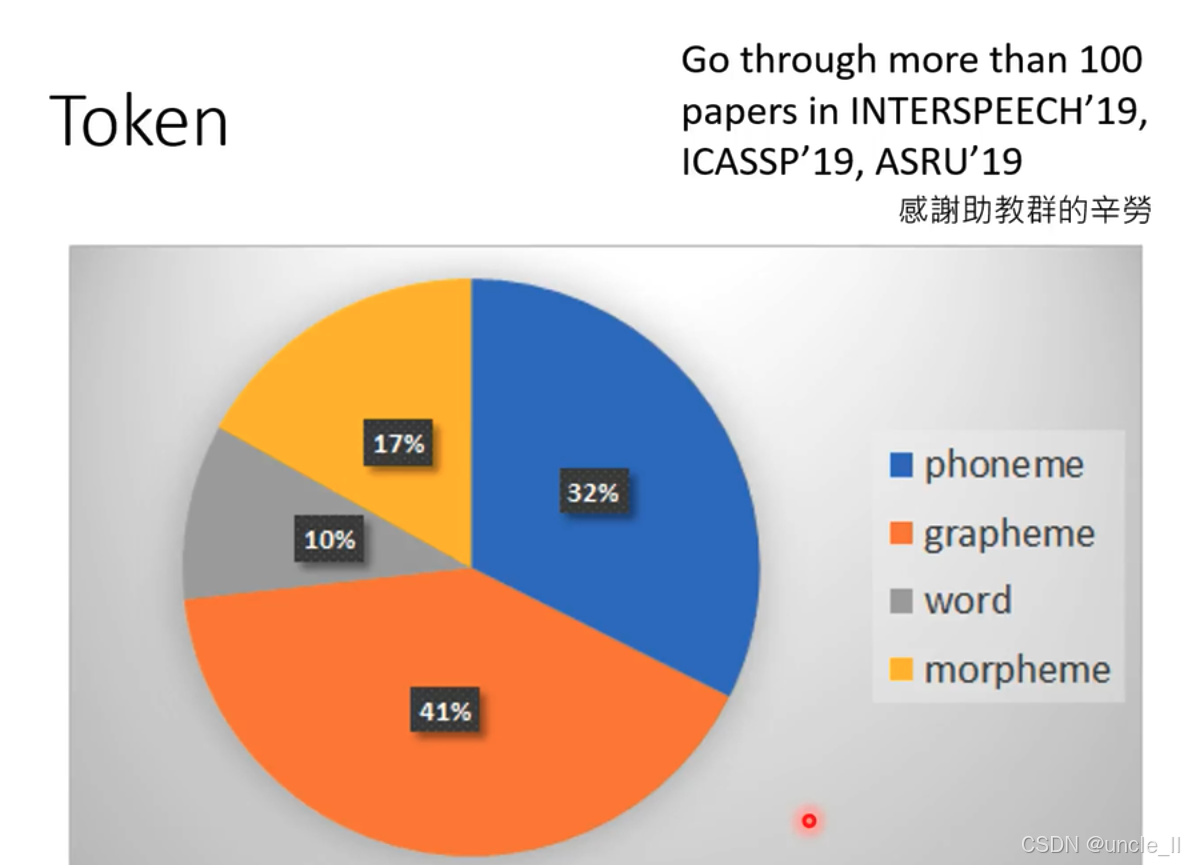
数据来源于对 INTERSPEECH'19、ICASSP'19、ASRU'19 这三个会议超 100 篇论文的调研 ,并感谢助教群的辛苦工作。 图中不同颜色代表不同类型的 Token:
- 蓝色(phoneme,音素):占比 32% ,音素是声音的最小单位。
- 橙色(grapheme,字素):占比 41% ,字素是书写系统的最小单位。
- 灰色(word,单词):占比 10% 。
- 黄色(morpheme,词素):占比 17% ,词素是最小的有意义的语言单位。 该图直观呈现了不同类型 Token 在相关论文研究中的占比情况 。
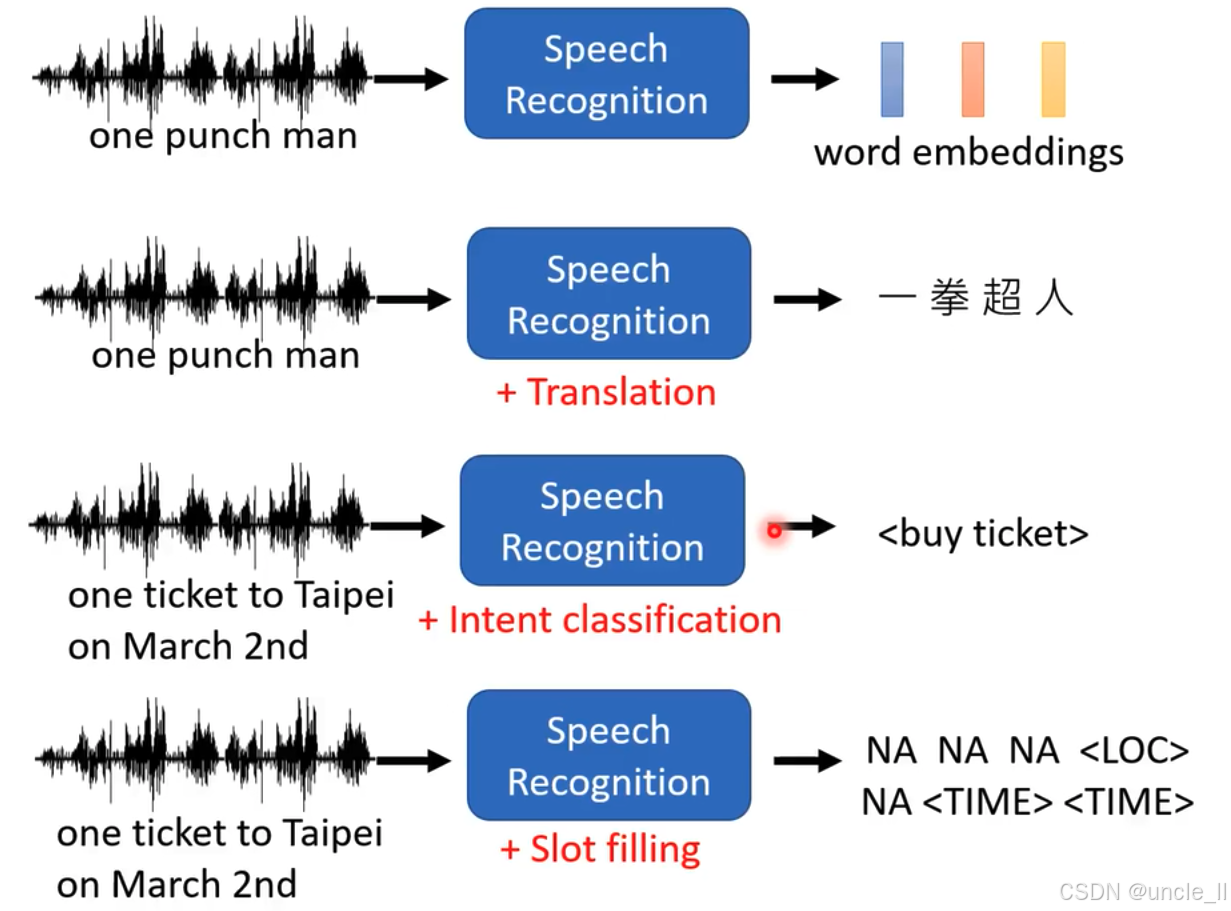
语音识别(Speech Recognition)在不同应用场景下的处理流程:
生成词嵌入(word embeddings)
- 输入语音"one punch man" ,经过语音识别模块,输出为"word embeddings" ,即把语音转换为词的向量表示,用于进一步的自然语言处理任务 。
语音识别加翻译(Translation)
- 同样输入"one punch man" ,经过语音识别后,再进行翻译操作,最终输出为中文"一拳超人" ,体现语音识别与翻译结合的应用 。
语音识别加意图分类(Intent classification)
- 输入语音"one ticket to Taipei on March 2nd" ,经语音识别后,通过意图分类判断用户意图,输出为"" ,表明识别出用户有购票意图 。
语音识别加槽位填充(Slot filling)
- 输入"one ticket to Taipei on March 2nd" ,经语音识别后进行槽位填充操作,输出为"NA NA NA NA " ,将语音中的地点、时间等信息填充到对应的槽位中 。

语音信号的声学特征(Acoustic Feature)
语音波形与帧
- 图中展示了一段语音的波形。语音处理常将其分割成帧,图中红色框出时长25ms的片段,在16KHz采样率下对应400个采样点 。
- 标注出帧移为10ms ,意味着每10ms移动一次窗口截取语音帧。由此可知,1秒的语音会被划分为100帧(1s = 1000ms,1000ms÷10ms = 100 ) 。
声学特征
- 帧(frame):代表语音信号被划分后的基本单元。
- 特征维度:介绍了两种常用的声学特征,39维的梅尔频率倒谱系数(MFCC) ,以及80维的滤波器组输出(filter bank output) 。右上角彩色方块表示声学特征序列,长度为T,维度为d ,是语音信号处理后的特征表示形式 。 这张图主要阐述语音信号如何从时域波形转换为便于后续语音识别等任务处理的声学特征 。
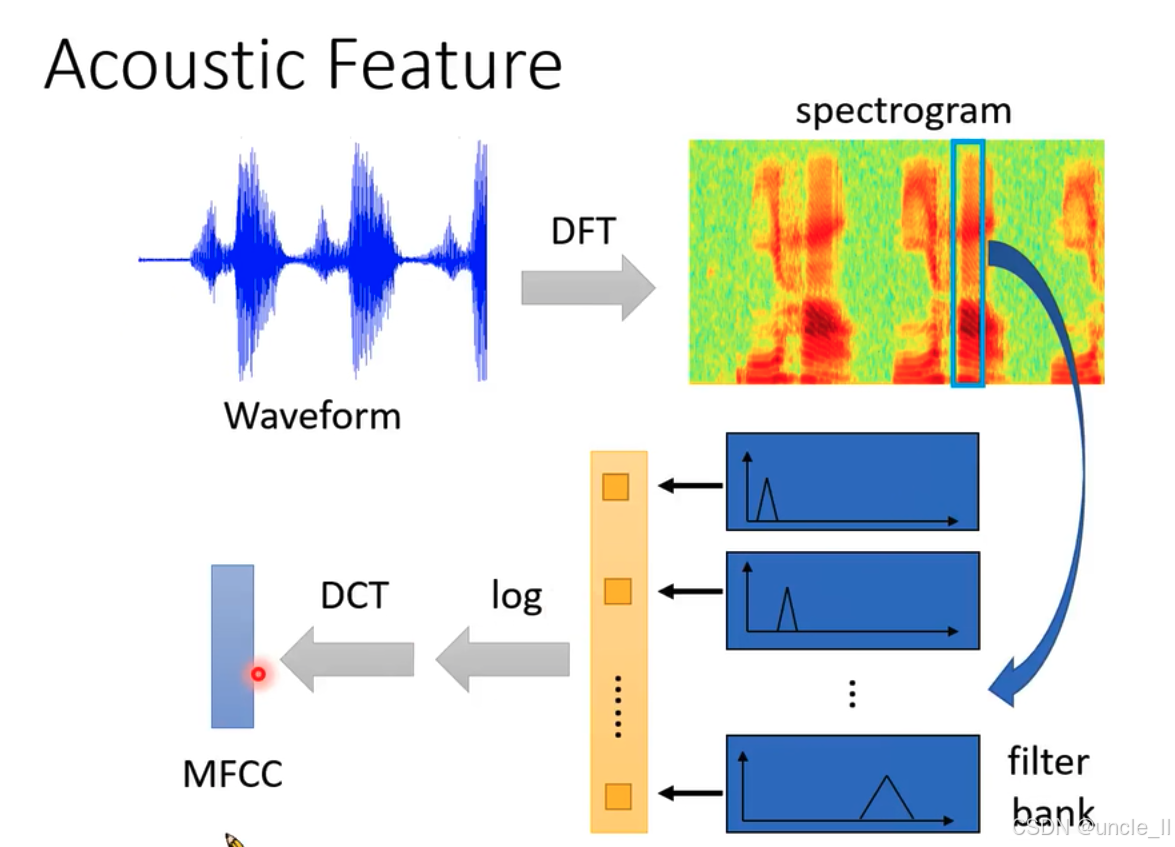
这张图展示了从语音波形(Waveform)到梅尔频率倒谱系数(MFCC)这一声学特征提取的过程:
从波形到时频谱图
- 左侧的蓝色波形代表语音信号的原始时域波形。通过离散傅里叶变换(DFT) ,将时域的语音信号转换到频域,得到右侧的时频谱图(spectrogram) ,呈现语音信号在不同时间和频率上的能量分布 。
梅尔频率倒谱系数提取
- 时频谱图经过滤波器组(filter bank)处理,滤波器组由多个三角形滤波器组成,对频域信号进行滤波 。
- 滤波后的信号取对数(log)操作,再通过离散余弦变换(DCT) ,最终得到梅尔频率倒谱系数(MFCC) 。MFCC是语音识别中常用的声学特征,能够有效表征语音信号的特性 。 图中清晰呈现了语音信号从原始波形到MFCC特征提取的关键步骤 。

关于声学特征(Acoustic Feature)使用占比的饼状图 。数据源于对 INTERSPEECH'19、ICASSP'19、ASRU'19 三个会议超 100 篇论文的调研。 图中不同颜色代表不同类型的声学特征及其占比:
- 深蓝色(filter bank output,滤波器组输出):占比 75% ,是使用最广泛的声学特征。
- 橙色(MFCC,梅尔频率倒谱系数):占比 18% 。
- 灰色(spectrogram,频谱图):占比 4% 。
- 黄色(waveform,波形):占比 2% 。
- 浅蓝色(other,其他):占比 1% 。
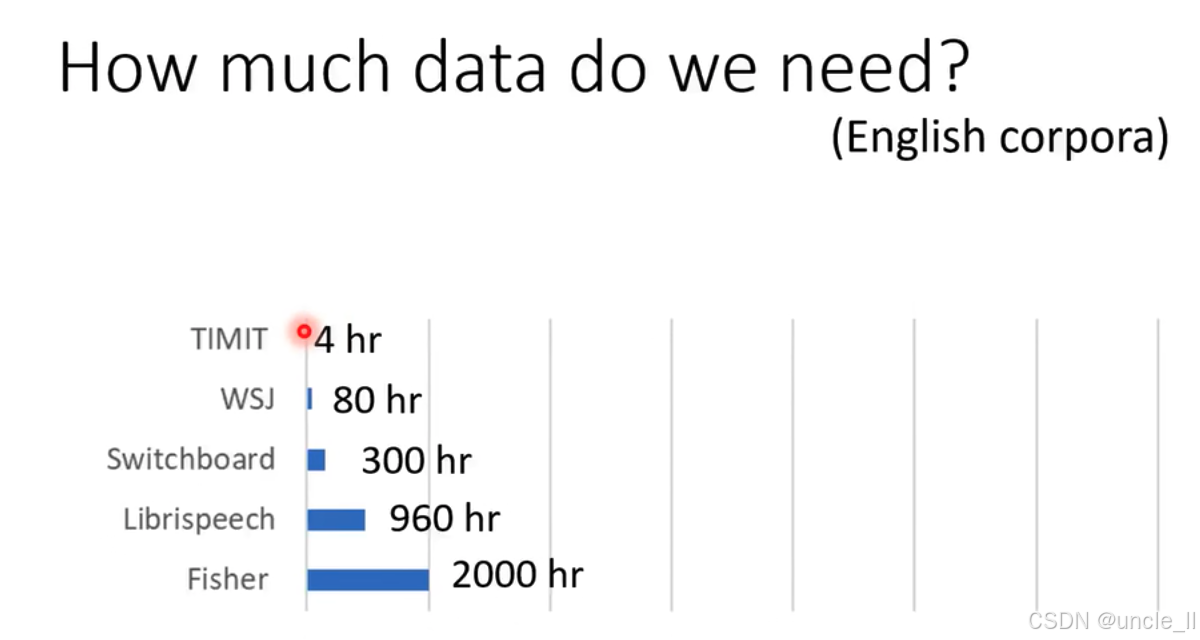
图中展示了几种常见英语语音数据集及其数据量:
- TIMIT:数据量为4小时,是相对较小的数据集 。
- WSJ(Wall Street Journal):数据量为80小时 。
- Switchboard:数据量为300小时 。
- Librispeech:数据量为960小时 。
- Fisher:数据量最大,为2000小时 。
将cv的数据集转换成nlp数据集的情况下,是多大:

对于大公司的训练资料而言,都超过了1万小时。

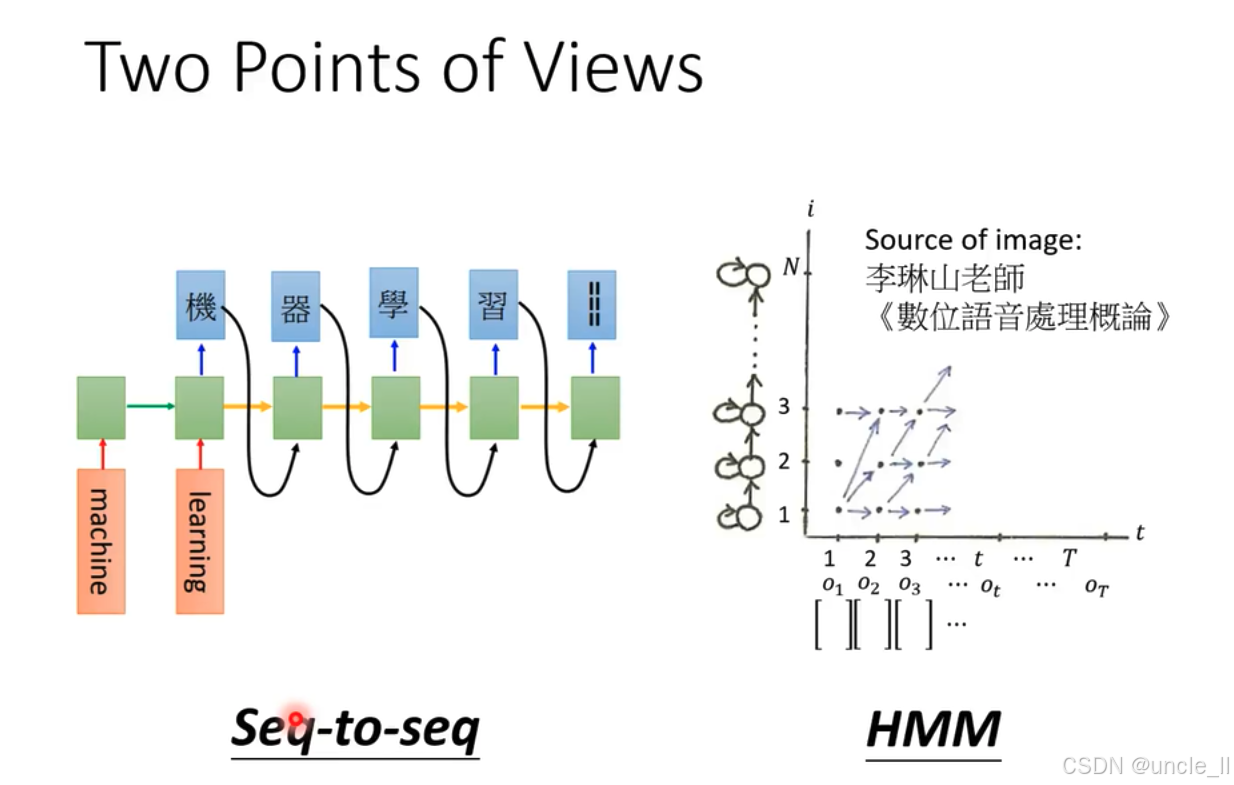
语音处理中的两种观点,分别是序列到序列(Seq - to - seq)模型和隐马尔可夫模型(HMM) :
序列到序列(Seq - to - seq)模型
- 左侧部分展示了Seq - to - seq模型结构。底部橙色的"machine"和"learning"通过箭头指向绿色模块,代表机器学习相关操作。绿色模块之间通过橙色箭头依次连接,体现数据的序列处理过程,每个绿色模块又通过黑色箭头与上方蓝色模块相连,蓝色模块内有汉字"機器學習" ,表示模型对输入序列进行处理并输出相应序列 。
隐马尔可夫模型(HMM)
- 右侧部分展示了HMM。横轴t代表时间,从1到T ,纵轴i从1到N ,表示状态。图中有多个状态节点,用圆圈表示,节点间有箭头连接,表示状态转移。下方的 o 1 o_1 o1到 o T o_T oT表示在不同时间点的观测值。图像来源标注为李琳山老师的《數位語音處理概論》 。

列出了几种语音识别领域的模型:
Listen, Attend, and Spell (LAS)
- 由Chorowski等人在NIPS'15(神经信息处理系统大会,2015年 )上提出。该模型结合注意力机制,使模型在处理语音时能聚焦关键部分,提升识别效果 。
Connectionist Temporal Classification (CTC)
- 由Graves等人在ICML'06(国际机器学习会议,2006年 )上提出。用于解决语音序列和文本序列难以精准对齐的问题,允许模型直接处理未对齐的语音数据 。
RNN Transducer (RNN-T)
- 由Graves在ICML workshop'12(国际机器学习会议研讨会,2012年 )上提出。结合循环神经网络(RNN) ,可有效处理语音的时序信息,在语音识别任务中广泛应用 。
Neural Transducer
- 由Jaitly等人在NIPS'16(神经信息处理系统大会,2016年 )上提出。属于端到端的语音识别模型,旨在更高效地将语音转换为文本 。
Monotonic Chunkwise Attention (MoChA)
- 由Chiu等人在ICLR'18(国际学习表征会议,2018年 )上提出。基于注意力机制,以分块方式处理语音数据,提高模型处理效率和识别准确性 。 幻灯片为后续对这些模型的详细讲解做铺垫 。
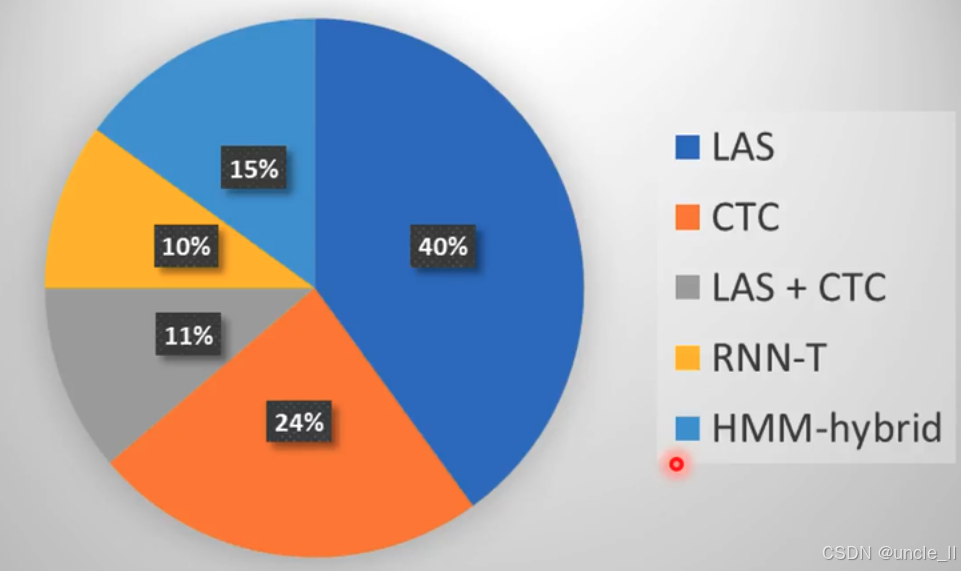
这是一张关于语音识别模型使用占比的饼状图 。数据来源于对INTERSPEECH'19、ICASSP'19、ASRU'19三个会议超100篇论文的调研。图中不同颜色代表不同的语音识别模型及其占比:
- 深蓝色(LAS):占比40% ,是使用最广泛的模型之一。
- 橙色(CTC):占比24% 。
- 灰色(LAS + CTC ):占比11% ,表示结合了LAS和CTC的模型。
- 黄色(RNN-T):占比10% 。
- 浅蓝色(HMM-hybrid):占比15% 。