nn.GRU 是 PyTorch 中实现门控循环单元(Gated Recurrent Unit, GRU)的模块。GRU 是一种循环神经网络(RNN)的变体,用于处理序列数据,能够更好地捕捉长距离依赖关系。
⭐重点掌握输入输出部分输入张量:input、初始隐藏状态:h_0、输出张量:output、最终隐藏状态:h_n
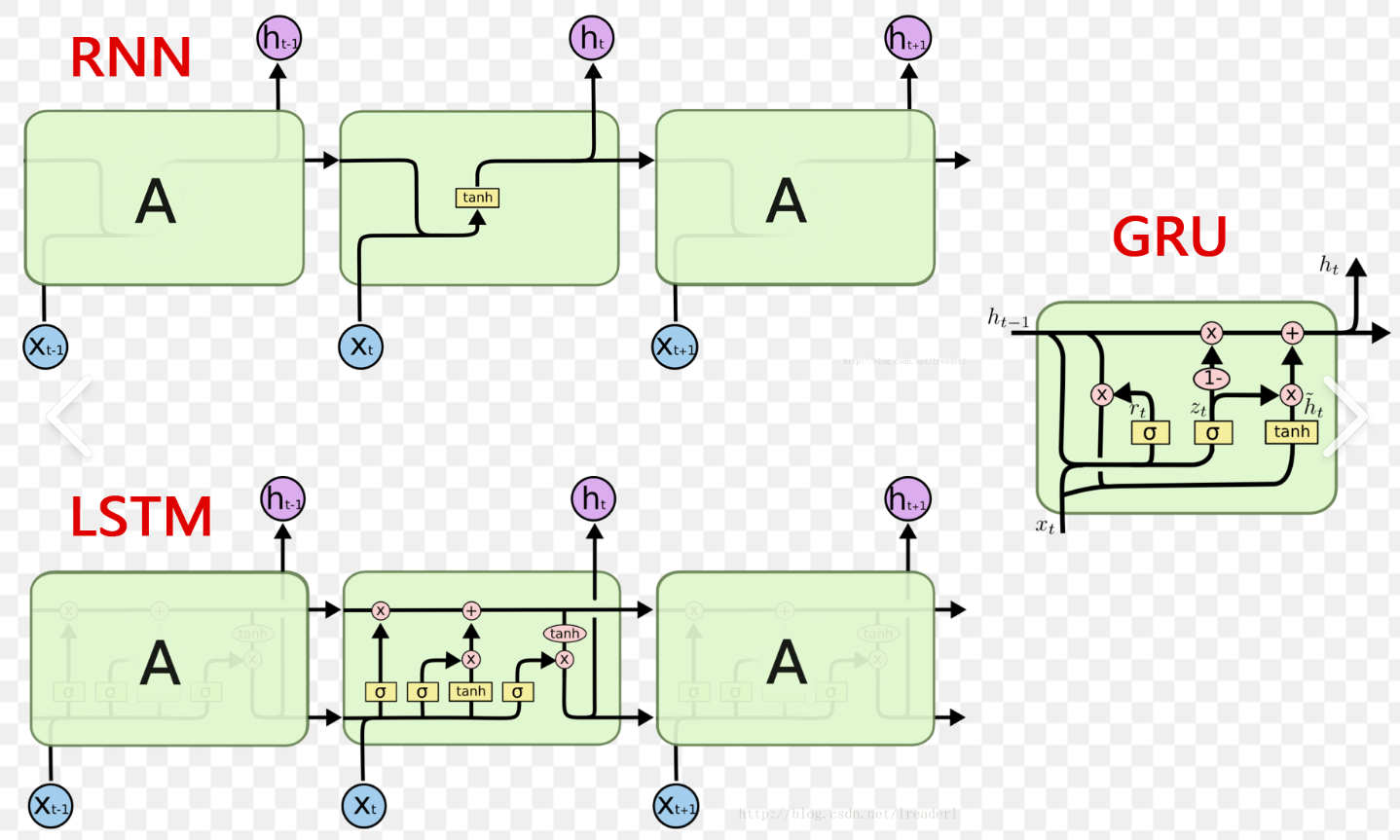
nn.GRU 的参数
nn.GRU 的完整定义如下:
torch.nn.GRU(
input_size,
hidden_size,
num_layers=1,
bias=True,
batch_first=False,
dropout=0.0,
bidirectional=False
)1. input_size
-
类型 :
int -
含义:输入特征的维度。
-
解释 :假设输入序列的形状为
[batch_size, seq_len, input_size],其中:-
batch_size是批量大小。 -
seq_len是序列的长度。 -
input_size是每个时间步输入特征的维度。
-
-
示例 :如果输入是一个单词序列,且每个单词通过嵌入层映射为 128 维的向量,则
input_size=128。
2. hidden_size
-
类型 :
int -
含义:隐藏状态的维度。
-
解释 :GRU 的隐藏状态维度决定了模型内部状态的大小。输出的隐藏状态形状为
[batch_size, seq_len, hidden_size]。 -
示例 :如果
hidden_size=256,则每个时间步的隐藏状态是一个 256 维的向量。
3. num_layers
-
类型 :
int -
默认值 :
1 -
含义:GRU 的层数。
-
解释:可以堆叠多个 GRU 层,每一层的输出作为下一层的输入。增加层数可以增强模型的表达能力,但也会增加计算复杂度。
-
示例 :如果
num_layers=2,则有两层 GRU,第一层的输出会传递给第二层。
4. bias
-
类型 :
bool -
默认值 :
True -
含义:是否在 GRU 的权重矩阵中添加偏置项。
-
解释 :如果设置为
False,则在计算过程中不会使用偏置项,这可以减少模型的参数数量,但可能会影响模型的性能。
5. batch_first
-
类型 :
bool -
默认值 :
False -
含义:输入和输出张量的第一个维度是否是批量大小。
-
解释:
-
如果
batch_first=True,输入和输出的形状为[batch_size, seq_len, input_size]。 -
如果
batch_first=False,输入和输出的形状为[seq_len, batch_size, input_size]。
-
-
示例 :在大多数实际应用中,为了方便处理批量数据,通常设置
batch_first=True。
6. dropout
-
类型 :
float -
默认值 :
0.0 -
含义:在 GRU 的每一层之间应用的 dropout 概率。
-
解释 :
dropout用于防止过拟合,通过在训练过程中随机丢弃一些神经元的输出来增强模型的泛化能力。该参数仅在num_layers > 1时有效。 -
示例 :如果
dropout=0.5,则在每一层之间有 50% 的概率丢弃神经元的输出。
7. bidirectional
-
类型 :
bool -
默认值 :
False -
含义:是否使用双向 GRU。
-
解释:
-
如果
bidirectional=True,则 GRU 会同时处理序列的正向和反向信息,输出的隐藏状态维度会加倍(2 * hidden_size)。 -
如果
bidirectional=False,则 GRU 只处理序列的正向信息。
-
-
示例:在一些任务中(如文本分类、机器翻译等),双向 GRU 可以更好地捕捉上下文信息。
输入和输出
输入
-
输入张量 :
input-
形状 :
[batch_size, seq_len, input_size](如果batch_first=True)或[seq_len, batch_size, input_size](如果batch_first=False)。 -
含义 :输入序列,每个时间步的特征维度为
input_size。
-
-
初始隐藏状态 :
h_0-
形状 :
[num_layers * num_directions, batch_size, hidden_size]。 -
含义 :初始隐藏状态,
num_directions是方向的数量(单向为 1,双向为 2)。 -
默认值:如果未提供,则默认为全零张量。
-
输出
-
输出张量 :
output-
形状 :
[batch_size, seq_len, num_directions * hidden_size](如果batch_first=True)或[seq_len, batch_size, num_directions * hidden_size](如果batch_first=False)。 -
含义:每个时间步的隐藏状态。
-
-
最终隐藏状态 :
h_n-
形状 :
[num_layers * num_directions, batch_size, hidden_size]。 -
含义:序列处理结束后的最终隐藏状态。
-