目录
前言
学习 UP 主 比飞鸟贵重的多_HKL 的 GGML源码逐行调试 视频,记录下个人学习笔记,仅供自己参考😄
refer1:【大模型部署】GGML源码逐行调试
refer2:llama.cpp源码解读--ggml框架学习
refer3:https://github.com/ggml-org/ggml
refer4:https://chatgpt.com/
1. 简述
我们接着 上篇文章 来讲,在上篇文章中我们梳理了 ggml 推理 gpt-2 时模型加载部分的总体流程,这篇文章我们就来看下剩余的流程具体都是怎么做的
2. 预分配计算图内存
这个小节我们来看 ggml 框架是如何分配计算图内存的,代码如下:
cpp
ggml_gallocr_t allocr = NULL;
// allocate the compute buffer
{
// create a graph allocator with the backend's default buffer type
allocr = ggml_gallocr_new(ggml_backend_get_default_buffer_type(model.backend));
// create the worst case graph for memory usage estimation
int n_tokens = std::min(model.hparams.n_ctx, params.n_batch);
int n_past = model.hparams.n_ctx - n_tokens;
struct ggml_cgraph * gf = gpt2_graph(model, n_past, n_tokens);
// pre-allocate the compute buffer for the worst case (optional)
ggml_gallocr_reserve(allocr, gf);
size_t mem_size = ggml_gallocr_get_buffer_size(allocr, 0);
fprintf(stderr, "%s: compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0);
}整体流程如下:(from ChatGPT)
1. 创建图内存分配器
cpp
allocr = ggml_gallocr_new(ggml_backend_get_default_buffer_type(model.backend));使用后端默认的缓冲区类型,通过调用 ggml_gallocr_new 创建一个图内存分配器(allocr)
2. 构建最坏情况的计算图
cpp
int n_tokens = std::min(model.hparams.n_ctx, params.n_batch);
int n_past = model.hparams.n_ctx - n_tokens;
struct ggml_cgraph * gf = gpt2_graph(model, n_past, n_tokens);为了估计最坏情况下所需的计算内存,代码先根据模型上下文长度以及 batch 参数计算出当前 token 数和 past 数,然后调用 gpt2_graph 来构造一个最坏情况的计算图
3. 预留计算图内存
cpp
ggml_gallocr_reserve(allocr, gf);
size_t mem_size = ggml_gallocr_get_buffer_size(allocr, 0);
fprintf(stderr, "%s: compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0);利用图内存分配器和构造的最坏情况计算图,调用 ggml_gallocr_reserve 对计算图内所有节点所需的内存进行预分配
整个流程从后端缓冲区类型出发,创建一个专门用于计算图内存管理的分配器,接着通过最坏情况的计算图来精确估计计算过程中将使用的内存,然后预留这部分内存,最后查询并输出整个分配结果
下面我们就来对每个流程进行具体的分析
2.1 创建图内存分配器
这部分代码的作用是为后续计算图内存预分配创建一个 "图内存分配器"(graph allocator),也就是 ggml_gallocr 对象。该对象负责管理后端缓冲区(backend buffer)相关的信息以及对应的动态张量分配器(dynamic tensor allocator),为后续的计算图节点内存分配提供统一的接口
1. 图内存分配器创建接口函数 ggml_gallocr_new
cpp
ggml_gallocr_t ggml_gallocr_new(ggml_backend_buffer_type_t buft) {
return ggml_gallocr_new_n(&buft, 1);
}这是一个方便的封装函数,用于创建只有一个缓冲区类型的图内存分配器,它接收一个后端缓冲区类型 buft
2. 图内存分配器创建实现函数 ggml_gallocr_new_n
cpp
ggml_gallocr_t ggml_gallocr_new_n(ggml_backend_buffer_type_t * bufts, int n_bufs) {
ggml_gallocr_t galloc = (ggml_gallocr_t)calloc(1, sizeof(struct ggml_gallocr));
GGML_ASSERT(galloc != NULL);
galloc->bufts = calloc(n_bufs, sizeof(ggml_backend_buffer_type_t));
GGML_ASSERT(galloc->bufts != NULL);
galloc->buffers = calloc(n_bufs, sizeof(ggml_backend_buffer_t));
GGML_ASSERT(galloc->buffers != NULL);
galloc->buf_tallocs = calloc(n_bufs, sizeof(struct ggml_dyn_tallocr *));
GGML_ASSERT(galloc->buf_tallocs != NULL);
for (int i = 0; i < n_bufs; i++) {
galloc->bufts[i] = bufts[i];
galloc->buffers[i] = NULL;
// 检查是否已经使用过该缓冲区类型,若是,则重用已有的动态张量分配器
for (int j = 0; j < i; j++) {
if (bufts[i] == bufts[j]) {
galloc->buf_tallocs[i] = galloc->buf_tallocs[j];
break;
}
}
// 如果前面没有匹配到,则新建一个动态张量分配器
if (galloc->buf_tallocs[i] == NULL) {
size_t alignment = ggml_backend_buft_get_alignment(bufts[i]);
galloc->buf_tallocs[i] = ggml_dyn_tallocr_new(alignment);
}
}
galloc->n_buffers = n_bufs;
return galloc;
}创建流程如下:
- 内存分配
- 通过
calloc为ggml_gallocr结构体分配内存,并确保内存全部置 0 - 分别为存储后端缓冲区类型的数组
bufts、后端缓冲区数组buffers和动态张量分配器数组buf_tallocs分配空间,空间大小都为n_bufs
- 通过
- 初始化每个缓冲区类型及其分配器
- 循环遍历每个缓冲区
- 将传入的
bufts[i]直接复制到galloc->bufts[i]中 - 初始化对应的
buffers[i]为NULL
- 将传入的
- 重用动态分配器
- 内部循环检查在前面是否已经遇到相同的缓冲区类型。如果相同,就直接将之前的动态张量分配器指针复用到当前
buf_tallocs[i]中,这避免了对同一缓冲区类型重复创建分配器
- 内部循环检查在前面是否已经遇到相同的缓冲区类型。如果相同,就直接将之前的动态张量分配器指针复用到当前
- 新建动态张量分配器
- 如果当前缓冲区类型第一次出现,则调用
ggml_backend_buft_get_alignment获取该缓冲区的对齐要求 - 然后调用
ggml_dyn_tallocr_new新建一个动态张量分配器,并存储到galloc->buf_tallocs[i]中
- 如果当前缓冲区类型第一次出现,则调用
- 循环遍历每个缓冲区
- 设置缓冲区数量
- 最后将
n_bufs保存在galloc->n_buffers字段中,并返回新建的图内存分配器galloc
- 最后将
这种设计使得图内存分配器能够根据实际后端的内存对齐和最大分配要求,对计算图中可能产生的中间张量内存进行精确预估和统一管理
2.2 构建最坏情况的计算图
这部分代码(gpt2_graph(...))的目的是在预分配计算图内存之前,构造一个 "最坏情况" 下的计算图,也就是在最极端内存需求下(例如最多 token)的图结构,从而准确评估所需内存量。整个过程大体分为以下几个步骤:(from ChatGPT)
1. 预留计算图元数据缓冲区
cpp
static size_t buf_size = ggml_tensor_overhead()*GPT2_MAX_NODES + ggml_graph_overhead_custom(GPT2_MAX_NODES, false);
static std::vector<uint8_t> buf(buf_size);为构建计算图所需的 ggml 上下文与图对象分配一个临时内存缓冲区,该缓冲区只需要存储 ggml_tensor 结构体和 ggml_cgraph 结构体,不包括实际张量数据
2. 初始化 ggml 上下文
cpp
struct ggml_init_params params = {
/*.mem_size =*/ buf_size,
/*.mem_buffer =*/ buf.data(),
/*.no_alloc =*/ true,
};
struct ggml_context * ctx = ggml_init(params);使用预先构造的内存缓冲区与初始化参数,调用 ggml_init 创建上下文。其中参数 no_alloc 为 true,表示后续张量数据将在图内存分配器中进行统一分配,不在这里分配实际内存
3. 构造自定义计算图对象
cpp
struct ggml_cgraph * gf = ggml_new_graph_custom(ctx, GPT2_MAX_NODES, false);使用函数 ggml_new_graph_custom 创建自定义计算图节对象 gf,该对象用于记录所有后续构造的运算节点
4. 构造输入张量
cpp
struct ggml_tensor * embd = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, N);
ggml_set_name(embd, "embd");
ggml_set_input(embd);
struct ggml_tensor * position = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, N);
ggml_set_name(position, "position");
ggml_set_input(position);构造两个一维张量:
- embd:存放 token 索引,作为模型输入
- position:存放位置索引
并调用 ggml_set_input 标记为输入张量
5. 构造嵌入查询与位置嵌入加和
cpp
struct ggml_tensor * inpL =
ggml_add(ctx,
ggml_get_rows(ctx, model.wte, embd),
ggml_get_rows(ctx, model.wpe, position));对模型中预先加载的词向量(wte)和位置编码(wpe),通过 ggml_get_rows 分别取出对应于输入 token 和位置的行,之后用 ggml_add 相加产生第一层的输入张量 inpL
6. 进入 Transformer 层循环
cpp
for (int il = 0; il < n_layer; ++il) {
struct ggml_tensor * cur;
// norm: 归一化并加权偏置
{
cur = ggml_norm(ctx, inpL, hparams.eps);
cur = ggml_add(ctx,
ggml_mul(ctx,
cur,
model.layers[il].ln_1_g),
model.layers[il].ln_1_b);
}
// attn: 对输入进行全连接变换并加偏置
{
cur = ggml_mul_mat(ctx, model.layers[il].c_attn_attn_w, cur);
cur = ggml_add(ctx, cur, model.layers[il].c_attn_attn_b);
}
// self-attention: 从 cur 中按块拆分出 Q、K、V,再进行计算与 KV 缓存存储
{
struct ggml_tensor * Qcur = ggml_view_2d(ctx, cur, n_embd, N, cur->nb[1], 0*sizeof(float)*n_embd);
struct ggml_tensor * Kcur = ggml_view_2d(ctx, cur, n_embd, N, cur->nb[1], 1*sizeof(float)*n_embd);
struct ggml_tensor * Vcur = ggml_view_2d(ctx, cur, n_embd, N, cur->nb[1], 2*sizeof(float)*n_embd);
if (N >= 1) {
struct ggml_tensor * k = ggml_view_1d(ctx, model.memory_k, N*n_embd, (ggml_element_size(model.memory_k)*n_embd)*(il*n_ctx + n_past));
struct ggml_tensor * v = ggml_view_1d(ctx, model.memory_v, N*n_embd, (ggml_element_size(model.memory_v)*n_embd)*(il*n_ctx + n_past));
ggml_build_forward_expand(gf, ggml_cpy(ctx, Kcur, k));
ggml_build_forward_expand(gf, ggml_cpy(ctx, Vcur, v));
}
// 对 Q、K 进行 reshape、permute
struct ggml_tensor * Q = ggml_permute(ctx,
ggml_cont_3d(ctx, Qcur, n_embd/n_head, n_head, N),
0, 2, 1, 3);
struct ggml_tensor * K = ggml_permute(ctx,
ggml_reshape_3d(ctx,
ggml_view_1d(ctx, model.memory_k, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_k)*n_embd),
n_embd/n_head, n_head, n_past + N),
0, 2, 1, 3);
// 注意力计算: K*Q, 缩放、mask、softmax
struct ggml_tensor * KQ = ggml_mul_mat(ctx, K, Q);
struct ggml_tensor * KQ_scaled = ggml_scale(ctx, KQ, 1.0f/sqrtf(float(n_embd)/n_head));
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf(ctx, KQ_scaled, n_past);
struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx, KQ_masked);
// V_trans: 对 V 进行相应的变换
struct ggml_tensor * V_trans = ggml_cont_3d(ctx,
ggml_permute(ctx,
ggml_reshape_3d(ctx,
ggml_view_1d(ctx, model.memory_v, (n_past + N)*n_embd, il*n_ctx*ggml_element_size(model.memory_v)*n_embd),
n_embd/n_head, n_head, n_past + N),
1, 2, 0, 3),
n_past + N, n_embd/n_head, n_head);
// 最后计算 KQV,即 V_trans * attention权重
struct ggml_tensor * KQV = ggml_mul_mat(ctx, V_trans, KQ_soft_max);
struct ggml_tensor * KQV_merged = ggml_permute(ctx, KQV, 0, 2, 1, 3);
cur = ggml_cont_2d(ctx, KQV_merged, n_embd, N);
}
// attention projection:线性变换(矩阵乘法+加偏置)
{
cur = ggml_mul_mat(ctx, model.layers[il].c_attn_proj_w, cur);
cur = ggml_add(ctx, cur, model.layers[il].c_attn_proj_b);
}
// 添加输入的残差连接:将计算结果与上层输入 inpL 相加
cur = ggml_add(ctx, cur, inpL);
// Feed Forward 部分(前馈网络):先归一化、全连接、GELU激活,再做投影和加残差
struct ggml_tensor * inpFF = cur;
{
{
cur = ggml_norm(ctx, inpFF, hparams.eps);
cur = ggml_add(ctx,
ggml_mul(ctx, cur, model.layers[il].ln_2_g),
model.layers[il].ln_2_b);
}
cur = ggml_mul_mat(ctx, model.layers[il].c_mlp_fc_w, cur);
cur = ggml_add(ctx, cur, model.layers[il].c_mlp_fc_b);
cur = ggml_gelu(ctx, cur);
cur = ggml_mul_mat(ctx, model.layers[il].c_mlp_proj_w, cur);
cur = ggml_add(ctx, cur, model.layers[il].c_mlp_proj_b);
}
// 再次残差连接:将前馈网络的输出与输入 inpFF 相加
inpL = ggml_add(ctx, cur, inpFF);
}对于每个 Transformer 层(总层数为 n_layer),执行如下主要操作:
- LayerNorm 与残差连接(前置)
- 多头自注意力
- 先将上一层输出(
inpL)经过归一化(ggml_norm) - 经过全连接变换生成 attention 输入
- 使用
ggml_view_2d从cur中分离出 Q、K、V 向量 - 利用
ggml_view_1d将当前层的 K 与 V 存入模型内部的 kv cache 中(这里利用n_ctx、n_past参数定位到正确的偏移) - 对 Q、K 进行 reshape 和 permute 操作,准备进行注意力点积计算
- 计算注意力得分( Q K T QK^T QKT)、进行缩放( 1 D \frac{1}{\sqrt{D}} D 1)、mask 掩码、softmax 得到注意力权重
- 对 V 进行变换,最终通过矩阵乘法得到注意力层输出
- 对输出进行排列(permute)和变形(contiguous 转为 2D 张量)
- 先将上一层输出(
- Attention Projection
- 将多头自注意力输出进行线性变换
- 残差连接与后续 FFN
- 将输出结果与输入相加(残差连接)
- 接着进行前馈网络操作:LayerNorm、全连接、GELU 激活,再做一次全连接投影,并同样进行残差连接
- 更新
inpL为当前层输出,为下一层做输入
7. 最终归一化与输出映射
cpp
{
inpL = ggml_norm(ctx, inpL, hparams.eps);
inpL = ggml_add(ctx,
ggml_mul(ctx, inpL, model.ln_f_g),
model.ln_f_b);
}
inpL = ggml_mul_mat(ctx, model.lm_head, inpL);
ggml_set_name(inpL, "logits");
ggml_set_output(inpL);在所有 Transformer 层之后,先对最终的 inpL 进行归一化,并使用最后的归一化参数 ln_f_g 和 ln_f_b 对其进行变换。接着将归一化后的张量与模型的 lm_head 做矩阵乘法,生成 logits 输出,并将该张量设置为 graph 的输出。
8. 构建前向传播图并清理上下文
cpp
ggml_build_forward_expand(gf, inpL);
ggml_free(ctx);
return gf;最后通过 ggml_build_forward_expand(...) 将计算图的最后一个节点(logits)添加至图中完成前向传播路径构建,然后调用 ggml_free(ctx) 释放上下文中的临时内存,返回构造好的计算图 gf
通过构建这样一个最坏情况的计算图(采用最坏的 tokens 数量、最大 n_ctx),上层代码就能通过预分配接口准确估算计算过程中内存需求,为后续推理的高效执行做好内存预留工作
Note :在这里整个 graph 计算图是手动构建的,这有点类似于 tensorrtx 这个 repo,tensorrtx 是通过 TensorRT 的 C++ API 手动来构建模型
2.3 预留计算图内存
这部分代码的主要目标是为构建好的计算图(graph)预先计算并分配好所有中间节点和叶子节点所需内存,利用图内存分配器(gallocr)对计算图中各个张量的内存需求进行 "预留",代码通过以下几个步骤来实现这一目标:
1. 初始化 Hash 表用于内存分配记录
cpp
size_t min_hash_size = graph->n_nodes + graph->n_leafs;
min_hash_size += min_hash_size / 4; // 增加 25% 余量以避免哈希冲突计算需要的 hash 表大小,即总节点数(计算节点和叶子节点之和)再加上 25% 的余量,旨在降低哈希冲突的概率
2. 初始化并重置 Hash 表
cpp
if (galloc->hash_set.size < min_hash_size) {
ggml_hash_set_free(&galloc->hash_set);
galloc->hash_set = ggml_hash_set_new(min_hash_size);
GGML_ASSERT(galloc->hash_set.keys != NULL);
free(galloc->hash_values);
galloc->hash_values = malloc(sizeof(struct hash_node) * galloc->hash_set.size);
GGML_ASSERT(galloc->hash_values != NULL);
}检查当前图内存分配器中的 hash set 是否足够大。如果不足,则先释放旧的,再创建一个新哈希集合,保证其大小能容纳所有节点信息
3. 重置所有动态张量分配器
cpp
for (int i = 0; i < galloc->n_buffers; i++) {
ggml_dyn_tallocr_reset(galloc->buf_tallocs[i]);
}对每个后端缓冲区对应的动态张量分配器进行重置,将内部的空闲块初始化为初始状态
4. 分配图中各个节点和叶子的内存
cpp
ggml_gallocr_alloc_graph_impl(galloc, graph, node_buffer_ids, leaf_buffer_ids);这个函数内部会遍历计算图中所有的节点(nodes)和叶子(leafs),为每个 tensor 计算出对应的内存分配(buffer_id, offset 等),并将这些信息记录到前面分配的 Hash 表中
5. 建立 node_allocs 数组
cpp
if (galloc->n_nodes < graph->n_nodes) {
free(galloc->node_allocs);
galloc->node_allocs = calloc(graph->n_nodes, sizeof(struct node_alloc));
GGML_ASSERT(galloc->node_allocs != NULL);
}
galloc->n_nodes = graph->n_nodes;
for (int i = 0; i < graph->n_nodes; i++) {
struct ggml_tensor * node = graph->nodes[i];
struct node_alloc * node_alloc = &galloc->node_allocs[i];
if (node->view_src || node->data) {
node_alloc->dst.buffer_id = -1;
node_alloc->dst.offset = SIZE_MAX;
node_alloc->dst.size_max = 0;
} else {
struct hash_node * hn = ggml_gallocr_hash_get(galloc, node);
node_alloc->dst.buffer_id = hn->buffer_id;
node_alloc->dst.offset = hn->offset;
node_alloc->dst.size_max = ggml_backend_buft_get_alloc_size(galloc->bufts[hn->buffer_id], node);
}
for (int j = 0; j < GGML_MAX_SRC; j++) {
struct ggml_tensor * src = node->src[j];
if (!src || src->view_src || src->data) {
node_alloc->src[j].buffer_id = -1;
node_alloc->src[j].offset = SIZE_MAX;
node_alloc->src[j].size_max = 0;
} else {
struct hash_node * hn = ggml_gallocr_hash_get(galloc, src);
node_alloc->src[j].buffer_id = hn->buffer_id;
node_alloc->src[j].offset = hn->offset;
node_alloc->src[j].size_max = ggml_backend_buft_get_alloc_size(galloc->bufts[hn->buffer_id], src);
}
}
}为计算图中的每个 "计算节点"(非叶子张量)建立一个 node_alloc 结构,记录该节点的输出(dst)在内存缓冲区中的分配情况,以及其依赖的各个输入(src)的内存分配信息。具体操作如下:
- 若 node 已经有数据或属于视图,则标记其输出(dst)为无需重新分配
- 否则利用
ggml_gallocr_hash_get从 Hash 表中查找该 tensor 的分配记录,将buffer_id、offset、size_max写入对应的 node_alloc - 对每个节点的每个输入源做类似处理
6. 建立 leaf_allocs 数组
cpp
if (galloc->n_leafs < graph->n_leafs) {
free(galloc->leaf_allocs);
galloc->leaf_allocs = calloc(graph->n_leafs, sizeof(galloc->leaf_allocs[0]));
GGML_ASSERT(galloc->leaf_allocs != NULL);
}
galloc->n_leafs = graph->n_leafs;
for (int i = 0; i < graph->n_leafs; i++) {
struct ggml_tensor * leaf = graph->leafs[i];
struct hash_node * hn = ggml_gallocr_hash_get(galloc, leaf);
if (leaf->view_src || leaf->data) {
galloc->leaf_allocs[i].leaf.buffer_id = -1;
galloc->leaf_allocs[i].leaf.offset = SIZE_MAX;
galloc->leaf_allocs[i].leaf.size_max = 0;
} else {
galloc->leaf_allocs[i].leaf.buffer_id = hn->buffer_id;
galloc->leaf_allocs[i].leaf.offset = hn->offset;
galloc->leaf_allocs[i].leaf.size_max = ggml_backend_buft_get_alloc_size(galloc->bufts[hn->buffer_id], leaf);
}
}为计算图中的每个 "叶子节点"(通常是输入、常量或权重)建立一个 leaf_alloc 结构,记录其在内存中的分配信息。具体操作如下:
- 同样利用
ggml_gallocr_hash_get获取 leaf 在哈希表中的分配记录,并写入leaf_alloc - 如果 leaf 已经是一个 view 或者已经分配数据,则标记为无需分配
7. 根据当前分配器信息重新分配后端缓冲区
cpp
for (int i = 0; i < galloc->n_buffers; i++) {
// 如果同一个动态分配器被重复使用,则复用已有的缓冲区
for (int j = 0; j < i; j++) {
if (galloc->buf_tallocs[j] == galloc->buf_tallocs[i]) {
galloc->buffers[i] = galloc->buffers[j];
break;
}
}
size_t cur_size = galloc->buffers[i] ? ggml_backend_buffer_get_size(galloc->buffers[i]) : 0;
size_t new_size = ggml_dyn_tallocr_max_size(galloc->buf_tallocs[i]);
// 即使当前该缓冲区中没有 tensor 被分配,也需要分配以便初始化视图 tensor
if (new_size > cur_size || galloc->buffers[i] == NULL) {
#ifndef NDEBUG
GGML_LOG_DEBUG("%s: reallocating %s buffer from size %.02f MiB to %.02f MiB\n", __func__, ggml_backend_buft_name(galloc->bufts[i]), cur_size / 1024.0 / 1024.0, new_size / 1024.0 / 1024.0);
#endif
ggml_backend_buffer_free(galloc->buffers[i]);
galloc->buffers[i] = ggml_backend_buft_alloc_buffer(galloc->bufts[i], new_size);
if (galloc->buffers[i] == NULL) {
GGML_LOG_ERROR("%s: failed to allocate %s buffer of size %zu\n", __func__, ggml_backend_buft_name(galloc->bufts[i]), new_size);
return false;
}
ggml_backend_buffer_set_usage(galloc->buffers[i], GGML_BACKEND_BUFFER_USAGE_COMPUTE);
}
}根据预先通过动态分配器(ggml_dyn_tallocr)的累计信息,计算出每个缓冲区所需的内存新大小。具体操作如下:
- 对每个后端缓冲区(
galloc->buffers[i]),先检查是否存在同一动态分配器已复用的情况,如果有则复用相同的缓冲区 - 获取当前缓冲区大小(cur_size),并调用
ggml_dyn_tallocr_max_size得到该缓冲区内所有 tensor 分配所需的最大内存空间(new_size) - 如果 new_size 大于当前分配大小或者当前没有分配,则释放旧缓冲区,并通过
ggml_backend_buft_alloc_buffer分配一个新的缓冲区,大小为 new_size - 分配成功后,调用
ggml_backend_buffer_set_usage标记该缓冲区的使用场景为 COMPUTE 计算
8. 返回成功标志
函数最后返回 true 表示预留计算图内存成功完成
这一系列流程确保了计算图在执行前所有内存都已被 "预留",即各个节点和叶子的内存位置与大小都已经确定,后续在实际执行图的运算(前向传播)时,只需要按照预留信息访问连续的后端缓冲区,即可获得高效且正确的内存访问
至此,我们完成了预分配计算图内存的全部代码分析,下面我们来看分词
3. 分词
这个小节我们来看 ggml 框架在推理 gpt-2 时是如何做分词的:

gpt_tokenize 函数负责将用户输入的 prompt 文本转化为一系列 token(即 vocab_id)以便后续模型推理时作为输入,下面我们来具体分析:
1. 文本拆分为单词和特殊 token
cpp
std::vector<std::string> words;
// first split the text into words
{
std::string str = text;
// Generate the subpattern from the special_tokens vector if it's not empty
if (!vocab.special_tokens.empty()) {
const std::regex escape(R"([\[\\\^\$\.\|\?\*\+\(\)\{\}])");
std::string special_tokens_subpattern;
for (const auto & token : vocab.special_tokens) {
if (!special_tokens_subpattern.empty()) {
special_tokens_subpattern += "|";
}
special_tokens_subpattern += std::regex_replace(token, escape, R"(\$&)");
}
std::regex re(special_tokens_subpattern);
std::smatch m;
// Split the text by special tokens.
while (std::regex_search(str, m, re)) {
// Split the substrings in-between special tokens into words.
gpt_split_words(m.prefix(), words);
// Add matched special tokens as words.
for (auto x : m) {
words.push_back(x);
}
str = m.suffix();
}
// Remaining text without special tokens will be handled below.
}
gpt_split_words(str, words);
}这部分代码首先将输入的 text 拷贝给局部变量 str,然后检查 vocab.special_tokens 是否为空。如果有特殊 token,则构造一个正则表达式 special_tokens_subpattern 来匹配这些 token,并使用 std::regex_search 将特殊 token 从文本中提取出来
在匹配过程中,通过 m.prefix() 调用 gpt_split_words 拆分特殊 token 前面的内容,然后直接把匹配到的特殊 token 加入 words 向量
最后,对剩余的字符串 str(即没有特殊 token 的部分),再次调用 gpt_split_words 进一步拆分,确保所有单词、标点、数字等都被拆分出来
gpt_split_words 函数实现如下:
cpp
void gpt_split_words(std::string str, std::vector<std::string>& words) {
const std::string pattern = R"('s|'t|'re|'ve|'m|'ll|'d| ?[[:alpha:]]+| ?[[:digit:]]+| ?[^\s[:alpha:][:digit:]]+|\s+(?!\S)|\s+)";
const std::regex re(pattern);
std::smatch m;
while (std::regex_search(str, m, re)) {
for (auto x : m) {
words.push_back(x);
}
str = m.suffix();
}
}首先预定义正则表达式模式,包含以下几类匹配规则:
- 匹配特定的缩写形式,如
's、't、're等 - 匹配可选空格后的一串字母(英文单词)
- 匹配可选空格后的一串数字
- 匹配可选空格后非空格、非字母、非数字的符号
- 匹配连续空白字符(但不跟随非空白字符)以及其他空白组合
该正则表达式设计的目的是将文本细致地拆分成组成部分,使得后续的 token greedy 分割可以更准确地匹配词汇表中的 token
接着拆分文本,利用 std::regex_search 对输入字符串进行迭代匹配,将每次匹配到的部分(smatch 中的各个子匹配)加入到 word 向量中,直至字符串完全匹配结束
2. 采用贪心匹配策略为每个单词找到最长 token
cpp
// find the longest token that forms each word in words:
std::vector<gpt_vocab::id> tokens;
for (const auto & word : words) {
for (int i = 0; i < (int) word.size(); ){
for (int j = word.size() - 1; j >= i; j--){
auto cand = word.substr(i, j-i+1);
auto it = vocab.token_to_id.find(cand);
if (it != vocab.token_to_id.end()){ // word.substr(i, j-i+1) in vocab
tokens.push_back(it->second);
i = j + 1;
break;
}
else if (j == i){ // word.substr(i, 1) has no matching
fprintf(stderr, "%s: unknown token '%s'\n", __func__, word.substr(i, 1).data());
i++;
}
}
}
}遍历 words 向量中每一个字符串 word,对于每个 word,以索引 i 开始,尝试取从 i 到 j 的子串,其中 j 从单词末尾开始向 i 遍历,以保证能匹配最长可能的子串
若找到在 vocab.token_to_id 中存在的子串(即 token),则将对应的 token id 加入返回的 tokens 向量,并将 i 移动到匹配结束后的位置,从而实现贪心匹配。
如果连一个字符都匹配不到时(j == i),则输出错误并将 i 加 1
3. 返回 token 序列
cpp
return tokens;经过贪心匹配后,得到完整的 token 序列,存储在 tokens 向量中,函数最后返回这一向量作为最终的 token 化结果
该函数完成了将原始输入文本转换成一系列 token id,为后续模型推理提供输入表示
至此,我们完成了分词的全部代码分析,下面我们来看最后一部分即模型的推理与生成
4. 模型推理与生成
这个小节我们来看 ggml 框架在推理 gpt-2 时是如何进行前向传播推理与文本生成的:
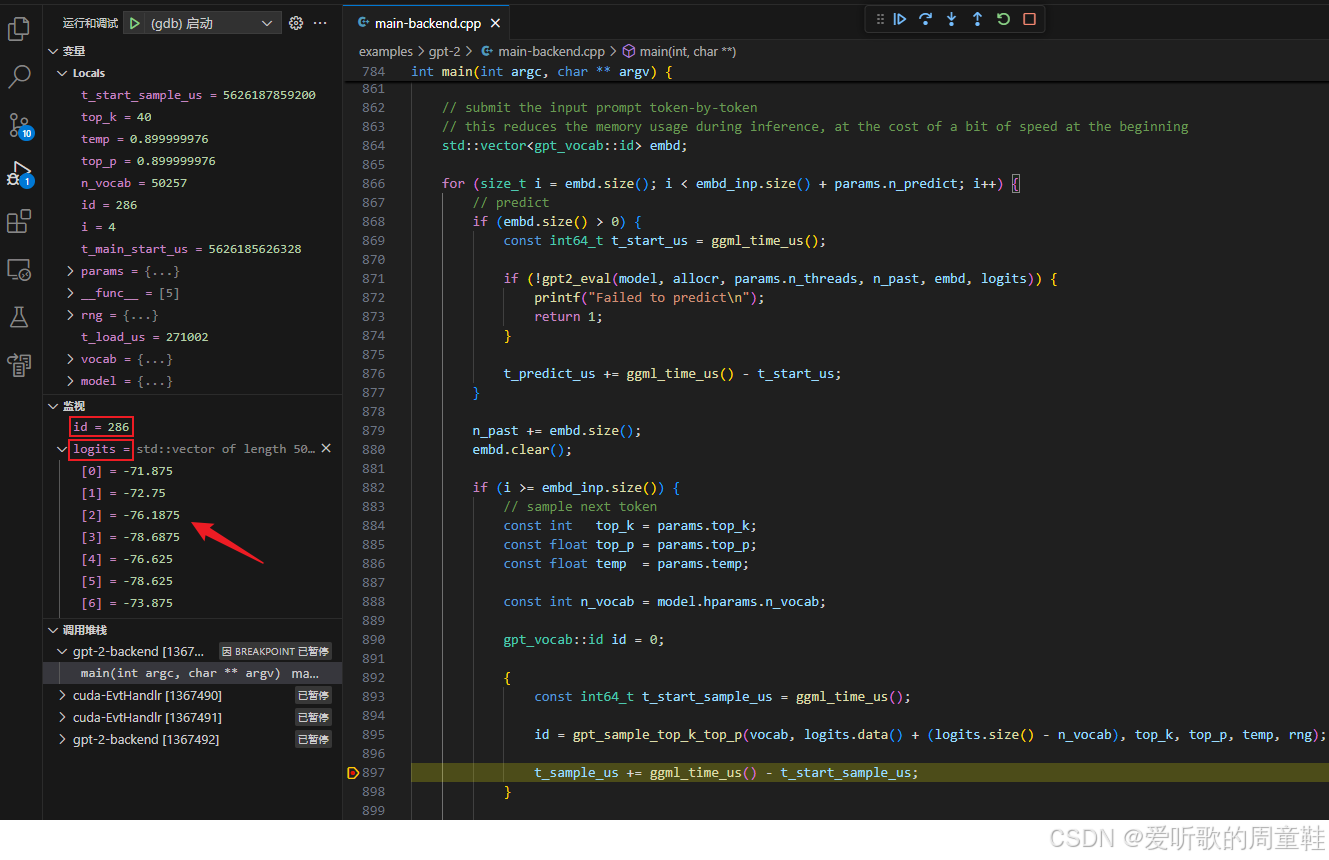
这里我们逐 token 来进行文本生成,先通过调用模型推理函数 gpt2_eval 来计算 logits,接着通过采样函数 gpt_sample_top_k_top_p 得到下一个 token,如此反复循环直至达到预测 token 数或者遇到结束符退出,下面我们来具体分析这两个函数
4.1 模型推理
gpt2_eval 函数的主要任务是:
- 根据当前上下文构造计算图
- 为计算图分配内存,并设置好输入张量
- 调用后端执行图计算,得到输出张量(logits)
- 从 logits 中提取最后一个 token 的预测结果(
embd_w),返回预测成功的状态
函数签名及参数说明:
- 输入参数:
model:模型结构体,包含模型上下文大小、层数、词汇表大小等信息allocr:图内存分配器(ggml_gallocr)对象,用于为计算图申请计算内存n_threads:设置后端计算使用的线程数n_past:上下文中已有的 token 数embd_inp:当前输入的 token 序列(以词汇 id 表示),它们将用于填充计算图中输入的张量
- 输出参数:
embd_w:输出的 logits 数组
- 返回值
- 返回
true表示推理计算完成
- 返回
下面我们来具体分析整个流程:(from ChatGPT)
1. 计算输入序列长度与参数准备
cpp
const int N = embd_inp.size();
const auto & hparams = model.hparams;
const int n_vocab = hparams.n_vocab;将输入 token 序列的长度保存为 N,引用模型中的超参数,获取词汇表大小 n_vocab
2. 构造计算图
cpp
struct ggml_cgraph * gf = gpt2_graph(model, n_past, embd_inp.size());调用 gpt2_graph 函数,传入当前历史 token 数 n_past 和本次输入 token 数来构造当前上下文下的计算图 gf
3. 分配计算图中的所有张量的内存
cpp
// allocate the graph tensors
ggml_gallocr_alloc_graph(allocr, gf);利用图内存分配器 allocr 为计算图 gf 内部所有尚未分配内存的张量进行内存分配
4. 设置输入张量
cpp
struct ggml_tensor * embd = ggml_graph_get_tensor(gf, "embd");
ggml_backend_tensor_set(embd, embd_inp.data(), 0, N*ggml_element_size(embd));设置 token 嵌入输入,通过 ggml_graph_get_tensor(gf, "embd") 获取计算图中名为 "embd" 的输入张量,利用 ggml_backend_tensor_set 将实际的输入 token 序列写入该张量的内存中
cpp
struct ggml_tensor * position = ggml_graph_get_tensor(gf, "position");
for (int i = 0; i < N; ++i) {
int32_t v = n_past + i;
ggml_backend_tensor_set(position, &v, i*sizeof(int32_t), sizeof(v));
}设置位置编码输入,获取计算图中名为 "position" 的位置张量,循环为每个输入 token 设置位置索引
5. 后端配置与线程设置
cpp
if (ggml_backend_is_cpu(model.backend)) {
ggml_backend_cpu_set_n_threads(model.backend, n_threads);
}判断当前使用的后端是否为 CPU 后端,如果是,则调用 ggml_backend_cpu_set_n_threads 设置使用的线程数为 n_threads
6. 执行计算图
cpp
// run the computation
ggml_backend_graph_compute(model.backend, gf);调用后端接口 ggml_backend_graph_compute 执行构造好的计算图 gf,模型推理的核心步骤就在这个函数。它会根据传入的 model.backend 参数调用不同后端的算子实现去完成整个 graph 的计算,对于当前示例的 CUDA 后端而言,最终调用的函数是 ggml_cuda_compute_forward,如下图所示:
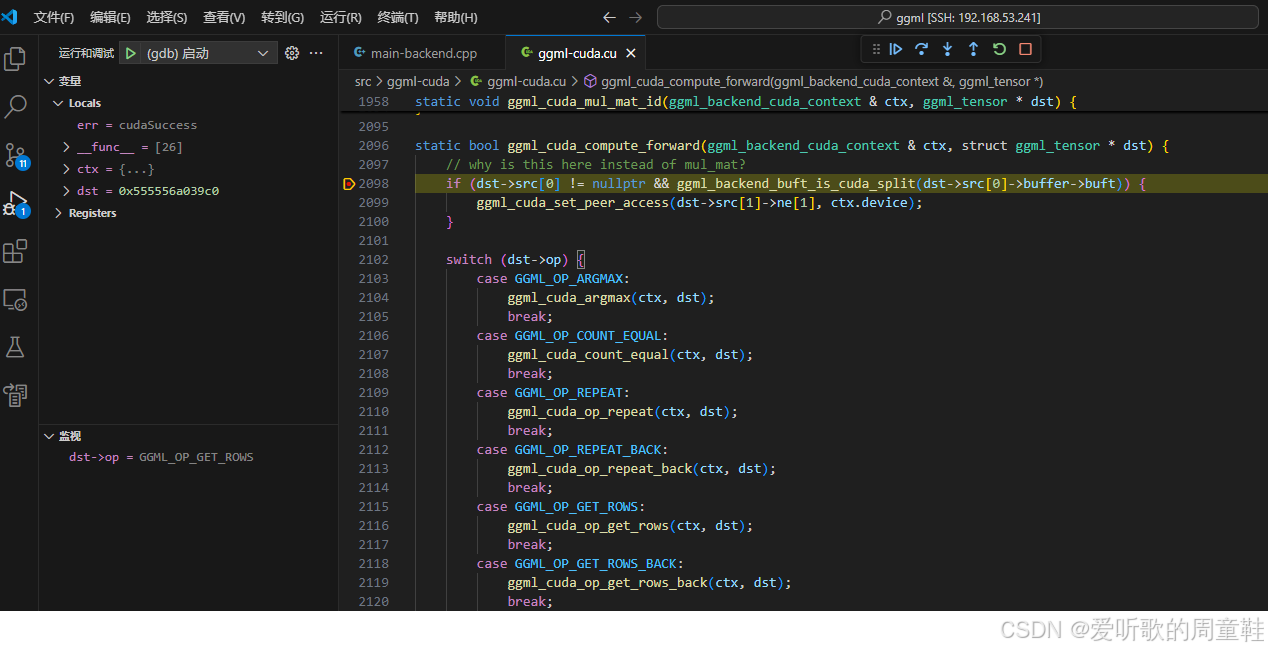
在 ggml_cuda_compute_forward 函数中我们会调用不同 op 算子的 CUDA 实现来完成计算,这是我们要学习的重点内容,看看每个算子的 CUDA 实现具体是怎么做的,不过在 ggml 框架中我们先跳过这部分吧,因为要分析的算子比较多,内容也比较长,以后有机会的话我们在 llama.cpp 中再来分析吧😄
7. 获取输出 logits
cpp
struct ggml_tensor * logits = ggml_graph_get_tensor(gf, "logits");
// return result just for the last token
embd_w.resize(n_vocab);
ggml_backend_tensor_get(logits, embd_w.data(), (n_vocab*(N-1))*sizeof(float), sizeof(float)*n_vocab);
//embd_w.resize(n_vocab*N);
//ggml_backend_tensor_get(logits, embd_w.data(), 0, sizeof(float)*n_vocab*N);
// return result just for the last token
embd_w.resize(n_vocab);
ggml_backend_tensor_get(logits, embd_w.data(), (n_vocab*(N-1))*sizeof(float), sizeof(float)*n_vocab);通过 ggml_graph_get_tensor(gf, "logits") 获取计算图中名为 "logits" 的输出张量,该张量表示对每个 token 预测的 logits 分布,之后获取最后一个 token 的输出:
- 分配
embd_w向量大小为n_vocab,即每个 token 对应一个n_vocab维度的 logits - 通过
ggml_backend_tensor_get从 logits 张量中读取最后一个 token 的 logits 数据
在自回归生成中,我们使用整个序列输出中最后一个 token 的 logits 分布来预测下一个 token,因此这里我们只取最后一个 token 的 logits 即可
8. 返回成功状态
cpp
return true;这样 gpt2_eval 函数便完成了从输入 token 到生成预测 logits 的整个推理过程
4.2 采样
gpt_sample_top_k_top_p 采样函数结合了 Top-K 与 Top-P(Nucleus Sampling)策略,对模型计算出来的 logits 进行温度缩放、选择候选 token、计算概率、归一化、截断概率质心集合,最后根据离散分布随机采样一个 token。
下面我们来具体分析整个流程:(from ChatGPT)
1. 初始化候选列表
cpp
int n_logits = vocab.id_to_token.size();
std::vector<std::pair<double, gpt_vocab::id>> logits_id;
logits_id.reserve(n_logits);
{
const double scale = 1.0 / temp;
for (int i = 0; i < n_logits; ++i) {
logits_id.push_back(std::make_pair(logits[i] * scale, i));
}
}- 获取候选数量:根据词汇表中 token 的数量
n_logits来初始化一个 vector,用于存储每个 token 缩放后对应的 logit 值以及它的 id - 温度缩放:使用给定的温度值
temp对 logit 进行缩放(示例中给定的温度值为 0.9),公式为logits[i] * (1 / temp)- 当
temp < 1时,缩放后 logits 差异会更大,生成更 "确定" 的分布 - 当
temp > 1时,则分布更平坦,生成较为随机的选择
- 当
- 结果存储:每个 token 的 logit 和对应 id 存入到
logits_id向量中,供后续排序和采样使用
2. Top-K 筛选
cpp
std::partial_sort(
logits_id.begin(),
logits_id.begin() + top_k,
logits_id.end(),
[](const std::pair<double, gpt_vocab::id> & a, const std::pair<double, gpt_vocab::id> & b) {
return a.first > b.first;
});
logits_id.resize(top_k);- 部分排序:使用
std::partial_sort对logits_id向量进行排序,仅排序出前top_k个最高的候选 token(示例中 top-k 为 40)- 排序基于
a.first > b.first,即按照缩放后的 logit 值从大到小排序
- 排序基于
- 截断候选集:调用
resize(top_k)截断 vector,使得后续只处理这top_k个候选 token
3. 计算 softmax 概率
cpp
double maxl = -INFINITY;
for (const auto & kv : logits_id) {
maxl = std::max(maxl, kv.first);
}
std::vector<double> probs;
probs.reserve(logits_id.size());
double sum = 0.0;
for (const auto & kv : logits_id) {
double p = exp(kv.first - maxl);
probs.push_back(p);
sum += p;
}
// normalize the probs
for (auto & p : probs) {
p /= sum;
}- 数值稳定性处理:遍历 Top-K 候选 token 计算最大值
maxl。计算 softmax 时先减去最大值,防止指数函数计算中的数值溢出,也就是我们前面文章中提到的 safe softmax - 计算 softmax 概率:遍历 Top-K 个候选 token 分别计算它们的 softmax 概率,公式为
p = exp(scaled_logit - maxl) / sum
4. Top-P 截断(Nucleus Sampling)
cpp
if (top_p < 1.0f) {
double cumsum = 0.0f;
for (int i = 0; i < top_k; i++) {
cumsum += probs[i];
if (cumsum >= top_p) {
top_k = i + 1;
probs.resize(top_k);
logits_id.resize(top_k);
break;
}
}
cumsum = 1.0 / cumsum;
for (int i = 0; i < (int) probs.size(); i++) {
probs[i] *= cumsum;
}
}- Nucleus Sampling:如果
top_p小于 1(示例中 top-p 为 0.9),表示需要保留累积概率质量达到top_p部分,丢弃剩余低概率 token - 累加与截断:逐个累加 Top-K 个 token 的概率
probs,直到累计和cumsum达到或超过设定的阈值top_p。此时,将top_k更新为当前索引加 1,即只保留这部分候选 token,并将probs和logits_id调整为新大小 - 重新归一化:将截断后累积总概率的倒数乘以每个概率,使得新的候选集的概率和重新归一化为 1
5. 离散采样
cpp
std::discrete_distribution<> dist(probs.begin(), probs.end());
int idx = dist(rng);
return logits_id[idx].second;- 构造离散分布:利用标准库的
std::discrete_distribution<>构造一个离散概率分布,分布参数为前面经过 top_p 截断归一化后的概率probs数组 - 随机采样:使用提供的随机数生成器
rng从该离散分布中采样一个索引idx,该索引指向候选 token 集中的某个 token - 返回采样结果:根据采样到的索引从
logits_id数组中获取对应的 token id 并返回,作为最终的采样结果
通过以上步骤,函数最终返回了一个 token id,即下一个生成的 token
下面我们以一个具体的例子来说明采样流程,假设:
- 词汇表大小:10
- 温度:0.9
- top-p:0.9
- top-k:5
原始 logits 数组如下:
| Token id | 原始 Logit 值 |
|---|---|
| 0 | 0.5 |
| 1 | 2.0 |
| 2 | 1.5 |
| 3 | 0.0 |
| 4 | 1.0 |
| 5 | -0.5 |
| 6 | 3.0 |
| 7 | 0.2 |
| 8 | 2.5 |
| 9 | 1.8 |
下面具体说明各个步骤:
1. 温度缩放
温度设为 0.9,则缩放因子为:
s c a l e = 1 0.9 ≈ 1.1111 scale = \frac{1}{0.9} \approx 1.1111 scale=0.91≈1.1111
对每个原始 logit 乘以该因子,得到缩放后的 logit:
| Token id | 原始 Logit 值 | 缩放后 Logit |
|---|---|---|
| 0 | 0.5 | 0.5556 |
| 1 | 2.0 | 2.2222 |
| 2 | 1.5 | 1.6667 |
| 3 | 0.0 | 0.0 |
| 4 | 1.0 | 1.1111 |
| 5 | -0.5 | -0.5556 |
| 6 | 3.0 | 3.3333 |
| 7 | 0.2 | 0.2222 |
| 8 | 2.5 | 2.7778 |
| 9 | 1.8 | 2.0000 |
2. Top-K 筛选
接下来使用 partial_sort 仅保留 logit 最高的前 5 个候选 token,对上面缩放后的 logit 值排序,从高到低,我们得到前 5 个候选为:
shell
1. Token 6:3.3333
2. Token 8:2.7778
3. Token 1:2.2222
4. Token 9:2.0000
5. Token 2:1.6667其他 token 的得分较低,不被考虑
3. softmax 概率计算
为了得到概率分布,首先确定候选集合中最大的值: m a x l = 3.3333 maxl = 3.3333 maxl=3.3333(来自 Token 6)
然后对每个候选 token 计算:
p i = exp ( s c a l e d _ l o g i t i − m a x l ) p_i = \exp(scaled\_logit_i - maxl) pi=exp(scaled_logiti−maxl)
计算结果(近似值):
- Token 6: exp ( 3.3333 − 3.3333 ) = exp ( 0 ) = 1.0 \exp(3.3333 - 3.3333) = \exp(0) = 1.0 exp(3.3333−3.3333)=exp(0)=1.0
- Token 8: exp ( 2.7778 − 3.3333 ) = exp ( − 0.5555 ) ≈ 0.5738 \exp(2.7778 - 3.3333) = \exp(-0.5555) \approx 0.5738 exp(2.7778−3.3333)=exp(−0.5555)≈0.5738
- Token 1: exp ( 2.2222 − 3.3333 ) = exp ( − 1.1111 ) ≈ 0.3293 \exp(2.2222 - 3.3333) = \exp(-1.1111) \approx 0.3293 exp(2.2222−3.3333)=exp(−1.1111)≈0.3293
- Token 9: exp ( 2.0000 − 3.3333 ) = exp ( − 1.3333 ) ≈ 0.2636 \exp(2.0000 - 3.3333) = \exp(-1.3333) \approx 0.2636 exp(2.0000−3.3333)=exp(−1.3333)≈0.2636
- Token 2: exp ( 1.6667 − 3.3333 ) = exp ( − 1.6666 ) ≈ 0.1889 \exp(1.6667 - 3.3333) = \exp(-1.6666) \approx 0.1889 exp(1.6667−3.3333)=exp(−1.6666)≈0.1889
总和 S = 1.0 + 0.5738 + 0.3293 + 0.2636 + 0.1889 ≈ 2.3556 S = 1.0+0.5738+0.3293+0.2636+0.1889 \approx 2.3556 S=1.0+0.5738+0.3293+0.2636+0.1889≈2.3556
归一化后,每个 token 的概率为:
- Token 6: 1.0 / 2.3556 ≈ 0.4244 1.0 / 2.3556 \approx 0.4244 1.0/2.3556≈0.4244
- Token 8: 0.5738 / 2.3556 ≈ 0.2435 0.5738 / 2.3556 \approx 0.2435 0.5738/2.3556≈0.2435
- Token 1: 0.3293 / 2.3556 ≈ 0.1398 0.3293 / 2.3556 \approx 0.1398 0.3293/2.3556≈0.1398
- Token 9: 0.2636 / 2.3556 ≈ 0.1119 0.2636 / 2.3556 \approx 0.1119 0.2636/2.3556≈0.1119
- Token 2: 0.1889 / 2.3556 ≈ 0.0802 0.1889 / 2.3556 \approx 0.0802 0.1889/2.3556≈0.0802
4. Top-P 截断
设置的 top-p 等于 0.9,表示我们只希望候选 token 的累积概率至少达到 90%
从上述排序后的候选开始累积概率
- 加入 Token 6:累积概率 = 0.4244
- 加入 Token 8:累积概率 = 0.4244 + 0.2435 = 0.6679
- 加入 Token 1:累积概率 = 0.6679 + 0.1398 = 0.8077
- 加入 Token 9:累积概率 = 0.8077 + 0.1119 = 0.9196
当加入 Token 9 后累积概率超过 0.9,因此,将候选集合截断为前 4 个 token:Token 6,Token 8,Token 1,Token 9。Token 2 被舍弃
接下来,对剩下的 4 个 token 的概率重新归一化。它们原累积概率为 0.9196,归一化因子为 1 / 0.9196 ≈ 1.0870 1/0.9196 \approx 1.0870 1/0.9196≈1.0870:
- Token 6: 0.4244 × 1.0870 ≈ 0.4617 0.4244 \times 1.0870 \approx 0.4617 0.4244×1.0870≈0.4617
- Token 8: 0.2435 × 1.0870 ≈ 0.2650 0.2435 \times 1.0870 \approx 0.2650 0.2435×1.0870≈0.2650
- Token 1: 0.1398 × 1.0870 ≈ 0.1519 0.1398 \times 1.0870 \approx 0.1519 0.1398×1.0870≈0.1519
- Token 9: 0.1119 × 1.0870 ≈ 0.1219 0.1119 \times 1.0870 \approx 0.1219 0.1119×1.0870≈0.1219
最终总体候选概率约为:
- Token 6:46.17%
- Token 8:26.50%
- Token 1:15.19%
- Token 9:12.19%
5. 离散分布采样
利用上面的 4 个候选 token 的归一化概率构造一个离散分布。函数调用标准库 std::discrete_distribution<>,并使用传入的随机数生成器 rng 根据该分布采样出一个索引
假设采样结果得到的索引为 0,那么对应的候选 token 就是 Token 6,函数最后返回此 token id 即 6
OK,这就是模型推理与文本采样生成的整体过程了
至此,我们算简单过了一遍 ggml 框架推理 gpt-2 的整体流程,主要包括模型加载、预分配计算图内存、分词以及模型推理与生成
结语
这里我们完整的过了一遍 ggml 推理 gpt-2 的整体流程,之后再来阅读 llama.cpp 时会相对轻松些
其实博主对 ggml 整个框架的设计并不了解,只是表面上随着代码完整的 debug 了一遍,那如果想要深入的学习了解 ggml 这个框架,可能需要从框架设计方式出发去理解它,为什么要这么设计,有什么优点
博主能力有限,所有也就带着大家简单过了一遍,大部分都是 ChatGPT 分析的结果,真正理解的少之又少,其中的一些内容分析可能有误,博主也没有完全理解,更多的细节可能需要大家自己深入研究分析了
大家感兴趣的可以看看 UP 的视频讲解,还是非常不错的🤗