刷题day_15,继续加油!!!
一、平方数
题目解析
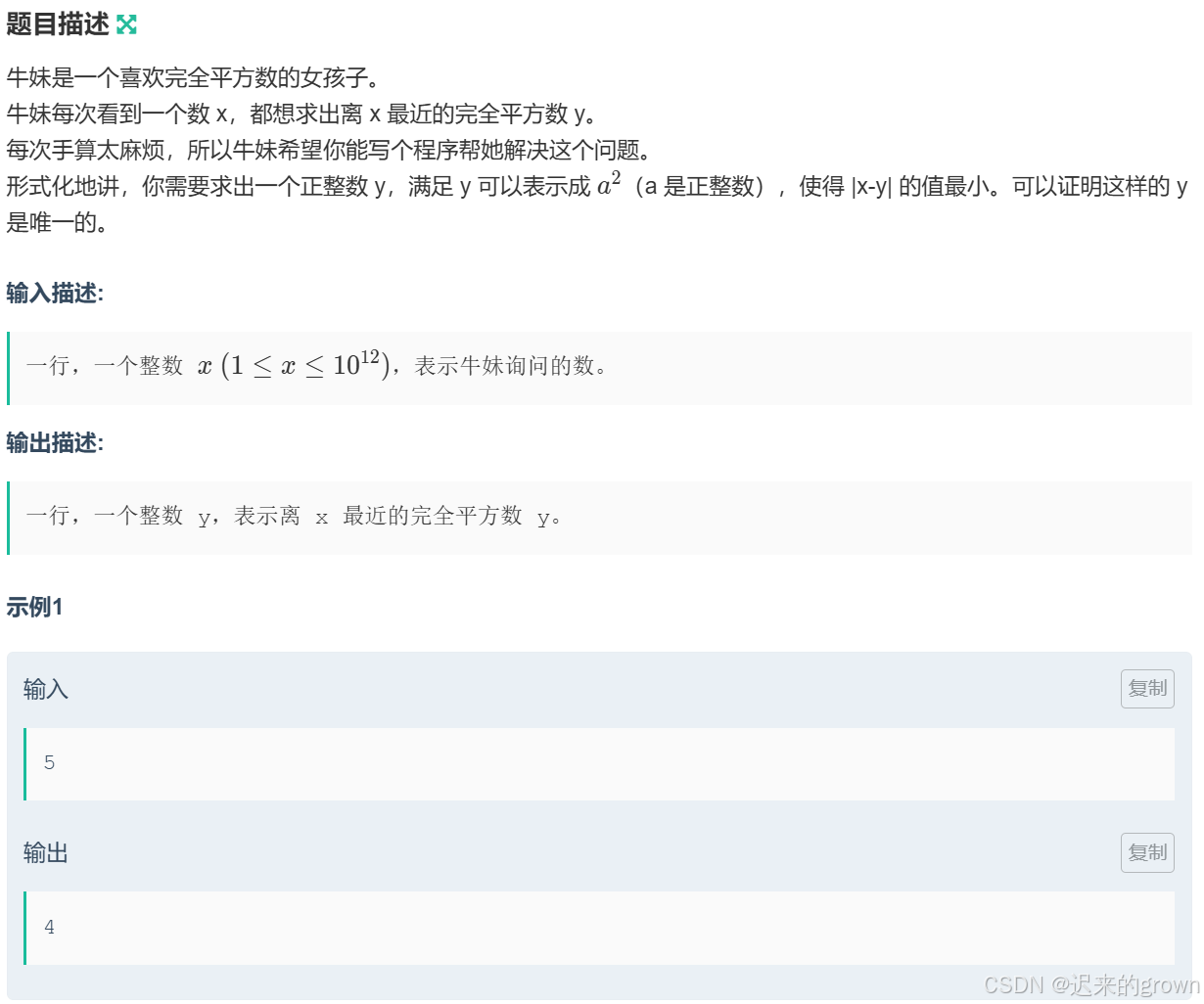
题目给出一个数,让我们找到离它最近的一个平方数,然后输出即可。
算法思路
这道题总体来说还是非常简单的。
这里先来看一种思路,就是从1开始找,找到小于x的最大的平方数l和大于x的最小的平方数r;然后判断r-x和x-l中哪一个最小即可。
但是,主播主播你的这种思路确实能解决问题,但还是太麻烦了,有没有更加简单易上手的方法;
有的兄弟有的,我们不妨来看看这种思路:
我们知道
sqrt函数可以对一个数进行开根号预算,它会返回一个double类型是数据;那我们对这个返回值强转一下,转成整型不就拿到
l,再对其加一就拿到了r。这样我们这个数是在区间
[l*l , r*r]内的,我们判断r*r - x和x - l*l哪一个最小即可。
代码实现
cpp
#include<iostream>
#include<cmath>
using namespace std;
int main()
{
long long x;
cin>>x;
long long a = sqrt(x);
long long l = a*a, r = (a+1)*(a+1);
if(x-l > r-x)
cout<<r<<endl;
else
cout<<l<<endl;
return 0;
}二、分组
题目解析

题目描述:我们现在要对同学们进行分组,每一个同学都擅长一个声部;我们要将擅长同一个声部是同学分到一个组(不同组的同学可以擅长同一个分部);
我们想要每一个组的同学数量尽可能少,如果我们能够顺利安排就输出 组中同学数量最多的人数;否则输出
-1。
转换成底阿妈思想就是:
输入
n,m,表示一共n个人,我们要分成m个组;其次的n个数,表示每一个同学它擅长的声调。
算法思路
那这道题,我们如何去写呢?
首次看到这道题,博主有一种思路:
首先记录擅长同一个音调的人的数量;
然后将这些数量放入到
堆中,我们先把擅长同一个声调的同学分到一个组;如果此时的组数要大于m就表示我们没办法顺利分组,就输出1。然后我们堆中存放的就是每一组同学的数量,取出来堆顶数据,然后将它分成两组,再放回到堆中。(这一个操作可以理解为:每次将同学数最多的组别分成两组)
重复取出来堆顶数据,分成两组然后放回堆中,知道我们堆中的数据个数等于
m;此时我们堆顶数据就是所有组中,同学数量最多的组别的同学数。
但是,这里博主的想法是错误的,博主这里只是简单记录一下自己当时的想法。
现在我们来看这道题的解决思路:
对于这道题,我们直接根据擅长每一个声调的人数去找这些同学要分成多少组,那肯定不现实的;
如果我们擅长一个声调的有
k人,那我们就要分1,2,3... k组,k中情况,再算上其他组的各种情况,那可想而知有多麻烦了。
既然,我们根据擅长每一个声调的人数去找分成多少组不行,那我们就根据每一个组的人数,去找擅长每一个声调的人可以分成多少组。
假设我们现在每一个组中最多有
x人,假设擅长某一个声调的人数为y,那我们就可以将y分成y/x个组(注意,我们这里y不一定能被x整除,如果不能整除,我们就要多分一个组 )所以应该分成y/x + (y%x==0?0:1)个组。那我们记录了擅长每一个声调的人数,那我们在求一下擅长同一个声调能够分成多少组,求出来每个组有最多
x个人时,需要多少组;我们求出的需要的组数
sum,如果sum>m就说明我们的x取小了,我们就要将x取的大一点再求需要的组数;这样直到
sum<=m时,我们就找到了人数最多的小组人数最小的情况,然后返回即可。
这里我们取x的值,从·1`开始,直到擅长某个声调最多的人数,可以使用暴力枚举,但是这样可能会超时。
这里我们在仔细分析一下:
当我们
x取小了,即sum > m时,我们就要取x大一点的数(在区间[x + 1 , hmax]中取);如果x取大了,即sum < m,那我们就让x小一点,在区间[1 , x]中取;
看到这里相信已经看出来如何去优化了,那就是二分;
在区间
[1 , hmax]中,我们求出来的sum是递减的,那我们就可以使用二分去查找满足条件中最小的sum

代码实现
在实现代码之前,我们先来理清思路(上面描述一些乱)
- 首先我们要先统计擅长每一种声调的人数,并且也要找到擅长某一种声调人数的最大值
hmax。- 然后就是实现一个
check函数,它用来判断使用x求出来的sum是否小于等于m。- 在利用二分查找之前,先进行一下判断,如果
cnt.size()>m就表示我们声调的种类大于要分的组数,那一定不能完成任务;输出-1即可。- 最后就是使用二分,然后去找到满足条件中最小的
sum。这里二分: ,当我们用
x求出来的sum是小于等于m时,我们让right = mid,而不是mid - 1(因为可能前面求出来的sum是等于m的)。
cpp
#include<iostream>
#include<unordered_map>
using namespace std;
int n,m;
unordered_map<int,int> cnt;
bool check(int x)
{
int sum = 0;
for(auto& e:cnt)
{
sum +=(e.second/x + (e.second%x == 0?0:1));
}
return sum<=m;
}
int main()
{
cin>>n>>m;
int hmax = 0;
for(int i=0;i<n;i++)
{
int x;
cin>>x;
cnt[x]++;
if(cnt[x]>hmax)
hmax = cnt[x];
}
if(cnt.size()>m)
cout<<-1<<endl;
//二分
else
{
int left = 1, right = hmax;
while(left<right)
{
int mid = (left+right)/2;
if(check(mid))
right = mid;
else
left = mid + 1;
}
cout<<left<<endl;
}
return 0;
}三、【模板】拓扑排序
题目解析
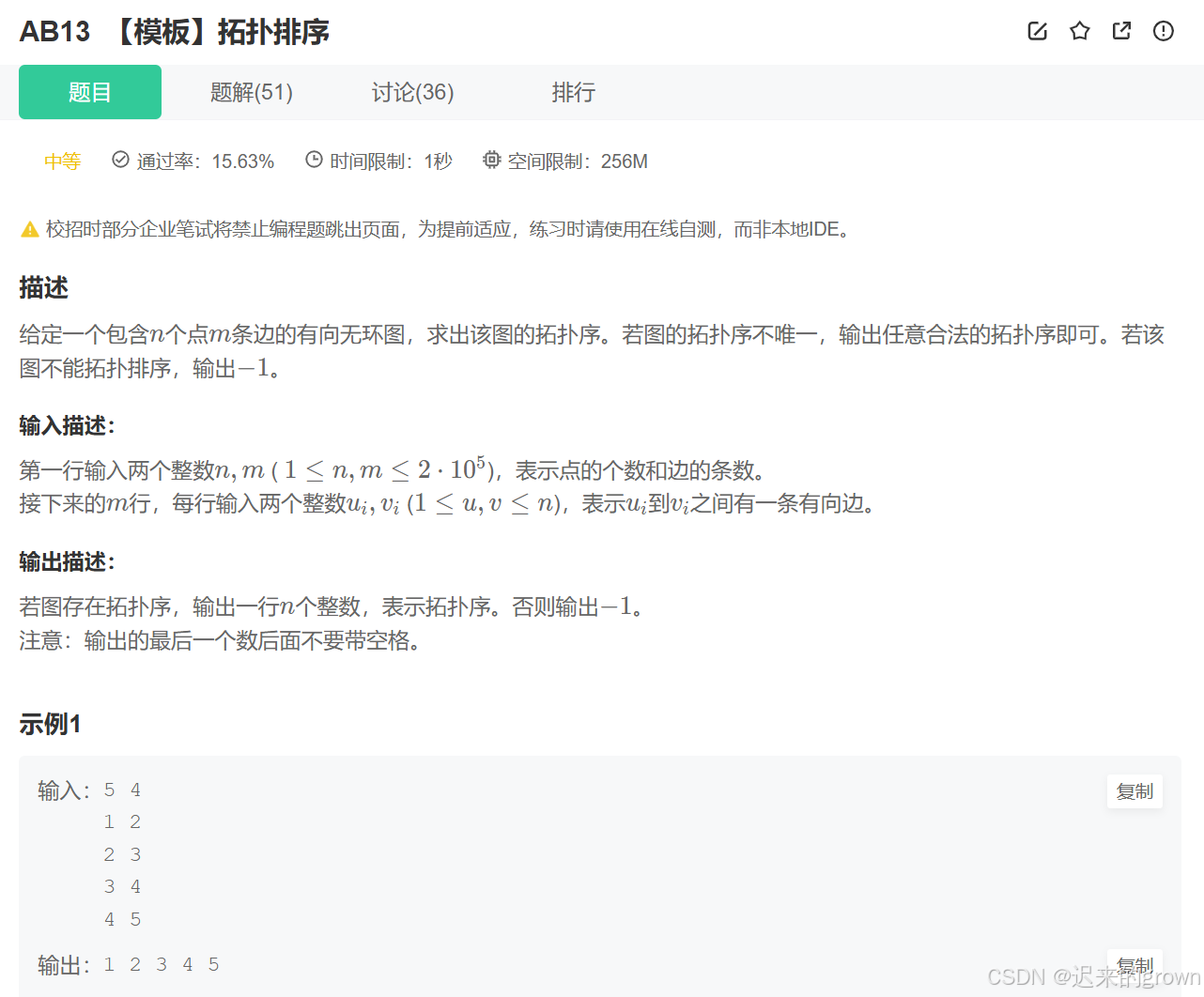
这道题没有任何弯弯绕绕,直接就考查拓扑排序,给我们一个包含
n条边的有向无环图,然我们输出该图的拓扑排序;**输入:**首先输入
n、m表示点的个数和边的个数,然后m行输入两个整数v1,v2表示v1到v2之间有一条有向边。
算法思路
这里先简单看一下我们如何输出一个有向无环图的拓扑排序:
首先在图中选择一个入度为
0的节点,并输出该节点;然后将这个节点从图中删除,并且删除所有以该节点为顶点的有向边。
重复操作,摘到输出图中的所有节点。
以图中示例来说:

那现在我们来看代码如何去实现:
在上述描述中,我们需要记录每一个有向边,还要记录每一个节点的入度,为了能实现拓扑排序,我们这里使用quque
记录每一个有向边:
vector<vector<int>>,下标表示每一个有向边的起点,i位置的vector<int>表示从i位置到其他节点的有向边。记录每一个节点的入度:使用
hash来记录即可。
queue:这里queue的作用就是存放当前节点,然后进行删除当前节点和以当前节点开始的有向边,然后找到入度为0的节点放入queue中。记录结果:使用
vector<int> ret来记录结果,如果最后ret中数据个数等于n就说存在拓扑排序,就输出;否则输出-1。
代码实现
这里有应该坑,就是输出结果时,最后面不能有空格。
cpp
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
int main() {
int n, m;
cin >> n >> m;
vector<vector<int>> arr(n + 1);
vector<int> hash(n + 1);
for (int i = 0 ; i < m; i++) {
int x, y;
cin >> x >> y;
hash[y]++;
arr[x].push_back(y);
}
//找到度为0的节点
queue<int> q;
for (int i = 1; i <= n; i++) {
if (hash[i] == 0)
q.push(i);
}
vector<int> ret;//记录最终结果
while (!q.empty()) {
int x = q.front();
q.pop();
ret.push_back(x);
//删除x节点和所有x开始的有向边
for (auto& e : arr[x]) {
hash[e]--;
if (hash[e] == 0) {
q.push(e);
}
}
}
//输出结果
//如果ret中数据个数等于n就说明存在拓扑排序
//这里有一个坑:最后一个字符的后面不要输出空格
if (ret.size() == n) {
for (int i = 0; i < ret.size(); i++) {
cout << ret[i];
if (i < ret.size() - 1)
cout << ' ';
}
} else {
cout << -1 << endl;
}
return 0;
}到这里本篇文章内容就结束了
感谢各位的支持
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=2oul0hvapjsws