一、Elasticsearch是什么?
- Elasticsearch 是一款强大的
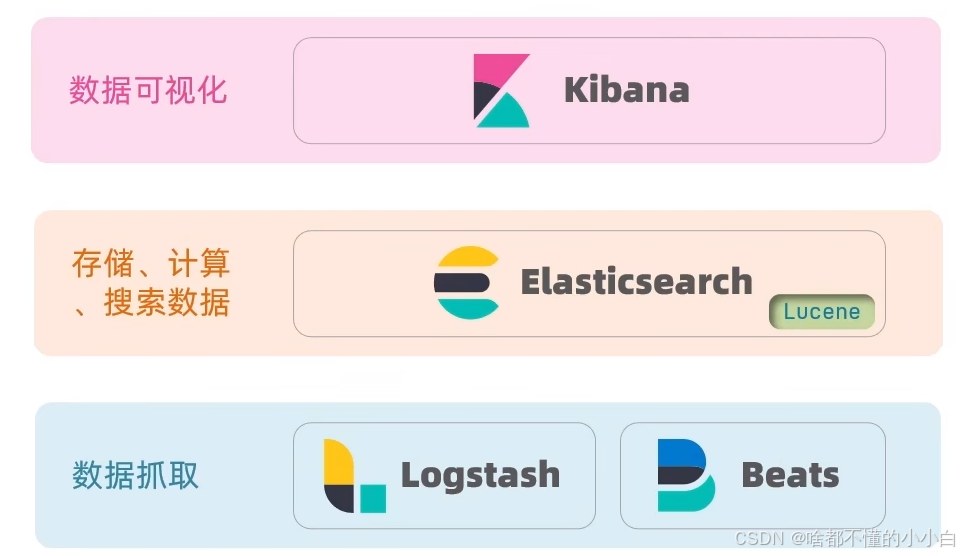
开源搜索引擎,可以帮助我们快速从海量数据中找到所需内容。 - 它与 Kibana、Logstash、Beats 共同组成 Elastic Stack (ELK),广泛应用于日志分析和实时监控。
- Elasticsearch 是 Elastic Stack 的核心,负责数据的存储、搜索和分析。
核心功能:
- 🔍 快速检索:支持关键词、模糊、地理位置等多种搜索方式
- 📊 数据分析:聚合统计、数据可视化(配合Kibana)
- ⚡ 实时处理 :日志监控、实时预警(配合Logstash)
elasticsearch的发展
- Lucene :由 Doug Cutting 于 1999 年开发,是一个 Java 搜索引擎库,官网:Lucene。
- 优势:易扩展、高性能(基于倒排索引)。
- 缺点:限于 Java 语言,学习曲线陡峭,不支持水平扩展。
- 2004 年,Shay Banon 基于 Lucene 开发了 Compass。
- 2010 年,Shay Banon 重写 Compass,命名为 Elasticsearch,官网:Elastic。
- 优势:支持分布式和水平扩展,提供 RESTful 接口,可被多种语言调用。
搜索引擎技术排名:
1.Elasticsearch:开源的分布式搜索引擎
2.Splunk:商业项目
3.Solr:Apache的开源搜索引擎
基本概念介绍
正向索引和倒排索引
什么是文档和词条?
- 文档( document) :每条数据就是一个文档,es中是Json格式
- 词条(term) :文档中按照语义划分的词语。
什么是正向索引?
- 基于文档id创建索引,查询时需先找到文档,再判断是否包含词条。
什么是倒排索引(Inverted Index?
- 对文档内容进行分词,记录词条及其所在文档。查询时先通过词条找到文档 ID,再获取文档内容。
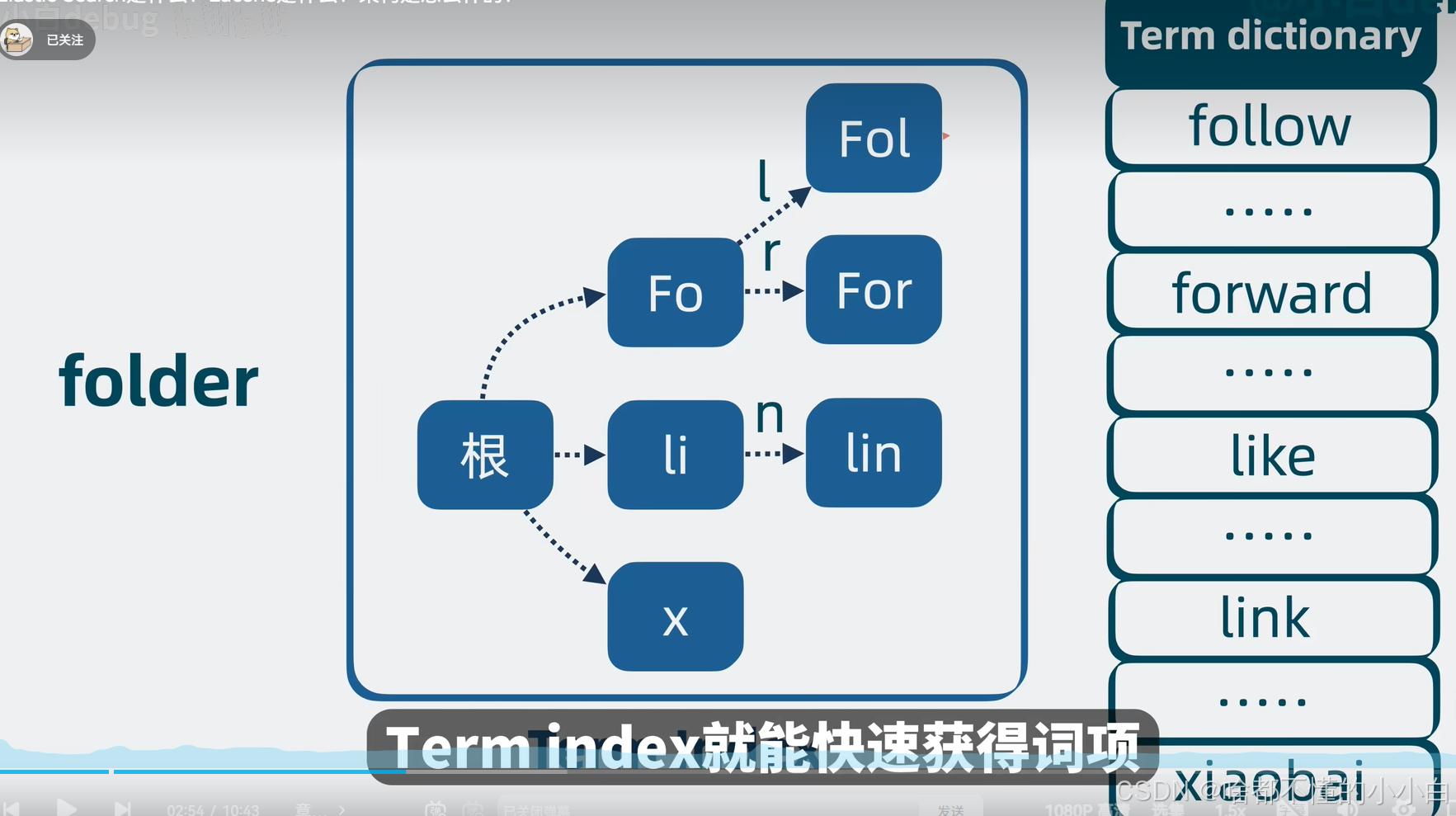
词条索引(Term Index) 通过词条前缀构建目录索引
词条和词条之间,有些前缀是一样的,比如follow和forward前面的fo是一致的,如果将部分term前缀提取出来,就可以用更少的空间表达更多的term。
利用这些词条的前缀信息,可以构建出一个精简的目录树。目录树的节点存放这些词条在磁盘中的偏移量,也就是指向磁盘中的位置。这个目录树结构,体积小,适合放在内存中,就是所谓的term index. 可以用它来加速搜索。
存储结构
- Stored Fields:行式存储,存放完整文档内容。
- Doc Values :用于排序和聚合,将散落在文档中的字段集中存放,以提高排序效率。

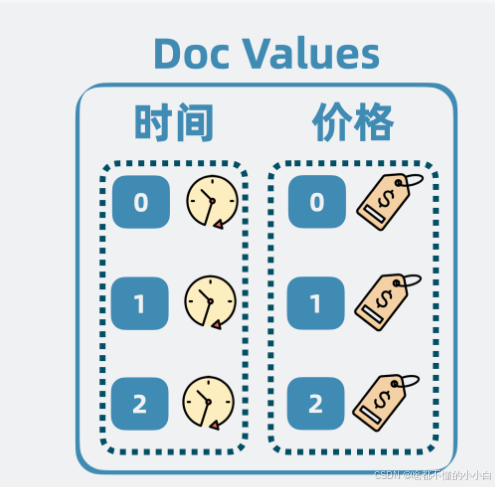
当用户经常需要根据某个字段排序文档,比如按时间排序或商品价格排序。但问题来了,这些字段散落在文档里,也就是说,要先获取Stored Fields里的文档,再提取出内部字段进行排序,比较耗时。
可以用空间换时间的思路,再构造一个列式存储结构,将将散落在各个文档的某个字段,集中存放。当我们想要对某个字段排序的时候,就只需要将这些集中存放的字段一次性取出来,就能做到针对性地进行排序。
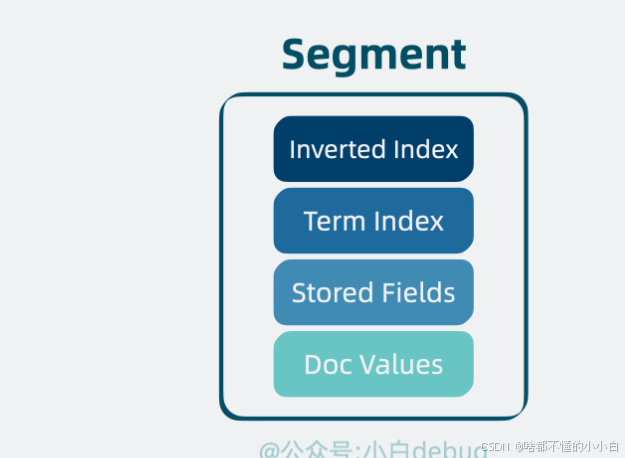
Segment
倒排索引用于搜索,Term Index 用于加速搜索,Stored Fields 用于存放文档的原始信息,以及 Doc Values 用于排序和聚合。这些结构共同组成了一个复合文件,也就是所谓的"segment", 它是一个具备完整搜索功能的最小单元。
概念名词介绍 es VS MySQL
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| 表(Table) | 索引(Index) | 存储同类型数据,索引是文档的集合,类似数据库的表 |
| 行(Row) | 文档(Document) | 一条条数据,类似数据库的行,文档是JSON格式 |
| 列(Column) | 字段(Field) | JSON文档中的字段,类似数据库的列 |
| Schema | Mapping | Mapping是索引中文档的约束,例如字段类型约束。类似数据库的表结构 |
| SQL | DSL | SQL是es提供的JSON风格的请求语句,用来操作es,实现CRUD |
elasticsearch与数据库的关系:
- Mysql:数据库负责
事务类型操作,可以确保数据的安全和一致性 - elasticsearch:负责海量数据的
搜索、分析、计算
10分钟快速入门
安装elasticsearch
1.部署单点es(docke安装es
2.部署kibana(docker安装kibana
3.安装ik分词器
分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但 默认的分词规则对中文处理并不友好。
我们在kibana的DevTools中测试:
clike
POST /_analyze
{
"analyzer": "standard",
"text": "黑马程序员 学习java太棒了! "
}结果:黑,马,程,序,员,学,习,java,太,棒,了
语法说明:
- POST:请求方式
- / _analyze:请求路径,这里省略了http://192.168.150.101:9200,有kibana帮我们补充
- 请求参数,json风格
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
问题:英文分词有空格间隔,但中文分词要根据语义分词有难度
处理中文分词一般采用ik分词器
下载IK分词器 https://github.com/medcl/elasticsearch-analysis-ik/releases
tip: 里面是各种jar包,下载完成后放在es的plugins目录下,重新启动es
ik分词器
中文分词往往需要语义分析,比较复杂,这就需要用到中文分词器,例如ik分词器。ik分词器是林良益在2006年开源发布的,其采用的正向迭代最细粒度切分算法一直沿用至今。
安装方式也比较简单,将分词器放入elasticsearch的插件目录即可
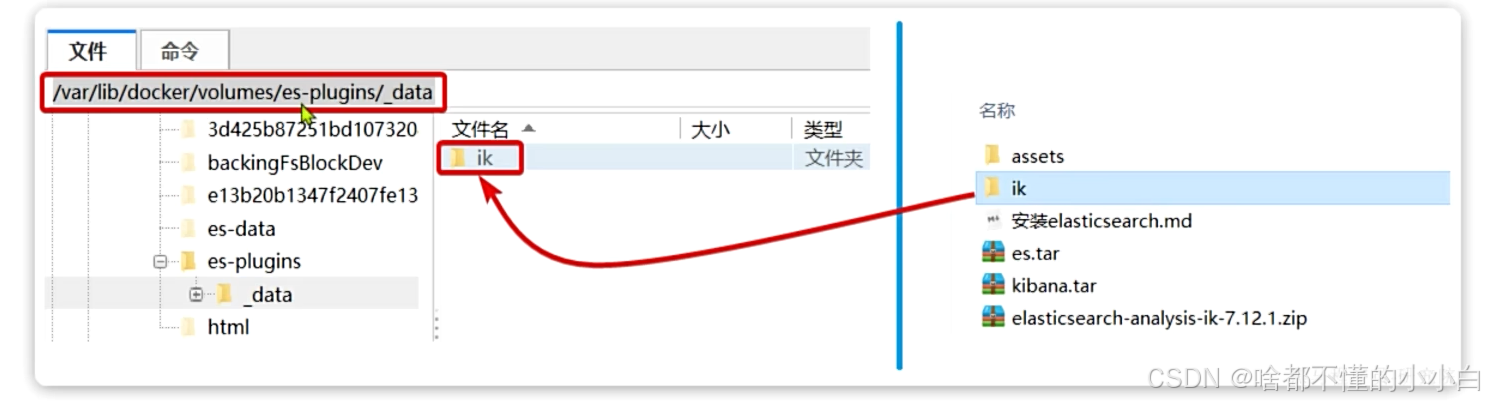
docker安装ik分词器(推荐离线安装,在线安装比较慢
clike
#1.查看数据卷目录
docker volume inspect es-plugins
#2.解压缩分词器安装包,上传解压后的ik目录到es-plugins挂在的目录
#3.重启容器
docker restart es
#4.查看es日志
docker logs -f esik分词器包含两种模式
ik_smart:最少切分 ==> 黑马,程序员,学习,java,太棒了ik_max_work:最细切分 ===> 黑马,程序员,程序,员,学习,java,太棒了,太棒,了
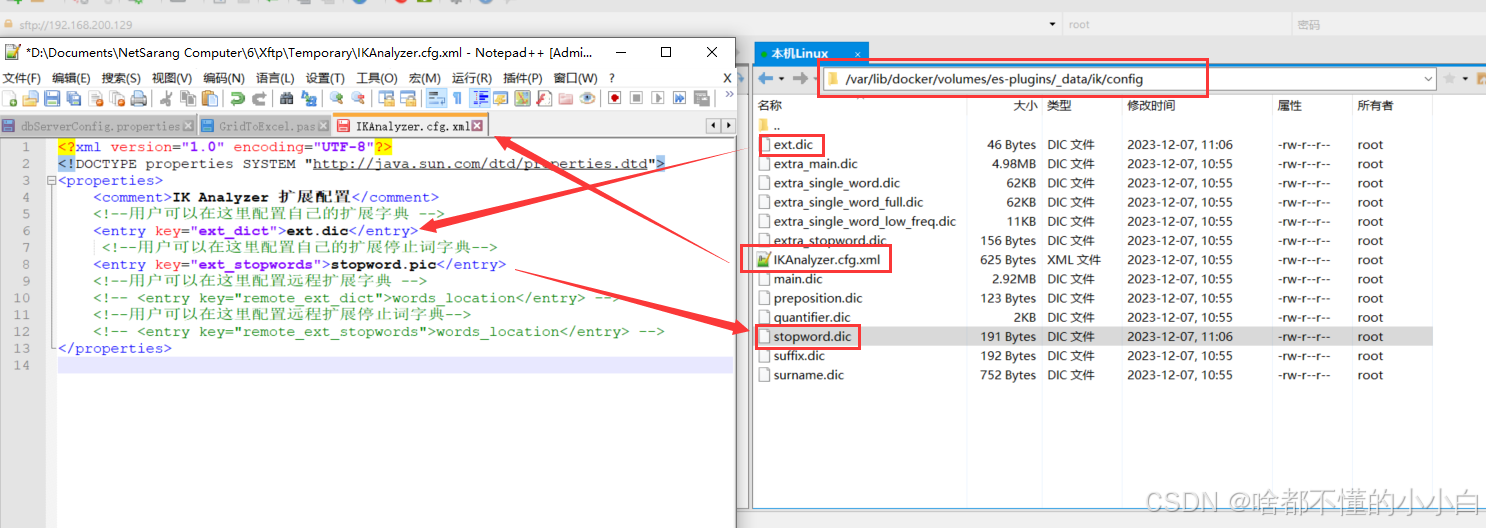
ik分词器-扩展字典和停用字典
要拓展和停用ik分词器的词库,只需要修改一个ik分词器目录中的**/var/lib/docker/volumes/es-plugins/_data/ik/config**目录中的IkAnalyzer.cfg.xml文件:

二、 索引库操作
mapping映射属性
mapping是对索引库中文档的约束
参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/dynamic-mapping.html

- mapping补全属性:serach_analyzer(搜索分词器)
- type扩展属性:Completion(补全)
索引库的CRUD
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库: GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库之添加字段: PUT /索引库名/_mapping
创建索引库
clike
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type":"object",
"properties": {
"firstName":{
"type":"keyword"
},
"lastname":{
"type":"keyword"
}
}
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

修改索引库

三 、文档操作
创建文档
clike
POST /索引库名/_doc #使用系统生成id
POST /索引库名/_create/1 #使用指定id, 存在则创建失败
POST /索引库名/_doc/1 #使用指定id,不存在创建,存在更新(版本递增)请求体数据:
clike
POST /heima/_doc/1
{
"email" : "zy@itcast.com",
"info" : "黑马程序员java老师",
"name":{
"firstName":"云",
"lastName":"赵"
}
}查询文档
clike
GET /索引库名/_doc/1查询单个文档
clike
GET /索引库名/_search查询全部文档,条件查询
clike
GET /索引库名/_search?q=info:java删除文档
clike
DELETE /索引库名/_doc/1
#查询出所有数据并清空
POST hotel/_delete_by_query
{
"query": {
"match_all": {}
}
}修改文档
1.修改文档(全量修改,会删除旧文档,添加新文档):能做新增,也能做修改
clike
PUT /索引库名/_doc/文档id
{
"name" : "springboot",
"type" : "springboot",
"description":"springboot"
}2.修改文档( 部分修改)
clike
POST /索引库名/_update/1
{
"doc" : {
"name" : "springboot"
}
}批量处理
ElasticSearch中允许通过一次请求中携带多次文档操作,也就是批量处理,语法格式如下:

- _index :指定要删除的索引库名
- _id :指定要操作的文档id