🔥 Rust 中的内存重排演示:X=0 && Y=0 是怎么出现的?
在并发编程中,我们经常会听说"内存重排(Memory Reordering)"这个术语,但它似乎总是只出现在理论或者别人口中的幻觉里。本文将通过一段简短却强大的 Rust 代码,来实际观察一次可能只发生在 CPU 和编译器角落的"神秘现象"。
🧪 实验目标
我们想要验证这样一件事:
在两个线程中,即使我们明确写入了某个变量的值,另一个线程仍可能读不到这个值,甚至两个线程都没看到对方的写入!
这似乎违背常识,但在 Relaxed 的内存模型下,这种事情确实会发生。
🧬 测试代码
我们从一个经典的"双线程数据交换"模型出发,使用 Rust 中的原子类型构造以下测试:
rust
use std::sync::atomic::{AtomicBool, AtomicI32, Ordering};
use std::sync::Arc;
use std::thread;
// 两个变量
static A: AtomicI32 = AtomicI32::new(0);
static B: AtomicI32 = AtomicI32::new(0);
// 两个线程读取的结果
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
#[test]
fn t() {
let mut count = 0;
loop {
A.store(0, Ordering::Relaxed);
B.store(0, Ordering::Relaxed);
X.store(0, Ordering::Relaxed);
Y.store(0, Ordering::Relaxed);
let t1 = thread::spawn(|| {
// 操作2 可能被重排到操作1前面
A.store(1, Ordering::Relaxed); // 操作1
let y = B.load(Ordering::Relaxed); // 操作2
X.store(y, Ordering::Relaxed); // 操作3
});
let t2 = thread::spawn(|| {
// 操作5 可能被重排到操作4前面
B.store(1, Ordering::Relaxed); // 操作4
let x = A.load(Ordering::Relaxed); // 操作5
Y.store(x, Ordering::Relaxed); // 操作6
});
// 可能的结果:
// t1 执行完了 t2 再执行 结果:X:0 Y:1
// t2 执行完了 t1 再执行 结果:X:1 Y:0
// t1 执行过程中,t2 也执行 结果:X:1 Y:1
// t2 执行过程中 , t1 也执行 结果:X:1 Y:1
// t1 t2 同时执行,在多核cpu上 一个线程一个核
// 结果也是 X:1 Y:1
// 等待线程结束 才往下执行
t1.join().unwrap();
t2.join().unwrap();
let x = X.load(Ordering::Relaxed);
let y = Y.load(Ordering::Relaxed);
count += 1;
if x == 0 && y == 0 {
println!("🔥 Reordering observed after {} iterations! X={}, Y={}", count, x, y);
break;
}
if count % 1_000_000 == 0 {
println!("Still testing... {} iterations", count);
}
}
}运行
bash
cargo test "memOrder::Relaxed::t" --release -- --exact --nocapture
# 不建议使用debug来查看,如果没有优化,很难看到
# "memOrder::Relaxed::t" 是模块的路径。这里得看你的文件是如何写的。可以问问AI你的应该如何填写
# --release 使用优化的版本。不是debug的版本
# --nocapture 禁止捕获输出,这样可以看到test的输出语句复现了 在第1百万次之后
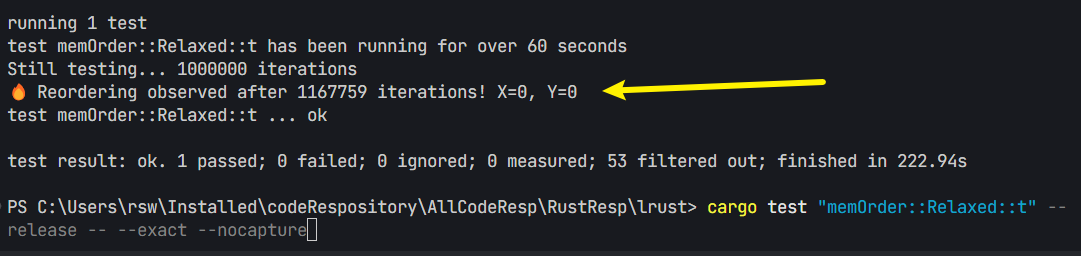
🤯 为什么 X0 && Y0 会发生?
✅ 预期行为
我们按常理推理,至少会有一个线程看到另一个线程的写入。可能的结果包括:
X=1, Y=1:两边都看到写入(最常见)X=1, Y=0或X=0, Y=1:一个看到,一个没看到- ❌
X=0, Y=0:理论上"不可能",却实实在在发生了
🧠 背后发生了什么?
这是内存模型中最令人着迷的部分。
1️⃣ 编译器重排
在 Relaxed 模式下,编译器允许重新排序读写操作,比如:
rust
// 原代码:
A.store(1);
let y = B.load();
// 实际可能被编译器优化为:
let y = B.load();
A.store(1);2️⃣ CPU 层级的乱序执行
即便编译器没优化,CPU 在执行指令时也可能提前执行 load 操作(出于缓存命中率、流水线等优化考虑)。
3️⃣ 多核之间的缓存不可见性
每个 CPU 核心有自己的缓存,如果线程运行在不同核心上,而缓存同步还没完成,就会出现这种"看不到对方写入"的情况。
🚨 为什么这很危险?
如果你在业务代码中用 Relaxed 来实现同步(比如某种状态机、标志位),那你可能看到的状态并不是你以为的那样。更严重的,在某些极端时机下,程序可能出现奇怪的崩溃、断言失败,或者数据一致性问题。
✅ 如何避免这种问题?
使用合适的内存顺序,比如:
- 使用
Ordering::Release写入 - 使用
Ordering::Acquire读取
这可以确保"写操作在读取操作前发生",编译器和 CPU 都不会乱排:
rust
A.store(1, Ordering::Release);
let y = B.load(Ordering::Acquire);这样写可以防止 x == 0 && y == 0 这种现象出现。
🧵 延伸:这个实验很有意思!
你可以试着:
- 多跑一会儿,看看多少次能复现一次
0, 0 - 改成
SeqCst观察结果 - 用 barrier(内存屏障)代替 Ordering
- 在不同平台(ARM vs x86)测试效果(ARM 更容易复现)