目录
[(3)自定义 Dataset 示例](#(3)自定义 Dataset 示例)
[1、transforms 常用类](#1、transforms 常用类)
[2、使用 transforms.Compose 组合多个转换](#2、使用 transforms.Compose 组合多个转换)
[3、transforms 的 ToTensor 类](#3、transforms 的 ToTensor 类)
[(1)为什么在pytorch中要把数据类型转化为 tensor?](#(1)为什么在pytorch中要把数据类型转化为 tensor?)
[(2)transforms 的 ToTensor 类的使用](#(2)transforms 的 ToTensor 类的使用)
[五、 torchvision 中的 datasets](#五、 torchvision 中的 datasets)
[2、torchvision.datasets 中常见数据集说明](#2、torchvision.datasets 中常见数据集说明)
[(1)CIFAR10 和 CIFAR100](#(1)CIFAR10 和 CIFAR100)
(4)COCO (Common Objects in Context)
(5)LSUN (Large Scale Scene Understanding)
(7)CelebA (CelebFaces Attributes)
(8)SVHN (Street View House Numbers)
(9)VOC (PASCAL Visual Object Classes)
[(1)查看 DataLoader 输出的数据类型](#(1)查看 DataLoader 输出的数据类型)
[(2)将每个批都用 tensorboard 显示](#(2)将每个批都用 tensorboard 显示)
[七、Pytorch中神经网络模型搭建相关的python API](#七、Pytorch中神经网络模型搭建相关的python API)
[(1)torch.nn 和 torch.nn.functional](#(1)torch.nn 和 torch.nn.functional)
(3)torch.nn.functional.conv2d函数的使用
[(8)实战模型搭建及 nn.Sequential 的使用](#(8)实战模型搭建及 nn.Sequential 的使用)
[(9)使用 tensorboard 完成模型的可视化](#(9)使用 tensorboard 完成模型的可视化)
[十三、如何将上述模型转到 GPU 上进行训练](#十三、如何将上述模型转到 GPU 上进行训练)
一、python学习中两大法宝函数
1、dir()
功能:打开顶层的类,或者包,查看里边的子方法或包
例子:dir(torch):返回的是 PyTorch 的核心模块(torch)中的方法、类和属性。
2、help()
功能:提供说明书
例子:help(torch):会显示关于 PyTorch torch 模块的帮助文档。这个文档通常包括模块的简介、常用功能、方法、类等。
二、PyTorch读取数据集
主要涉及两个类:Dataset 和 Dataloader
1、Dataset类
每个 Dataset 对象都表示一个数据集,负责提供数据和标签。可以从 PyTorch 提供的许多现成的数据集类中继承,或者自己实现一个自定义的 Dataset。
(1)作用和基本原理
-
主要职责:定义如何读取单个数据样本。
-
基本接口:
-
__len__:返回数据集样本总数。 -
__getitem__:通过索引返回一个数据样本,通常包括数据本身和对应的标签。
-
(2)常见用法
-
继承
torch.utils.data.Dataset:用户可以继承该类并重写__len__和__getitem__方法,实现对自定义数据格式的支持。 -
内置数据集 :PyTorch 提供了很多内置的数据集,如
torchvision.datasets.MNIST、CIFAR10等,这些数据集已经封装好了数据读取逻辑。
(3)自定义 Dataset 示例
python
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data, labels, transform=None):
self.data = data
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample, label = self.data[index], self.labels[index]
# 若有需要,可进行数据转换
if self.transform:
sample = self.transform(sample)
return sample, label
# 示例数据
data = [i for i in range(100)]
labels = [i % 2 for i in range(100)]
dataset = MyDataset(data, labels)在这个示例中,我们定义了一个简单的数据集,用来说明如何实现 __len__ 和 __getitem__ 方法。
2、Dataloader类
DataLoader 是 PyTorch 中用于批量加载数据的工具。它可以将数据集分割成小批次(batch),并在训练时自动迭代这些小批次。
(1)作用和基本原理
-
主要职责:封装 Dataset 并进行批处理、打乱数据、并行加载以及内存优化(如 pin_memory)等操作。
-
接口参数:
-
batch_size:每个 batch 的样本数。 -
shuffle:是否在每个 epoch 开始前打乱数据。 -
num_workers:使用多少个子进程来加载数据,默认是 0(即在主进程中加载)。 -
collate_fn:用于将一个 batch 的样本组合成一个 mini-batch,可以自定义数据如何拼接。
-
(2)常见用法
-
批处理 :DataLoader 会根据
batch_size自动将样本组合成一个 batch,方便输入到模型中。 -
数据打乱 :通过
shuffle=True可以保证每个 epoch 的数据顺序不同,有助于模型训练的稳定性和泛化性。 -
多进程加载 :设置
num_workers>0后,DataLoader 会使用多个子进程来加速数据加载,尤其在数据预处理比较复杂时效果显著。
(3)使用示例
python
from torch.utils.data import DataLoader
# 创建 DataLoader
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4)
# 迭代数据
for batch_idx, (inputs, targets) in enumerate(dataloader):
# 这里可以将 inputs 和 targets 输入模型
print(f"Batch {batch_idx}: inputs {inputs}, targets {targets}")通过这个示例,可以看出 DataLoader 如何简化数据加载和批处理过程。
3、实际案例分析
(1)数据集格式介绍
常见的数据集文件格式为:
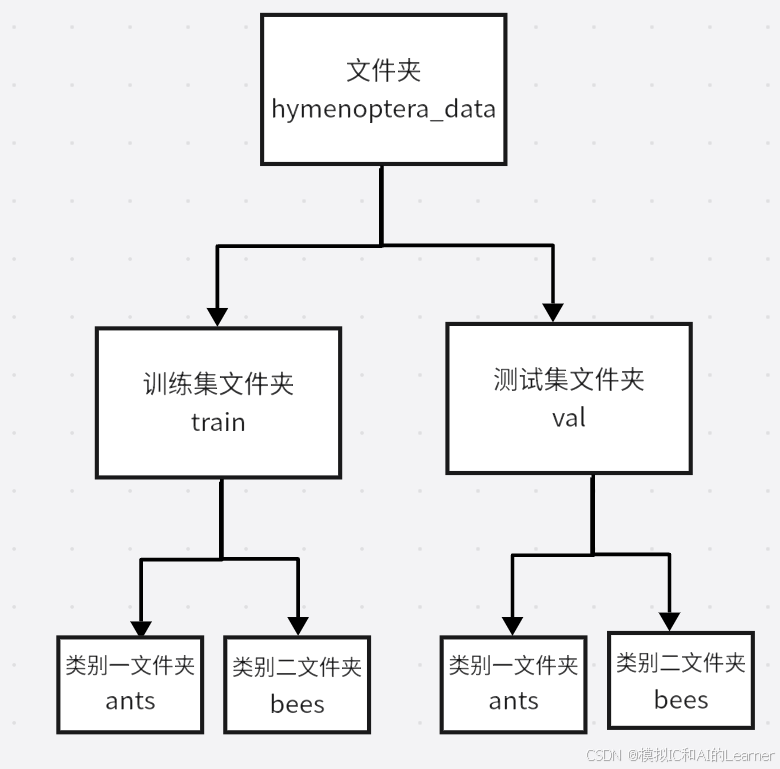
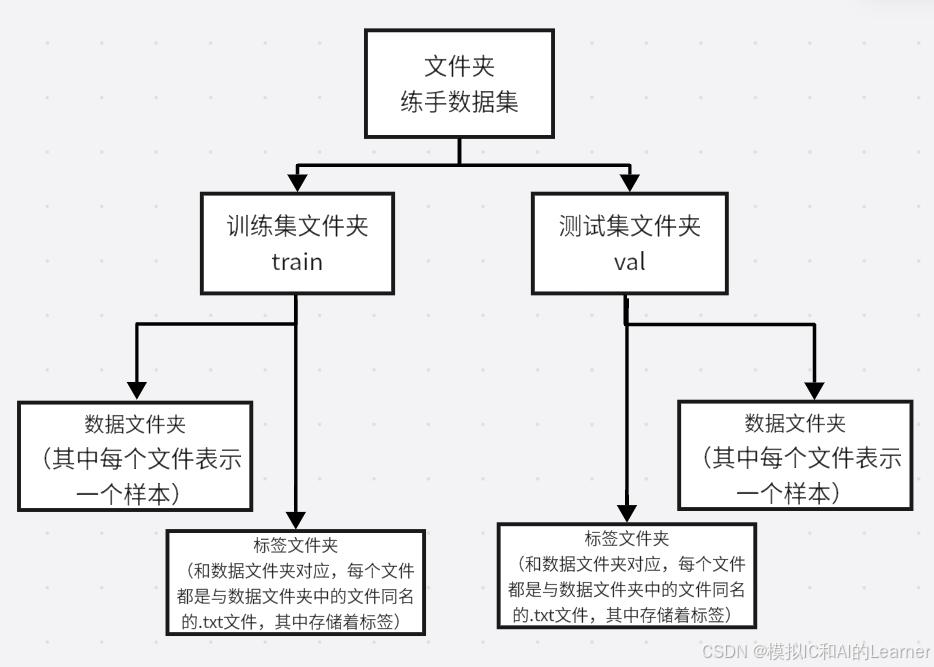
在这个案例中,数据集的格式为第一种:
下面为继承Dataset的类MyData
python
import torch
import os
from torch.utils.data import Dataset
from PIL import Image
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)实例化一个对象:
python
root_dir = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train"
ants_label_dir = "ants"
ants_dataset = MyData(root_dir,ants_label_dir)
img, label = ants_dataset[0]
import matplotlib.pyplot as plt
# 使用 matplotlib 显示图像
plt.imshow(img)
plt.axis('off') # 关闭坐标轴
plt.show()可见这个MyData类的功能是仅将训练集中的一个类别进行了实现,下面将训练集两个类都实现:
python
root_dir = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset = ants_dataset + bees_dataset
img, label = train_dataset[0]
import matplotlib.pyplot as plt
# 使用 matplotlib 显示图像
plt.imshow(img)
plt.axis('off') # 关闭坐标轴
plt.show()三、Tensorboard的使用
这里主要介绍 Tensorboard 中的类 SummaryWriter ,其功能是将 PyTorch 的训练过程中的数据(如损失值、准确率、模型权重、图像等)写入到事件文件中,供 TensorBoard 可视化使用。允许用户通过在训练中添加不同的可视化元素来跟踪和分析模型的训练过程。这里主要介绍 SummaryWriter 类中的两个方法:
- add_scalar:在训练过程中,可以记录标量(如损失值、准确率等)并将它们写入 TensorBoard。
- add_image:可以将图像数据(如输入图像、模型生成的图像等)写入 TensorBoard。
1、使用Tensorboard追踪标量
(1)add_scalar参数说明
python
add_scalar(tag, scalar_value, global_step=None, walltime=None)1. tag(必需)
-
类型 :
str -
说明 : 数据的标签,通常是你希望记录的标量的名称。这个标签将用于 TensorBoard 中的图表名称。例如,
'Loss/train'或'Accuracy/test'。 -
示例 :
'Loss/train'、'Accuracy/test'
2. scalar_value(必需)
-
类型 :
float或int -
说明: 要记录的标量值。通常是一个单一的数值,例如模型的损失值或准确率。
-
示例 :
0.5(损失值),0.75(准确率)
3. global_step(可选)
-
类型 :
int或None -
说明 : 用于标记标量值的全局步数(如 epoch 或 batch 的编号)。它用于指定该标量值对应的训练步骤,TensorBoard 会根据此步数来显示数据的变化。通常,你会将
global_step设置为当前 epoch 或 batch 数。 -
默认值 :
None,表示没有指定步骤。 -
示例 :
epoch或batch编号,例如global_step=epoch。
4. walltime(可选)
-
类型 :
float或None -
说明 : 用于指定记录的时间戳(单位为秒)。如果你不指定,
SummaryWriter会自动使用当前的时间戳。这对于同步时间序列数据非常有用,但通常不需要手动设置。 -
默认值 :
None,表示使用当前时间。
返回值
- 返回值 : 无,
add_scalar方法是一个副作用方法,只会将数据写入事件文件中。
(2)add_scalar使用步骤
导入SummaryWriter类:
python
from torch.utils.tensorboard import SummaryWriter初始化SummaryWriter:
python
writer = SummaryWriter('logs')注:参数"logs"表示将事件写入logs文件夹中
add_scalar的使用:
python
writer.add_scalar('Loss/train', loss, epoch)
writer.add_scalar('Accuracy/train', accuracy, epoch)注:第一个参数是图像的标题,第二个参数是要可视化的标量,即图像的y轴,第三个参数是图像的x轴。
关闭:
python
writer.close()启动 TensorBoard窗口:
python
# 6. 启动 TensorBoard
%load_ext tensorboard
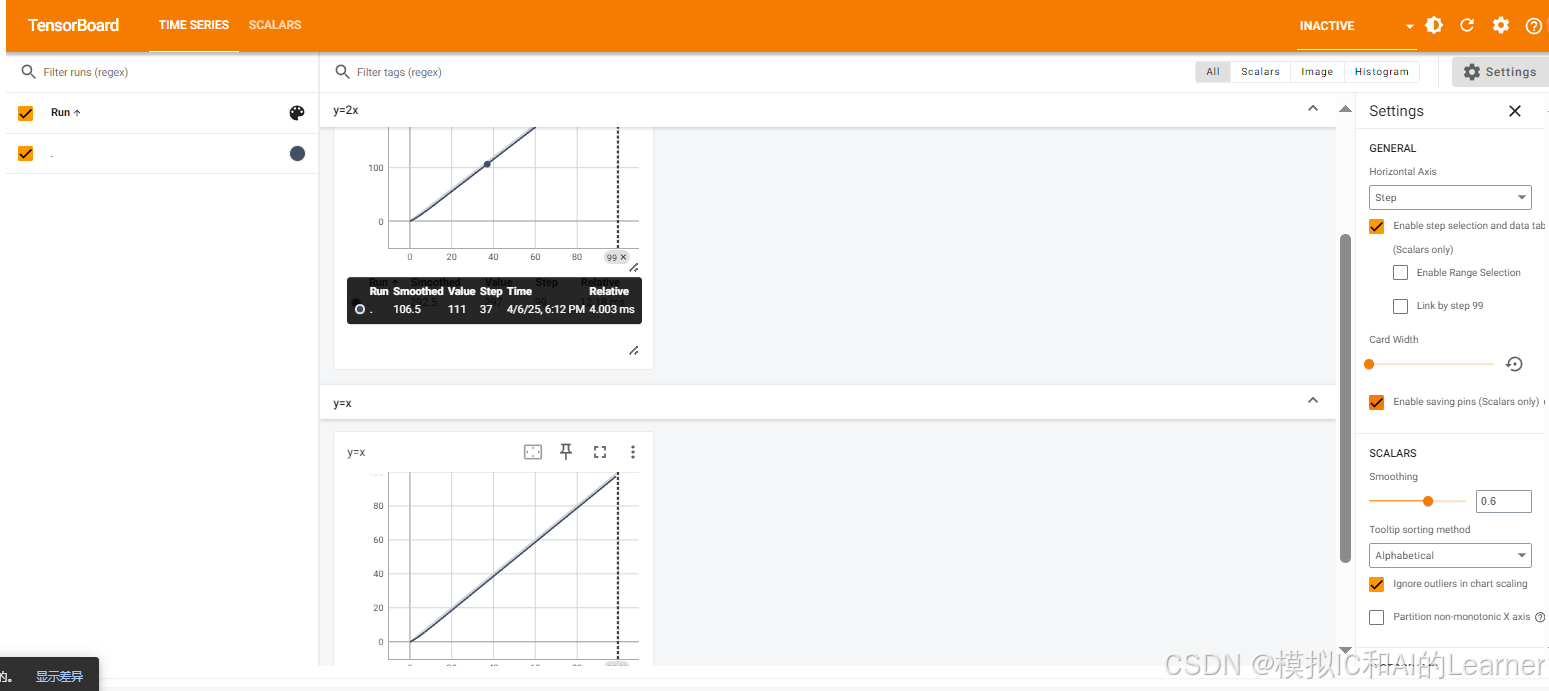
%tensorboard --logdir logs代码放一块的小案例为:
python
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.add_scalar("y=2x",2*i,i)
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs结果:
2、使用Tensorboard追踪图像
(1)add_image参数说明
python
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')1. tag(必需)
-
类型 :
str -
说明 : 图像的标签,通常是你希望在 TensorBoard 中显示的图像名称。这个标签用于在 TensorBoard 中标识图像,通常是一个字符串,例如
'Image/sample'。 -
示例 :
'Image/train_input','Model_output'
2. img_tensor(必需)
-
类型 :
Tensor(PyTorch tensor) -
说明: 你要记录的图像数据,必须是一个 PyTorch tensor(也可以是numpy.array)。这个 tensor 应该具有以下形状之一:
-
(C, H, W):适用于单张图像,其中C是通道数(例如 3 表示 RGB),H是高度,W是宽度。 -
(B, C, H, W):适用于一批图像,其中B是批次大小,C是通道数,H是高度,W是宽度。
图像数据的值应该在 0, 1 或 -1, 1 范围内。如果数据值不在此范围内,TensorBoard 可能无法正确显示图像。
-
-
示例 :
img_tensor = torch.rand(3, 64, 64)(生成一张随机图像,3 通道,64x64 像素)
3. global_step(可选)
-
类型 :
int或None -
说明 : 用于标记图像记录的全局步骤(通常是 epoch 或 batch 编号)。TensorBoard 会根据此步骤显示图像。例如,你可以使用
global_step=epoch来记录每个 epoch 的图像,或者使用global_step=batch来记录每个 batch 的图像。 -
默认值 :
None,表示没有指定步骤。 -
示例 :
global_step=epoch
4. walltime(可选)
-
类型 :
float或None -
说明 : 用于指定记录的时间戳(单位为秒)。如果你不指定,
SummaryWriter会自动使用当前时间戳。通常情况下,除非有特殊需求,否则不需要手动设置。 -
默认值 :
None,表示使用当前时间。
5. dataformats(可选)
-
类型 :
str -
说明: 用于指定图像数据的格式。它指定了输入 tensor 的维度顺序。通常有两种格式:
-
'CHW':图像数据格式为 (C, H, W),其中 C 是通道数,H 是高度,W 是宽度。常用于单张图像。 -
'NHWC':图像数据格式为 (N, H, W, C),其中 N 是批次大小,H 是高度,W 是宽度,C 是通道数。常用于一批图像。
如果你传入的是一张图像,通常使用
'CHW'格式;如果传入的是一批图像,通常使用'NHWC'格式。 -
-
默认值 :
'CHW' -
示例 :
'CHW'或'NHWC'
返回值
- 返回值 : 无,
add_image是一个副作用方法,数据被写入事件文件中,不会返回任何内容。
(2)add_image使用步骤
导入SummaryWriter类:
python
from torch.utils.tensorboard import SummaryWriter初始化SummaryWriter:
python
writer = SummaryWriter('logs')注:参数"logs"表示将事件写入logs文件夹中
add_image的使用:
加载图片:
python
image_path = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train/ants/0013035.jpg"
from PIL import Image
img = Image.open(image_path)
print(type(img))
# 输出为:<class 'PIL.JpegImagePlugin.JpegImageFile'>输出的img类型不符合 add_image传入参数的类型,需要将 img 类型转为 PyTorch tensor(或是numpy.array),下面代码将 img 转为了numpy.array,如果要用PyTorch tensor类型可使用transforms中的ToTensor类进行转化。
python
# 将img转为numpy类型
import numpy as np
img_array = np.array(img)
print(type(img_array))
# 输出为:<class 'numpy.ndarray'>接下来调用 add_image:
python
writer.add_image("test",img_array,1,dataformats='HWC')
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs结果为:
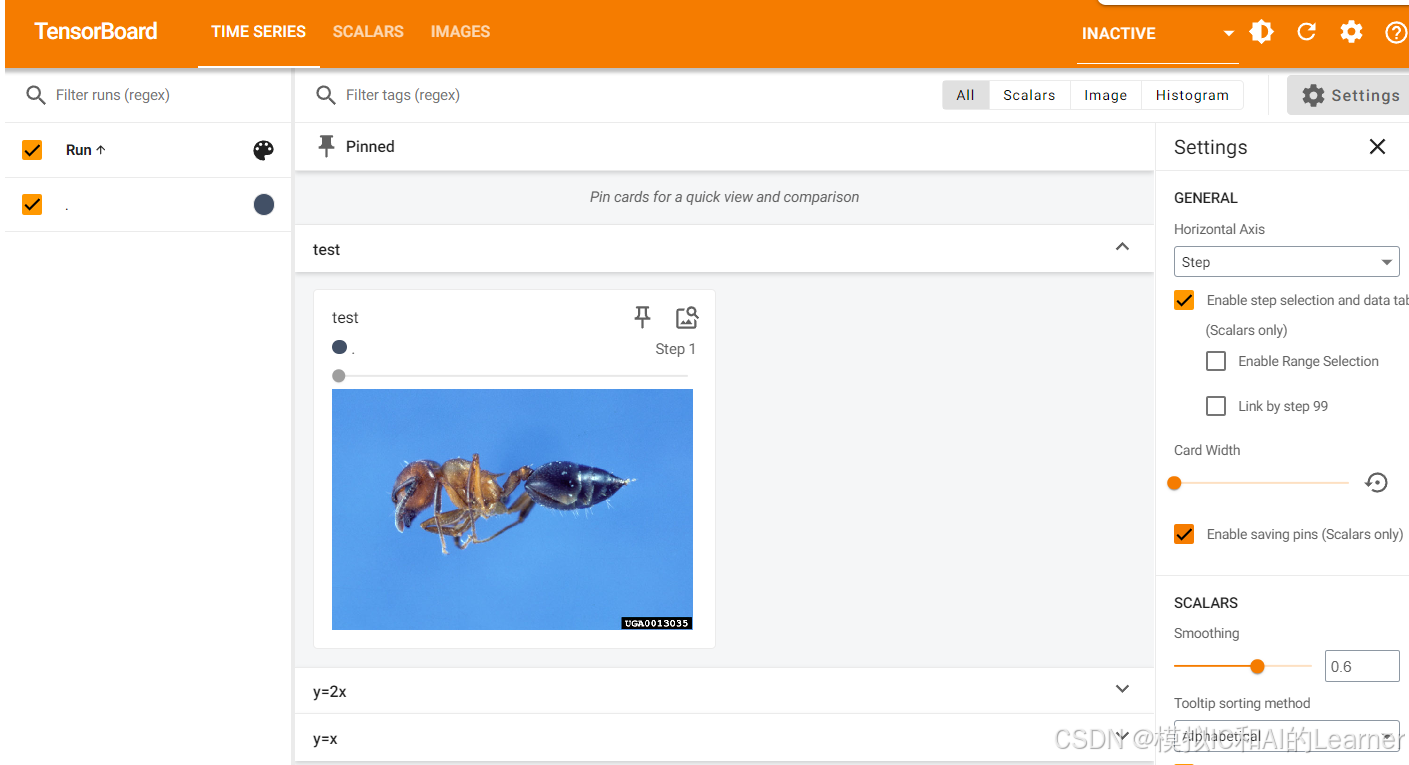
当在同一个标题下传入TensorBoard 多个图像时(设置不同序号,即第三个参数),可拖动进度条查看图像的渐变过程。当改变标题时,会另开一个图像窗口。
四、transforms的使用
是一个对图像数据进行处理的工具箱,其中有很多有关图像处理的类。
在 PyTorch 中,torchvision.transforms 提供了许多图像处理的常用操作,能够在数据预处理过程中自动对图像进行转换。常见的用途包括图像增强、归一化、裁剪、旋转、调整大小等。这些转换操作可以帮助你在训练神经网络时处理图像数据。
1、transforms 常用类
-
Resize:调整图像的大小。 -
CenterCrop:对图像进行中心裁剪。 -
RandomCrop:随机裁剪图像。 -
RandomHorizontalFlip:随机水平翻转图像。 -
ToTensor:将图像转换为 PyTorch Tensor(同时将像素值从 0, 255 转换为 0, 1 的范围)。 -
Normalize:对图像进行归一化处理。 -
ColorJitter:随机调整图像的亮度、对比度、饱和度和色调。 -
RandomRotation:随机旋转图像。
2、使用 transforms.Compose 组合多个转换
transforms.Compose 是一个非常方便的工具,它可以将多个图像处理操作按顺序组合成一个管道,从而在数据加载时一次性应用所有转换。
python
import torch
from torchvision import transforms
from PIL import Image
# 加载一个示例图像
img = Image.open('sample_image.jpg')
# 定义一个转换组合
transform = transforms.Compose([
transforms.Resize((128, 128)), # 调整图像大小
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为 Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 应用转换
img_tensor = transform(img)
print(img_tensor.shape) # 打印转换后的图像大小3、transforms 的 ToTensor 类
(1)为什么在pytorch中要把数据类型转化为 tensor?
tensor数据类型的数据有很多属性和方法(如梯度、设备、形状、维度等),便于在神经网络中使用。
python
import torch
tensor = torch.tensor([1.0, 2.0, 3.0])
print(dir(tensor)) # 输出: 输出为:
'dtype','device','shape','dim()','requires_grad','grad','is_cuda','is_leaf','is_floating_point()',.......
查看某tensor变量的属性:
python
import torch
# 创建一个示例张量
tensor = torch.randn(3, 4, 5, device='cuda', requires_grad=True)
# 查看属性函数
print(f"张量的设备: {tensor.device}") # 输出: cuda:0
print(f"张量的形状: {tensor.shape}") # 输出: torch.Size([3, 4, 5])
print(f"张量的维度数: {tensor.ndimension()}") # 输出: 3
print(f"是否需要梯度计算: {tensor.requires_grad}") # 输出: True
print(f"张量的类型: {tensor.dtype}") # 输出: torch.float32
print(f"是否在 GPU 上: {tensor.is_cuda}") # 输出: True
print(f"是否为叶子节点: {tensor.is_leaf}") # 输出: True
print(f"张量的元素个数: {tensor.numel()}") # 输出: 60(2)transforms 的 ToTensor 类的使用
功能:将两种非 tensor 类型的图像数据转化为 tensor 类型
下面是其使用示例:
python
# 挂载 Google Drive以实现数据集的获取,
from google.colab import drive
drive.mount('/content/drive')
from PIL import Image
from torchvision import transforms
#python的用法 -》 tensor数据类型
img_path = "/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train/ants/0013035.jpg"
# 使用Image读取到的类型是<class 'PIL.JpegImagePlugin.JpegImageFile'>
img = Image.open(img_path)
# transforms该如何使用,以其中的ToTensor类为例
# 使用ToTensor类将"<class 'PIL.JpegImagePlugin.JpegImageFile'>"类型的图像数据转化为Tensor类型
tensor_trans = transforms.ToTensor()
tensor_img_1 = tensor_trans(img)
print(tensor_img)
print("-------------------------------------------------------------------------------------------------------------")
# 使用ToTensor类将"<class 'numpy.ndarray'>"类型的图像数据转化为Tensor类型
import cv2
# 使用cv2读取到的类型是<class 'numpy.ndarray'>
cv_img = cv2.imread(img_path)
tensor_trans = transforms.ToTensor()
tensor_img_2 = tensor_trans(cv_img)
print(tensor_img_2)
print("-------------------------------------------------------------------------------------------------------------")4、transforms中的常用类
遇到一个transforms中的常用类应该关注的点:
- 关注输入与输出类型
- 多看官方文档:eg:help(
transforms.ToTensor)
几个类的使用方法案例:
python
# 挂载 Google Drive以实现数据集的获取,
from google.colab import drive
drive.mount('/content/drive')
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# 创建 SummaryWriter 对象,指定日志文件夹
writer = SummaryWriter("logs")
# 打开图像
img = Image.open("/content/drive/MyDrive/unzipped_folder/hymenoptera_data/train/ants/0013035.jpg")
print(img)
# 将图像转换为 Tensor
trans_to_tensor = transforms.ToTensor()
img_tensor = trans_to_tensor(img)
# 在 TensorBoard 中添加 ToTensor 图像
writer.add_image("ToTensor", img_tensor)
# 打印转换后的图像的第一个通道的第一个像素值
print(img_tensor[0][0][0])
# 对图像进行归一化处理 Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
# 打印归一化后的图像的第一个通道的第一个像素值
print(img_norm[0][0][0])
# 在 TensorBoard 中添加 Normalize 图像
writer.add_image("Normalize", img_norm)
# 类Resize的使用
print(img.size)
trans_resize = transforms.Resize((256, 256))
# 使用 Resize 转换图像 -> 输入和输出的图像类型都为 PIL
img_resize = trans_resize(img)
# 将 PIL 图像转换为 Tensor -> img_resize tensor
img_resize = trans_to_tensor(img_resize)
# 上一步的原因是下面这一步add_image的输入只接受tensor或np.darray类型的图像
writer.add_image("Resize", img_resize, 0)
print(img_resize.shape)
# 类 Compose 和 Resize(只传入一个参数) 的使用
trans_resize_2 = transforms.Resize(256) #一个参数不会改变图像的宽长比
# 使用 Compose 将多个转换结合起来
trans_compose = transforms.Compose([trans_resize_2, trans_to_tensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
print(img_resize_2.shape)
#随机裁剪
# RandomCrop
# 参数为一个序列的话是指定裁剪的大小,参数为一个int类型数字的话是裁剪为正方形
trans_random = transforms.RandomCrop(256)
# 使用 RandomCrop 转换图像 -> 输入和输出的图像类型都为 PIL
trans_compose_2 = transforms.Compose([trans_random, trans_to_tensor])
# 生成 10 张随机裁剪的图像
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
# 关闭 writer
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs(1)ToTensor
(3)Resize
(4)RandomCrop
-
功能 :将 PIL 图像或
numpy.ndarray转换为 PyTorch 的张量。张量的值范围会从 0, 255 转换为 0.0, 1.0。 -
示例:
pythonfrom torchvision import transforms from PIL import Image img = Image.open("image.jpg") transform = transforms.ToTensor() img_tensor = transform(img)(2)
Normalize -
功能:对图像的每个通道进行标准化,使其具有指定的均值和标准差。
-
**要点:**输入只能是 tensor image 类型,不能是 PIL Image,输出是 tensor image 类型。
-
示例:
pythontransform = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) img_normalized = transform(img_tensor) -
功能:调整图像的大小。可以指定新的宽度和高度,或者只指定一个边长,按比例调整。
-
**要点:**输入和输出的图像类型都为 PIL Image,输入参数是序列的话代表的是裁剪后的图像的尺寸,如果输入是一个 int 类型数字的话,裁剪不会改变宽长比。
-
示例:
pythontransform = transforms.Resize((256, 256)) img_resized = transform(img) -
功能:随机裁剪图像的一个区域。可以指定裁剪后的大小。
-
要点: 输入和输出的图像类型都为 PIL Image,输入参数是序列的话代表的是裁剪后的图像的尺寸,如果输入是一个 int 类型数字的话,裁剪后为正方形(这点和**
Resize不一样**)。 -
示例
pythontransform = transforms.RandomCrop(256) img_cropped = transform(img)
(5)RandomHorizontalFlip
-
功能:随机水平翻转图像,通常用于数据增强。
-
示例:
pythontransform = transforms.RandomHorizontalFlip(p=0.5) # p 表示翻转的概率 img_flipped = transform(img)
(6)RandomVerticalFlip
-
功能:随机垂直翻转图像,通常用于数据增强。
-
示例:
pythontransform = transforms.RandomVerticalFlip(p=0.5) img_flipped = transform(img)
(7)ColorJitter
-
功能:随机改变图像的亮度、对比度、饱和度和色调,常用于数据增强。
-
示例:
pythontransform = transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2) img_jittered = transform(img)
(8)RandomRotation
-
功能:随机旋转图像一定角度范围内的角度。
-
示例:
pythontransform = transforms.RandomRotation(30) # 旋转范围在 -30 到 30 度之间 img_rotated = transform(img)
(9)Grayscale
-
功能:将图像转换为灰度图像,可以指定输出的通道数。
-
示例:
pythontransform = transforms.Grayscale(num_output_channels=1) img_gray = transform(img)
(10)RandomAffine
-
功能:对图像应用随机的仿射变换,包括平移、缩放、旋转等操作。
-
示例:
pythontransform = transforms.RandomAffine(degrees=30, translate=(0.1, 0.1)) img_affine = transform(img)
(11)RandomPerspective
-
功能:应用随机的透视变换,常用于增强图像的多样性。
-
示例:
pythontransform = transforms.RandomPerspective(distortion_scale=0.5, p=1.0, interpolation=3) img_perspective = transform(img)
(12)RandomErasing
-
功能:随机擦除图像的一部分,通常用于数据增强。
-
示例:
pythontransform = transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3)) img_erased = transform(img)
(13)ToPILImage
-
功能:将 PyTorch 张量转换回 PIL 图像。
-
示例:
pythontransform = transforms.ToPILImage() img_pil = transform(img_tensor)
(14)Compose
-
功能:将多个图像转换操作组合在一起,使得可以按顺序执行多个操作。常用于组合多个预处理步骤。
-
示例:
pythontransform = transforms.Compose([ transforms.Resize(256), transforms.RandomCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) img_transformed = transform(img)
(15)Lambda
-
功能:对图像应用一个自定义的转换函数。
-
示例:
pythontransform = transforms.Lambda(lambda x: x / 255.0) img_normalized = transform(img_tensor)
(16)FiveCrop
-
功能:将图像裁剪为四个角的裁剪区域和中心裁剪区域。
-
示例:
pythontransform = transforms.FiveCrop(224) img_crops = transform(img)
(17)Pad
-
功能:对图像进行填充,添加指定的像素宽度或指定的填充模式。
-
示例:
pythontransform = transforms.Pad(10) # 为图像四周填充 10 像素 img_padded = transform(img)
五、 torchvision 中的 datasets
1、先来一个案例
python
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform = dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform = dataset_transform, download=True)
'''
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
import matplotlib.pyplot as plt
# 使用 matplotlib 显示图像
plt.imshow(img)
plt.axis('off') # 关闭坐标轴
plt.show()
'''
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
# 关闭 writer
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs2、torchvision.datasets 中常见数据集说明
torchvision.datasets 是 PyTorch 中一个重要的模块,提供了各种常用的标准数据集。通过这个模块,用户可以轻松地加载和处理图像数据集,尤其是用于图像分类、目标检测、分割等任务。datasets 模块中的数据集大多都经过了处理,包含了下载、预处理和转换等功能。
以下是一些常见的 torchvision.datasets 数据集及其简要介绍:
(1)CIFAR10 和 CIFAR100
-
功能:这两个数据集是广泛用于图像分类任务的小型数据集。
-
CIFAR-10:包含 10 个类别,每个类别 6,000 张 32x32 的彩色图像。
-
CIFAR-100:包含 100 个类别,每个类别 600 张图像,图像的尺寸为 32x32。
-
用法:
pythonfrom torchvision import datasets, transforms # 进行数据预处理(例如将图像转换为张量并标准化) transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # 加载 CIFAR10 数据集 train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
(2)MNIST
-
功能:MNIST 是一个经典的手写数字数据集,包含 28x28 像素的灰度图像,分为 10 类(0-9)。
-
用法:
pythonfrom torchvision import datasets, transforms # 定义数据转换 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) # 下载训练集和测试集 train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
(3)ImageNet
-
功能:ImageNet 是一个包含超过 1400 万张图像和 1000 个类别的大型数据集。它广泛应用于图像分类任务,并且是计算机视觉领域的标准数据集之一。
-
用法:
pythonfrom torchvision import datasets, transforms # 数据预处理 transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # 加载 ImageNet 数据集 train_dataset = datasets.ImageNet(root='./data', split='train', download=True, transform=transform) val_dataset = datasets.ImageNet(root='./data', split='val', download=True, transform=transform)
(4)COCO (Common Objects in Context)
-
功能:COCO 是一个大型图像数据集,包含了 80 类常见物体,并提供了目标检测、实例分割、人体关键点检测等标注。它适用于更复杂的计算机视觉任务。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor()]) # 加载 COCO 数据集 coco_train = datasets.CocoDetection(root='./data', annFile='./data/annotations/instances_train2017.json', transform=transform) coco_val = datasets.CocoDetection(root='./data', annFile='./data/annotations/instances_val2017.json', transform=transform)
(5)LSUN (Large Scale Scene Understanding)
-
功能:LSUN 是一个面向场景理解的大型数据集,包含了多个不同场景类别的图像。适用于图像分类和生成模型任务。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor()]) # 加载 LSUN 数据集 lsun_train = datasets.LSUN(root='./data', classes=['train'], transform=transform)
(6)FashionMNIST
-
功能:FashionMNIST 是一个包含 28x28 灰度图像的数据集,用于服装分类任务。与 MNIST 类似,但其分类对象为衣物和配饰。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) train_dataset = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
(7)CelebA (CelebFaces Attributes)
-
功能:CelebA 是一个包含 20 多万张名人面孔的图像数据集,广泛用于人脸识别、面部属性预测等任务。每张图像有 40 个属性标签(如是否有胡子、是否戴眼镜等)。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor()]) # 加载 CelebA 数据集 celebA = datasets.CelebA(root='./data', split='train', download=True, transform=transform)
(8)SVHN (Street View House Numbers)
-
功能:SVHN 是一个由街景图像中提取的数字数据集,目标是对数字进行分类。它的图像大小是 32x32 像素,包含了较为复杂的背景。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) # 下载和加载 SVHN 数据集 train_dataset = datasets.SVHN(root='./data', split='train', download=True, transform=transform) test_dataset = datasets.SVHN(root='./data', split='test', download=True, transform=transform)
(9)VOC (PASCAL Visual Object Classes)
-
功能:PASCAL VOC 是一个包含多种物体类别的图像数据集,广泛用于目标检测、语义分割等任务。它包含 20 个物体类别,并且每个类别都有对应的标注数据。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor()]) # 加载 PASCAL VOC 数据集 voc_train = datasets.VOCDetection(root='./data', year='2012', image_set='train', download=True, transform=transform)
(10)Kinetics
-
功能:Kinetics 是一个视频数据集,包含了许多动作分类的视频。适用于动作识别和视频分析任务。
-
用法:
pythonfrom torchvision import datasets, transforms transform = transforms.Compose([transforms.ToTensor()]) # 加载 Kinetics 数据集 kinetics_train = datasets.Kinetics400(root='./data', split='train', download=True, transform=transform)
(11)总结
torchvision.datasets 提供了广泛的常用数据集,涵盖了从简单的图像分类(如 MNIST 和 CIFAR)到更复杂的图像识别、目标检测和视频分析(如 COCO 和 Kinetics)等任务。使用 torchvision.datasets,用户可以方便地下载和处理数据集,并进行标准化、裁剪、翻转等常见的图像预处理操作。通过这些数据集,用户可以快速启动并实验各种计算机视觉任务。
六、DataLoader的使用
1、DataLoader介绍
在 PyTorch 中,DataLoader 是一个非常重要的工具,用于加载数据集,并且提供了批量加载、数据打乱、并行处理等功能。通过 DataLoader,我们可以更高效地加载训练和测试数据,尤其是在深度学习模型的训练过程中。
DataLoader 的基本作用:
DataLoader 用于从数据集(例如 torchvision.datasets 提供的数据集或自定义数据集)中按批次加载数据,并返回每个批次的数据。这使得我们在训练模型时能够轻松地处理大规模数据集。
DataLoader 构造函数参数
DataLoader 的常用参数如下:
python
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)1. dataset:
-
这个参数指定了数据集,可以是任何继承自
torch.utils.data.Dataset类的对象。DataLoader将从这个数据集对象中获取数据。 -
示例:
train_dataset、test_dataset或自定义的数据集类。
2. batch_size:
-
每个批次包含的样本数量。通常,批量大小取决于系统的内存限制和训练的需求。
-
示例:
batch_size=32表示每次加载 32 张图像。
注意:较大的批量大小通常能加速训练,但需要更多的内存。较小的批量大小则会降低内存占用,但可能会减慢训练速度。
3. shuffle:
-
如果设置为
True,每个epoch结束后会打乱数据集中的数据。通常在训练时使用此参数以提高模型的泛化能力。 -
示例:
shuffle=True用于训练集,以确保每次训练时数据顺序不同。
4. sampler 和 batch_sampler:
-
这两个参数允许用户定义如何抽样数据。
sampler是一种自定义的方式,决定数据的顺序,而batch_sampler则决定如何组合这些数据成批次。 -
通常情况下,用户不需要直接使用这两个参数。
5. num_workers:
-
定义用于加载数据的子进程数量。
num_workers设置为大于 0 的数字时,DataLoader将使用多进程加载数据。设置为 0 时,数据将通过主进程加载。 -
提高
num_workers可以加速数据加载,但也可能增加系统的 CPU 负载。通常在具有多个 CPU 核心的机器上会设置为更高的数字。 -
示例:
num_workers=4表示使用 4 个子进程来加载数据。
6. collate_fn:
-
collate_fn是一个函数,用于将多个样本组合成一个批次。默认情况下,DataLoader会简单地将一个批次的数据堆叠在一起。然而,如果你的数据样本是复杂的(例如不同大小的图像或多模态数据),你可能需要自定义一个collate_fn来处理批次的组合。 -
示例:对于不同大小的图像,可以使用
collate_fn来处理不同的尺寸。
7. pin_memory:
-
如果设置为
True,DataLoader会将数据加载到 page-locked memory(锁页内存)中,通常能加速将数据从 CPU 传输到 GPU。 -
在使用 GPU 时,通常建议将
pin_memory设置为True,以提高数据传输效率。
8. drop_last:
-
如果设置为
True,则会丢弃最后一个批次,如果该批次的样本数小于指定的batch_size。通常,在使用固定大小的批次进行训练时使用此选项。 -
示例:
drop_last=True将删除最后一个小于batch_size的批次。
9. timeout:
-
这个参数指定了等待数据加载的最大时间(以秒为单位)。如果超时,则会抛出错误。
-
示例:
timeout=60表示在 60 秒内没有加载数据就会抛出超时错误。
10. worker_init_fn:
-
用于在每个工作进程启动时进行初始化,通常用于设置种子或其他初始化操作。
-
示例:
worker_init_fn=set_seed用于设置每个工作进程的随机种子。
2、案例分析
(1)查看 DataLoader 输出的数据类型
python
import torchvision
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中获取一张图像和目标标签
img, target = test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs, targets = data
# DataLoader后 imgs和targets 都会加一维
print(imgs.shape)
print(targets)输出为:
python
torch.Size([4, 3, 32, 32])
tensor([2, 1, 4, 3])
torch.Size([4, 3, 32, 32])
tensor([1, 9, 1, 5])
torch.Size([4, 3, 32, 32])
tensor([0, 3, 9, 2])
torch.Size([4, 3, 32, 32])
tensor([0, 5, 1, 2])
......(2)将每个批都用 tensorboard 显示
python
# 通过tensorboard将每个批次的图像都画出来
import torchvision
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中获取一张图像和目标标签
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("logs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step )
step += 1
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs输出为:
七、Pytorch中神经网络模型搭建相关的python API
(1)torch.nn 和 torch.nn.functional
- torch.nn 中包含了所有与神经网络相关的类,"nn"就是"神经网络"的英文首字母。
- torch.nn.functional 相比于 torch.nn ,其中的内容更底层,包含很多神经网络相关的函数,即 torch.nn 相当于 torch.nn.functional 的再封装。
(2)torch.nn.Module的使用
torch.nn中第一个就是 Module(是一个类),它是神经网络的框架,所有自己的神经网络的框架都要继承它。
下面的程序是一个简单的神经网络框架:
python
# pytorch 中,有关神经网络的类都在torch.nn中
# torch.nn中第一个就是 Module,它是神经网络的框架,所有自己的神经网络的框架都要继承它。
#
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)(3)torch.nn.functional.conv2d函数的使用
注意conv2d是个函数,和Conv2d不同(Conv2d是一个类,表示卷积层)
python
torch.nn.functional.conv2d(input, weight, bias=None, stride=1,
padding=0, dilation=1, groups=1)函数的参数介绍:
-
input -- 输入张量,形状为 (minibatch, in_channels, iH, iW)
-
weight -- 卷积核,形状为 (out_channels, in_channels // groups, kH, kW)
-
bias -- 可选的偏置张量,形状为 (out_channels)。默认值为 None
-
stride -- 卷积核的步幅。可以是单一数字或元组 (sH, sW)。默认值为 1
-
padding -- 输入张量的隐式填充。可以是字符串 {'valid', 'same'},单一数字或元组 (padH, padW)。默认值为 0,padding='valid' 表示无填充;padding='same' 会对输入进行填充,以保证输出与输入形状相同。然而,该模式不支持步幅大于 1 的情况。
警告: 对于
padding='same',如果weight的长度是偶数,并且dilation在任何维度上是奇数,那么可能需要内部执行pad()操作,从而降低性能。 -
dilation -- 卷积核元素之间的间距。可以是单一数字或元组 (dH, dW)。默认值为 1
下面是函数conv2d实现卷积操作的例子:
python
# 二维卷积操作 conv2d 的使用
# 注意conv2d是个函数,和Conv2d不同(Conv2d是一个类,表示卷积层)
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# Reshape the input and kernel to fit convolution dimensions
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
# input的四个维度分别为(minibatch,in_channels,iH,iW)
# kernel的四个维度分别为(out_channels, in_channels/groups ,kH,kW)
print(input.shape)
print(kernel.shape)
# Perform 2D convolution
# 卷积的跨度stride=1
output = F.conv2d(input, kernel, stride=1)
print(output)
# 卷积的跨度stride=2
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
# 卷积的填充 padding=1,(填充的是0)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)输出为:
python
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[10, 12],
[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])(4)torch.nn.Conv2d卷积层的使用
Conv2d 和 torch.nn.functional 中的 conv2d 不同,Conv2d 是一个类,将表示一个卷积层。
python
torch.nn.Conv2d(in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros',
device=None, dtype=None)Conv2d 类的参数介绍:
-
in_channels (int) -- 输入图像中的通道数
-
out_channels (int) -- 卷积操作后产生的通道数
-
kernel_size (int 或 tuple) -- 卷积核的大小
-
stride (int 或 tuple, optional) -- 卷积的步幅。默认值:1
-
padding (int, tuple 或 str, optional) -- 填充,添加到输入的四个边的填充量。默认值:0
-
dilation (int 或 tuple, optional) -- 卷积核元素之间的间距。默认值:1
-
groups (int, optional) -- 输入通道与输出通道之间的分组数。默认值:1
-
bias (bool, optional) -- 如果为 True,将可学习的偏置添加到输出。默认值:True
-
padding_mode (size,可选) -- 填充模式:'zeros'、'reflect'、'replicate' 或 'circular'。默认值:'zeros'
下面是类Conv2d实现卷积层的例子:
python
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
print(tudui)
writer = SummaryWriter("../content/logs")
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
# print(imgs.shape) #这句输出为:torch.Size([64, 3, 32, 32])
# print(output.shape) #这句输出为:torch.Size([64, 6, 30, 30])
writer.add_images("input",imgs,step)
output = torch.reshape(output,(-1,3,30,30)) # 变换后的形状第一维设置-1表示不确定,其实在这里是128
writer.add_images("output",output,step)
step = step + 1
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs输出为:
(5)torch.nn.MaxPool2d池化层的使用
和 Conv2d 一样,MaxPool2d 是一个类,将表示一个最大池化层。
python
torch.nn.MaxPool2d(kernel_size, stride=None,
padding=0, dilation=1, return_indices=False,
ceil_mode=False)MaxPool2d 类的参数介绍:
-
kernel_size (Unionint, Tuple\[int, int]) -- 用于池化操作的窗口大小
-
stride (Unionint, Tuple\[int, int], optional) -- 窗口的步幅。默认值是
kernel_size -
padding (Unionint, Tuple\[int, int], optional) -- 在池化操作的两侧添加的隐式负无穷大填充。
-
dilation (Unionint, Tuple\[int, int], optional) -- 一个控制窗口中元素步幅的参数。
-
return_indices (bool, optional) -- 如果为
True,将返回最大值的索引以及输出值。对torch.nn.MaxUnpool2d有用,即通常用于后续的反池化操作。 -
ceil_mode (bool, optional) -- 当为
True时,使用向上取整 (ceil) 而不是向下取整 (floor) 来计算输出形状。
下面是两个使用池化层的例子,一个是简单的池化层使用示例,第二个是池化层对图片的使用:
python
# 池化层 MaxPool2d 的使用
# 基础示例
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]],dtype = torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
# 如果ceil_mode=False,则池化的输出为tensor([[[[2]]]]),只有一个数,因为不足以完成池化的边缘被舍去了
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
'''
输出为torch.Size([1, 1, 5, 5])
tensor([[[[2, 3],
[5, 1]]]])
'''
python
# 池化层 MaxPool2d 的使用
# 项目示例
import torch
from torch import nn
from torch.nn import MaxPool2d
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
# 如果ceil_mode=False,则池化的输出为tensor([[[[2]]]]),只有一个数,因为不足以完成池化的边缘被舍去了
def forward(self, input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../content/logs/logs_MaxPool2d")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs输出为:
(6)激活函数,非线性层
以 torch.nn.ReLU 为例。
参数介绍:
- inplace (bool) -- 可选择是否在原地执行操作。默认值:
False。若为True,则直接改变原输入的值,若为False,原输入值不变,返回输出值。
下面是两个使用激活层的例子,一个是简单的激活层使用示例(ReLU),第二个是激活层对图片的使用(Sigmoid):
python
# ReLU层的使用
# 基础示例
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5], [-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
def forward(self, input):
output = self.relu1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
'''
输出为:
torch.Size([1, 1, 2, 2])
tensor([[[[1., 0.],
[0., 3.]]]])
'''
python
# ReLU层的使用
# 项目示例
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
tudui = Tudui()
writer = SummaryWriter("../content/logs/logs_Sigmoid")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs输出为:
(7)线性层的使用
python
torch.nn.Linear(in_features, out_features, bias=True,
device=None, dtype=None)参数介绍:
-
in_features (int):每个输入样本的大小。
-
out_features (int):每个输出样本的大小。
-
bias (bool):如果设置为
False,该层将不学习加性偏置。默认值为True。
下面是使用线性层的例子:
python
# 线性层 Linear 的使用
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(
"../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True
)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.reshape(imgs, (1, 1, 1, -1))
# 上面这句代码可以用torch.flatten()来代替,如 output = torch.flatten(imags)
print(output.shape)
output = tudui(output)
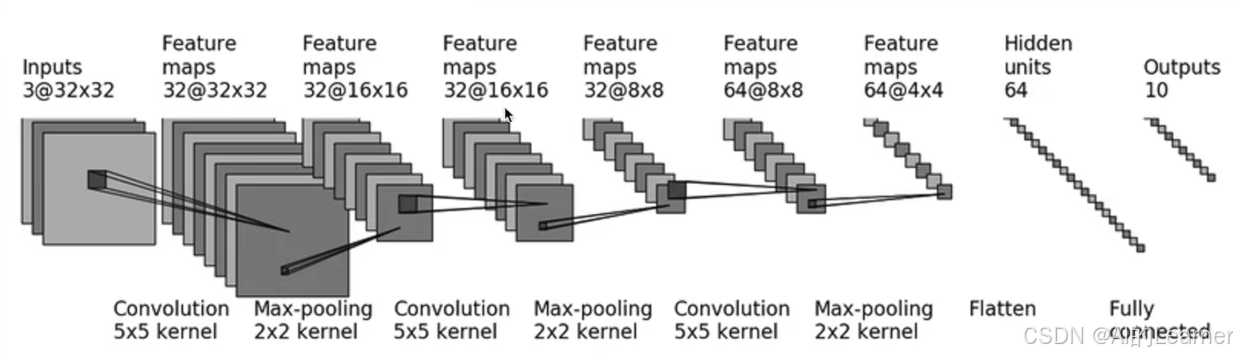
print(output.shape)(8)实战模型搭建及 nn.Sequential 的使用
模型为:
python
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
# 实例化模型
tudui = Tudui()
print(tudui)
# 测试输入
input = torch.ones((64, 3, 32, 32)) # 批次大小 64,3 通道,32x32 图像
output = tudui(input)
print(output.shape)下面使用 nn.Sequential 简化上面的代码:
python
# 使用 Sequential 完成上面的实战
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
# 实例化模型
tudui = Tudui()
print(tudui)
# 测试输入
input = torch.ones((64, 3, 32, 32)) # 批次大小 64,3 通道,32x32 图像
output = tudui(input)
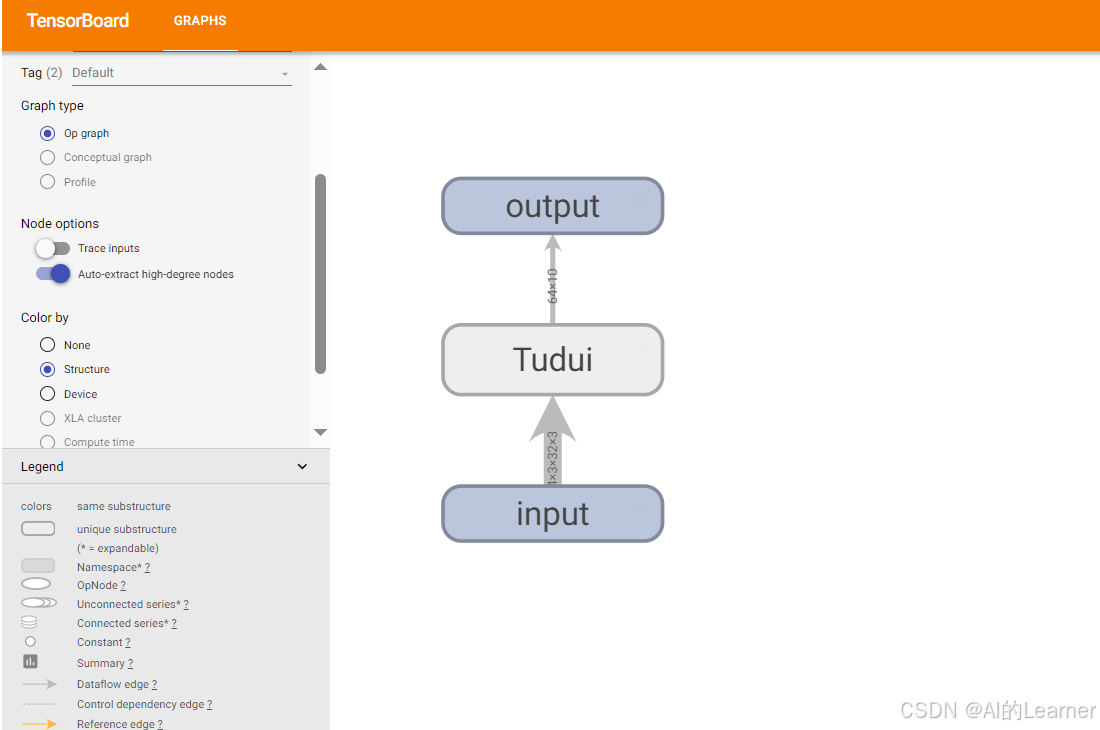
print(output.shape)(9)使用 tensorboard 完成模型的可视化
tensorboard.SummaryWriter 中的 add_graph 可实现对模型的可视化,即画出模型的框图
python
# 使用 tensorboard 完成模型的可视化
# 下面使用 add_graph 将上面的模型可视化
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("../content/logs/add_graph")
writer.add_graph(tudui,input)
writer.close()
# 6. 启动 TensorBoard
%load_ext tensorboard
%tensorboard --logdir logs输出为:
八、损失函数
在这里介绍 L1损失、L2损失(均方损失MES)、交叉熵损失。
pytorch 中的损失函数计算的类不仅计算得到了损失,在其中还隐藏着一个宝贝,就是梯度grad,便于后续优化时更新参数。loss.backward():这句话调用后就直接计算了权重的梯度
(1)L1损失
python
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')参数说明:
reduction:默认为'mean',表示批次中损失的平均;若为'sum',为批次损失的和,不平均。
使用示例:
python
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward() # 这一步是计算梯度(2)L2损失
python
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')使用示例:
python
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()(3)交叉熵损失
python
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100,
reduce=None, reduction='mean', label_smoothing=0.0)使用示例:
python
# Example of target with class indices
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()
# Example of target with class probabilities
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)
output = loss(input, target)
output.backward()(4)案例
python
# 损失函数
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))# 1代表批次中只有一个样本,3代表分类任务共有三类
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)九、反向传播与优化算法
在计算完损失后,可以直接调用 loss.backward() 来计算梯度,然后就可以根据这个梯度对参数进行优化了,首先要构建优化器。
优化器在 torch.optim 中。
下面是一个反向传播与优化算法的案例:
python
# 使用 Sequential 完成上面的实战
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
import torchvision
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(
"../content/data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for eooch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward() # 这句话调用后就直接计算了权重的梯度
optim.step()
running_loss = running_loss + result_loss
print(running_loss)十、现有网络模型的使用和修改
在这部分以 vgg16 模型为例。
vgg16模型是基于数据集 ImageNet 训练的模型,在调用模型是,可通过参数pretrained来确定是否要使用预训练的参数,该模型适合ImageNet数据集,因此分类数量为1000类,模型框架为:该模型为看起来清晰分为三个子模块:features、avgpool、classifier 。
python
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)下面是对该模型进行修改,改为10个类别输出,有两种方式,一种方式是在原模型最后加一层从1000到10的线性层,另一种方式是将原模型最后一个线性层的输出1000通道改为10通道。
python
import torchvision
# train_data = torchvision.datasets.ImageNet("../data_image_net", split='train', download=True,
# transform=torchvision.transforms.ToTensor())# 该数据集现已无法下载,但可在网上找到资源
from torch import nn
# 下面比较观察不使用预训练参数和使用预训练参数的情况
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print('非预训练模型:',vgg16_false)
print('预训练模型:',vgg16_true)
print('----------------------------------------------------------------------------------------------------------------------------------------')
train_data = torchvision.datasets.CIFAR10('../data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 在模型后面加个线性层
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
# 上面这句话若写为 vgg16_true.add_module('add_linear', nn.Linear(1000, 10)),则修改后的一层将不会加到模型子模块classifier中,而是单独一个模块
print(vgg16_true)
# 将模型最后一个线性层改为10通道输出
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)十一、模型的保存与加载
两种模型保存与加载的方式:
- 保存方式一,该方法保存的是:模型结构+模型参数
- 保存方式二,该方法保存的只有模型参数,是以字典方式保存的
python
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式一,该方法保存的是:模型结构+模型参数
torch.save(vgg16,"vgg16_method1.pth")
# 保存方式二,该方法保存的只有模型参数,是以字典方式保存的
torch.save(vgg16.state_dict(),"vgg16_method2.pth")- 加载方式一,对应保存方式一
- 加载方式二,对应保存方式二
python
# 加载方式一,对应保存方式一
load_model_1 = torch.load("vgg16_method1.pth", weights_only=False)
print(load_model_1)
# 加载方式二,对应保存方式二
load_model_2 = torch.load("vgg16_method2.pth")
print(load_model_2) # 这样的方式得到的只是一个字典,不是模型,要想得到模型,可以添加如下操作
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(load_model_2)
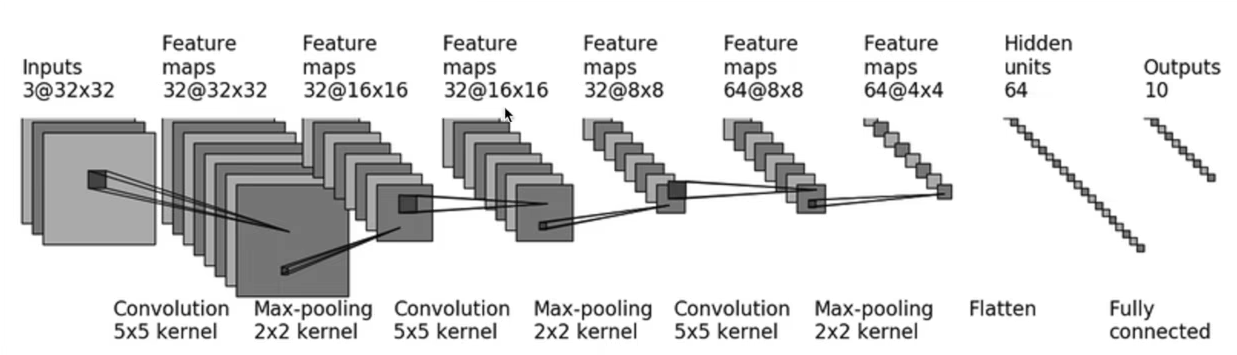
print(vgg16)十二、完整的模型训练方式
这个小项目的模型同样是使用的 CIFAR10 数据集,模型仍是是下面这个图:
任务是在 pycharm 中完成的。项目目录为:
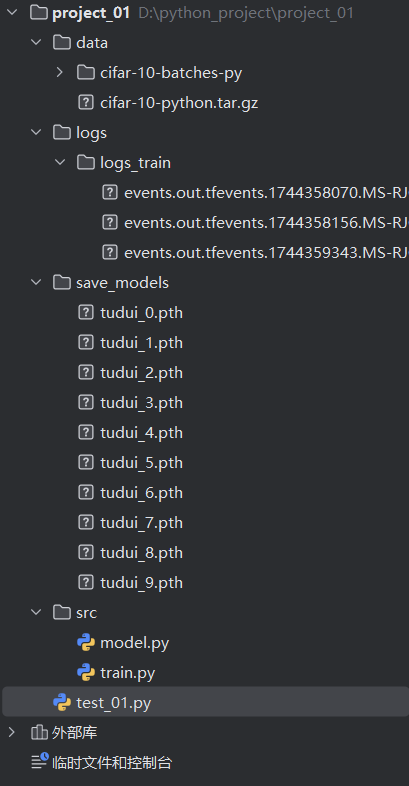
文件 model.py 为:
python
import torch
from torch import nn
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 测试模型
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)文件 train.py 为:
python
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from model import *
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# Length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练轮数
total_train_step = 0
# 记录测试轮数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("../logs/logs_train")
for i in range(epoch):
print("----- 第 {} 轮训练开始 -----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中存在 Dropout、BatchNorm层时,这行代码和下面的tudui.eval()是一定要的,如果没有这些特殊层,这两句代码要不要都行
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练轮数:{}, 训练次数:{}, Loss: {}".format(i+1, total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval() # 当网络中存在 Dropout、BatchNorm层时,这行代码和下面的tudui.train()是一定要的,如果没有这些特殊层,这两句代码要不要都行
total_test_loss = 0
total_accuracy = 0 # 在测试集上的分类精度
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "../save_models/tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
如何查看tensorboard
在终端命令窗口使用以下命令打开所在的环境:conda activate my_pytorch_1
如果上面命令失败,则先初始化conda,使用以下命令:conda init
随后关闭终端重启,再次执行conda activate my_pytorch_1来打开环境
在当前环境下打开tensorboard,执行:tensorboard --logdir=logs_train
完成后将得到的链接复制到浏览器即可
'''十三、如何将上述模型转到 GPU 上进行训练
1、方法一
将模型在GPU上训练代码修改步骤:
找出程序中的:模型 、数据 、损失函数,在其后加上 .cuda()
将模型转到gpu上:
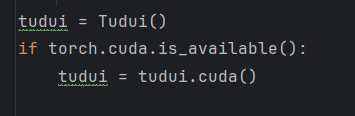
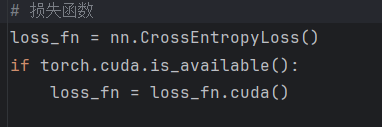
将损失函数转到gpu上:
将训练集数据转到gpu上:

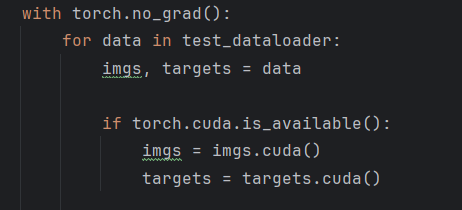
将测试集数据转到gpu上:
修改后的程序为(可适合gpu训练):
python
# 本文件在 train.py 的基础上做了修改(方法一),以适应模型在gpu上进行训练。
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# Length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练轮数
total_train_step = 0
# 记录测试轮数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("../logs/logs_train")
for i in range(epoch):
print("----- 第 {} 轮训练开始 -----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中存在 Dropout、BatchNorm层时,这行代码和下面的tudui.eval()是一定要的,如果没有这些特殊层,这两句代码要不要都行
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练轮数:{}, 训练次数:{}, Loss: {}".format(i+1, total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval() # 当网络中存在 Dropout、BatchNorm层时,这行代码和下面的tudui.train()是一定要的,如果没有这些特殊层,这两句代码要不要都行
total_test_loss = 0
total_accuracy = 0 # 在测试集上的分类精度
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "../save_models/tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
如何查看tensorboard
在终端命令窗口使用以下命令打开所在的环境:conda activate my_pytorch_1
如果上面命令失败,则先初始化conda,使用以下命令:conda init
随后关闭终端重启,再次执行conda activate my_pytorch_1来打开环境
在当前环境下打开tensorboard,执行:tensorboard --logdir=logs_train
完成后将得到的链接复制到浏览器即可
'''2、方法二
使用 to.(device) 来实现将程序放到 gpu 上,首先进行定义设备。
修改步骤为:
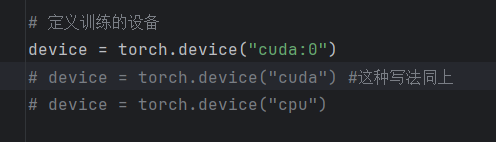
首先在文件开通定义使用的设备:
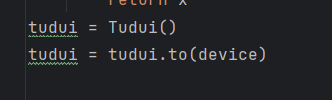
将模型转到gpu上:
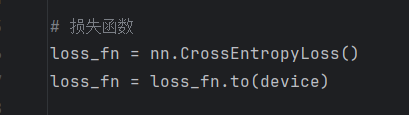
将损失函数转到gpu上:
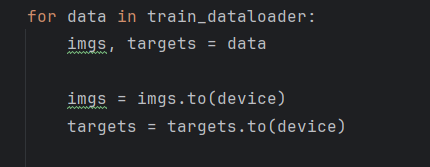
将训练集数据转到gpu上:
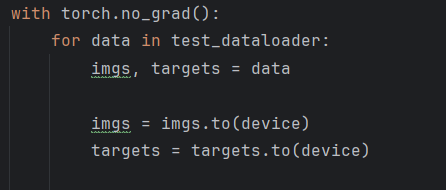
将测试集数据转到gpu上:
修改后的程序为(可适合gpu训练):
python
# 本文件在 train.py 的基础上做了修改(方法二),以适应模型在gpu上进行训练。
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# 定义训练的设备
device = torch.device("cuda:0")
# device = torch.device("cuda") #这种写法同上
# device = torch.device("cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True,
transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# Length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
tudui = tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练轮数
total_train_step = 0
# 记录测试轮数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("../logs/logs_train")
for i in range(epoch):
print("----- 第 {} 轮训练开始 -----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中存在 Dropout、BatchNorm层时,这行代码和下面的tudui.eval()是一定要的,如果没有这些特殊层,这两句代码要不要都行
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练轮数:{}, 训练次数:{}, Loss: {}".format(i+1, total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval() # 当网络中存在 Dropout、BatchNorm层时,这行代码和下面的tudui.train()是一定要的,如果没有这些特殊层,这两句代码要不要都行
total_test_loss = 0
total_accuracy = 0 # 在测试集上的分类精度
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "../save_models/tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
如何查看tensorboard
在终端命令窗口使用以下命令打开所在的环境:conda activate my_pytorch_1
如果上面命令失败,则先初始化conda,使用以下命令:conda init
随后关闭终端重启,再次执行conda activate my_pytorch_1来打开环境
在当前环境下打开tensorboard,执行:tensorboard --logdir=logs_train
完成后将得到的链接复制到浏览器即可
'''十四、模型验证流程
这部分的目标是使用训练好并保存好的模型对样本进行预测,代码如下(在test.py文件中):
python
import torch
from model import *
import torchvision
from PIL import Image
image_path = "../imgs/bird.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()
])
image = transform(image)
print(image.shape)
model = torch.load("../save_models/tudui_9.pth", weights_only=False)
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
'''
知道了预测的序号如何查看它具体属于哪一类呢?
其实在数据集中(是一个类),其中有一个属性,其中包含着序号与具体类别的对应信息。
下面是查看数据集中这个属性的方法:
在train.py中在训练集数据下面好后打上断点,比如说打在第14行下载测试集数据那一行,
然后打开调试过程,在调试界面可以查看变量,查看train_data数据集,
其中有一个 class_to_idx 属性,其中包含着具体类别与索引号的对应关系
'''