1 什么是Sqoop?
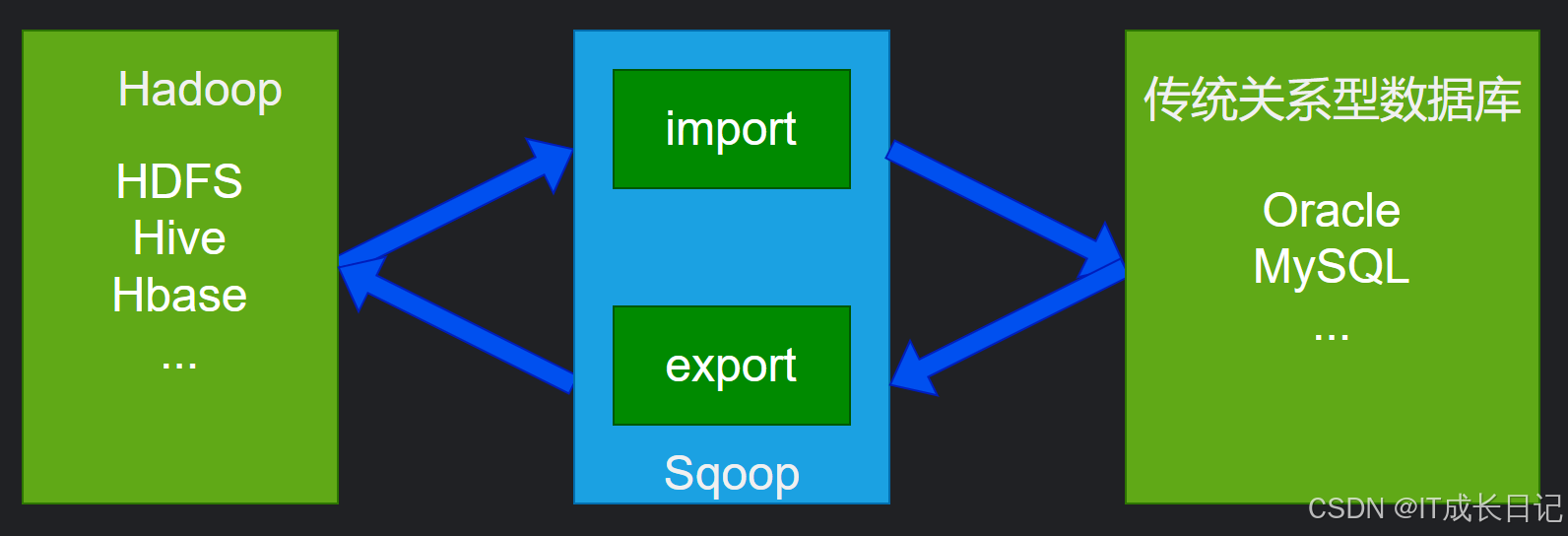
在企业的数据架构中,关系型数据库与Hadoop生态系统之间的数据流动是常见且关键的需求。Apache Sqoop(SQL-to-Hadoop)正是为解决这一问题而生的高效工具,它专门用于在结构化数据存储(如RDBMS)和Hadoop生态系统(如HDFS、Hive、HBase)之间 双向传输大规模数据集。
Sqoop的核心功能:
- 数据导入:将关系型数据库中的数据导入到Hadoop生态系统中,如HDFS、Hive或HBase
- 数据导出:将Hadoop生态系统中的数据导出到关系型数据库中
- 支持全量与增量导入:既可以一次性导入全部数据,也可以只导入新增或更新的数据,满足不同的业务需求
- 并行处理:利用MapReduce的并行处理能力,提高数据传输的速度和效率
- 数据格式转换:在导入导出过程中,支持多种数据格式的转换,如TextFile、Avro、Parquet等
2 Sqoop的核心价值
Sqoop(SQL-to-Hadoop)的核心价值主要体现在以下几个方面,这些价值点紧密围绕大数据处理与迁移的需求,为企业在数据整合、分析及应用方面提供了强有力的支持:
高效数据迁移:
- 跨平台支持:在关系型数据库(MySQL、Oracle等)与Hadoop生态(HDFS、Hive、HBase)间高效传输数据,支持全量和增量同步
- 高性能:基于并行处理与优化算法,显著提升海量数据迁移效率
简化数据集成:
- 自动化工具:通过命令行快速完成数据迁移,减少复杂脚本开发需求
- 降低人工成本:最小化手动操作,提高数据准确性与可靠性
多格式多存储兼容:
- 灵活格式:支持TextFile、Avro、Parquet等格式,适配不同分析场景
- 广泛存储支持:兼容HDFS、Hive、HBase及云存储
数据安全保障:
- 传输加密:保障敏感数据迁移过程中的安全性
- 权限管控:细粒度访问控制,限制未授权操作
生态集成与扩展性:
- 无缝对接Hadoop:与Hive、MapReduce等组件协同,构建完整数据处理链路
- 高可扩展:适应企业数据规模增长需求
成本优化:
- 开源免费:无许可费用,降低企业技术投入
- 资源高效利用:通过优化迁移流程,最大化集群资源利用率
3 工作原理剖析
Sqoop通过生成MapReduce作业来实现数据的导入和导出。具体过程如下:
导入过程:
- Sqoop连接到关系型数据库,获取元数据(如表结构、字段类型等)
- 根据指定的条件(如查询条件、分区列等),生成MapReduce作业
- MapReduce作业从数据库中读取数据,经过处理后写入到HDFS或其他Hadoop组件中
导出过程:
- Sqoop从Hadoop生态系统中读取数据
- 根据目标数据库的结构,生成相应的插入或更新语句
- 将数据写入到关系型数据库中
4.1 数据导入
sqoop import \
--connect jdbc:mysql://localhost:3306/mysql_db \ # 源数据库JDBC连接URL
--username root \ # 数据库用户名
--password 123456 \ # 数据库密码
--table mysqltable \ # 要导入的源表名
--target-dir /data/ \ # HDFS目标目录(存储导入数据)
--fields-terminated-by '\t' # 字段分隔符(默认逗号,此处指定为制表符)- 关键参数说明
|------------------------|---------------------------|
| 参数 | 说明 |
| --connect | 指定源数据库的JDBC连接字符串 |
| --table | 要导入的关系型数据库表名 |
| --target-dir | HDFS上存储导入数据的目录(需不存在,否则报错) |
| --fields-terminated-by | 生成文件的分隔符(如\t,,等) |
| --lines-terminated-by | 行分隔符(默认\n) |
| --null-string | 替换NULL字符串的占位符(如\\N) |
4.2 数据导出
sqoop export \
--connect jdbc:mysql://localhost:3306/data_warehouse \ # 目标数据库JDBC连接
--username user \ # 目标数据库用户名
--password pwd \ # 目标数据库密码
--table tablename \ # 目标表名(需提前创建)
--export-dir /results/ \ # HDFS源数据目录
--input-fields-terminated-by ',' # 输入文件字段分隔符- 关键参数说明
|------------------------------|------------------------------|
| 参数 | 说明 |
| --export-dir | HDFS中待导出数据的路径 |
| --input-fields-terminated-by | 输入文件的分隔符(需与导入时一致) |
| --update-key | 指定更新主键(如id,实现增量更新) |
| --update-mode | 更新模式(allowinsert或updateonly) |
4.3 高级功能
-
**增量导入(Incremental Import):**仅同步新增或修改的数据,避免全量导入
sqoop import
--connect jdbc:mysql://localhost:3306/mydb
--table orders
--check-column order_id \ # 增量检查列(通常为时间戳或自增ID)
--last-value "210001" \ # 上次导入的最大值
--incremental append \ # 增量模式(append或lastmodified)
--target-dir /data -
**Hive集成:**直接导入数据到Hive表,自动创建表结构
sqoop import
--connect jdbc:mysql://localhost:3306/mydb
--table products
--hive-import \ # 启用Hive导入
--hive-table ads_hive_h # 指定Hive数据库和表名 -
**压缩支持:**减少存储空间和I/O开销
--compress \ # 启用压缩(默认Gzip)
--compression-codec org.apache.hadoop.io.compress.SnappyCodec # 指定Snappy压缩 -
**自定义查询:**通过SQL语句灵活筛选源数据
sqoop import
--connect jdbc:mysql://localhost:3306/retail_db
--query "SELECT * FROM tablename"
--target-dir /data
5 Sqoop与传统ETL工具对比
|--------|---------------------------|-----------------------------------------|
| 对比维度 | Sqoop | 传统ETL工具 (如Informatica/Talend/DataStage) |
| 设计定位 | 专为Hadoop与关系数据库批量传输优化 | 企业级数据集成平台,支持复杂业务流程 |
| 架构特点 | 轻量级命令行工具,基于MapReduce/YARN | 可视化开发环境,集中式调度服务器 |
| 数据处理能力 | 结构化数据批处理 | 支持结构化/半结构化/非结构化数据,批处理+流处理 |
| 性能表现 | 大数据量并行传输优势明显(TB级) | 中小数据量事务处理更优,依赖硬件配置 |
| 扩展性 | 天然适配Hadoop生态横向扩展 | 垂直扩展为主,集群部署成本高 |
| 开发效率 | 简单场景配置快捷 | 复杂逻辑可视化开发效率高 |
| 调度管理 | 需外接调度系统(如Airflow) | 内置完善的任务调度和监控 |
| 数据转换能力 | 仅支持简单字段映射 | 提供丰富的数据清洗转换组件 |
| 实时能力 | 批处理为主(需结合Kafka等实现准实时) | 部分工具支持CDC实时同步 |
| 学习成本 | 命令行操作,技术门槛较低 | 需要掌握专用IDE和概念体系 |
| 成本投入 | 开源免费 | 商业授权费用高昂(部分提供社区版) |
| 典型适用场景 | Hadoop生态数据灌入/导出 | 企业级数据仓库建设,跨系统复杂集成 |
6 典型应用场景
数据仓库与数据湖构建:
场景需求:将关系型数据库历史数据迁移至Hadoop集群,建立分析型数据存储
Sqoop方案:支持全量/增量数据高效导入HDFS/Hive/HBase,为分析平台提供数据基础
大数据分析支持:
场景需求:为实时/离线分析提供数据源
Sqoop方案:定期同步业务数据到Hadoop生态,与Spark/Flink等计算引擎无缝集成
典型应用:机器学习特征工程,用户行为分析,实时报表生成
数据灾备方案:
场景需求:构建安全可靠的数据备份体系
Sqoop方案:利用Hadoop分布式存储特性实现数据库全量/增量备份
核心价值:3-2-1备份策略支持,PB级数据存储可靠性,快速恢复能力
系统迁移与整合:
场景需求:多源异构数据统一管理
Sqoop方案:跨数据库类型迁移(如Oracle→MySQL→HDFS)
实施优势:schema自动转换,数据一致性保证,最小化停机时间
准实时数据同步:
场景需求:业务系统与数据分析系统数据对齐
Sqoop方案:结合CDC工具实现分钟级延迟的数据管道
技术组合:Kafka+Sqoop+Spark Streaming架构,变更数据捕获(CDC)
多格式数据管理:
场景需求:适应不同分析场景的存储需求
Sqoop方案:
存储格式:支持Text/JSON/Parquet/Avro等
存储系统:兼容HDFS/Hive/HBase/云存储
业务价值:列式存储优化查询,压缩节省空间,schema演进支持
7 最佳实践建议
- 分区策略优化:选择高基数列作为拆分列
- 批量大小调整:平衡内存使用与性能
- 格式选择:生产环境推荐使用列式存储(如Parquet)
- 增量导入:对变化数据使用--incremental参数
- 错误处理:合理设置--num-mappers和错误容忍度
8 性能优化技巧
- 并行度控制:根据数据库负载能力调整mapper数量
- 直接模式:对MySQL使用--direct选项
- 缓存调优:适当增加fetch size减少网络往返
- 连接池配置:避免频繁创建数据库连接
- 压缩传输:减少I/O和网络开销
9 总结
Apache Sqoop作为Hadoop生态系统中数据桥梁的关键组件,在企业数据架构中仍然扮演着不可替代的角色。它简单而专注的设计理念,使其在特定场景下(特别是大规模批量数据传输)仍然保持着性能和可靠性的优势。