
本文继续接着我的上一篇博客【Python爬虫】简单案例介绍2-CSDN博客
目录
[3.3 代码开发](#3.3 代码开发)
3.3 代码开发
编写代码的步骤:
request请求科普中国网站地址url,解析得到类名为"list-block"的div标签。
for循环遍历这个div列表里的每个div,我们可以提取到文章标题,文章标题url,内容来源,内容来源url,发布时间,
再次request请求某个具体的文章的文章标题url,就可以请求得到具体文章的页面源代码,我们需要从中解析得到文章正文部分和图片的数量以及url链接。
这里主要介绍重要的函数。
(1)我们首先需要构建爬虫的大致框架,
python
# encoding=utf-8
import re, json, requests, xlwt, csv
import pandas as pd
from lxml import etree
from bs4 import BeautifulSoup
from openpyxl import Workbook
import numpy as np
"""科普中国-图文"""
class MySpider(object):
"""科普中国-图文"""
def __init__(self):
self.base_url = 'https://cloud.kepuchina.cn/newSearch/imageText?s=&start_time=&end_time=&type=1&keyword=&can_down=0&category_id=0&page='
self.url = self.base_url + str(0)
self.headers = {
'User-Agent': '此处为你的UA'
}
self.index_list = []
self.index_article = {}
def get(self, url):
"""请求并返回网页源代码"""
pass
def parse(self, start_page, pages_num):
"""
解析科普中国网站地址url
:param start_page: 开始页面
:param pages_num: 想要爬取的页面数量
:return:
"""
pass
def writeDataToExcleFile(self, inputData, outPutFile):
'''
将列表数据写入excel表格文件
inputData: 列表,含有多个字典;例如:[{'key_a':'123'},{'key_b':'456'}]
outPutFile:输出文件名,例如:'data.xlsx'
'''
pass
def parse_page(self, title_url):
"""
进一步解析页面,得到页面的文本content和图片数量以及地址
:param title_url: 文章标题的网页地址
:return:
"""
pass
def main(self):
"""
主函数
:return:
"""
self.get()
self.parse()
if __name__ == "__main__":
spider = MySpider()
spider.main()(2)编写get()函数,该函数的主要作用是request请求科普中国网站地址url并得到响应结果。
python
def get(self, url):
"""请求并返回网页源代码"""
try:
response = requests.get(url, self.headers)
if response.status_code == 200:
return response.text
except Exception as err:
print('get():', err)(3)编写save_excel()函数,该函数的主要作用是将我们获取到的数据写入excel表格文件。
python
def parse_page(self, title_url):
"""
进一步解析页面,得到页面的文本content和图片数量以及地址
:param title_url: 文章标题的网页地址
:return:
"""
response = requests.get(title_url, self.headers)
try:
if response.status_code == 200:
response = response.text
soup = BeautifulSoup(response, 'html.parser')
content = self.clean(soup.find('div', class_="video-box content-box").text) # 页面的文本content
# 图片数量以及地址
try:
img_url = []
for t in soup.findAll('img'):
if 'logo' not in t["src"] and 'wechat' not in t["src"] and 'weibo' not in t["src"]:
img_url.append(t["src"])
except Exception as err:
img_url = []
img_num = len(img_url) # 图片数量
self.index_article["content"] = content
self.index_article["img_num"] = img_num
self.index_article["img_url"] = img_url
except Exception as err:
print('parse_page:', err)(4)现在开始正式编写parse()函数,该函数的主要作用是可以根据输入的参数(开始页面,想要爬取的页面数量),来对科普中国网站的页面进行请求(内部调用了self.get()函数)和解析,以及将解析得到的数据进行存储(内部调用了self.save_excel()函数)。
python
def parse(self, start_page, pages_num):
"""
解析科普中国网站地址url
:param start_page: 开始页面
:param pages_num: 想要爬取的页面数量
:return:
"""
for page in range(start_page, start_page+pages_num):
# 将获取的页面源码加载到该对象中
soup = BeautifulSoup(self.get(self.base_url + str(page)), 'html.parser')
# 拿到数据列表
for i in soup.findAll('div', class_="list-block _blockParma"):
# 创建 BeautifulSoup 对象
soup_i = BeautifulSoup(str(i), 'html.parser')
# 提取文章标题和url、副标题、tag、发布者、发布时间
title = soup_i.find('a', class_='_title').text
title_url = soup_i.find('a', class_='_title')['href']
subtitle = soup_i.find('p', class_='info').find('a').text
tags = [a.text for a in soup_i.find_all('a', class_='typeColor')]
publisher = soup_i.find('a', class_='source-txt').text.strip()
publish_time = soup_i.find('span', class_='_time').text
self.index_article = {"title": title, "title_url": title_url, "subtitle": self.clean(subtitle), "tag": tags, "publisher": publisher, "publish_time": publish_time}
# 获得文章内容文本content和图片数量以及地址
self.parse_page(title_url)
if self.index_article not in self.index_list: # 存入列表
self.index_list.append(self.index_article)
print("已完成" + str(page+1) + "页的存储")
# self.get_json(str(self.index_list), "1.json")
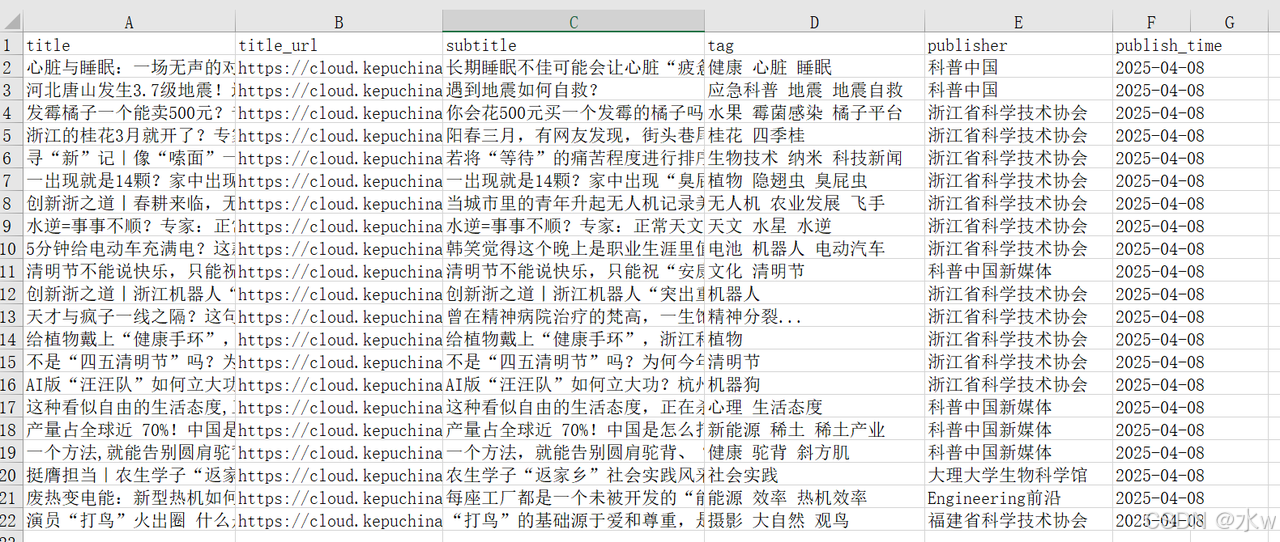
self.save_excel(self.index_list, "result_" + str(start_page) + "_" + str(pages_num) + ".xlsx")代码执行结果如下:
(5)编写parse_page()函数,我们需要进一步解析页面,因为需要得到页面的文本content和图片数量以及url。
python
def parse_page(self, title_url):
"""
进一步解析页面,得到页面的文本content、图片数量以及地址
:param title_url: 文章标题的网页地址
:return:
"""
response = requests.get(title_url, headers=self.headers)
try:
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 获取文章主体内容,根据新HTML结构调整选择器
content_div = soup.find('div', class_='content-box __imgtext-content')
if content_div:
content = self.clean(content_div.text)
else:
content = ""
# 图片数量以及地址,过滤掉不需要的图片来源(如含特定关键词的图片)
img_url = []
all_imgs = soup.find_all('img')
for img in all_imgs:
src = img.get('src')
if src and 'kepuyun' in src and 'logo' not in src and 'wechat' not in src and 'weibo' not in src:
img_url.append(src)
img_num = len(img_url)
self.index_article["content"] = content
self.index_article["img_num"] = img_num
self.index_article["img_url"] = img_url
else:
print(f"请求失败,状态码: {response.status_code}")
except Exception as err:
print('parse_page:', err)代码执行结果如下:

OK,一个简单的案例就到此结束了。