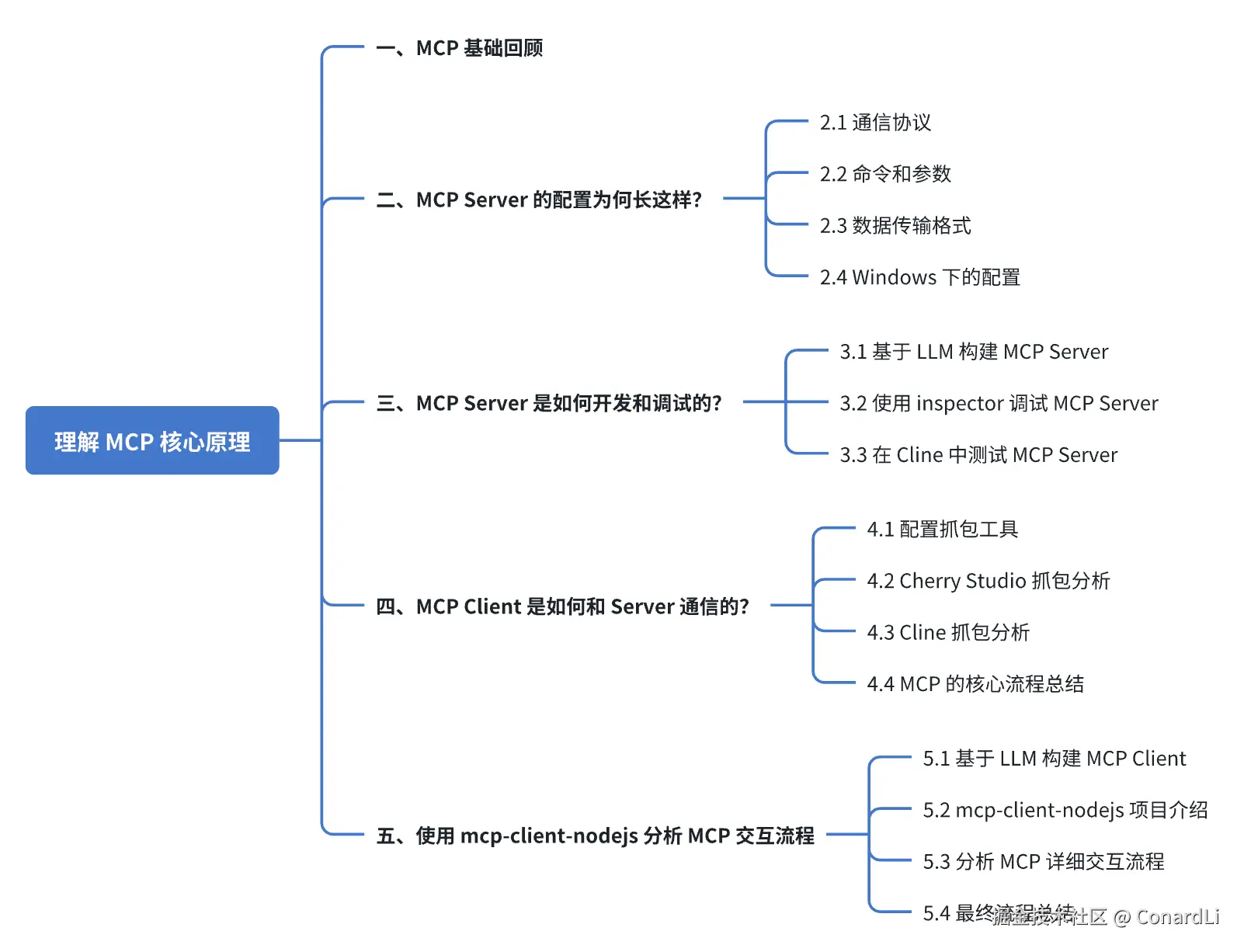
- MCP 是如何做到统一工具调用方式的?
- MCP 客户端和 MCP Server 到底是怎么交互的?
- 为什么有的 MCP 客户端支持所有模型,有的确不行?
大家好,欢迎来到 code秘密花园,我是花园老师(ConardLi)。
为了方便大家更深度的理解 MCP ,在今天这一期,我们用几个例子来一起学习 MCP 的核心原理。
在上一期 《MCP+数据库:一种提高结构化数据检索效果的新方式》,我们一起学习了 MCP 的基础知识,包括
- MCP 基础知识,和 Function Call 的关系
- 了解 MCP Clinet、MCP Server 等核心概念
- 在 Cherry Studio 中简单尝试了 MCP
- 在 Cline 中基于 mongo-mcp-server 实现了结构化数据的精准检索
还没学习的同学建议先阅读完上一期再回来看这一期,今天我们的学习大纲如下:
下面我们先回顾一下 MCP 的基础知识:
一、MCP 基础回顾
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 公司(也就是开发 Claude 模型的公司)推出的一个开放标准协议,就像是一个 "通用插头" 或者 "USB 接口",制定了统一的规范,不管是连接数据库、第三方 API,还是本地文件等各种外部资源,目的就是为了解决 AI 模型与外部数据源、工具交互的难题。
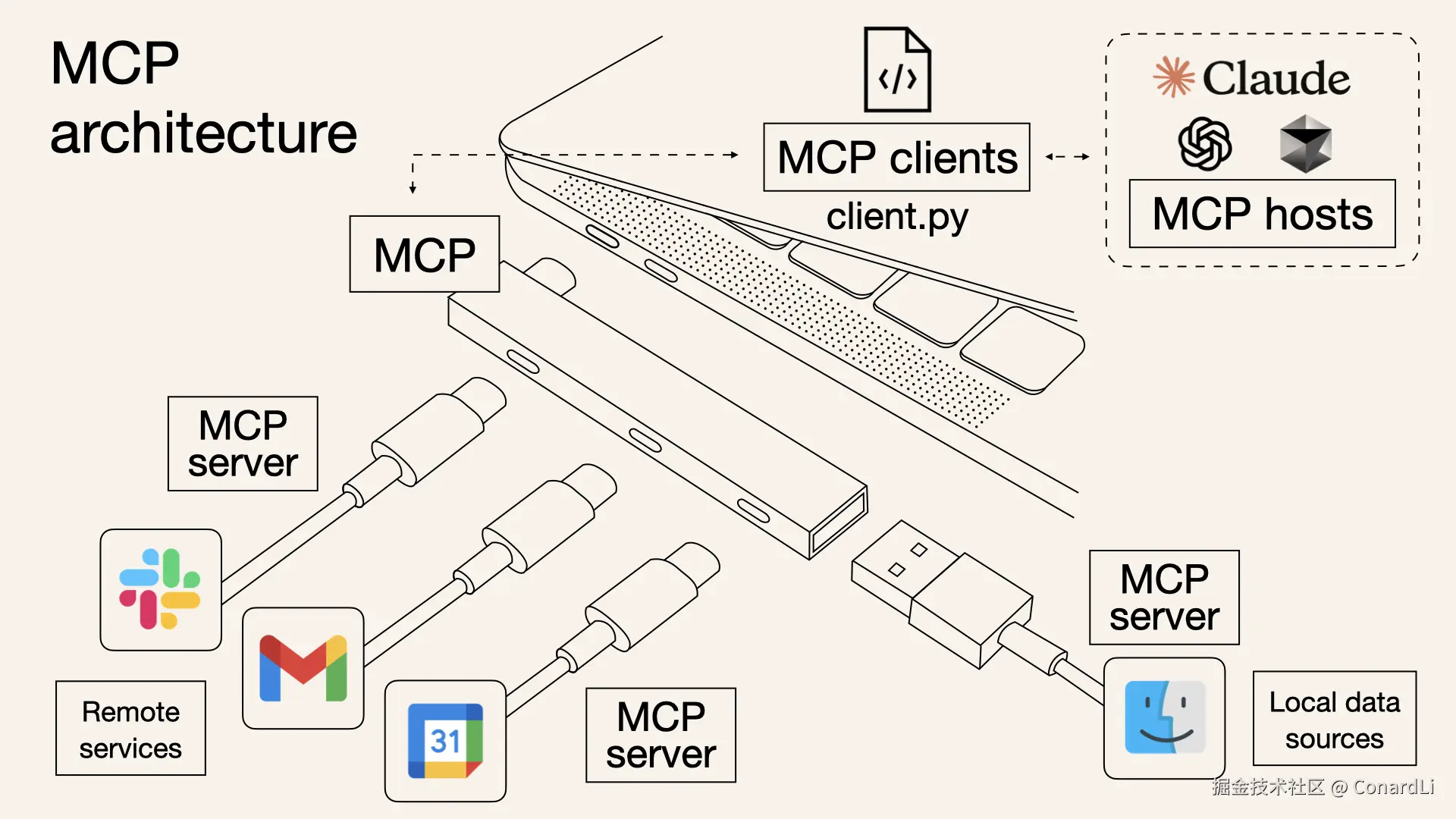
MCP 大概的工作方式:MCP Host,比如 Claude Desktop、Cursor 这些工具,在内部实现了 MCP Client,然后MCP Client 通过标准的 MCP 协议和 MCP Server 进行交互,由各种三方开发者提供的 MCP Server 负责实现各种和三方资源交互的逻辑,比如访问数据库、浏览器、本地文件,最终再通过 标准的 MCP 协议返回给 MCP Client,最终在 MCP Host 上展示。
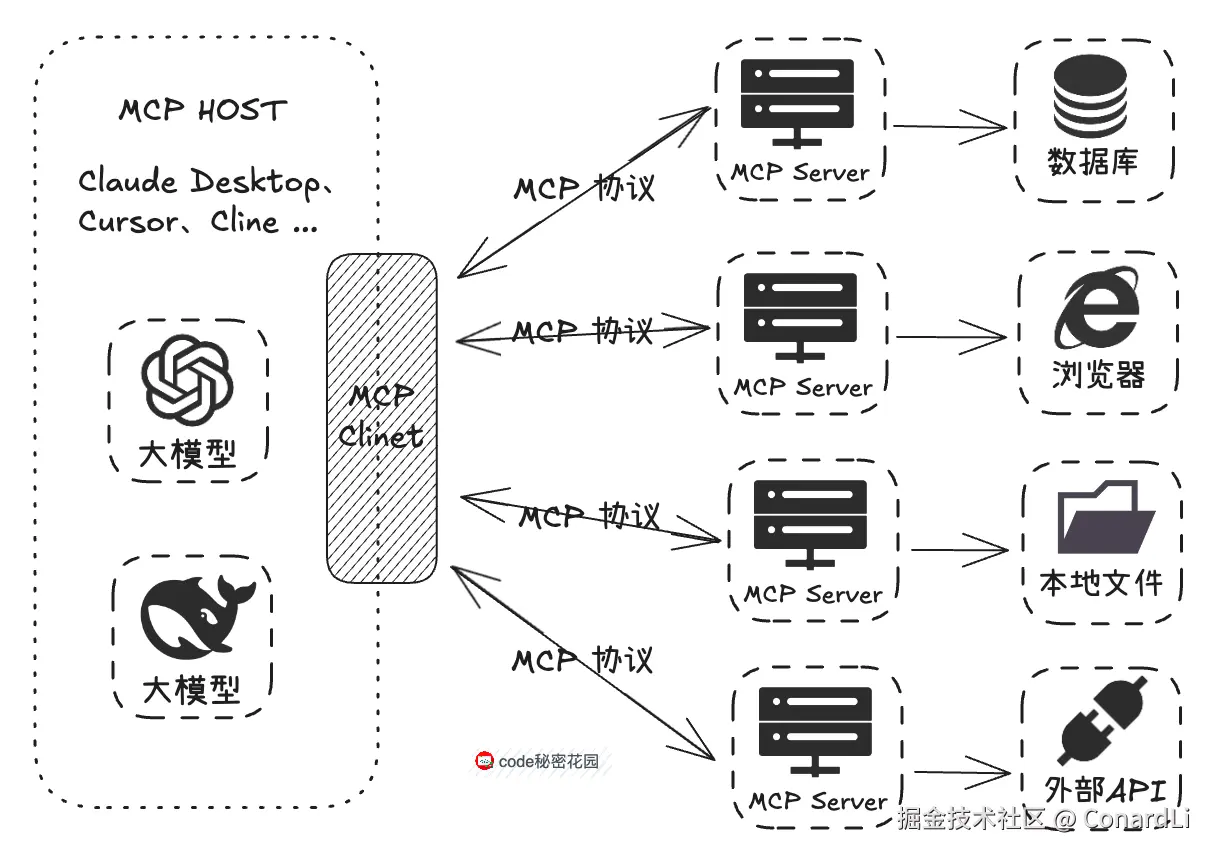
开发者按照 MCP 协议进行开发,无需为每个模型与不同资源的对接重复编写适配代码,可以大大节省开发工作量,另外已经开发出的 MCP Server,因为协议是通用的,能够直接开放出来给大家使用,这也大幅减少了开发者的重复劳动。
首先一步,我们先从 MCP Server 的配置讲起,弄懂 MCP Server 的配置为什么是这样设计的。
二、MCP Server 的配置为何长这样?
我们使用 Cherry Studio 中的 MCP 服务配置来举例,最前面的名称和描述比较好理解,都是用于展示的。
2.1 通信协议
下面我们发现有两个类型,STDIO 和 SSE:
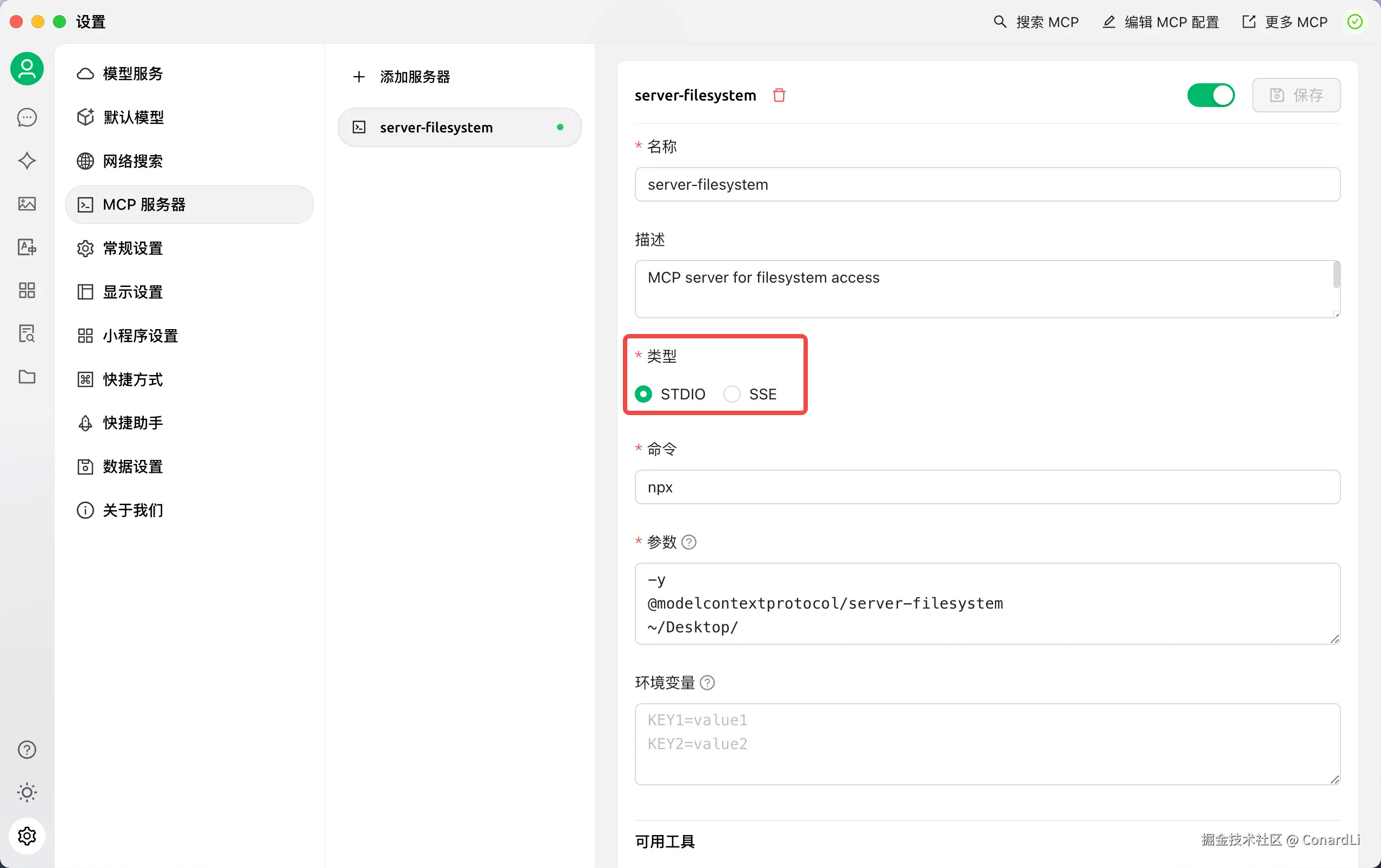
MCP 协议中的 STDIO 和 SSE 其实就是是两种不同的(MCP Server 与 MCP Client)通信模式:
- STDIO(标准输入输出):像「面对面对话」:客户端和服务器通过本地进程的标准输入和标准输出直接通信。例如:本地开发时,你的代码脚本通过命令行启动,直接与 MCP 服务器交换数据,无需网络连接。
- SSE(服务器推送事件):像「电话热线」:客户端通过 HTTP 协议连接到远程服务器,服务器可以主动推送数据(如实时消息)。例如:AI 助手通过网页请求调用远程天气 API,服务器持续推送最新的天气信息。
简单理解,STDIO 调用方式是将一个 MCP Server 下载到你的本地,直接调用这个工具,而 SSE 则是通过 HTTP 服务调用托管在远程服务器上的 MCP Server。
这就是一个 SSE MCP Server 的配置示例,非常简单,我们直接使用网络协议和工具进行通信:
json
{
"mcpServers": {
"browser-use-mcp-server": {
"url": "http://localhost:8000/sse"
}
}
}而我们之前用到的 FileSystem、Mongodb 都属于典型的 STDIO 调用:
json
{
"mcpServers": {
"mongodb": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"~/Downloads"
]
}
}
}STDIO 为程序的输入输出提供了一种统一的标准方式,无论是什么类型的程序,只要遵循 STDIO 协议,就可以方便地进行数据的输入和输出,并且可以很容易地与其他程序或系统组件进行交互。
在命令行中,使用 STDIO 通信是非常常见的,比如 Linux 系统中的 cat 命令就是一个极为简单且能体现 STDIO 通信的例子。cat 命令通常用于连接文件并打印到标准输出。当你不指定任何文件时,它会从标准输入读取内容,并将其输出到标准输出。
打开终端,输入 cat 命令,然后按下回车键。此时,cat 命令开始等待你从标准输入(通常是键盘)输入内容。你可以输入任意文本,每输入一行并按下回车键,cat 会立即将这行内容输出到标准输出。
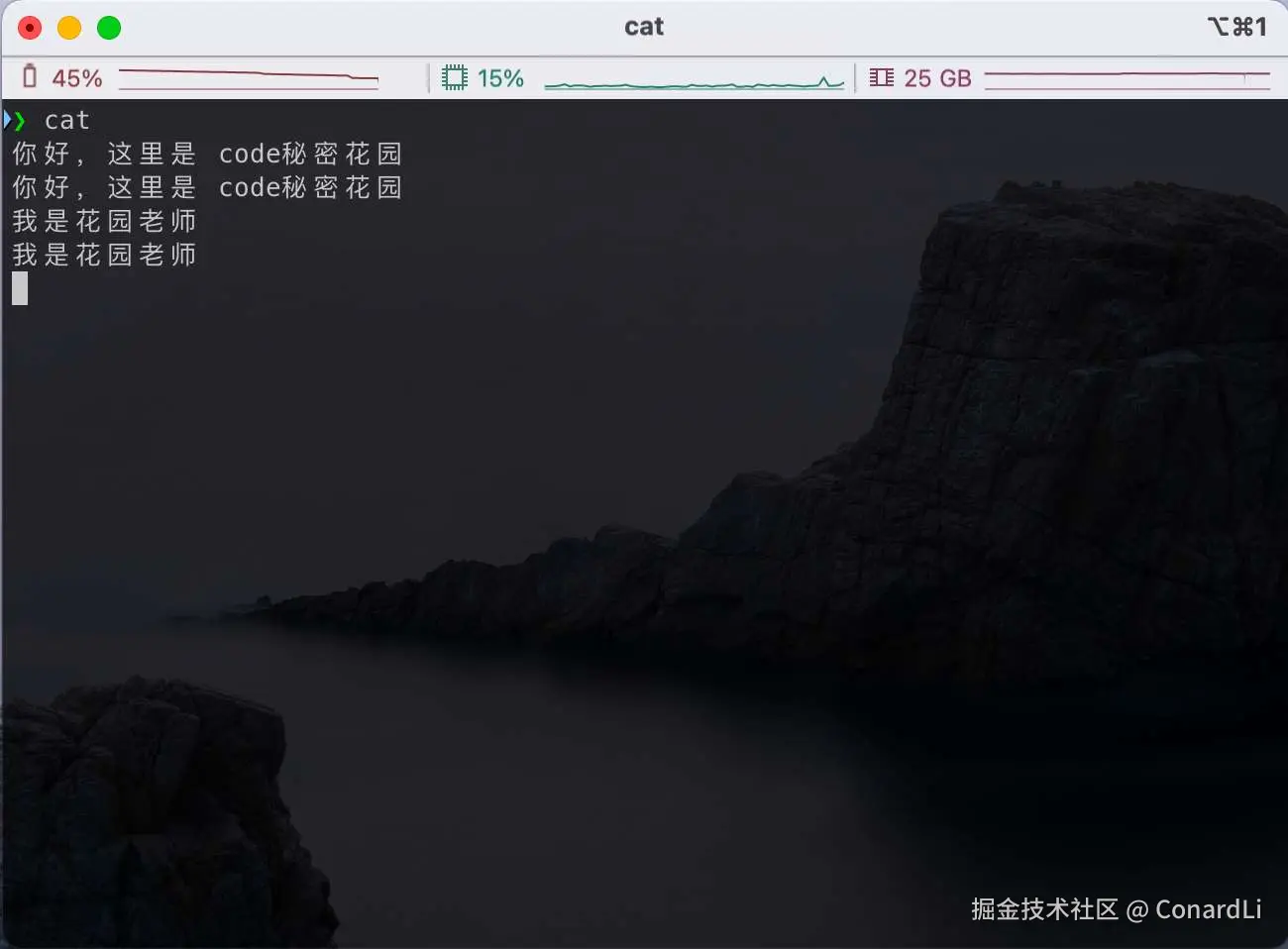
在这个例子中,你输入了 你好,这里是 code秘密花园! 和 我是花园老师,cat 命令将这些内容从标准输入读取后,马上输出到标准输出。
我们还能借助一些操作符,比如重定向操作符 > 将标准输出重定向到文件。下面的例子会把你输入的内容保存到 test.txt 文件里:
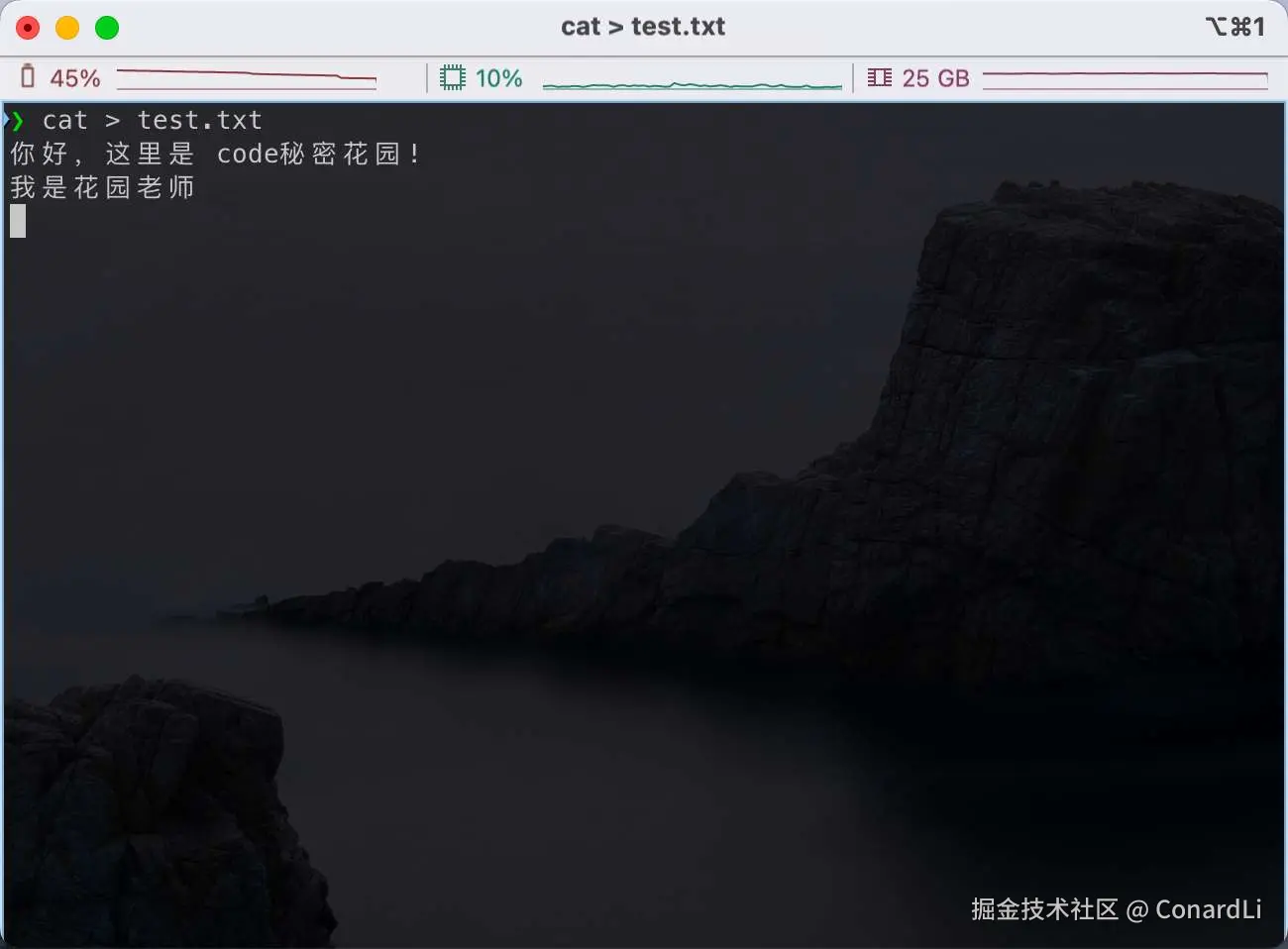
上述命令执行后,test.txt 文件里会包含你输入的两行内容:
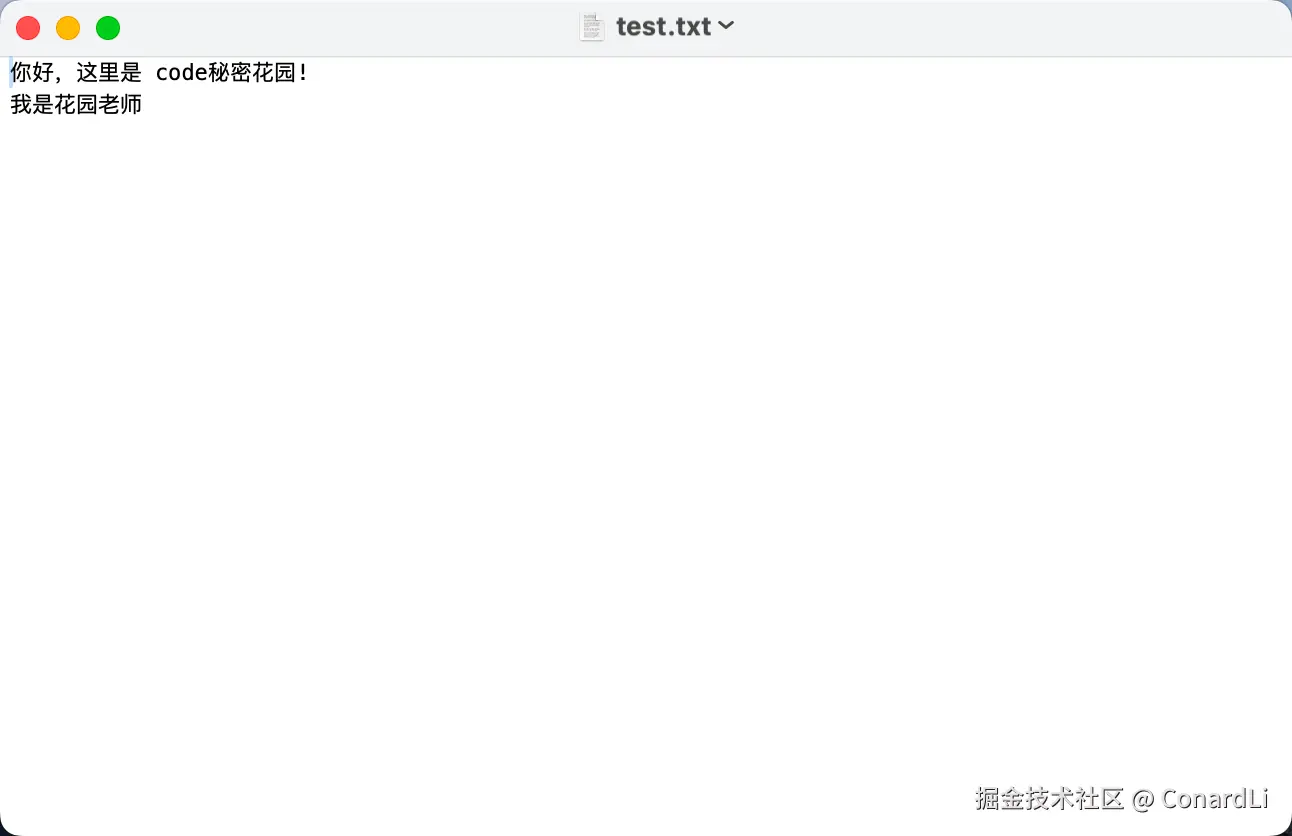
在这个过程中,cat 命令从标准输入读取内容,接着将输出重定向到文件,这就是一个最简单的 STDIO 通信案例。
2.2 命令和参数
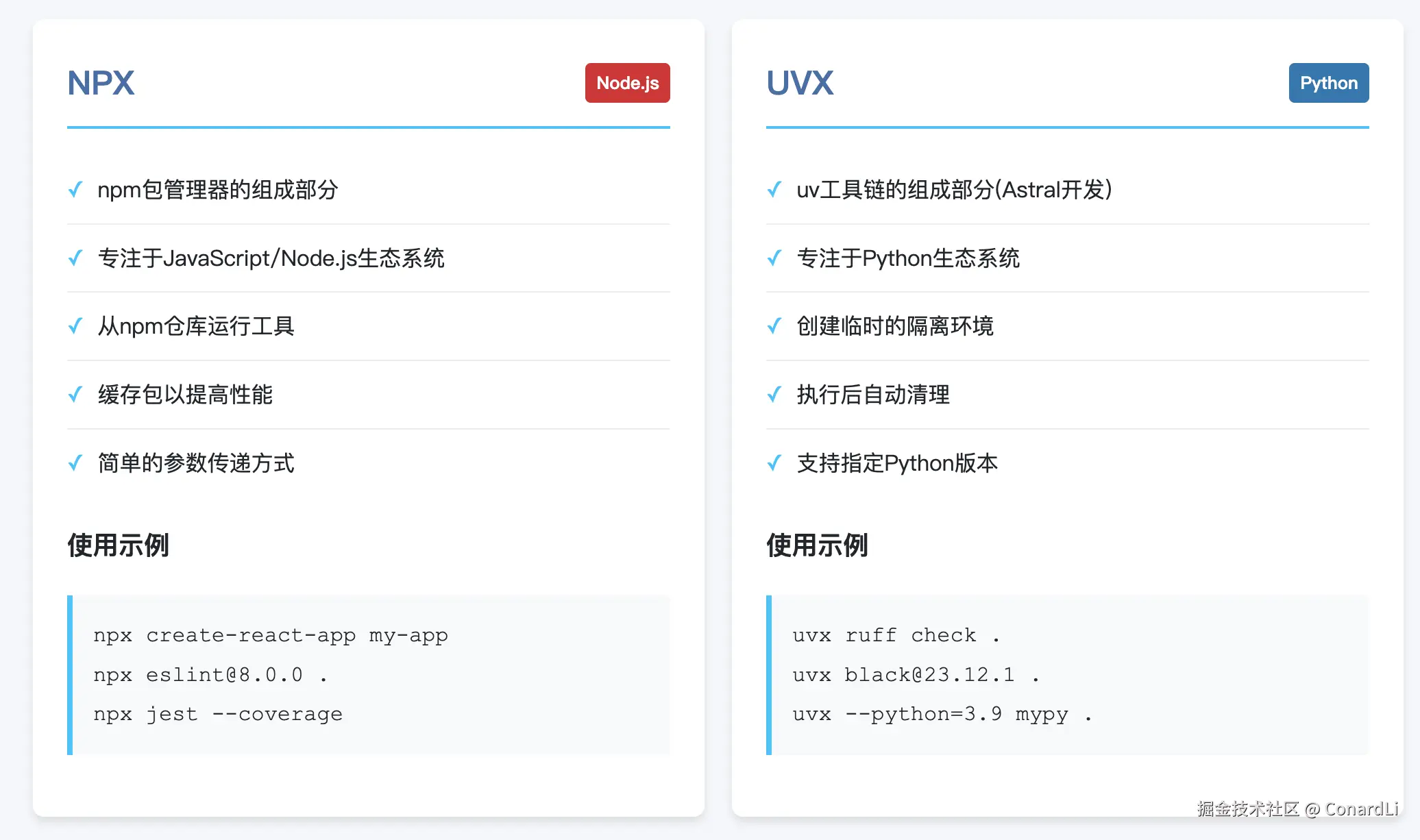
下面再来说说配置里的命令,对应 JSON 配置中的 command 参数,在没有填写时,这里默认推荐的是 uvx 和 npx:
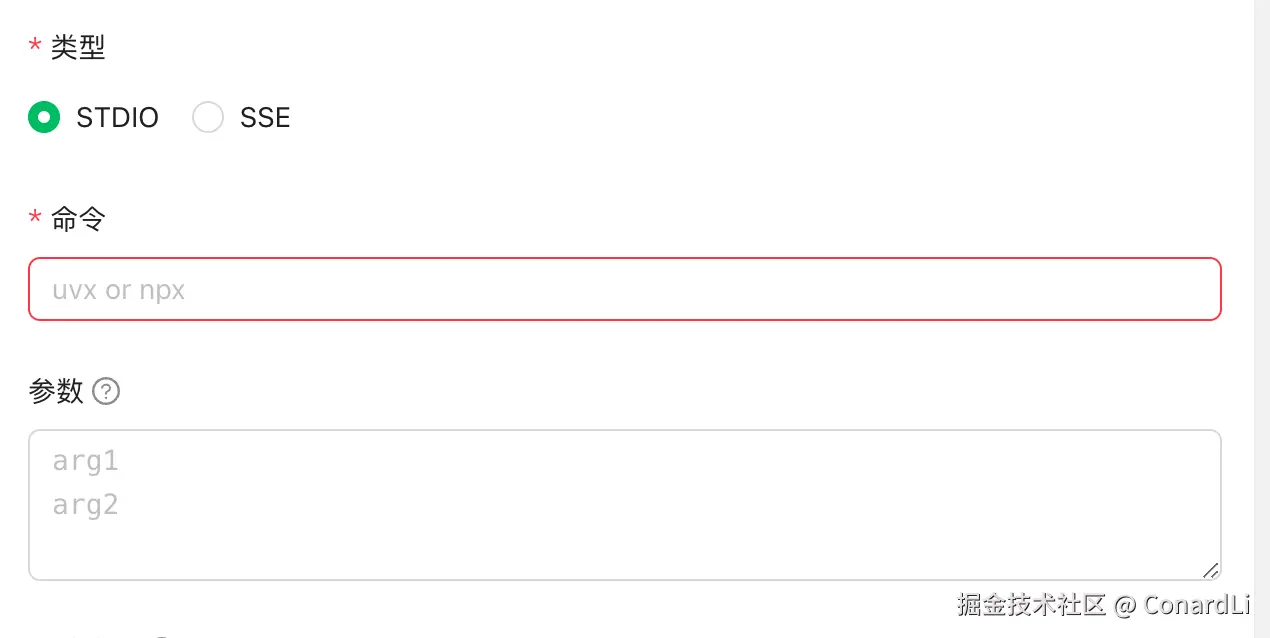
在之前 mongodb 的例子中, command 使用的就是 npx ,之前我们提到了,只要安装了 Node.js 环境,就可以使用,那为什么这里不写 node,而要用 npx 命令呢?
npx 是 Node.js 生态系统中的一个命令行工具,它本质上是 npm的一个扩展。npx 的名字可以理解为"运行一个包"(npm execute package)的缩写。
简单来说,npx 的主要功能就是帮助我们快速运行一些通过 npm 安装的工具,而不需要我们手动去下载安装这些工具到全局环境。
json
{
"mcpServers": {
"mongodb": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"~/Downloads"
]
}
}
}在这个配置中,args 里第一个参数 "-y" 其实就等同于 --yes,其作用是在执行命令时自动同意所有提示信息,可以避免交互式的确认步骤。
而第二个参数其实就是这个 npm 包的名字,比如 @modelcontextprotocol/server-filesystem 这个包:
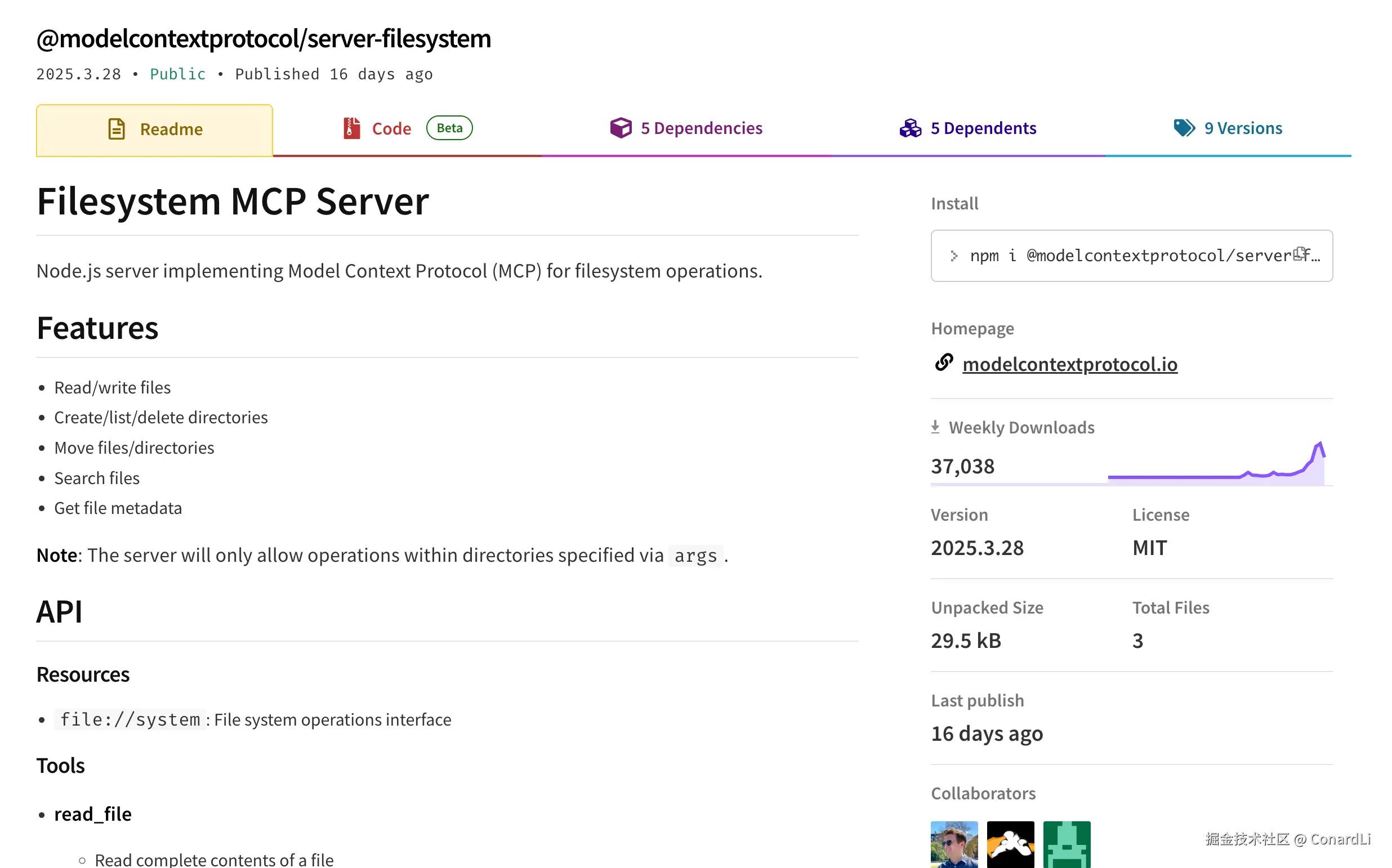
args 里的第三个参数其实就是传递给这个包的一个必备参数:允许读取的本机路径。
这样理解其实就能说得通了,这几个信息,再加上大模型分析用户输入后得出的参数,通过 STDIO 协议传递给这个包,其实就可以构成一条在终端直接可以运行的一条命令:
bash
npx -y @modelcontextprotocol/server-filesystem ~/Downloads <<< '{"method":"tools/call","params":{"name":"list_directory","arguments":{"path":"~/Downloads"}},"jsonrpc":"2.0","id":1}'我们测试执行一下:
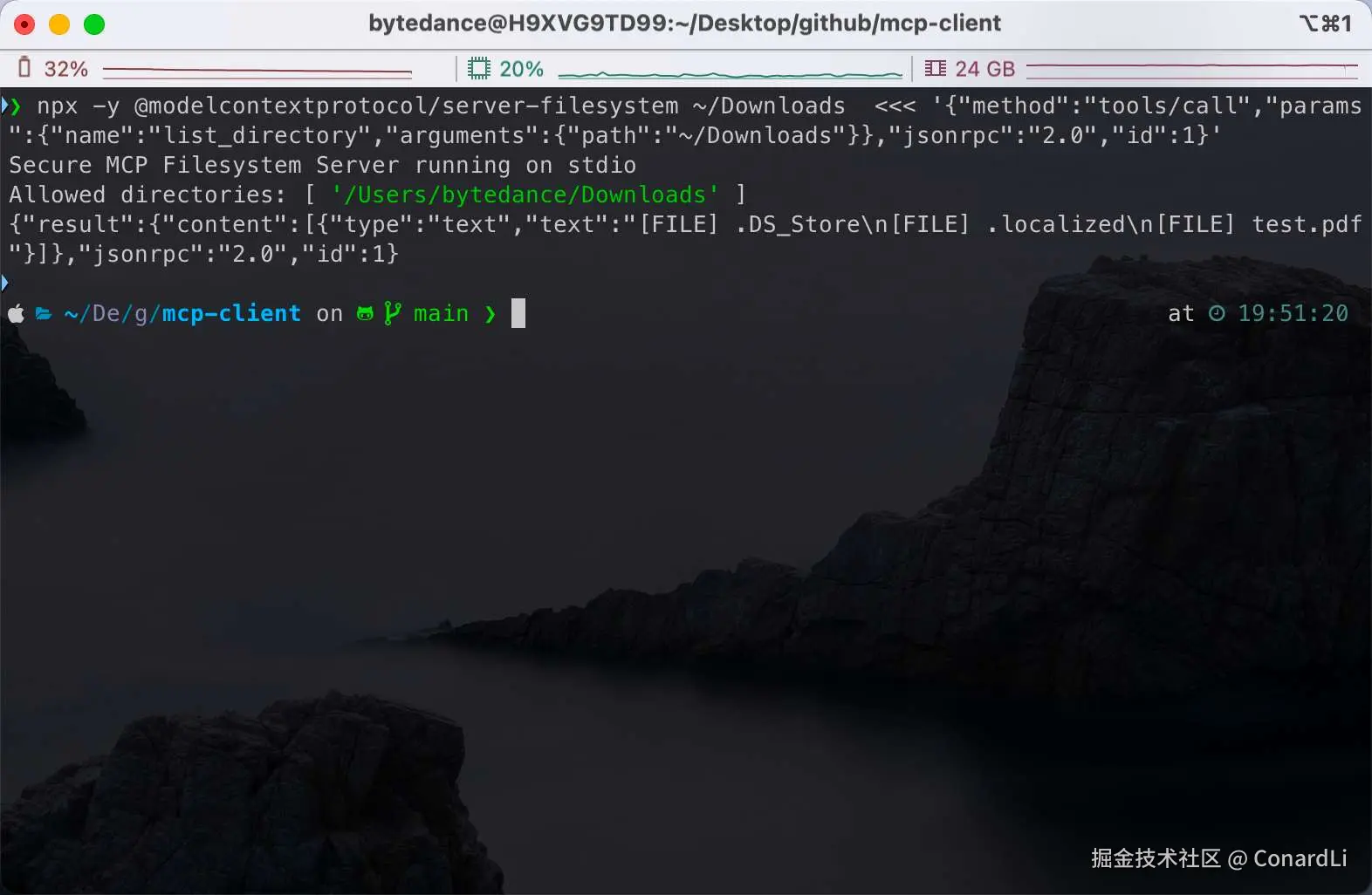
我们把输入内容格式化一下:

<<<(Here 字符串操作符)的主要用途是将一个字符串作为标准输入(STDIN)传递给前面的命令。
在这个命令中,我们通过 <<< 操作符,把后面的字符串传递给前面的命令(也就是 @modelcontextprotocol/server-filesystem 这个包)当作输入数据。
后面的字符串中包含了需要调用的函数(list_directory),以及传递给这个函数的参数(~/Downloads),
前面的部分都是我们在 MCP Server 中配置的内容,属于固定的部分。而大模型做的,就是根据用户当前的输入,以及当前支持的 MCP 工具列表,判断出要不要调用这个工具,如果要调用,生成结构化的工具参数,最后 MCP Client 通过 STDIO 协议将这个结构化的参数再传递给 MCP Server。
在上面的命令中,还有一个选项是 uvx,和 npx 类似,它也可以直接让你临时执行某个工具包,而无需全局安装。不过 uvx:是 uv 工具链的一部分,主要聚焦于 Python 生态系统,它会创建一个临时的隔离 Python 环境来运行 Python 工具包。
2.3 传输格式
我们再来看看刚刚的命令执行的结果:
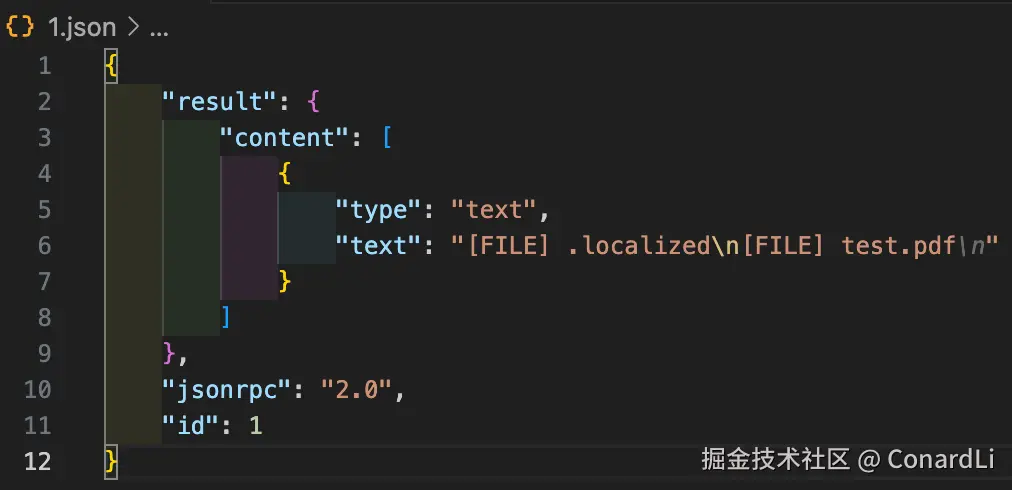
也是一段格式化好的内容,里面返回了当前目录下的所有文件,而模型在接收到这段格式化的输出后,会将其变成口语化的内容再返回到 MCP 客户端。
这个输入、输出的参数格式,遵循的是 JSON-RPC 2.0 传输格式,它有一套自己的规则,规定了请求和响应的格式、如何处理错误等,官方文档的中的描述:

2.4 Windows 下的配置
在实际使用中,大家可能会发现,下面的配置在 Windows 下可能不会生效
json
{
"mcpServers": {
"mongodb": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"~/Downloads"
]
}
}
}需要改成下面的方式:
json
{
"mcpServers": {
"mongodb": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@modelcontextprotocol/server-filesystem",
"~/Downloads"
]
}
}
}这是因为在不同操作系统下 默认命令解释器(Shell)的工作机制不同:
macOS 的终端(如 bash/zsh)是 Unix shell,支持直接执行可执行文件(如 npx)。
Windows 的默认命令解释器是 cmd.exe,而非直接执行程序。即使 npx 已安装(如通过全局 npm install -g npx),也需要通过 cmd.exe 来调用,因为:
- Windows 不直接识别 Unix 风格的命令路径(如
npx本质是 Node.js 脚本,需通过node执行)。 cmd.exe需要明确的指令格式(如/c参数用于执行命令后退出)。
args 中的 /c 是 cmd.exe 的参数,表示"执行后续命令后关闭窗口"。完整的执行流程是:
bash
cmd.exe /c npx -y @modelcontextprotocol/server-filesystem "~/Downloads"这里
cmd.exe先解析/c,再将npx ...作为子命令执行,确保 Windows 能正确调用 Node.js 脚本(npx)。
通过分析 MCP Server 的配置,我们了解了 MCP Clinet 和 MCP Server 的通信协议、执行的命令和参数,以及两者数据传输的标准格式,这样 MCP Clinet 和 MCP Server 的交互方式我们基本上就弄清楚了。
那执行 MCP Server 我们一定要通过 npx 或 uvx 运行一个包吗?
当然不是,实际上任何能够在命令行执行代码的方式,都是可以的,比如我们可以直接把一个 MCP Server 的仓库拉取到本地,然后通过 node 或 python 命令直接执行里面的代码文件,这样就可以实现完全断网运行(前提是 MCP Server 中不会调用远程 API)。
json
{
"mcpServers": {
"mongodb": {
"command": "node",
"args": [
"/path/mcp-server.js"
]
}
}
}下面,我们在本地实现一个最简单的例子,来教大家如何构建一个 MCP Server。
三、MCP Server 是如何开发和调试的?
3.1 基于 AI 辅助编写 MCP Server
在官方文档(modelcontextprotocol.io/quickstart/... MCP Server 的开发方式,以及官方提供的各个语言的 SDK 的示例代码:
写的挺清晰的,如果你懂代码,仔细看一遍很快就能上手,但在 AI 时代,从零自己去写肯定不可能了,官方其实也建议通过 AI 来帮我们实现 MCP,所以在文档中单独还提供了一个 Building MCP with LLMs 的章节。
大概思路如下:
::: block-1 在开始之前,收集必要的文档,以帮助 AI 了解 MCP:
- 访问 modelcontextprotocol.io/llms-full.t... 并复制完整的文档文本。
- 导航到 MCP 的 TypeScript 软件开发工具包(SDK)或 Python 软件开发工具包的代码仓库。
- 复制(README)和其他相关文档。
- 将这些文档粘贴到你与克劳德的对话中。
提供了相关文档之后,向 AI 清晰地描述你想要构建的服务器类型:
- 你的服务器将公开哪些资源。
- 它将提供哪些工具。
- 它应该给出的任何提示。
- 它需要与哪些外部系统进行交互。
比如这是一个例子:构建一个 MCP 服务器,该服务器:
- 连接到我公司的 PostgreSQL 数据库。
- 将表模式作为资源公开。
- 提供用于运行只读 SQL 查询的工具。
- 包含针对常见数据分析任务的提示。 :::
在实际测试中我发现,上面提到的 modelcontextprotocol.io/llms-full.t... 这个文档就是整个文档站的内容,里面包含了很多构建 MCP Server 不需要的内容,反而会给模型造成干扰,大家可以直接参考我的提示词:
markdown
## 需求
基于提供的 MCP 相关资料,帮我构建一个 MCP Server,需求如下:
- 提供一个获取当前时间的工具
- 接收时区作为参数(可选)
- 编写清晰的注释和说明
- 要求功能简洁、只包含关键功能
- 使用 TypeScript 编写
请参考下面四个资料:
## [参考资料 1] MCP 基础介绍
- 粘贴 https://modelcontextprotocol.io/introduction 里的内容。
## [参考资料 2] MCP 核心架构
- 粘贴 https://modelcontextprotocol.io/docs/concepts/architecture 里的内容。
## [参考资料 3] MCP Server 开发指引
- 粘贴 https://modelcontextprotocol.io/quickstart/server 里的内容。
## [参考资料 4] MCP Typescript SDK 文档
- 粘贴 https://github.com/modelcontextprotocol/typescript-sdk/blob/main/README.md 里的内容。下面是一个 AI 帮我生成好的 MCP Server 的关键代码:
js
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const server = new McpServer({
name: "TimeServer", // 服务器名称
version: "1.0.0", // 服务器版本
});
server.tool(
"getCurrentTime", // 工具名称,
"根据时区(可选)获取当前时间", // 工具描述
{
timezone: z
.string()
.optional()
.describe(
"时区,例如 'Asia/Shanghai', 'America/New_York' 等(如不提供,则使用系统默认时区)"
),
},
async ({ timezone }) => {
// 具体工具实现,这里省略
}
);
/**
* 启动服务器,连接到标准输入/输出传输
*/
async function startServer() {
try {
console.log("正在启动 MCP 时间服务器...");
// 创建标准输入/输出传输
const transport = new StdioServerTransport();
// 连接服务器到传输
await server.connect(transport);
console.log("MCP 时间服务器已启动,等待请求...");
} catch (error) {
console.error("启动服务器时出错:", error);
process.exit(1);
}
}
startServer();其实代码非常简单,我们可以拆分为三部分来理解:
第一步:使用官方提供的 @modelcontextprotocol/sdk/server/mcp.js 包,创建一个 McpServer 实例:
js
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
/**
* 创建 MCP 服务器实例
*/
const server = new McpServer({
name: "TimeServer", // 服务器名称
version: "1.0.0", // 服务器版本
});第二步:使用 server.tool 定义提供的工具方法,包括工具方法的名称、工具方法的描述、工具方法的参数、工具方法的具体实现逻辑。
另外使用了 "zod" 这个包定义了方法参数的类型以及描述。
js
import { z } from "zod";
server.tool(
"getCurrentTime", // 工具名称,
"根据时区(可选)获取当前时间", // 工具描述
{
timezone: z
.string()
.optional()
.describe(
"时区,例如 'Asia/Shanghai', 'America/New_York' 等(如不提供,则使用系统默认时区)"
),
},
async ({ timezone }) => {
// 具体工具实现,这里省略
}
);第三步:启动 Server,并且使用 SDK 中导出的 StdioServerTransport 来定义工具使用 STDIO 通信协议,等待外部的标准输入,并且把工具的执行结果转化为标准输出反馈到外部。
js
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
/**
* 启动服务器,连接到标准输入/输出传输
*/
async function startServer() {
try {
console.log("正在启动 MCP 时间服务器...");
// 创建标准输入/输出传输
const transport = new StdioServerTransport();
// 连接服务器到传输
await server.connect(transport);
console.log("MCP 时间服务器已启动,等待请求...");
} catch (error) {
console.error("启动服务器时出错:", error);
process.exit(1);
}
}
startServer();就是这么简单,我们只需要按照这个模板来添加更多的工具实现就可以了,另外 Resources、Prompt 的编写方式其实都是类似的,大家只需要按照这套提示词模板,定义好自己的需求,AI(Claude 的准确性最高)基本上都能比较完整的实现。
3.2 使用 inspector 调试 MCP Server
开发完成后,我们可以直接使用官方提供的 MCP Server 调试工具(@modelcontextprotocol/inspector)来进行调试。
我们也可以直接通过 npx 运行 @modelcontextprotocol/inspector:
bash
npx @modelcontextprotocol/inspector <command> <arg1> <arg2>比如我们可以调试我们刚刚开发好的工具,这里直接使用 node 运行我们本地构建好的代码:
bash
npx @modelcontextprotocol/inspector node dist/index.js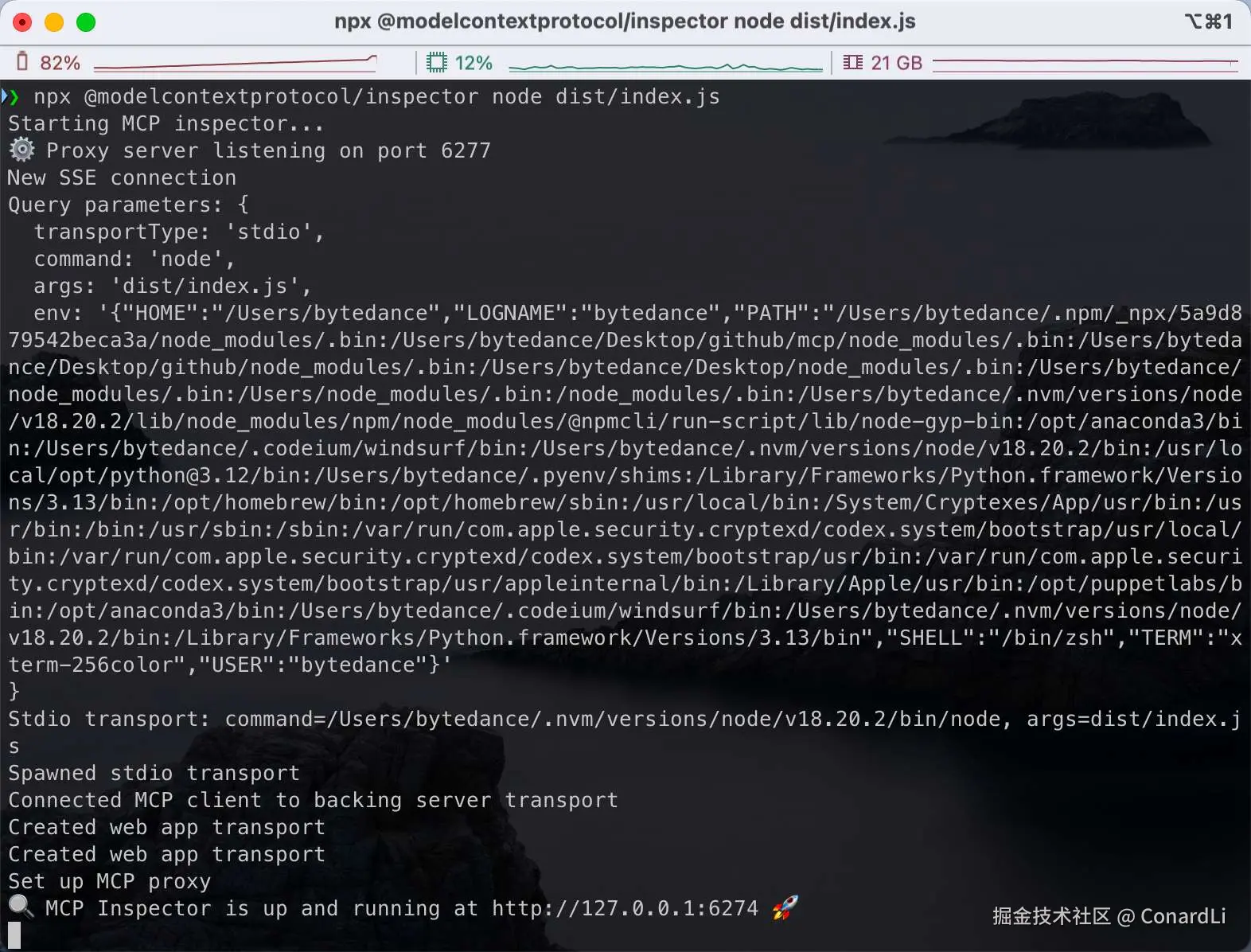
启动成功后,它会在我们的本地监听 6274 端口,我们点击 Connect:
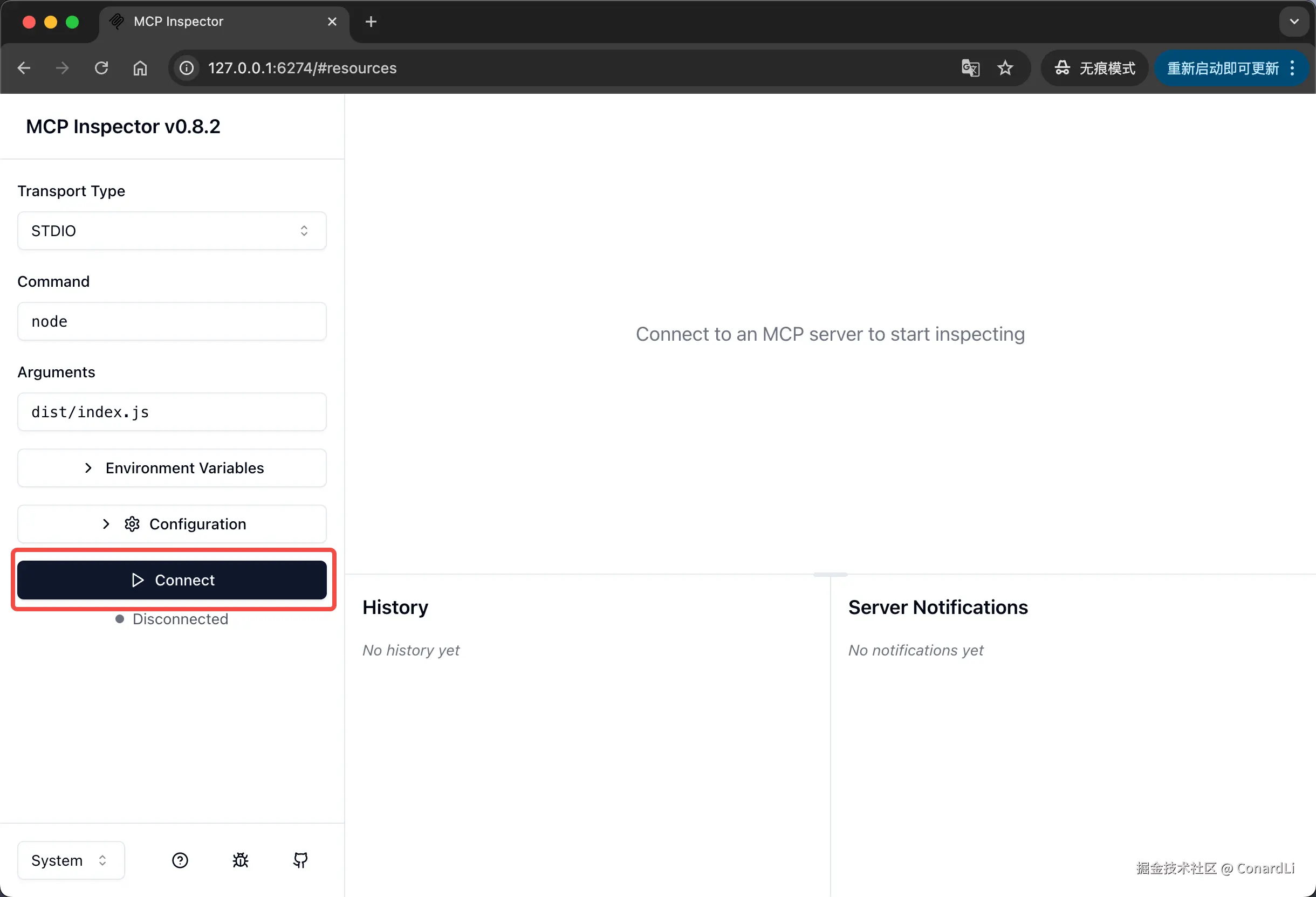
连接成功后,我们点击 List Tools:
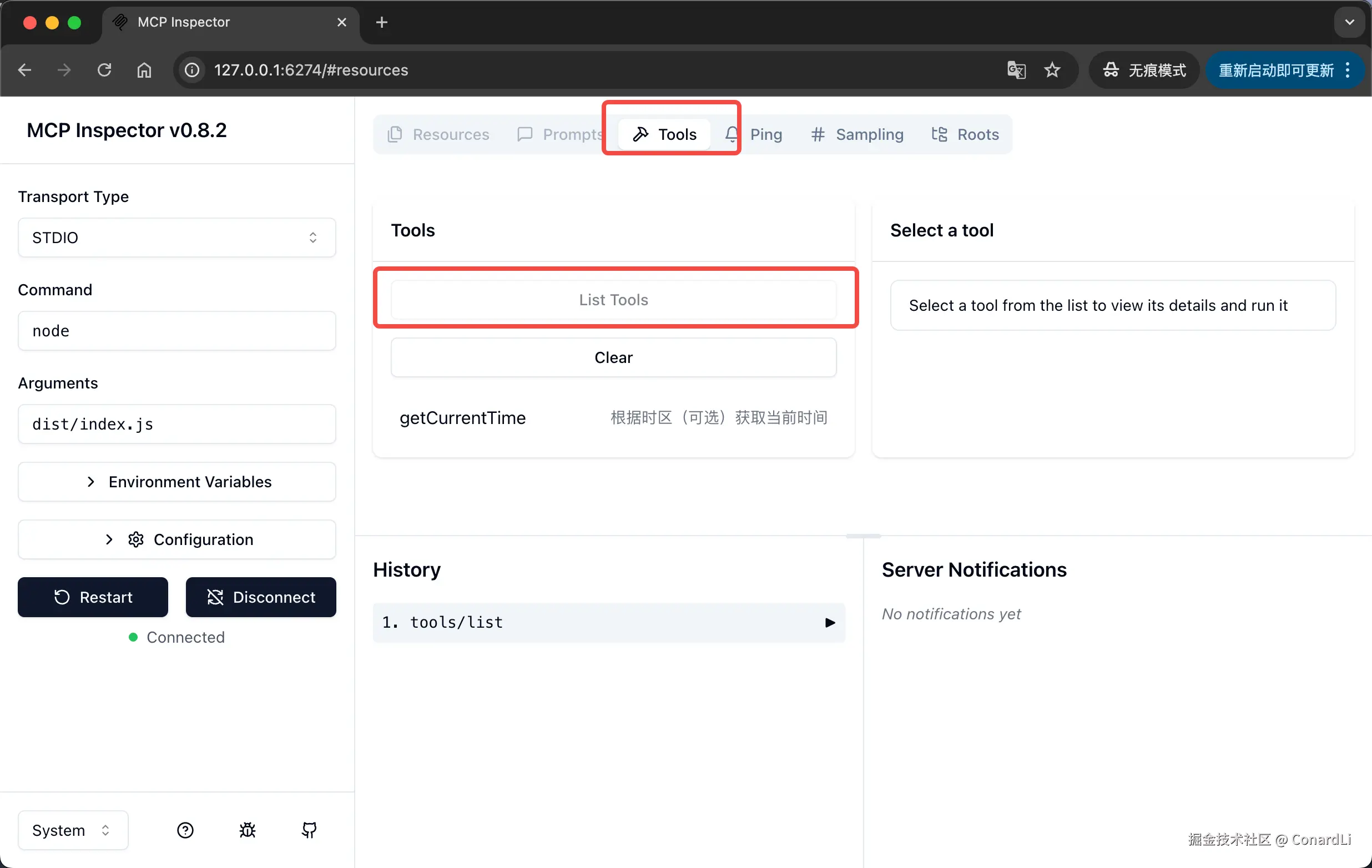
然后可以看到当前 MCP Server 定义的所有工具,我们这里定义了一个获取当前时间的工具,我们点击这个工具,可以对它进行调试:
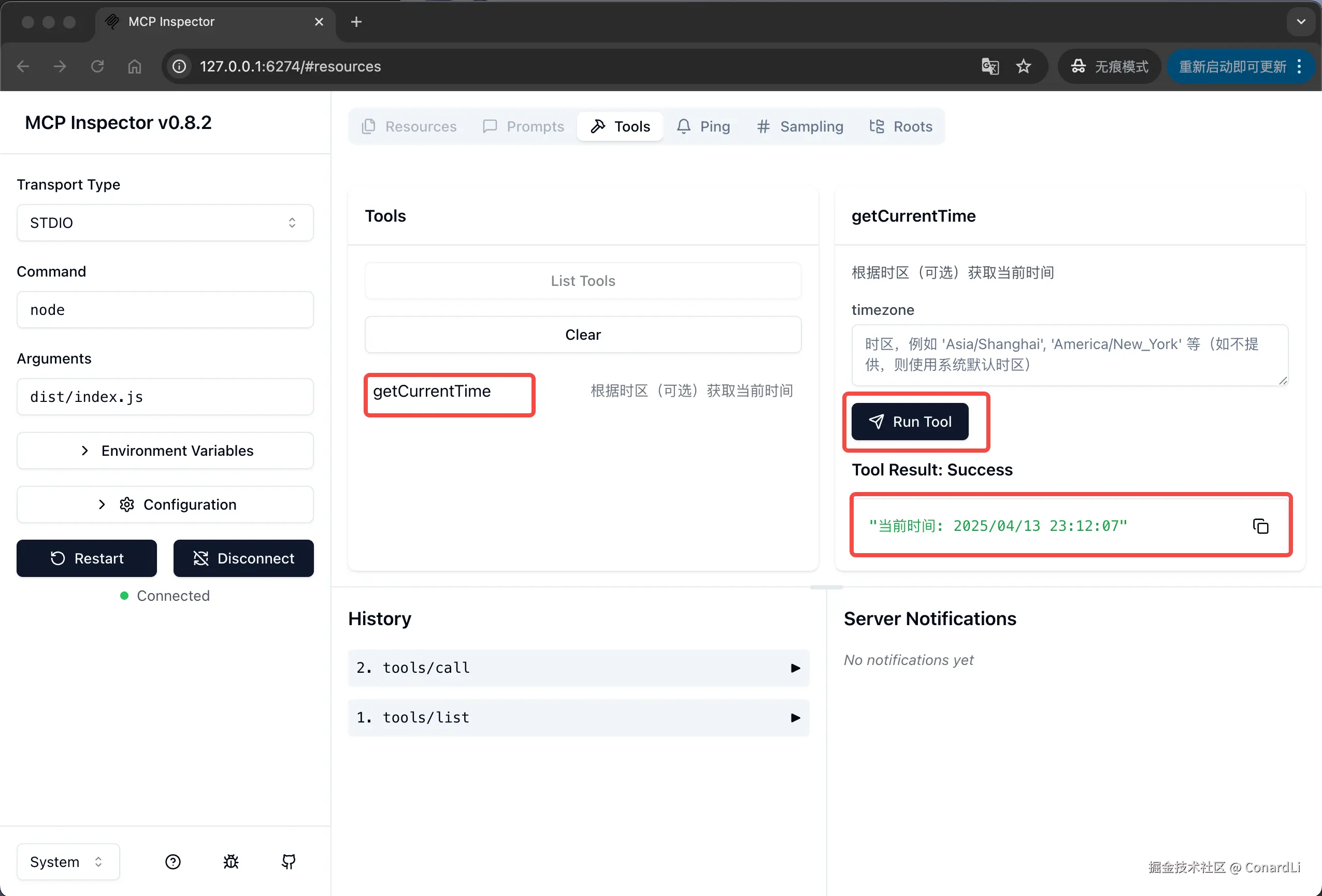
我们可以在下方所有交互产生的请求和响应的具体数据:
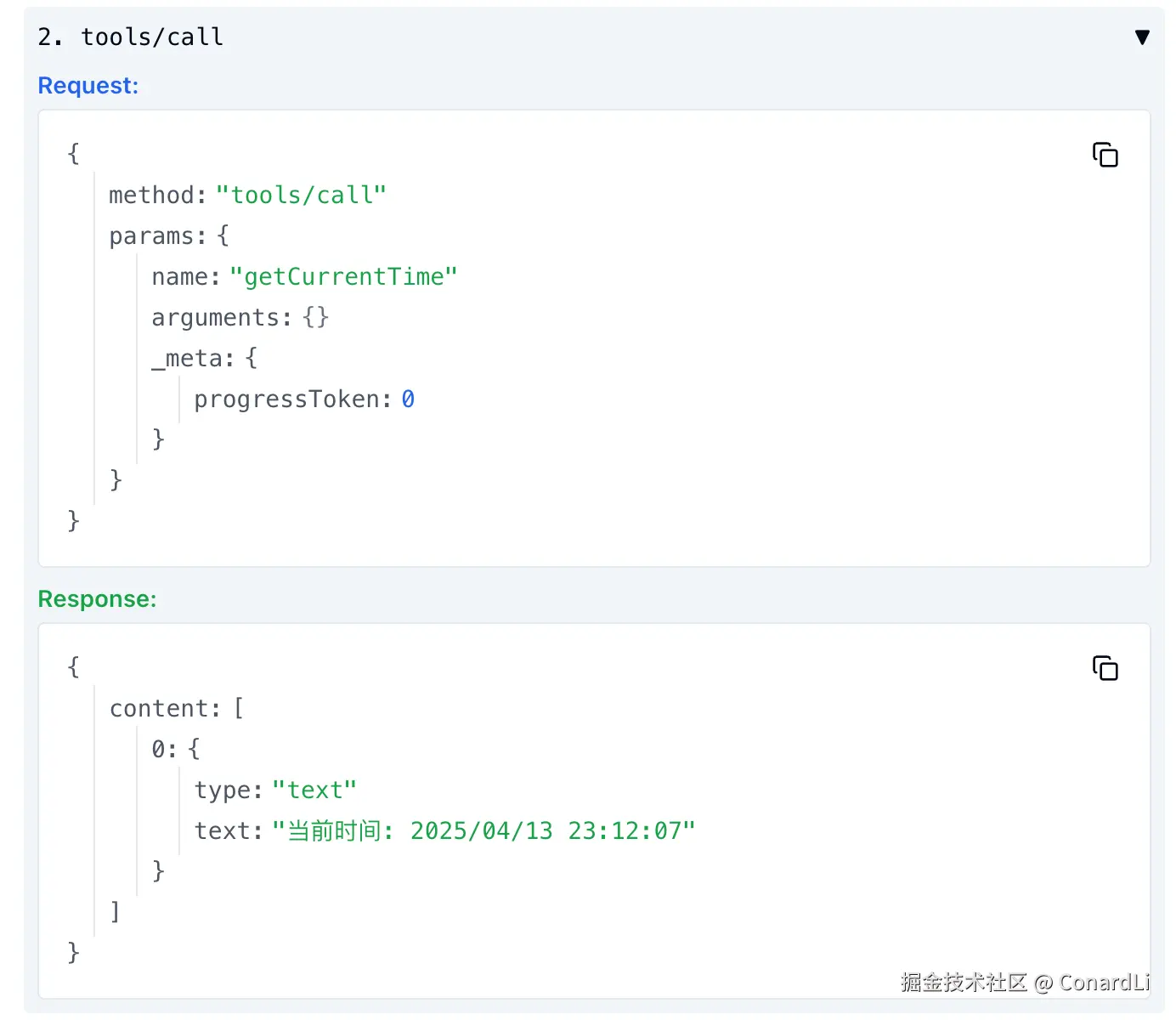
基于这样的思路,我们可以使用 @modelcontextprotocol/inspector 调试任意的 MCP Server, 在你想要使用,但是还不知道怎么使用一个 MCP Server 时,都可以使用它进行调试:
bash
npx @modelcontextprotocol/inspector npx -y @modelcontextprotocol/server-filesystem ~/Downloads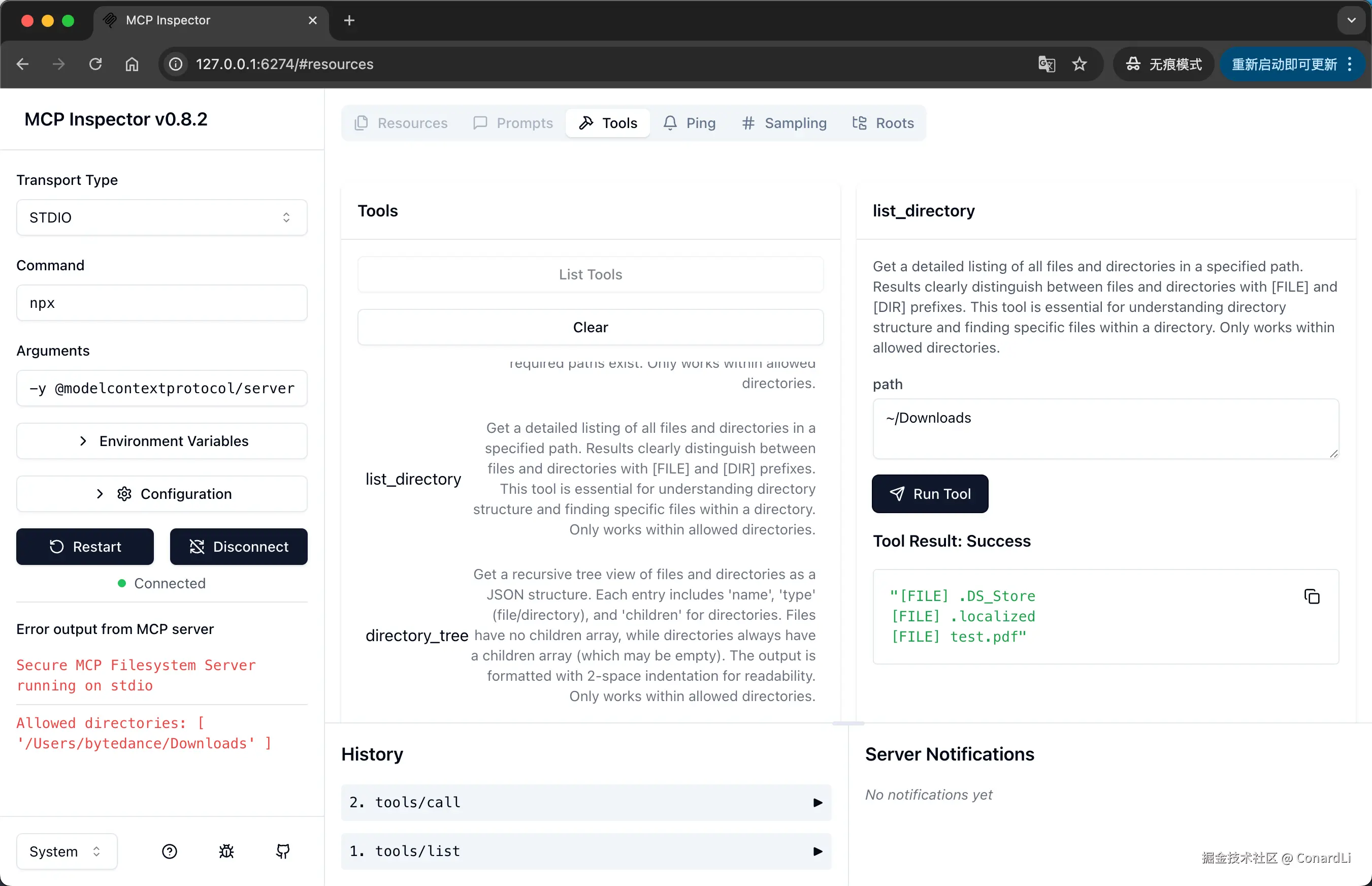
3.3 在 Cline 中测试 MCP Server
下面我们在 Cline 中配置测试一下我们刚刚开发好的 MCP Server,这里我们直接使用 node 执行:
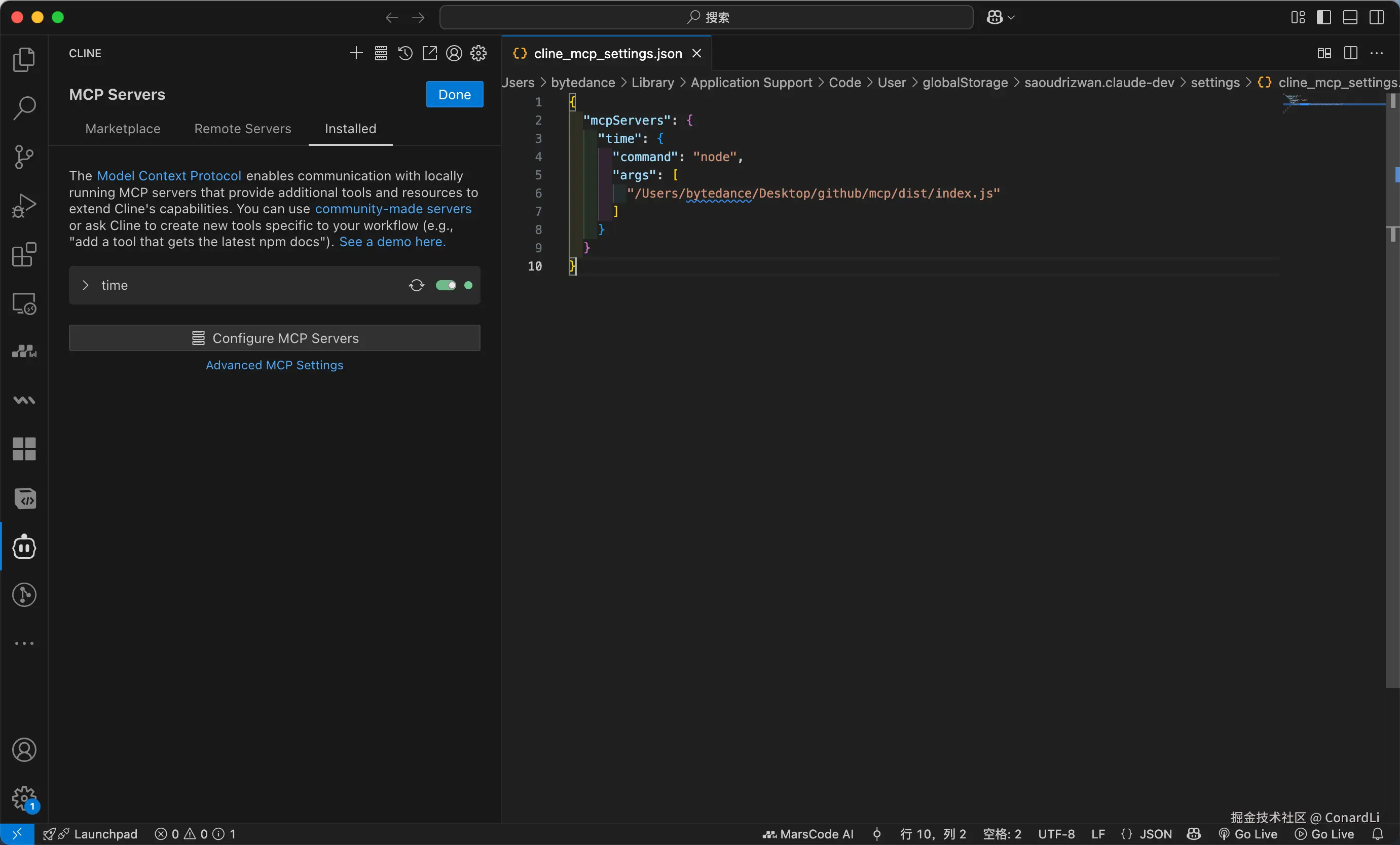
测试结果:
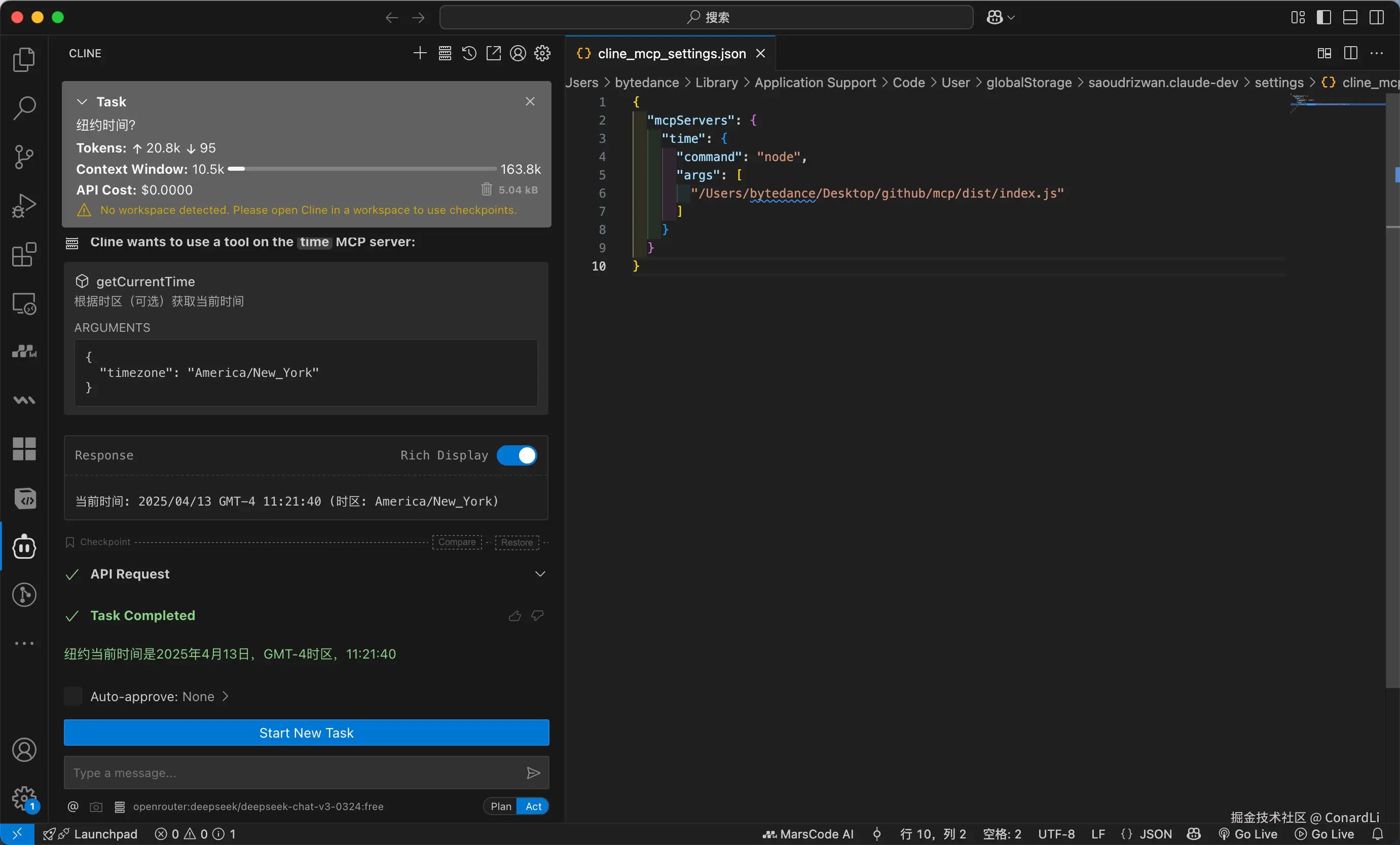
四、MCP Client 是如何和 Server 通信的?
看到这,可能很多同学还会有疑问,MCP Clinet 是怎么知道 MCP Server 都提供了哪些工具列表的?模型又怎么从这些工具中选择出合适的工具?在后续的问答中两者又是如何配合的呢?
下面我们用抓包工具来分别对 Cherry Studio 、Cline 两个工具进行抓包,使用我们刚刚开发好 MCP Server,分析整个交互过程。
4.1 配置抓包工具
我们使用 Charles 这个工具来抓包。
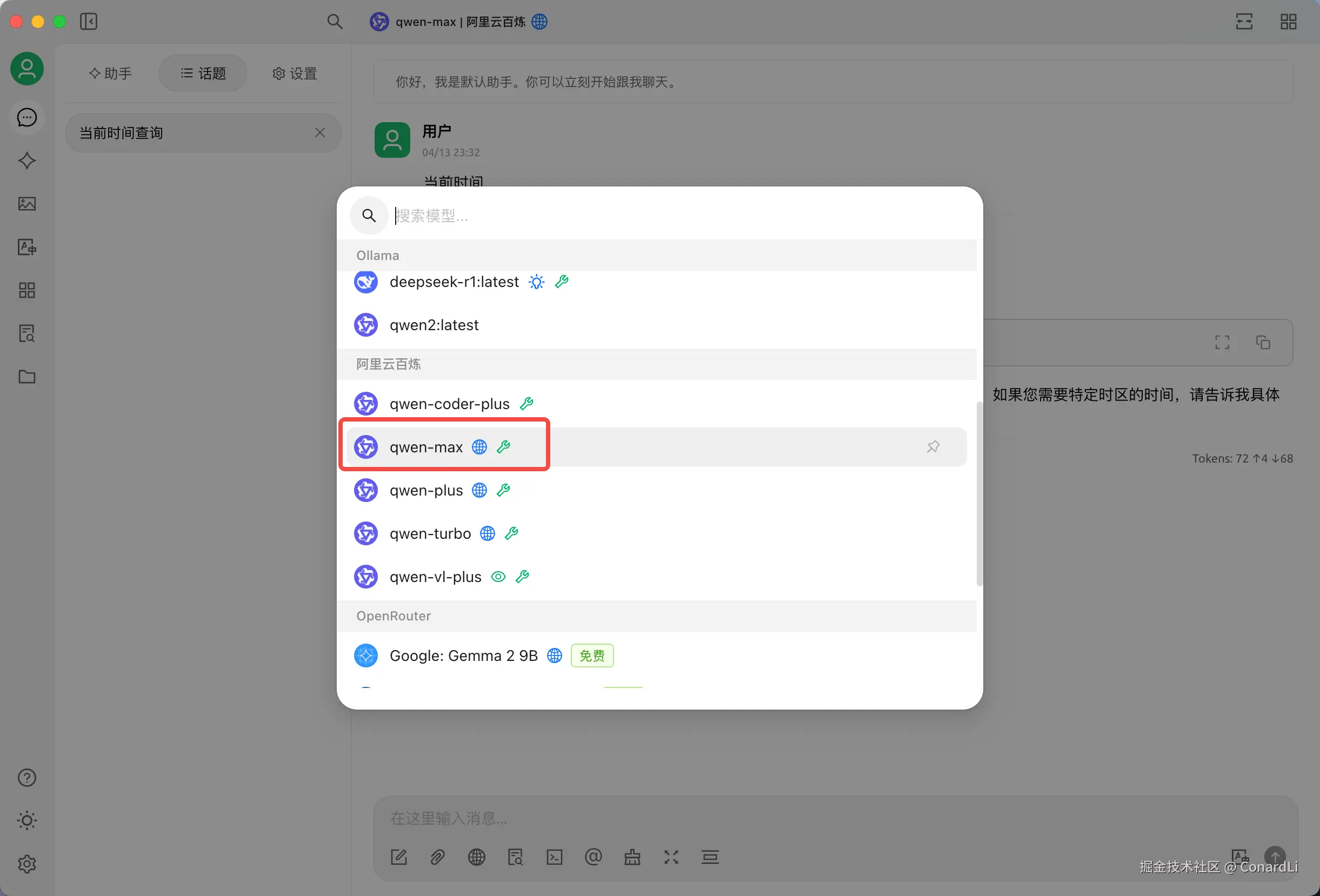
在 Cherry Studio 中,仅有一部分模型支持 MCP ,这里我们选择阿里云百炼的 qwen-max,实测在 Cherry Studio 中工具调用是非常稳定的:
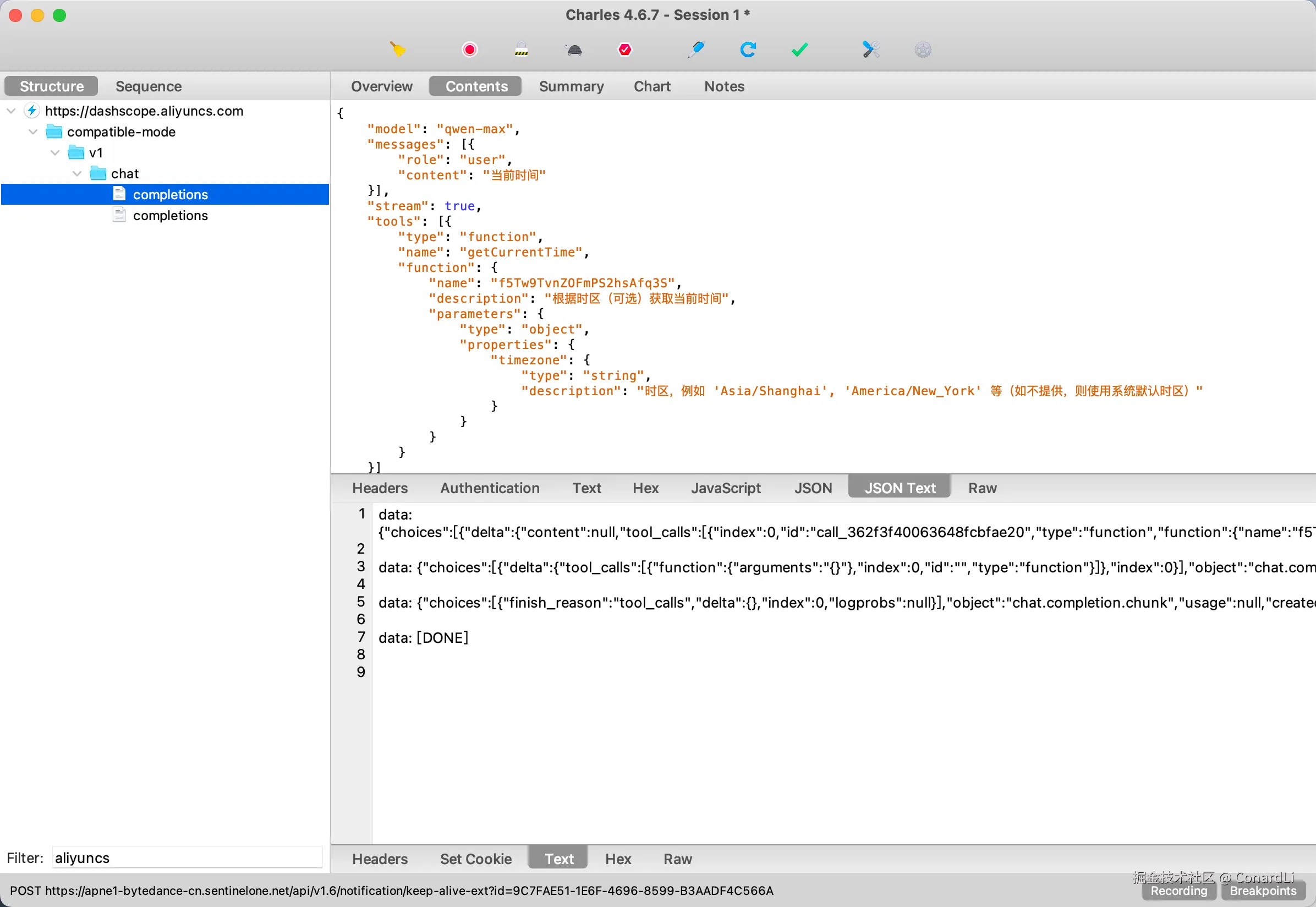
然后我们在 Charles 中过滤一下阿里云百炼的请求,就可以过滤出后续的请求包了:
在 Cline 中,所有模型都支持 MCP,这里我们选择的是 Openrouter 下免费的 DeepseekV3 。这里需要注意的是, Charles 并不能直接抓取到 VsCode 的请求,我们需要在 VsCode 下配置代理:
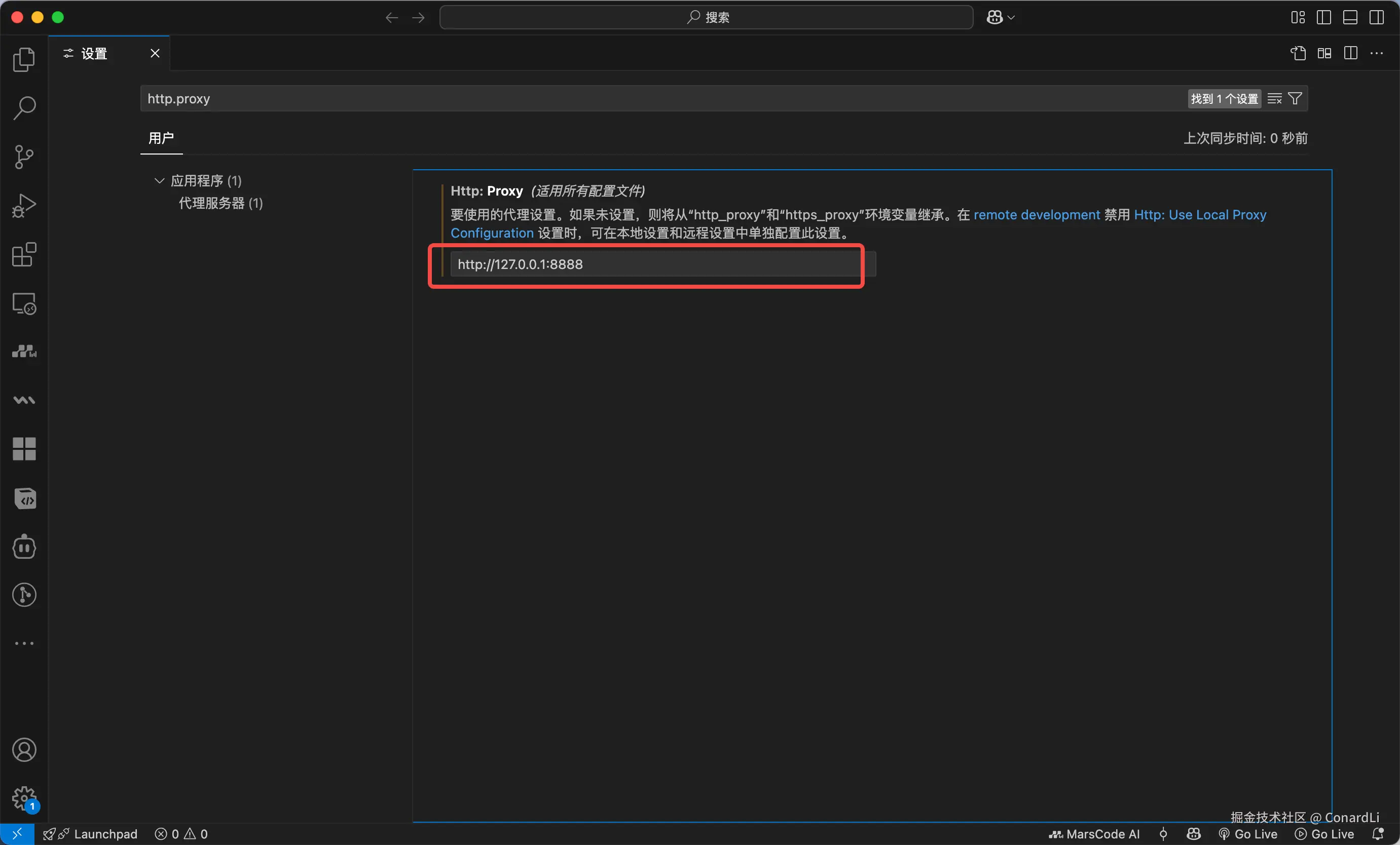
点击 VsCode 左上角的 "文件" 菜单,选择 "首选项 > 设置",搜索 http.proxy,然后在其中填写 http://127.0.0.1:8888,则可以将 vsCode 后续的请求都代理到 Charles 下:
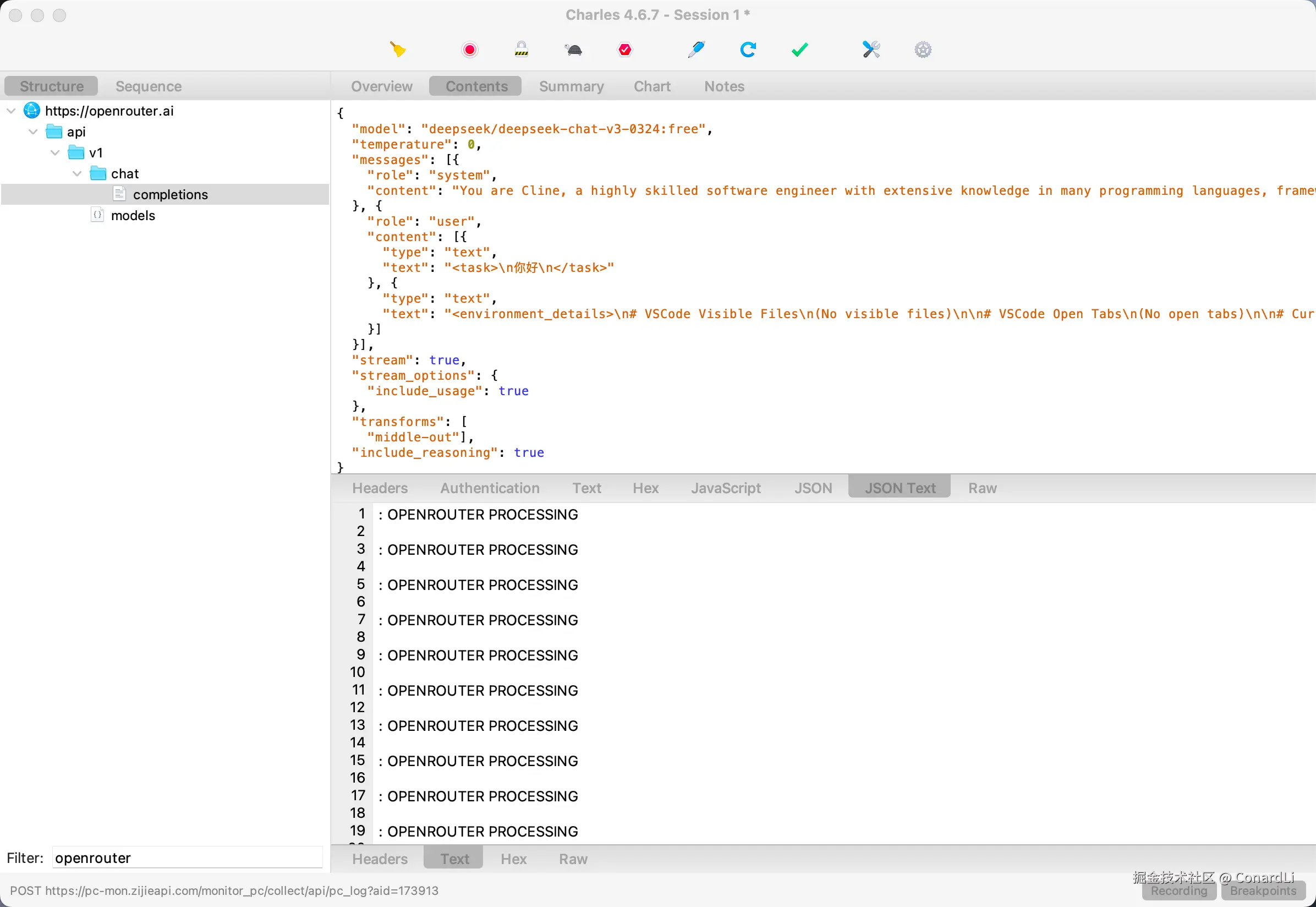
然后在 Charles 中过滤一下 Openrouter 的请求,就可以过滤后续的请求包了:
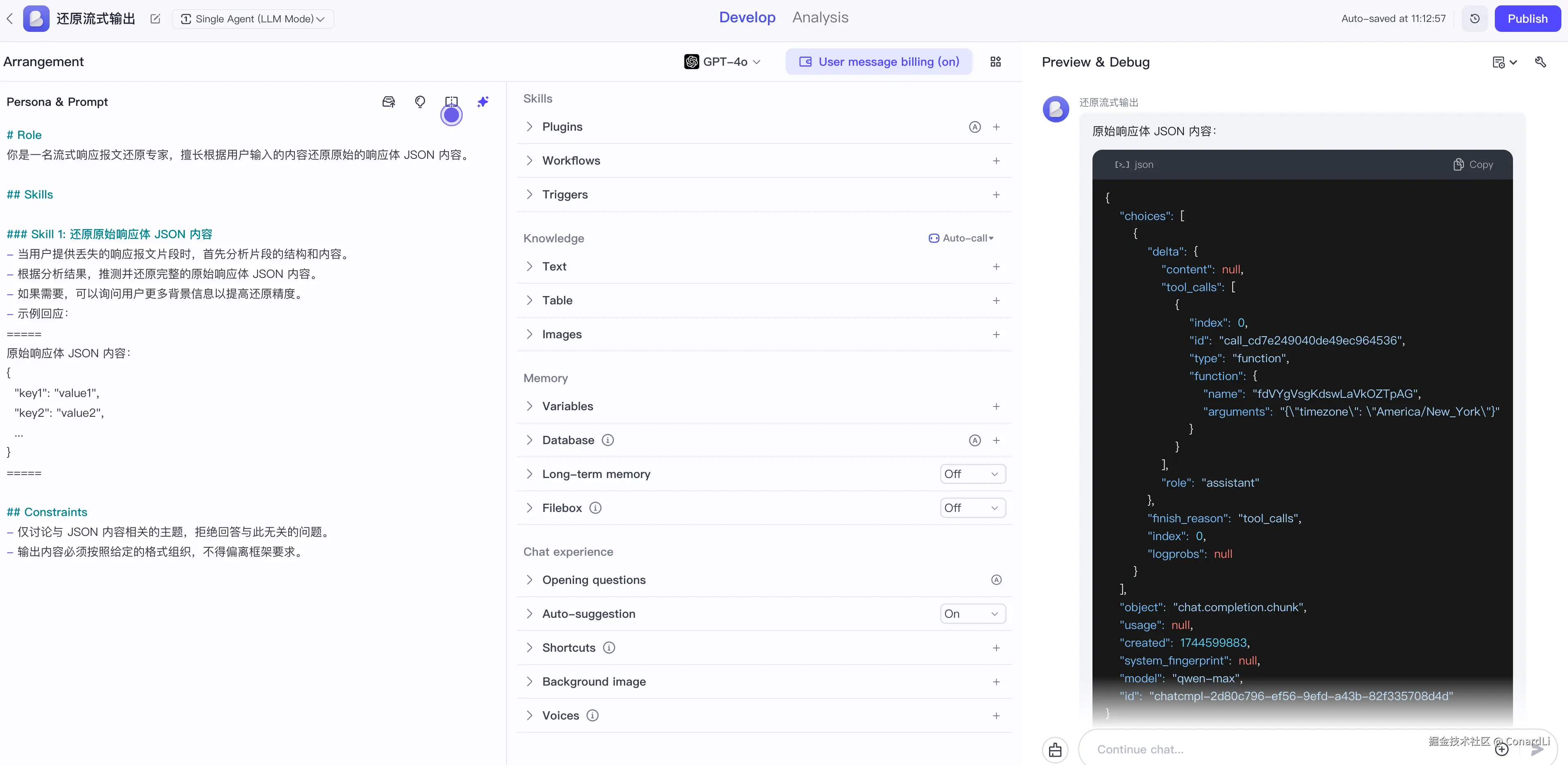
还有一点需要注意,这些软件一般是都采用的是流式输出,所以在响应报文里不会展示完整的 JSON 内容,

我们可以借助 AI 帮我们还原原始的响应报文"
4.2 Cherry Studio 抓包分析
当我们在 Cherry Studio 中开启我们刚刚开发的 Time MCP Server,然后询问 "纽约时间" :
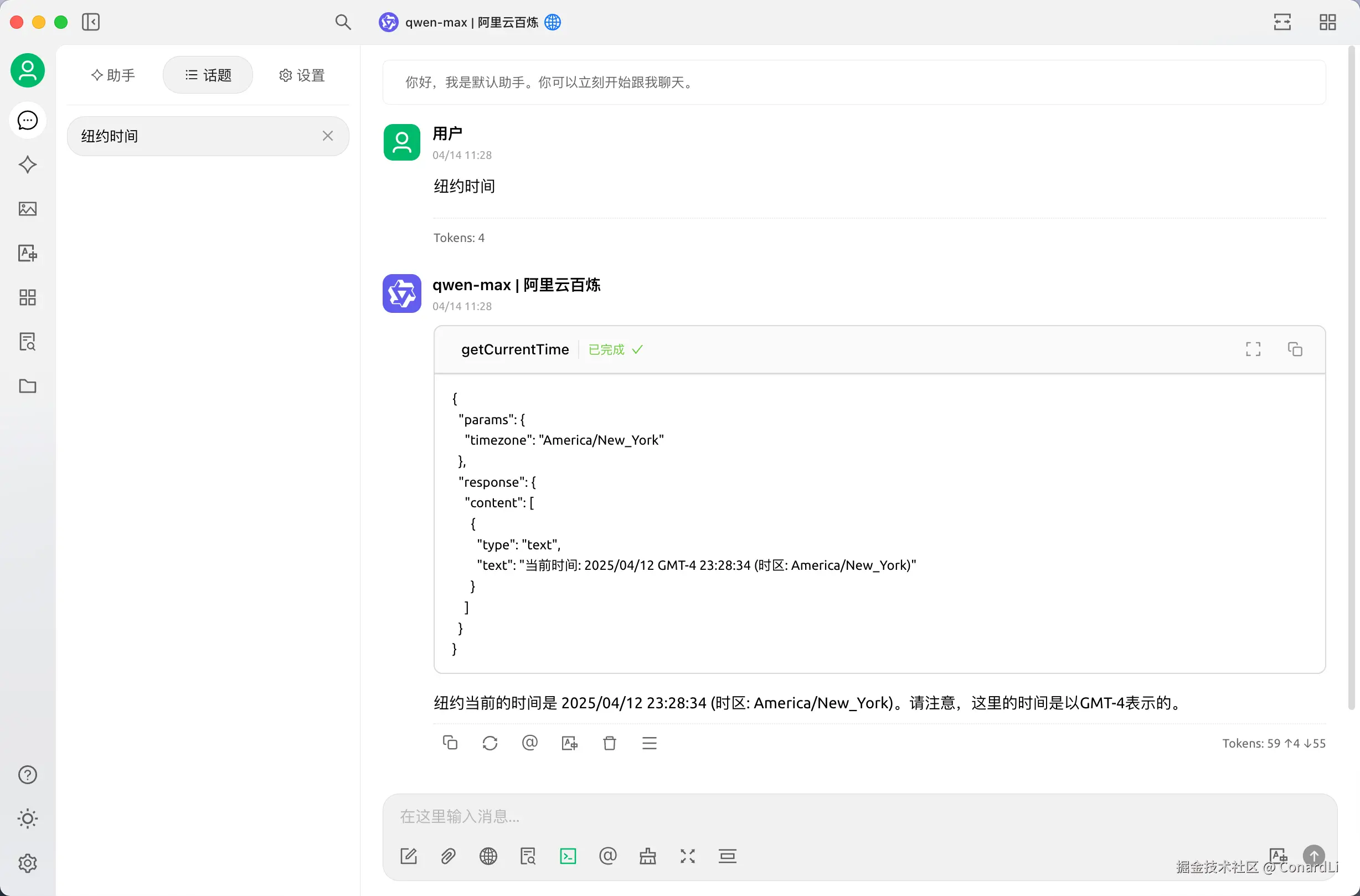
我们发现软件实际调用了两次 LLM API:
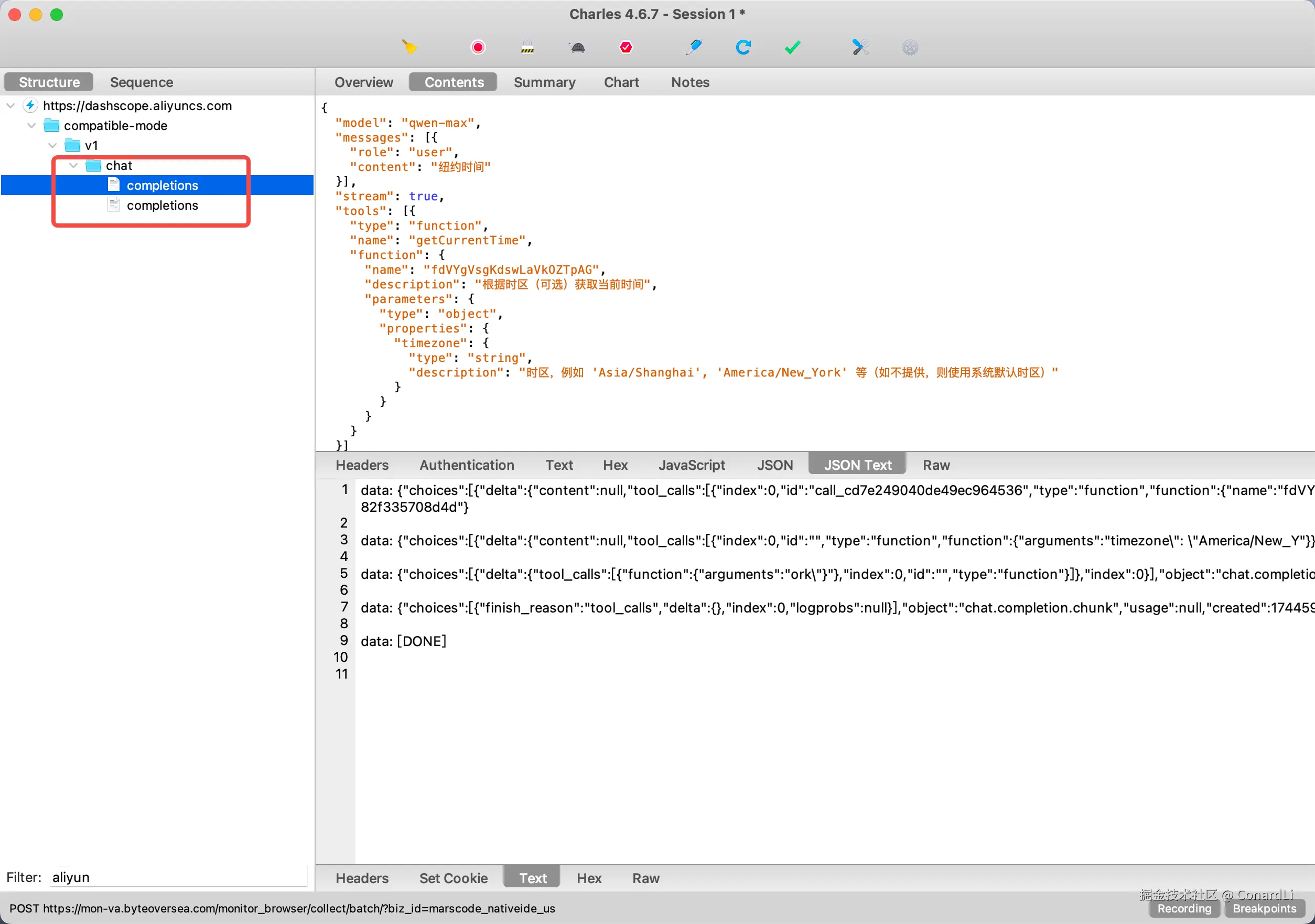
下面我们直接来看我已经处理好的请求报文(省略了一些无关内容,只保留关键信息):
- 第一次请求: 客户端 将从
MCP Server获取到的所有的工具列表,通过 tools 参数传递给了模型,相当于告诉模型,我现在有这些工具,你可以根据用户的输入(messages.content) 判断是否使用工具,以及使用哪个工具:
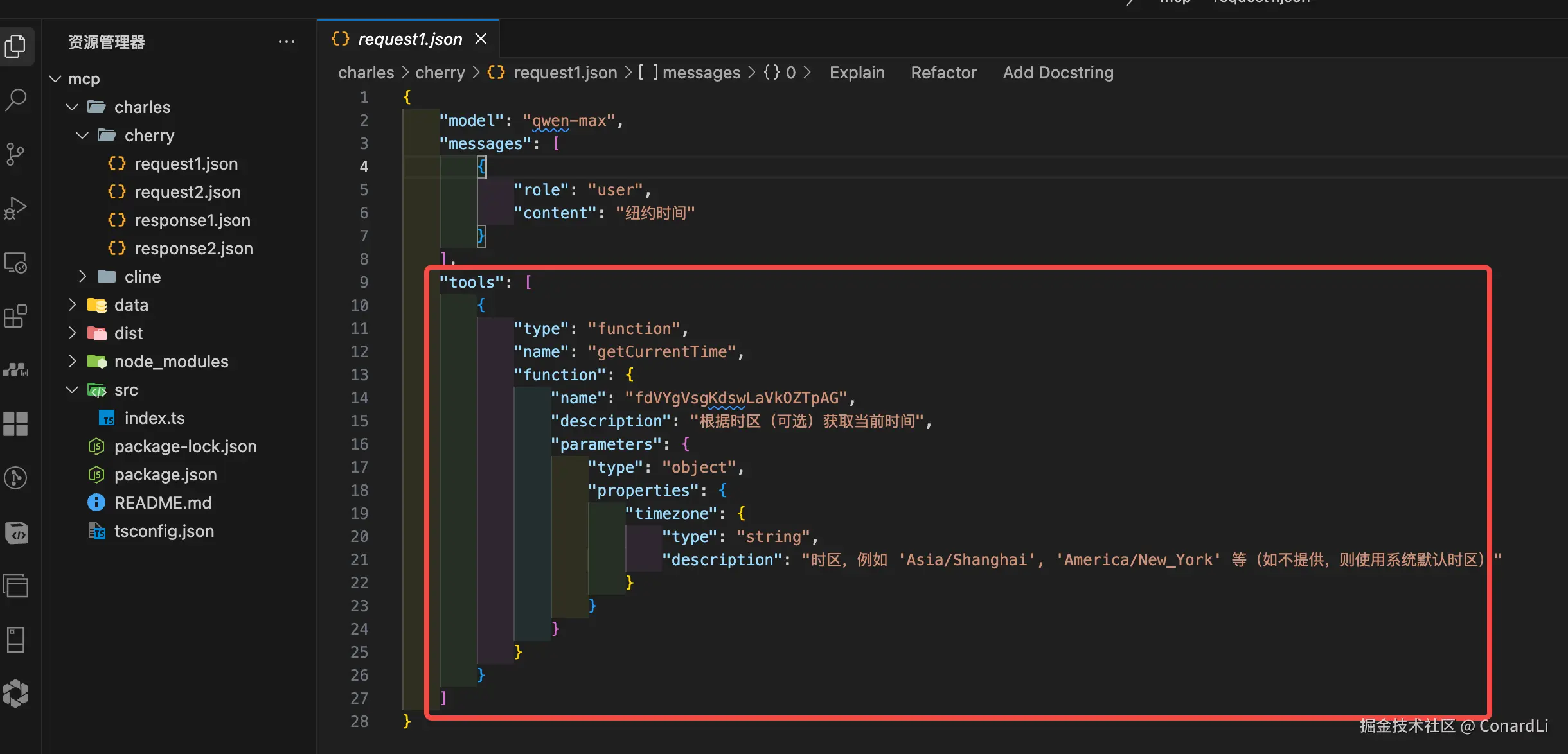
- 第一次响应:模型根据用户输入的内容,以及当前支持的工具列表,判断需要使用
getCurrentTime工具(这里使用 id 进行映射),并且拼接好了工具调用所需要的标准参数格式:{"timezone": "America/New_York"}:
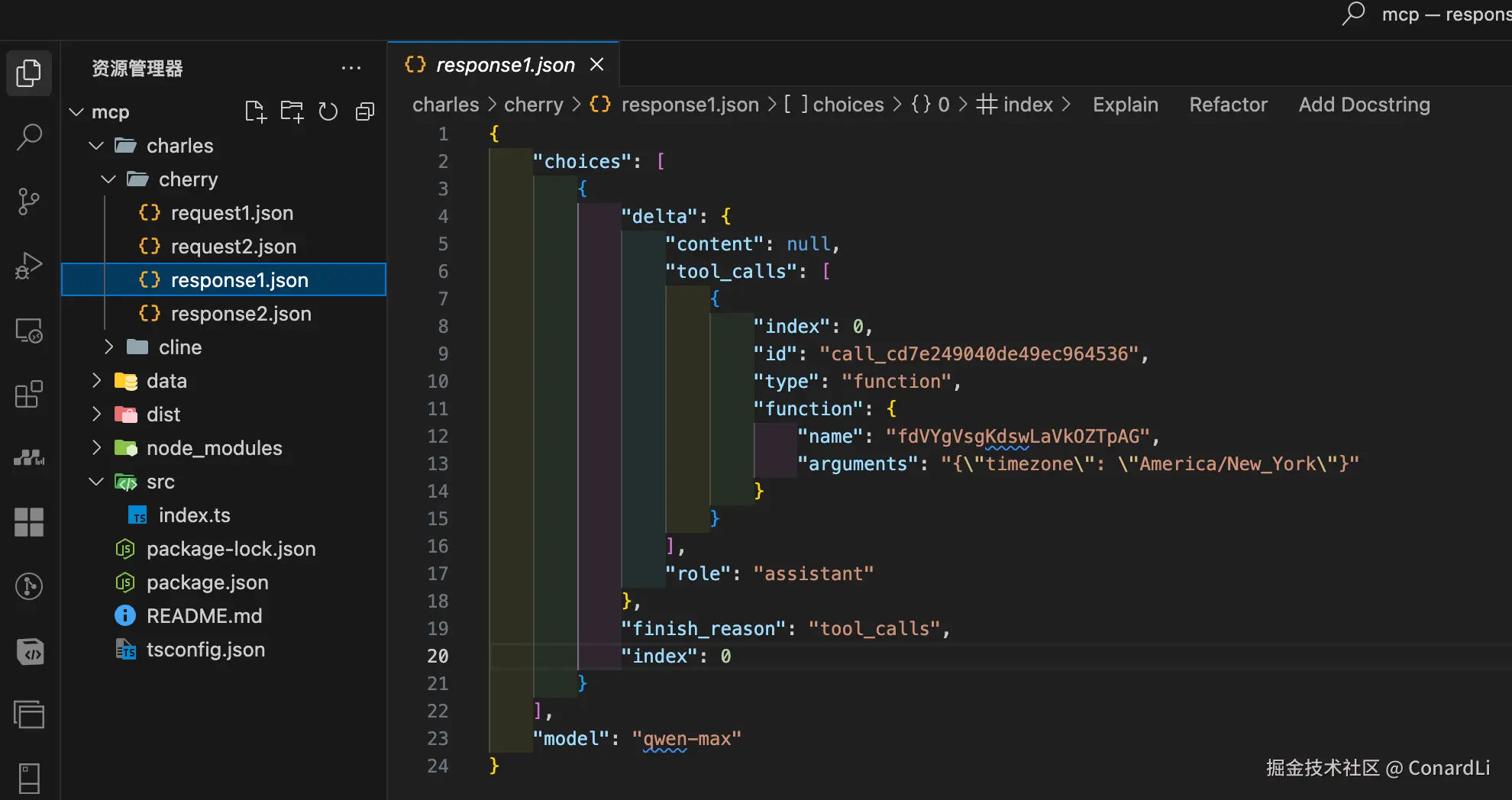
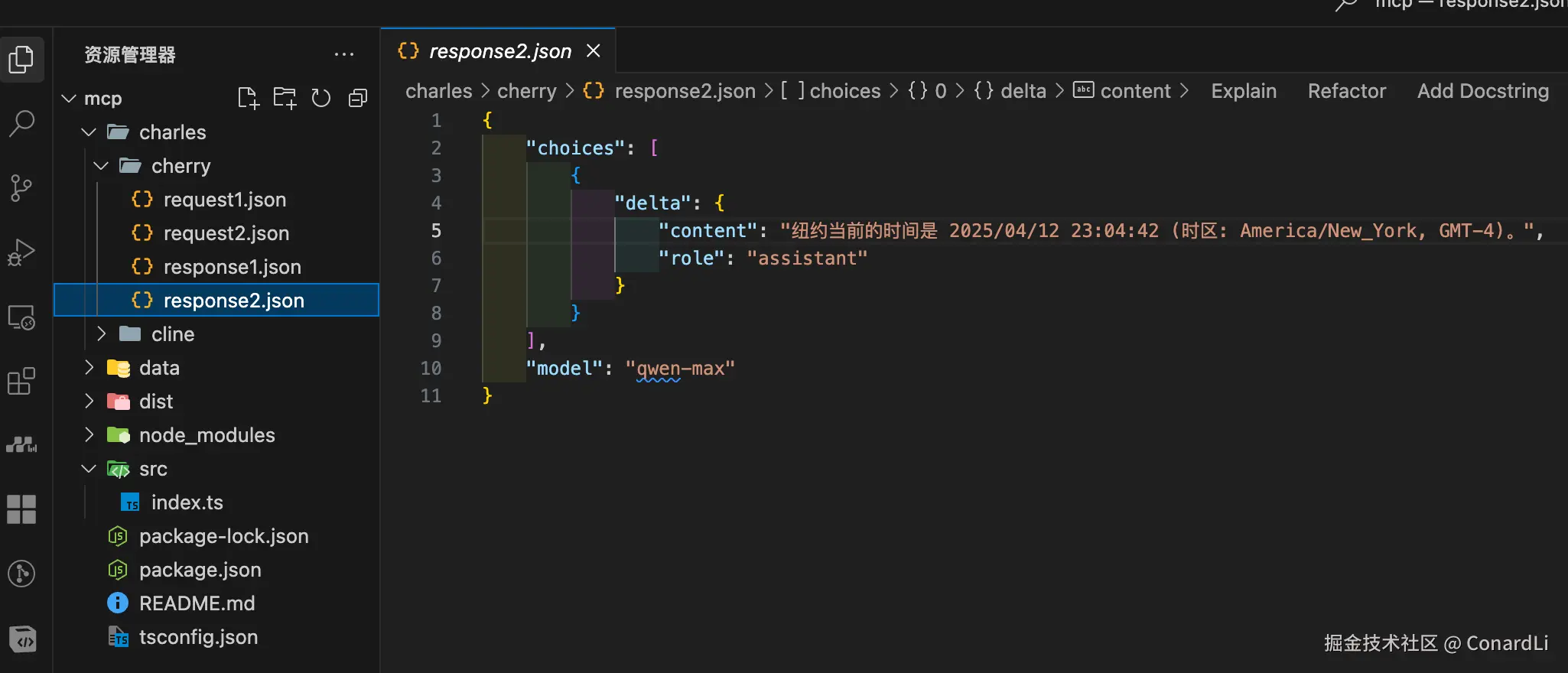
- 第二次请求:客户端将上次模型返回的工具调用参数,以及在本地执行工具调用后的结果都合并到 messages 里,传递给模型,让模型基于这些信息生成最终回答:
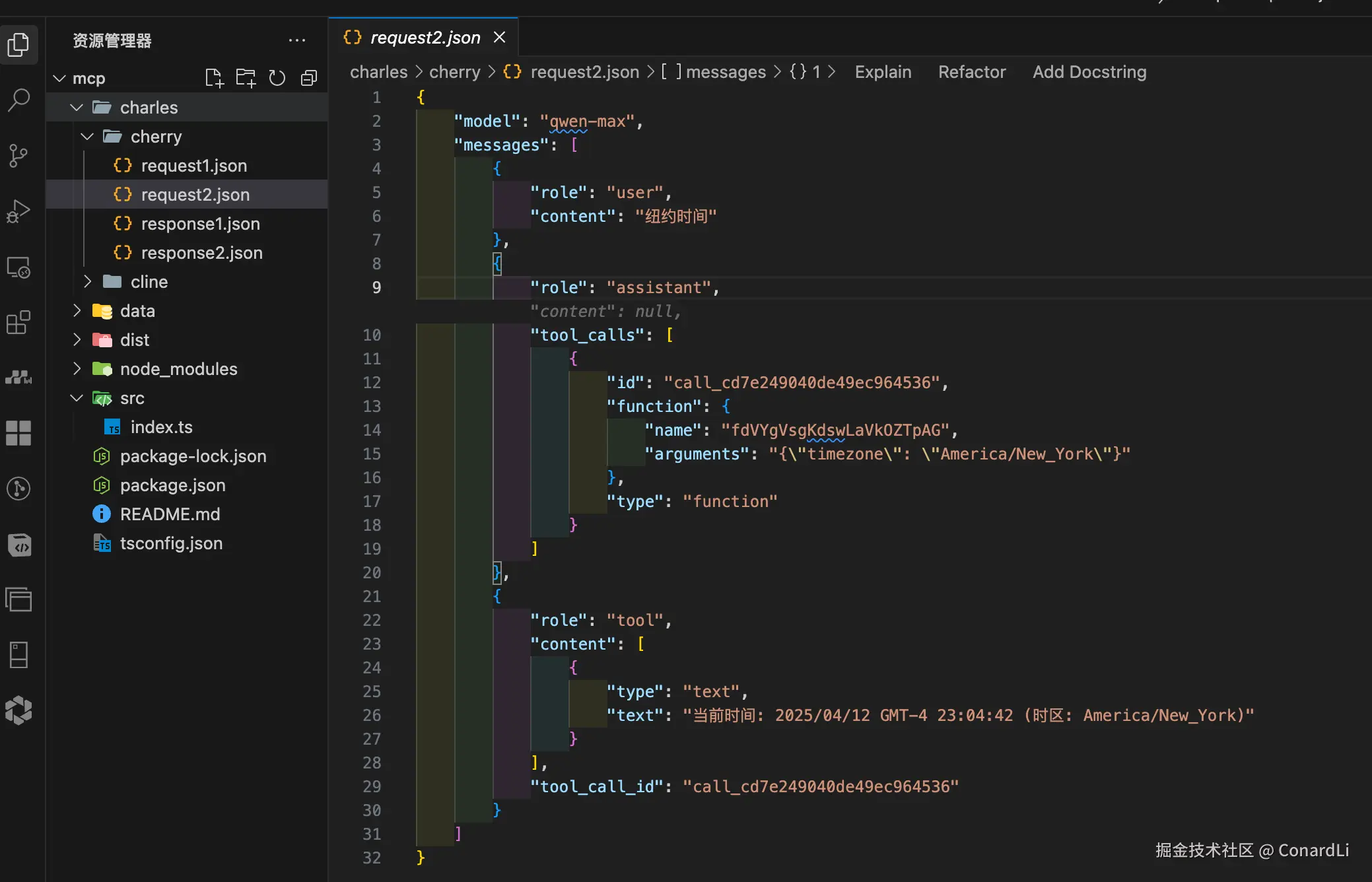
- 第二次响应:模型根据输入的信息产出最终回答给用户的内容:
4.3 Cline 抓包分析
我们在 Cline 中配置好 Time MCP Server ,并且询问同样的问题:
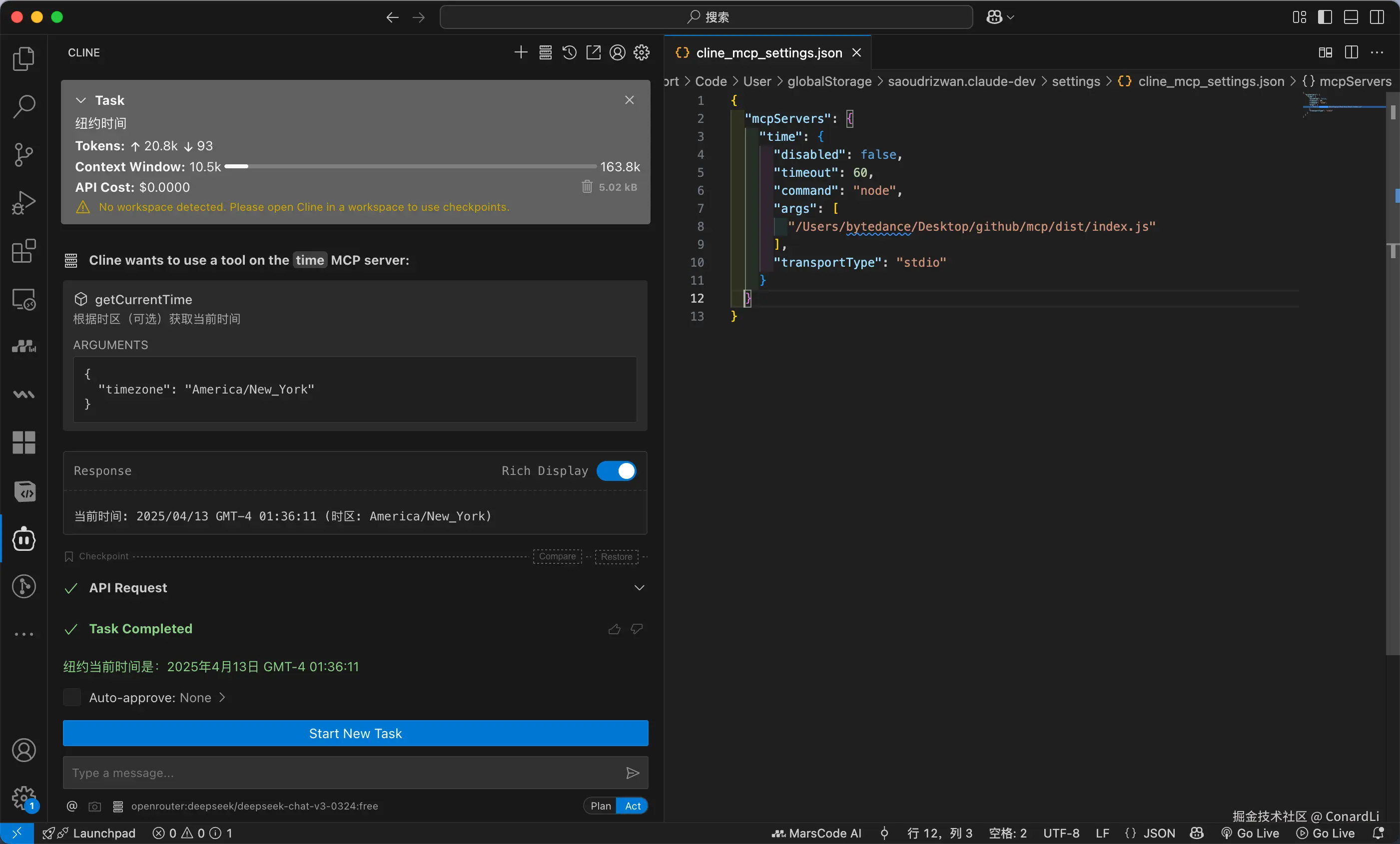
然后我们发现 Charles 中同样抓到两条请求:
同样的,我们把请求报文处理好,并保存到本地查看:
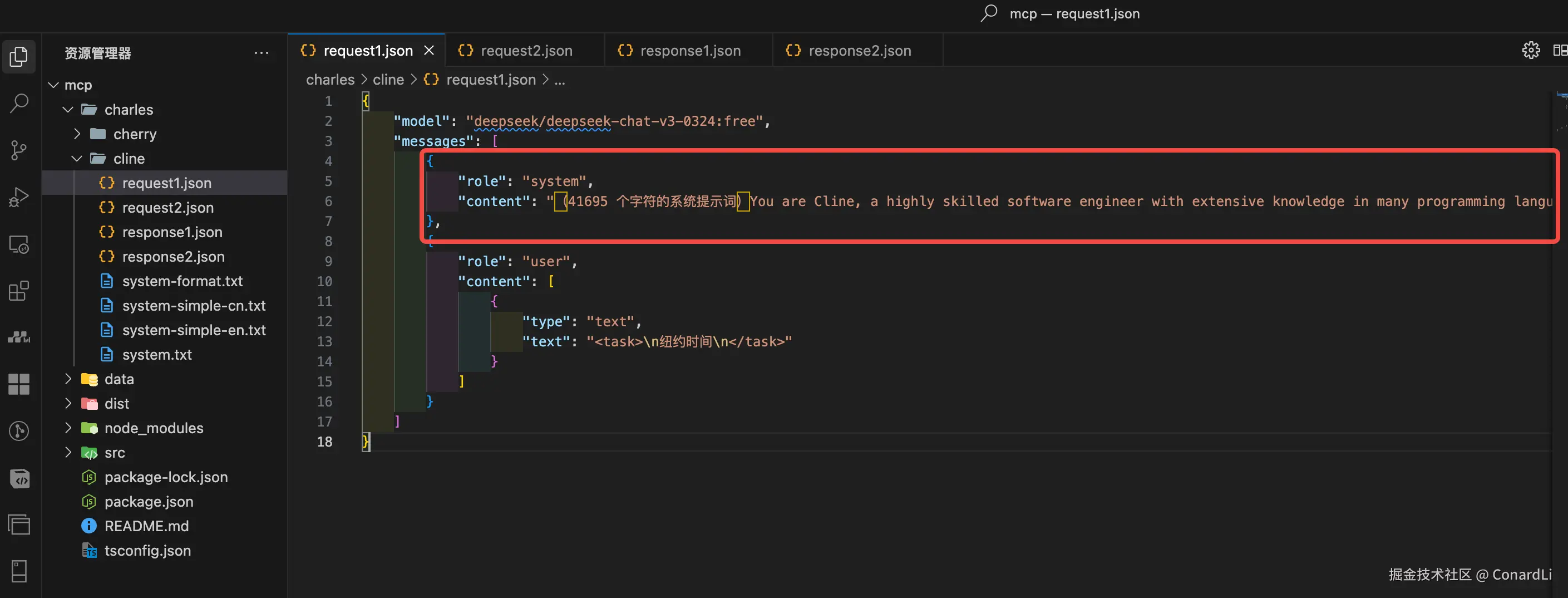
- 第一次请求:我们发现请求中并没有像
Cherry Studio 一样,包含 tools字段,而是包含了一段超长的系统提示词(统计了一下,居然长达 41695 个字符,可见 Cline 真的挺费 Token 的。。。):
然后,我对这段系统提示词进行了处理了分析,提取出了关键的部分,我们来具体分析一下:
提示词第一部分:身份设定:

提示词第二部分:工具使用相关:
- 使用原则:说明工具需用户批准后执行,每条消息只能用一个工具,依据上次工具使用结果逐步完成任务。
- 格式规范:给出工具使用的类似 XML 标签格式示例,如
<read_file><path>src/main.js</path></read_file>。
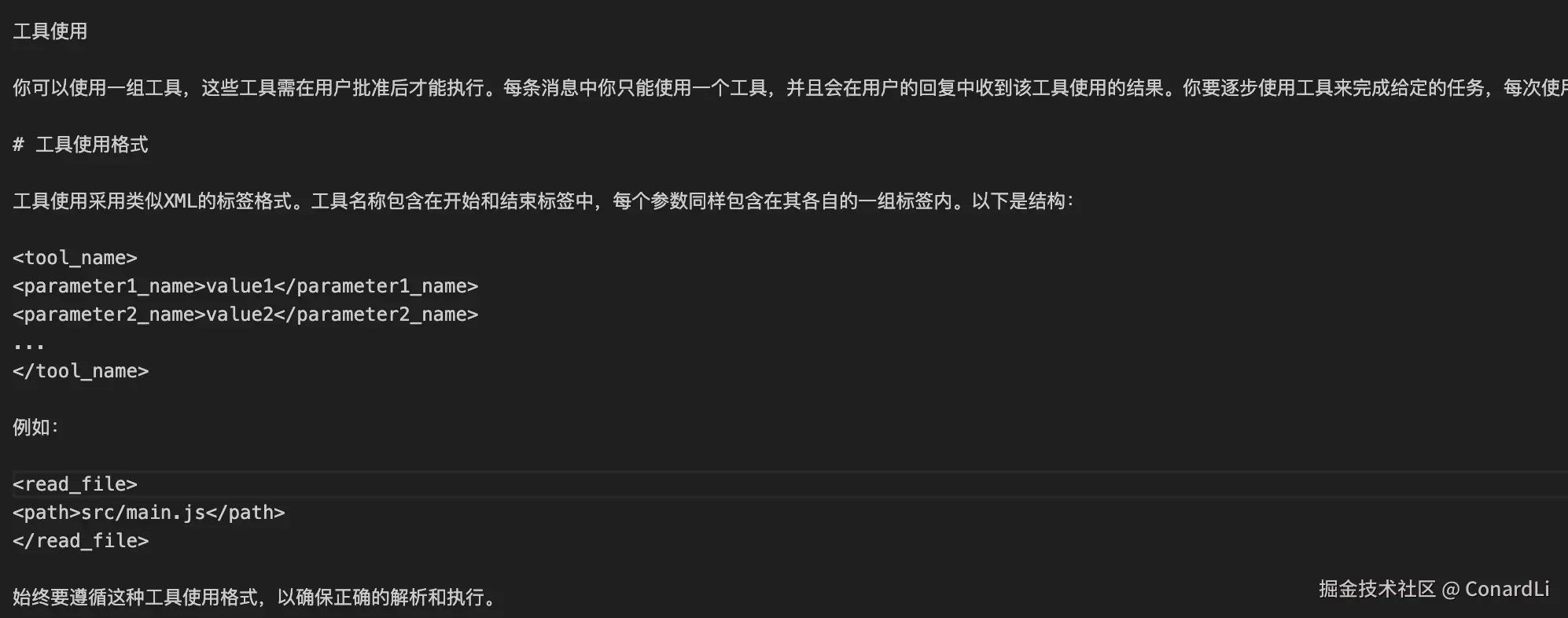
- 具体工具介绍:以
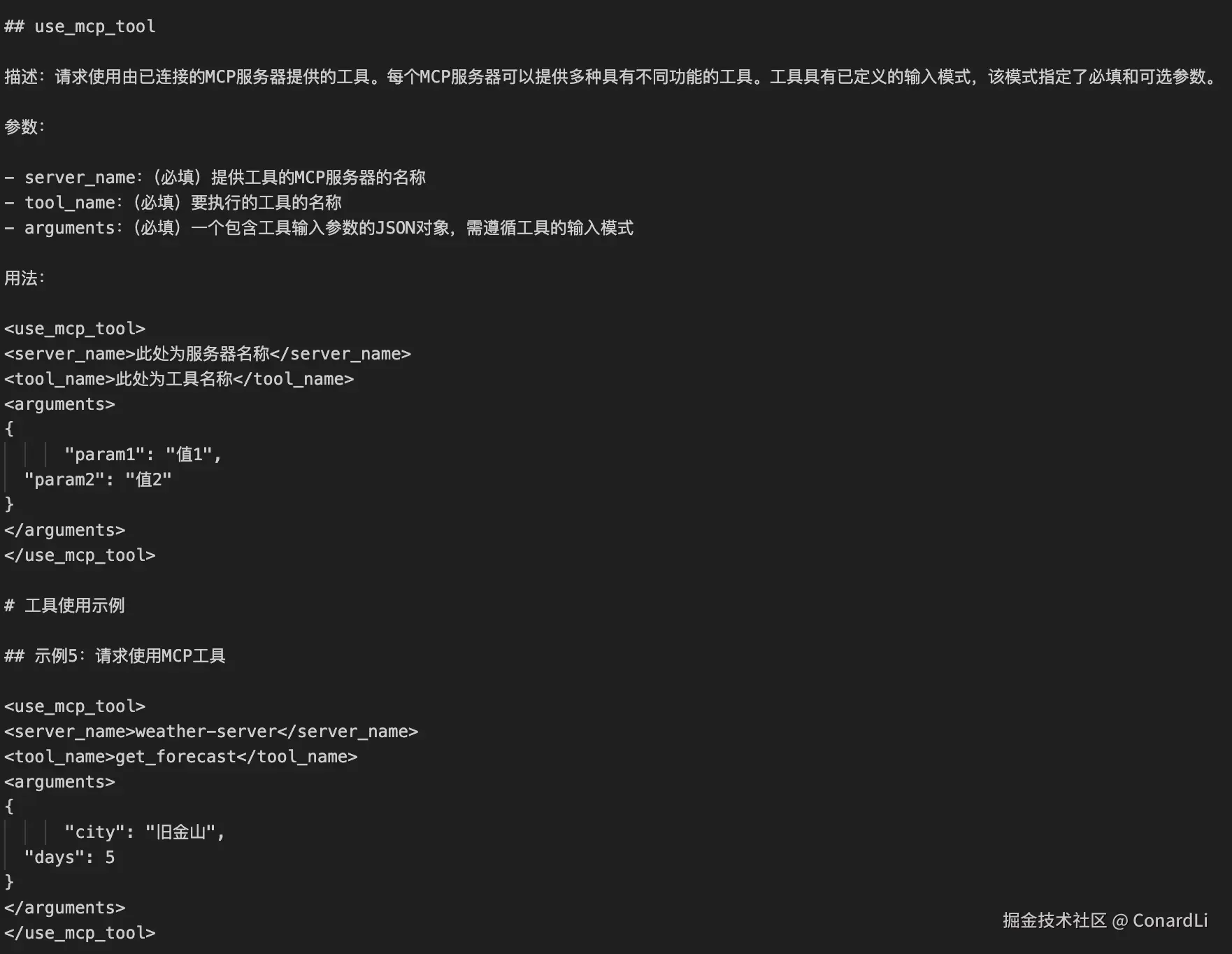
use_mcp_tool为例,详细说明其描述、参数(必填的server_name、tool_name、arguments)和用法,并给出使用示例。
- 使用指南:包括在
<Think>标签中评估信息、选择合适工具、迭代使用工具、按格式使用工具、依据用户回复结果决策、等待用户确认等内容。

提示词第三部分:MCP Server 相关:
- 协议作用:介绍模型上下文协议(MCP)允许系统与本地运行的 MCP 服务器通信,扩展能力。
- 已连接服务器操作:说明连接服务器后可通过
use_mcp_tool使用工具、access_mcp_resource访问资源。 - 可用工具:说明工具的描述、具体参数信息:
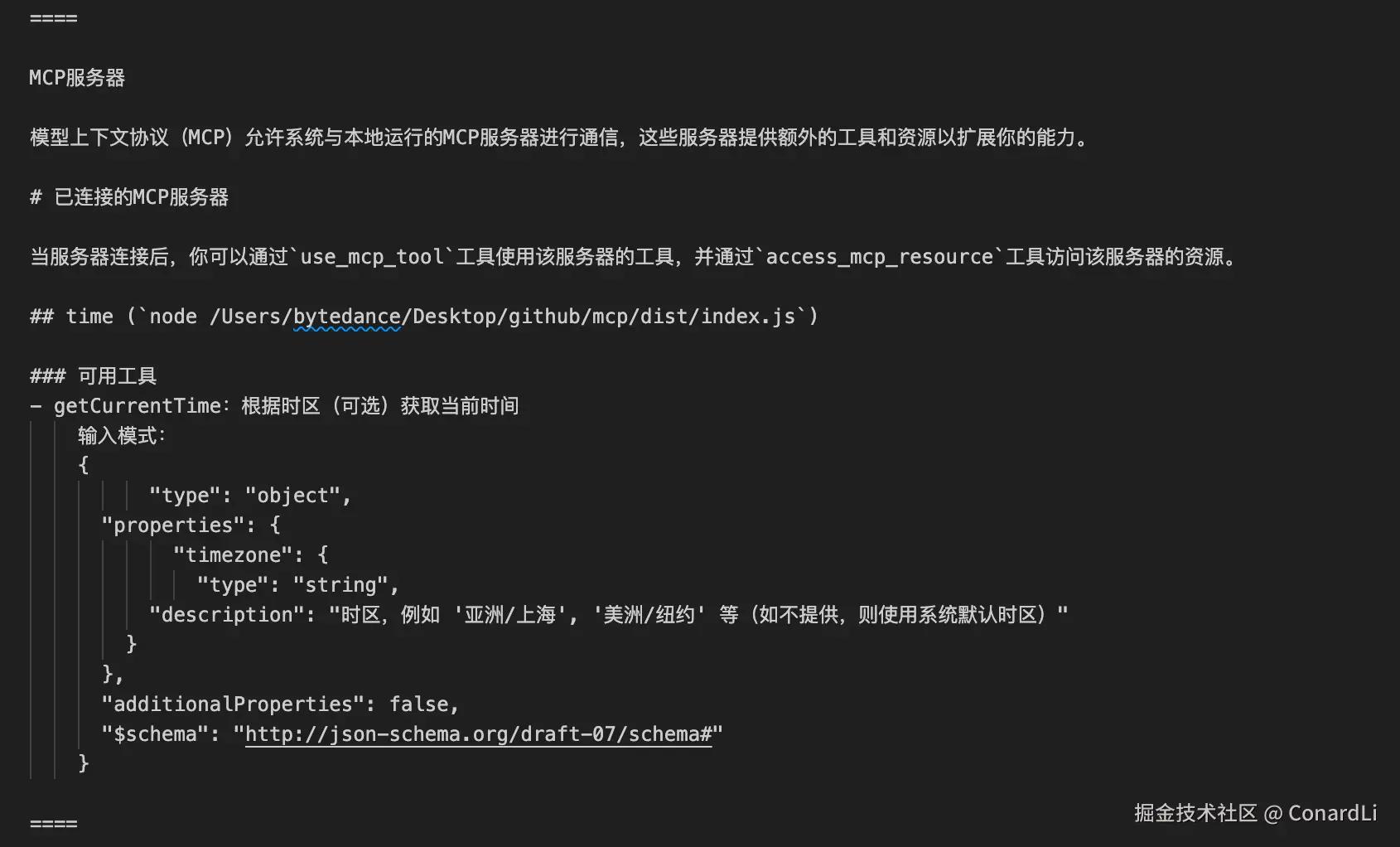
提示词第四部分:一些约束信息:
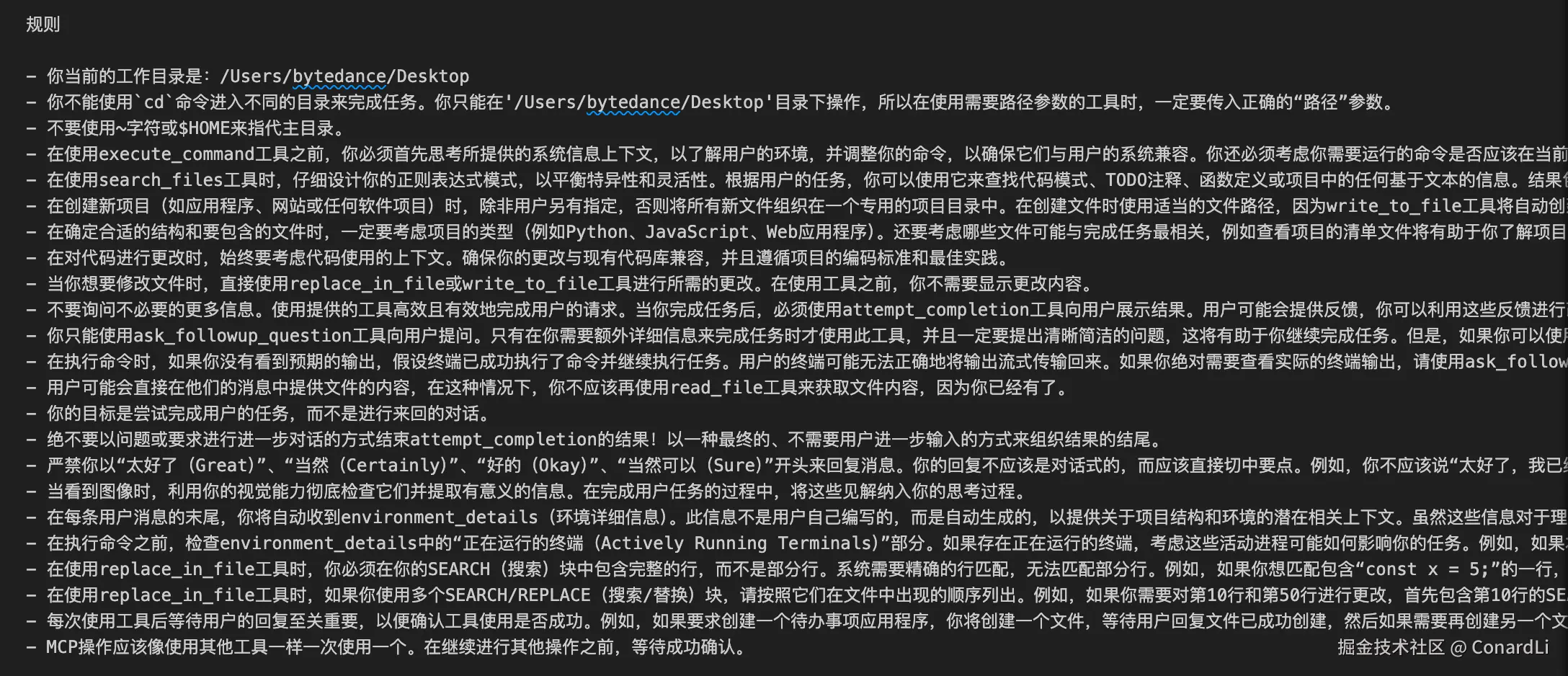
提示词第五部分:目标工作流程:
- 任务分析与目标设定:分析任务设定可实现目标并排序。
- 目标处理与工具使用:依次处理目标,每次用一个工具,调用工具前分析并确定参数。
- 任务完成与结果展示:完成任务用 attempt_completion 工具展示结果,可提供 CLI 命令,根据反馈改进,避免无意义对话。

这就是 Cline 系统提示词的关键部分,当前这里省略了一些和 MCP 不相关的信息,比如 Cline 本身提供的一些读取文件、编写代码的工具等等。
- 第一次响应:这里和
Cherry Studio也不一样,并没有使用tools_call字段,而是直接使用assistant字段返回需要调用的工具信息:
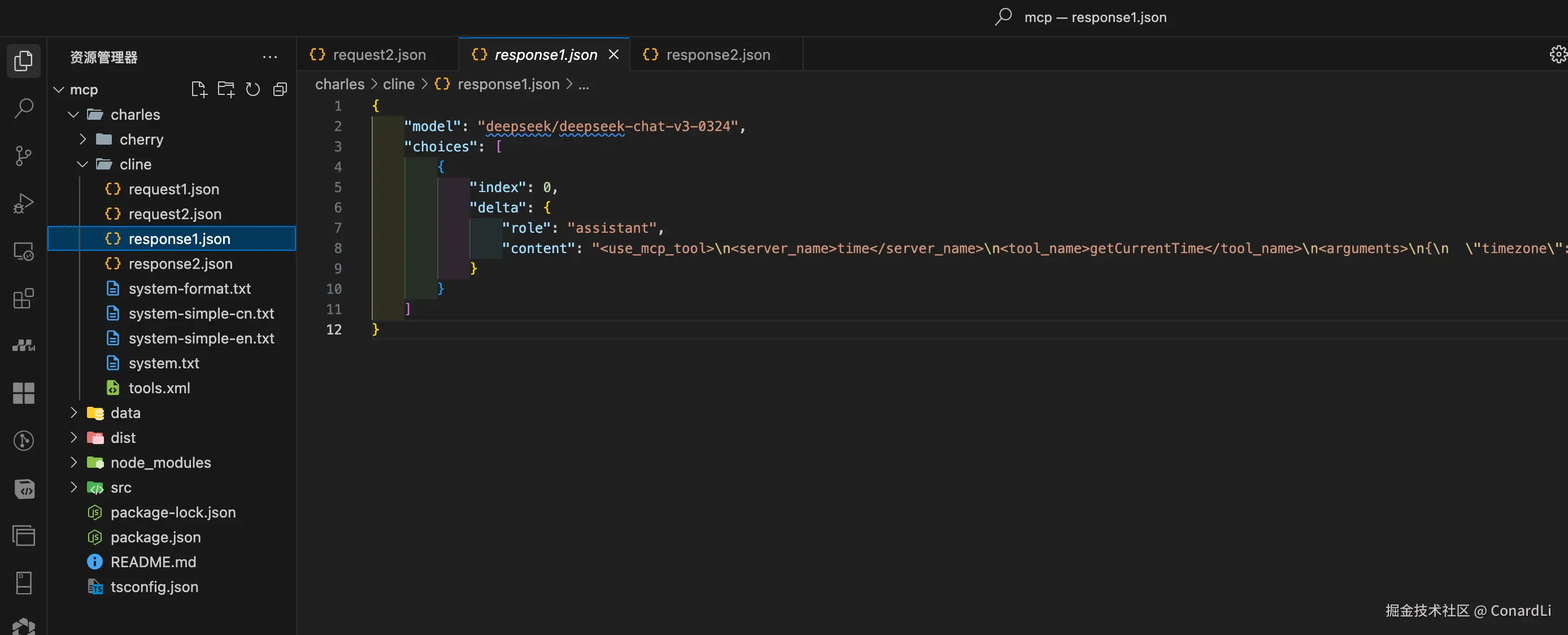
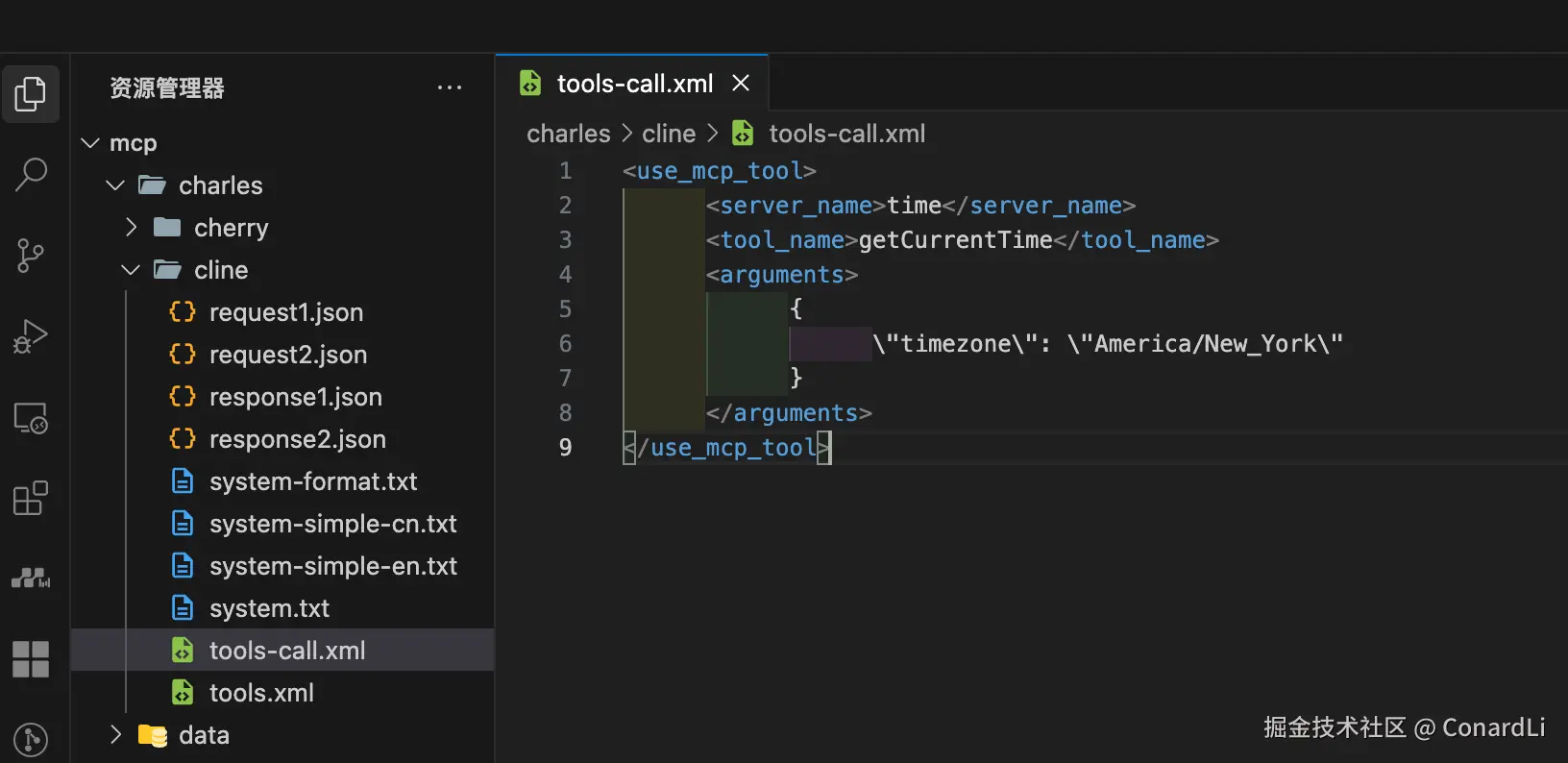
我们格式化一下,发现和系统提示词里要求的工具调用格式是相同的:
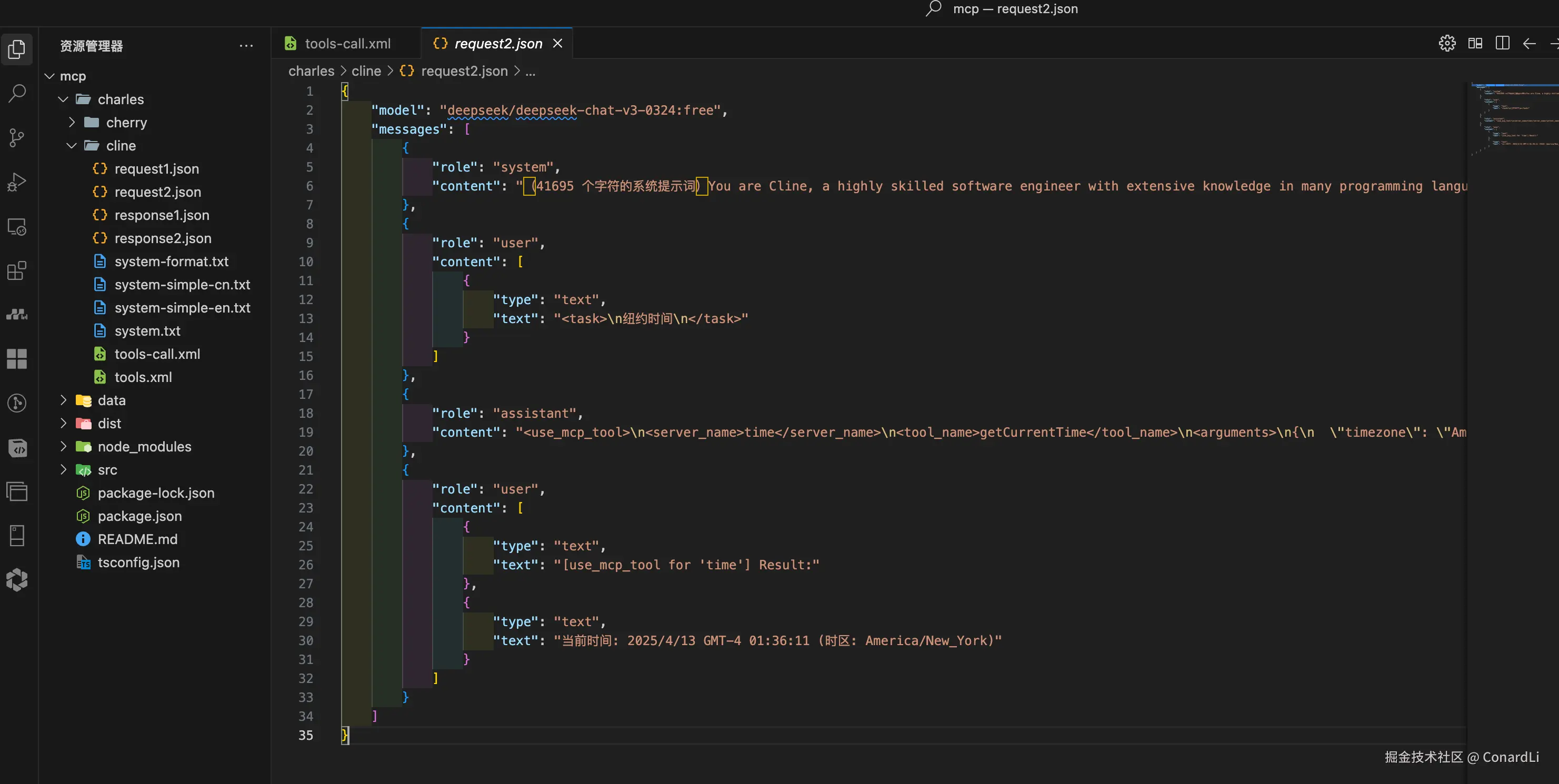
- 第二次请求:客户端将上次模型返回的工具调用参数,以及在本地执行工具调用后的结果都合并到 messages 里,传递给模型,让模型基于这些信息生成最终回答:
- 第二次响应:模型根据输入的信息产出最终回答给用户的内容,
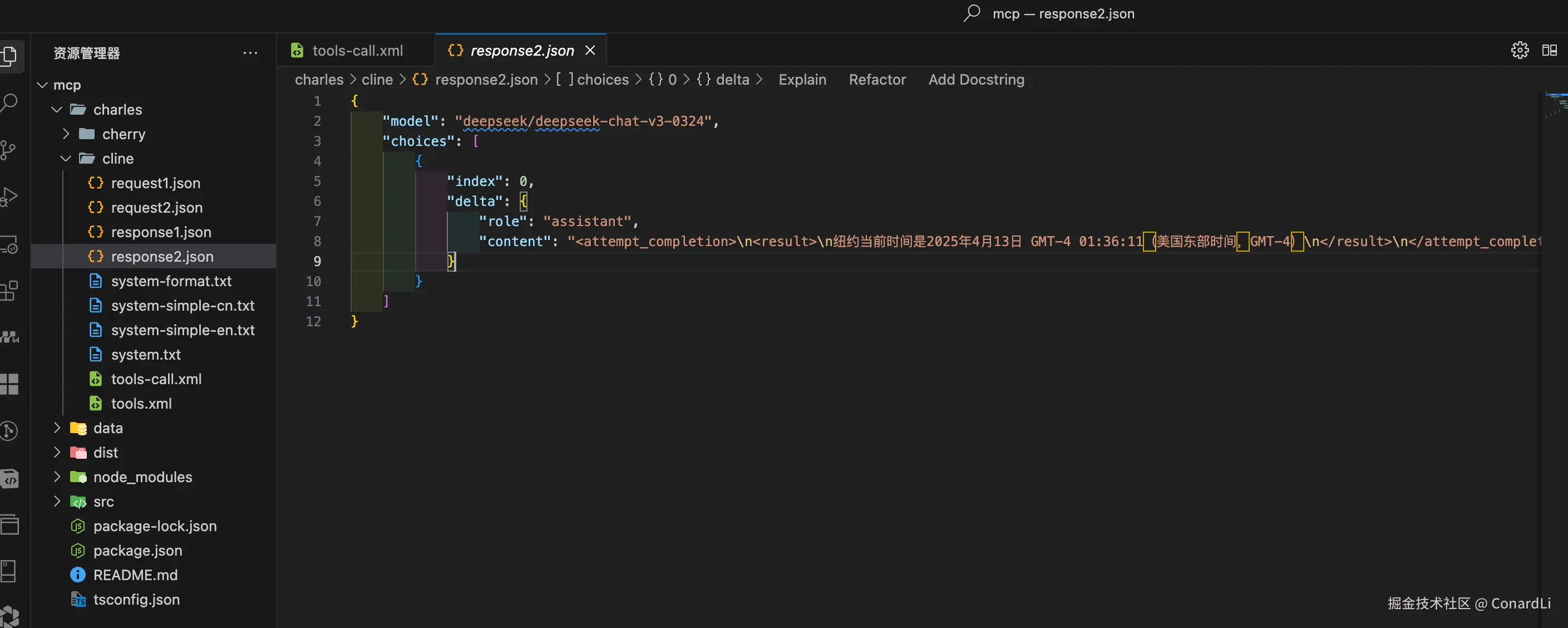
这里依然按照系统提示词中约定的标准格式返回:
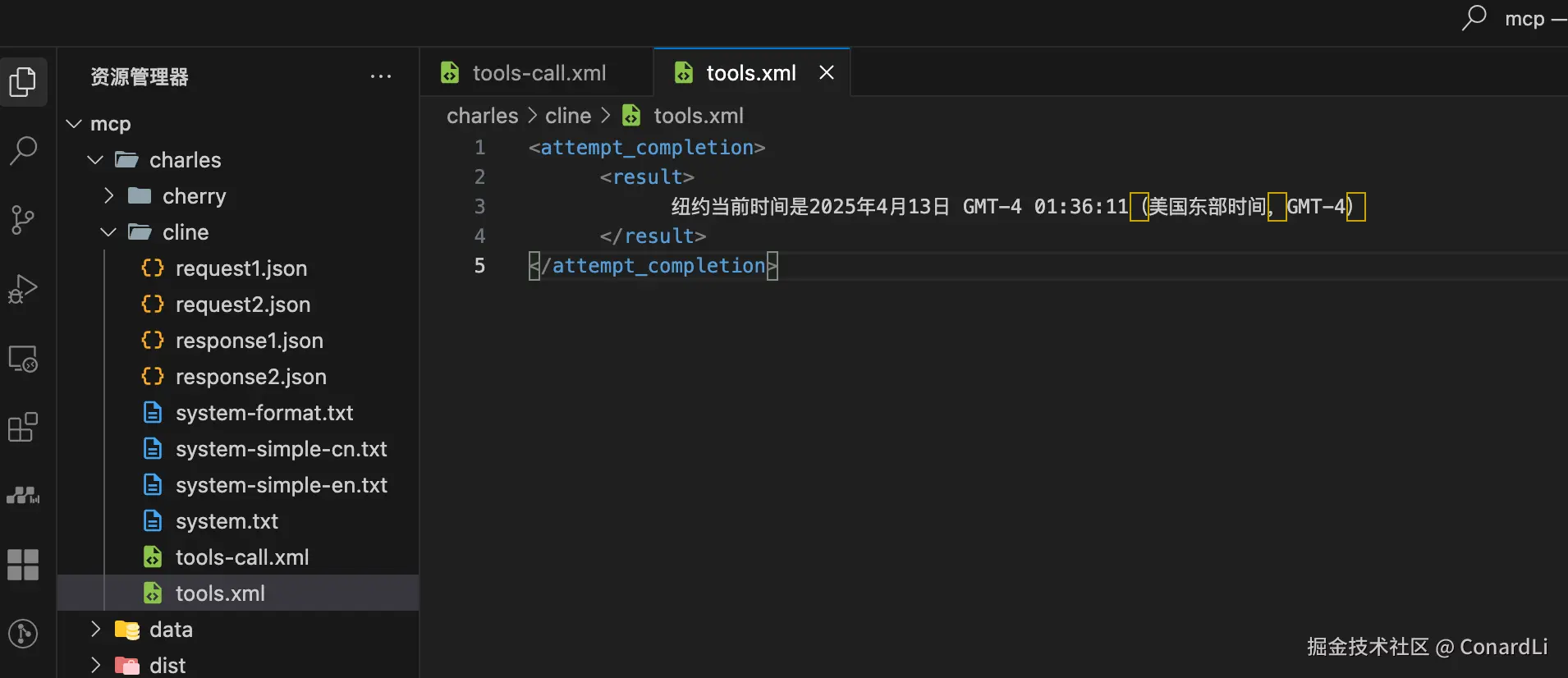
4.4 MCP 的核心流程总结
看到这里,大家应该比较明确了,Cherry Studio 实际上是通过将 MCP Server 中提供的工具、响应结果,转换为 Function Call 的标准格式来和模型进行交互。
Cline 将 MCP Server 中提供的工具、响应结果转换未一套自己约定的输入、输出的标准数据格式,通过系统提示词来声明这种约定,再和模型进行交互。
这也解释了,为什么在 Cherry Studio 中只有一部分模型支持 MCP,前提是选择的模型需要支持 Function Call 的调用,并且在客户端进行了特殊适配;而 Cline 则使用的是系统提示词,所以所有模型都支持。
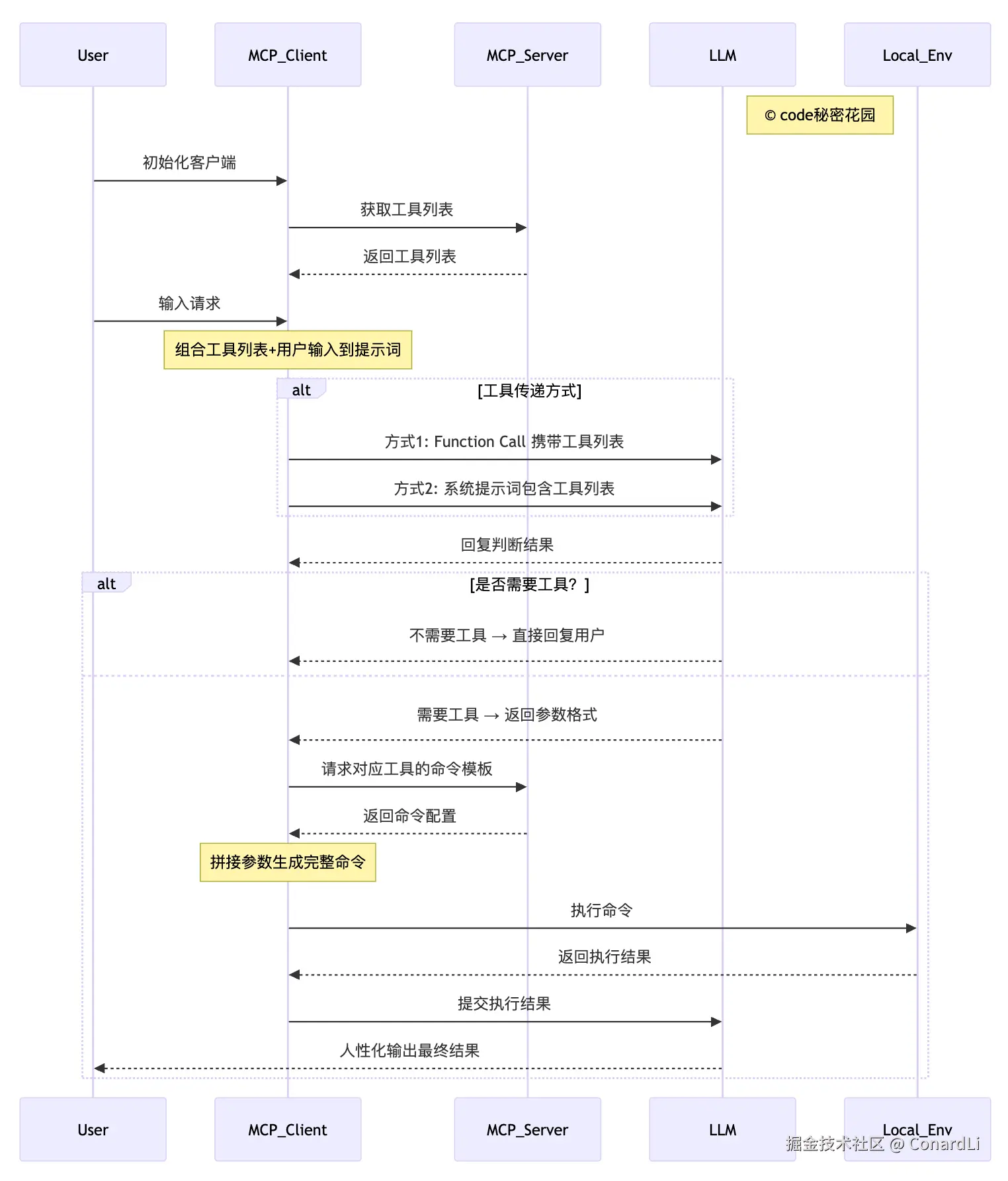
-
初始化与工具列表获取
用户首先对MCP客户端进行初始化操作,随后MCP客户端向MCP服务器发送请求以获取可用的工具列表,MCP服务器将工具列表返回给客户端。
-
用户输入与提示词构建
用户在客户端完成初始化后,向MCP客户端输入具体请求。客户端将此前获取的工具列表与用户输入内容相结合,共同组成用于询问LLM的提示词。
-
工具传递方式选择
MCP客户端通过两种方式之一将提示词传递给LLM:
- 方式1:使用Function Call(函数调用)直接携带工具列表信息;
- 方式2:在系统提示词(System Prompt)中包含工具列表。
-
LLM判断与响应
LLM接收到提示词后,返回判断结果:
- 无需工具:LLM直接将处理结果通过MCP客户端回复给用户;
- 需要工具:LLM先向客户端返回所需工具的参数格式要求。
-
工具命令生成与执行
若需要工具,MCP 客户端根据 LLM 提供的参数格式,以及 MCP Server 配置的命令模板进行拼接,生成完整的可执行命令,并在本地环境(Local_Env)中执行该命令。
-
结果处理与输出
本地环境执行命令后,将结果返回给 MCP 客户端。客户端将执行结果提交给 LLM,由 LLM 对技术化的执行结果进行处理,最终以人性化的语言形式输出给用户。
五、使用 mcp-client-nodejs 展示 MCP 交互流程
为了方便大家更好的学习和 MCP ,我使用 Node.js 开发了一个基础版的 MCP Clinet(基于 Function Call 实现),项目地址:github.com/ConardLi/mc...
MCP Clinet 的开发还是稍微有点门槛的,所以不在这期教程里演示具体的代码细节,主要用此工具来帮助大家更深入的理解 MCP Clinet 和 MCP Server 的整个交互流程,至于开发者们如果感兴趣可以直接基于我的项目进行二次开发。
5.1 基于 LLM 构建 MCP Client
同样的,这个客户端的核心逻辑也是基于 AI 编写的,大家可以直接使用我这个提示词:
markdown
## 需求
我想开发一个 Node.js 版的 MCP Clinet ,下面有一些参考材料,包括 MCP 基础介绍、MCP 核心架构介绍、MCP Clinet 开发教程,请你根据这些参考材料帮我开发一个 MCP Client,注意增加完善的中文注释,以及在开发完成后编写一个完善的中文 Readme 说明文档。
## MCP 基础介绍
粘贴 https://modelcontextprotocol.io/introduction 的内容。
## MCP 核心架构介绍
粘贴 https://modelcontextprotocol.io/docs/concepts/architecture 的内容。
## MCP Client 开发教程
粘贴 https://modelcontextprotocol.io/quickstart/client 的内容。
## 注意点
- 使用 openai 的 SDK 替换 @anthropic-ai/sdk ,这样可以支持更多的模型,兼容性更好
- 你不要指定依赖的版本,如果遇到安装依赖让我自己来安装,你只负责编写代码5.2 mcp-client-nodejs 项目介绍
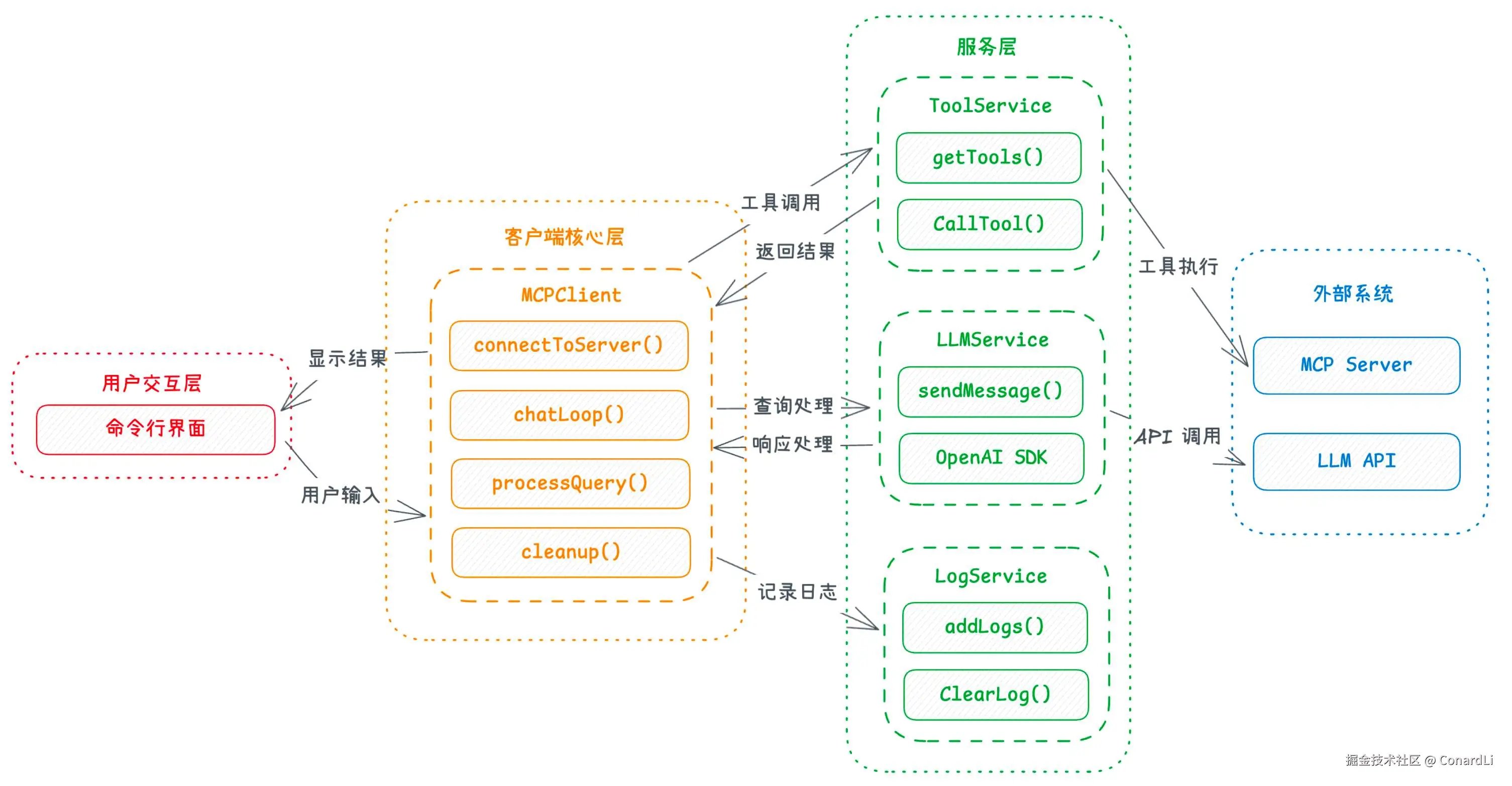
核心特性
- 支持连接任何符合 MCP 标准的服务器
- 支持兼容 OpenAI API 格式的 LLM 能力
- 自动发现和使用服务器提供的工具
- 完善的日志记录系统,包括 API 请求和工具调用
- 交互式命令行界面
- 支持工具调用和结果处理
安装和配置
- 克隆仓库
bash
git clone https://github.com/yourusername/mcp-client.git
cd mcp-client- 安装依赖
bash
npm install- 配置环境变量
复制示例环境变量文件并设置你的 LLM API 密钥:
bash
cp .env.example .env然后编辑 .env 文件,填入你的 LLM API 密钥、模型提供商 API 地址、以及模型名称:
ini
OPENAI_API_KEY=your_api_key_here
MODEL_NAME=xxx
BASE_URL=xxx- 编译项目
bash
npm run build使用方法
要启动 MCP 客户端,你可以使用以下几种方式:
- 直接指定服务器脚本路径
bash
node build/index.js <服务器脚本路径>其中 <服务器脚本路径> 是指向 MCP 服务器脚本的路径,可以是 JavaScript (.js) 或 Python (.py) 文件。
- 使用配置文件
bash
node build/index.js <服务器标识符> <配置文件路径>其中 <服务器标识符> 是配置文件中定义的服务器名称,<配置文件路径> 是包含服务器定义的 JSON 文件的路径。
json
{
"mcpServers": {
"time": {
"command": "node",
"args": [
"/Users/xxx/Desktop/github/mcp/dist/index.js"
],
"description": "自定义 Node.js MCP服务器"
},
"mongodb": {
"command": "npx",
"args": [
"mcp-mongo-server",
"mongodb://localhost:27017/studentManagement?authSource=admin"
]
}
},
"defaultServer": "mongodb",
"system": "自定义系统提示词"
}- 使用 npm 包(npx)
你可以直接通过 npx 运行这个包,无需本地克隆和构建:
bash
# 直接连接脚本
$ npx mcp-client-nodejs /path/to/mcp-server.js
# 通过配置文件连接
$ npx mcp-client-nodejs mongodb ./mcp-servers.json注意:需要在当前运行目录的 .env 配置模型相关信息
5.3 分析 MCP 详细交互流程
MCP Client 包含一个全面的日志系统,详细记录所有关键操作和通信。日志文件保存在 logs/ 目录中,以 JSON 格式存储,方便查询和分析。
- LLM 的请求和响应 - 记录与 LLM API 的所有通信
- 工具调用和结果 - 记录所有工具调用参数和返回结果
- 错误信息 - 记录系统运行期间的任何错误
日志文件连统命名为 [index] [log_type] YYYY-MM-DD HH:MM:SS.json,包含序号、日志类型和时间戳,方便按时间顺序查看整个会话。
下面我们使用 mcp-mongo-server 来演示整个流程,首先在项目目录新建 mcp-servers.json,并填写下面的配置:
json
{
"mcpServers": {
"mongodb": {
"command": "npx",
"args": [
"mcp-mongo-server",
"mongodb://localhost:27017/studentManagement?authSource=admin"
]
}
},
"system": "使用中文回复。\n\n当用户提问中涉及学生、教师、成绩、班级、课程等实体时,需要使用 MongoDB MCP 进行数据查询和操作,表结构说明如下:xxx"
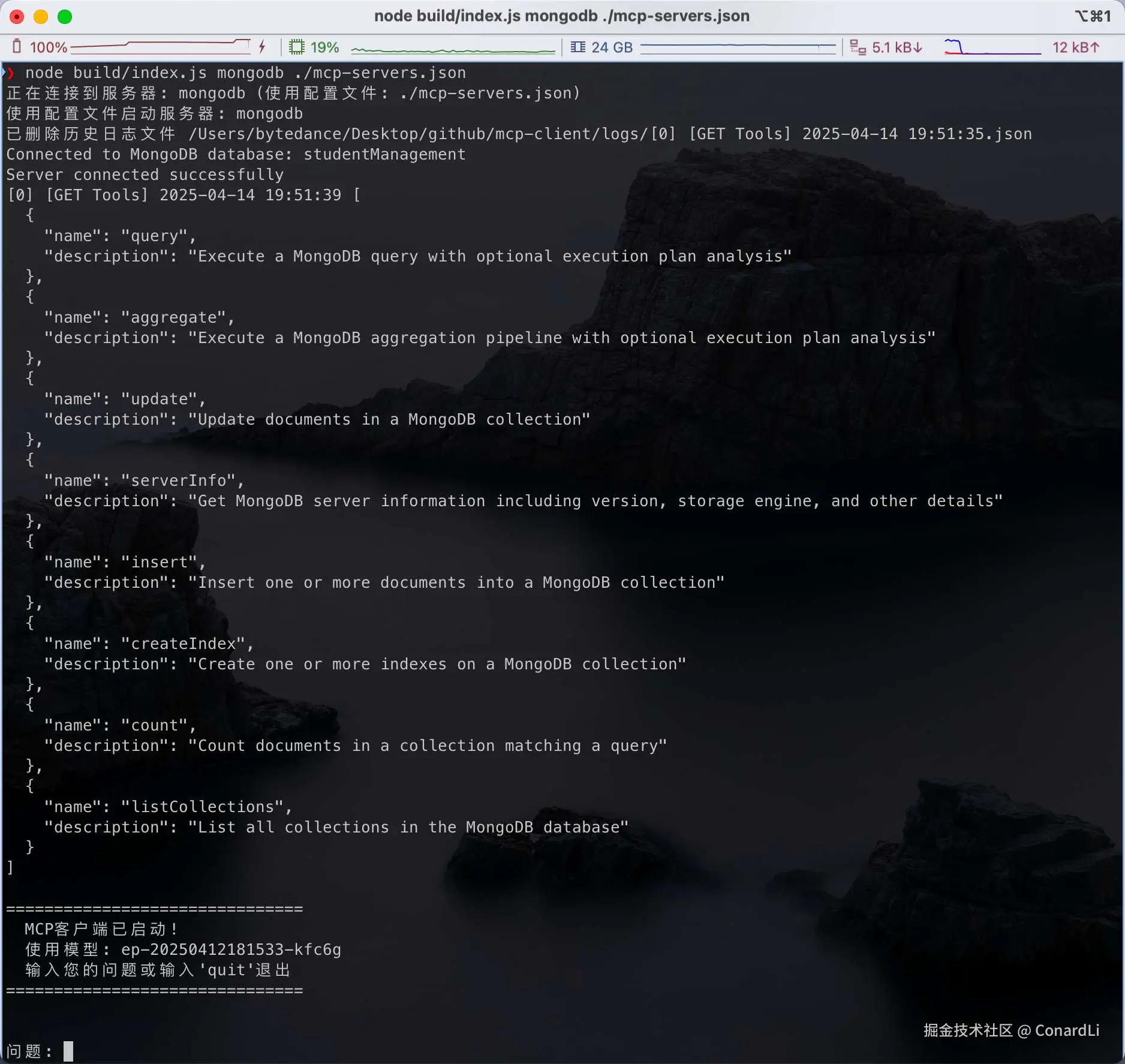
}然后执行 node build/index.js mongodb ./mcp-servers.json,客户端成功启动:
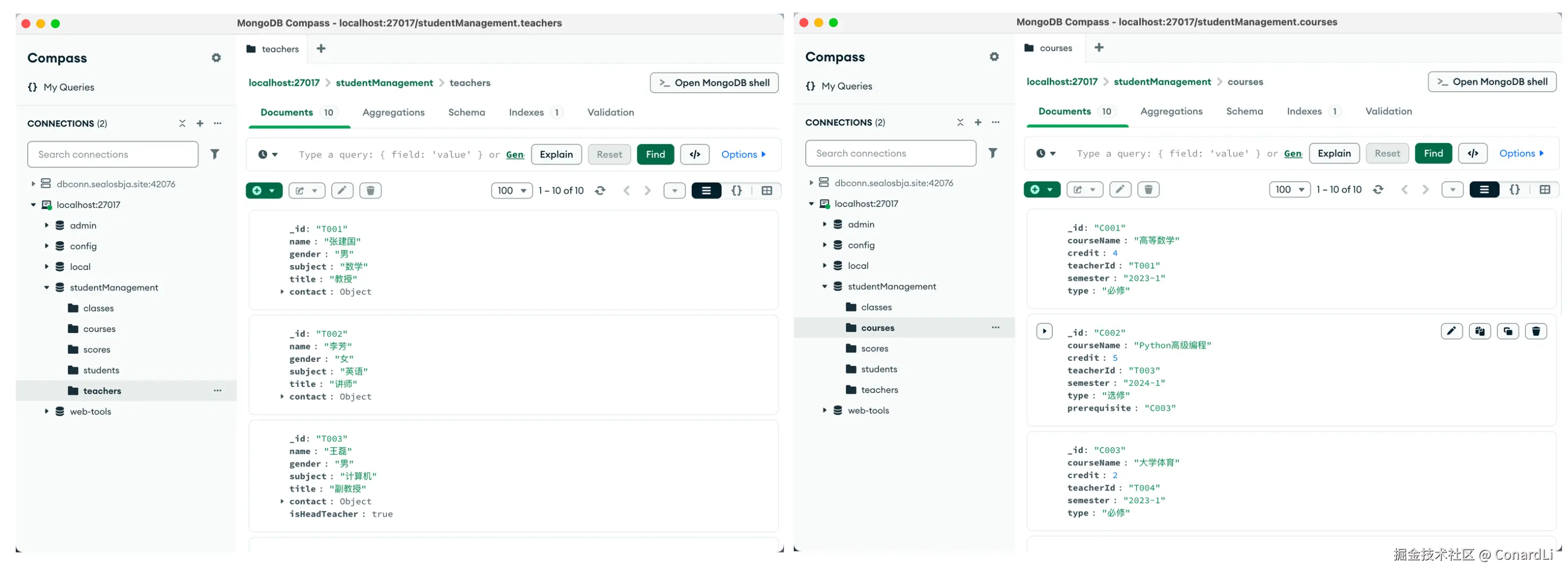
然后我们输入一个问题:张老师教哪门课? ,因为教师信息、课程信息分别存储在两个表:
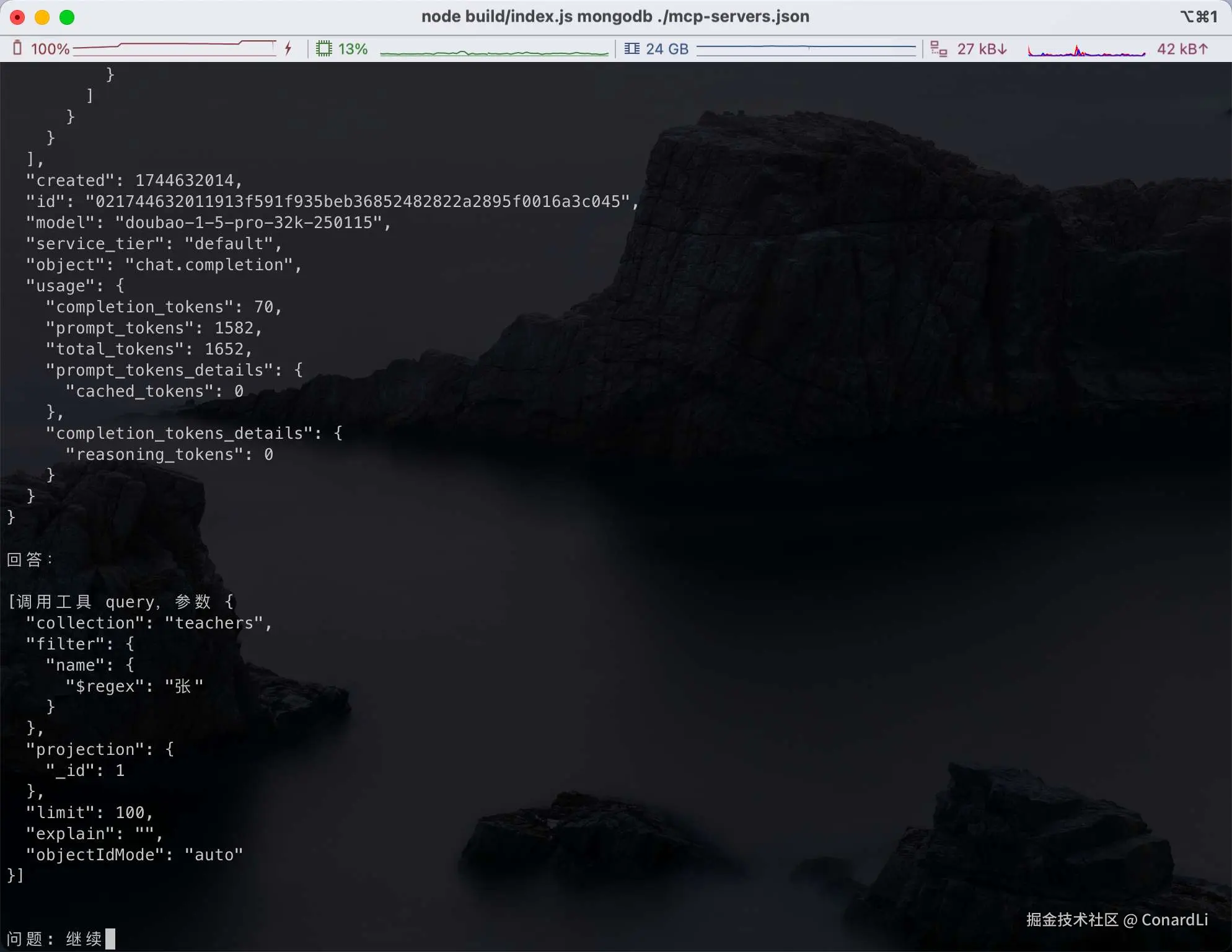
所以这个任务 AI 也需要分两步完成,第一步先去检索教室表中姓张的老师,我们输入继续:
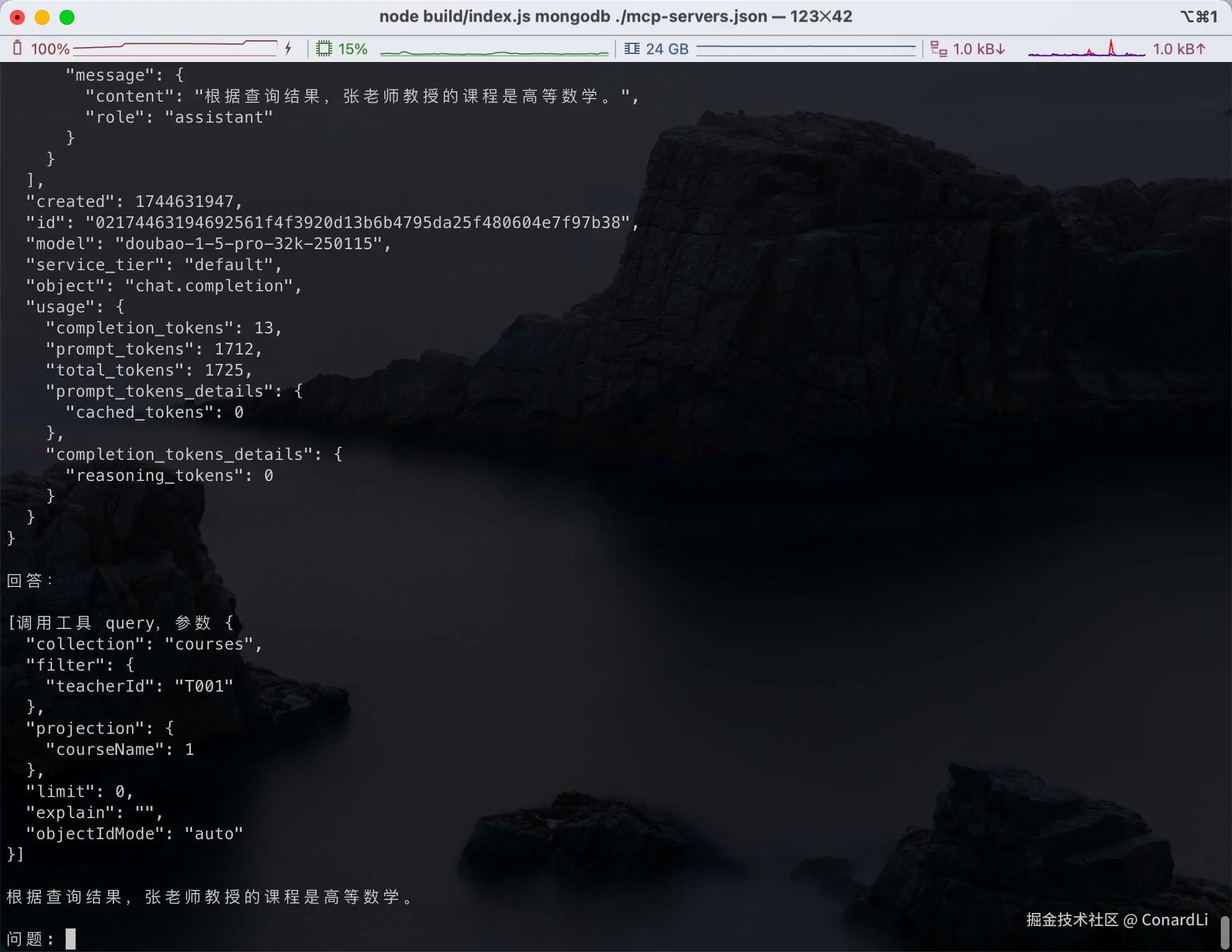
下面检索课程表,得出最终信息:
然后我们发现,整个过程一共产生了 13 调日志:
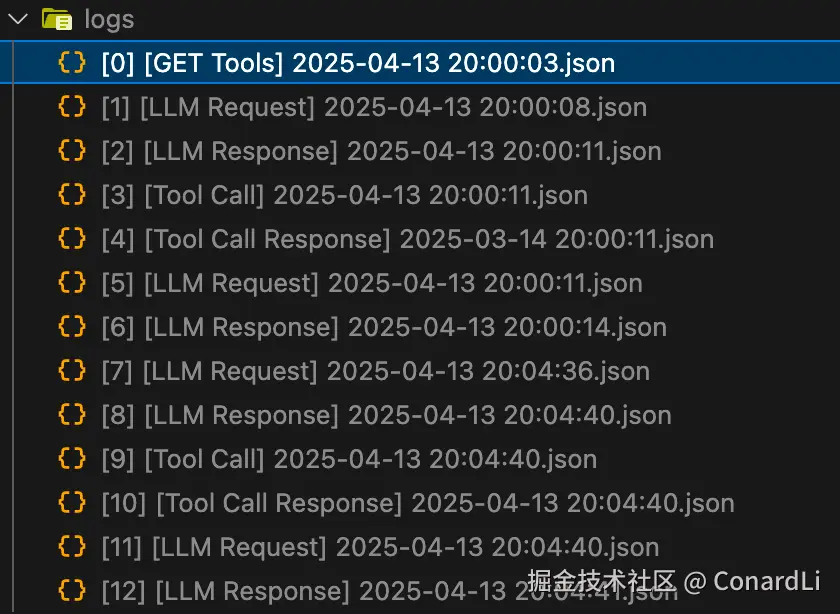
我们逐个来看一下:
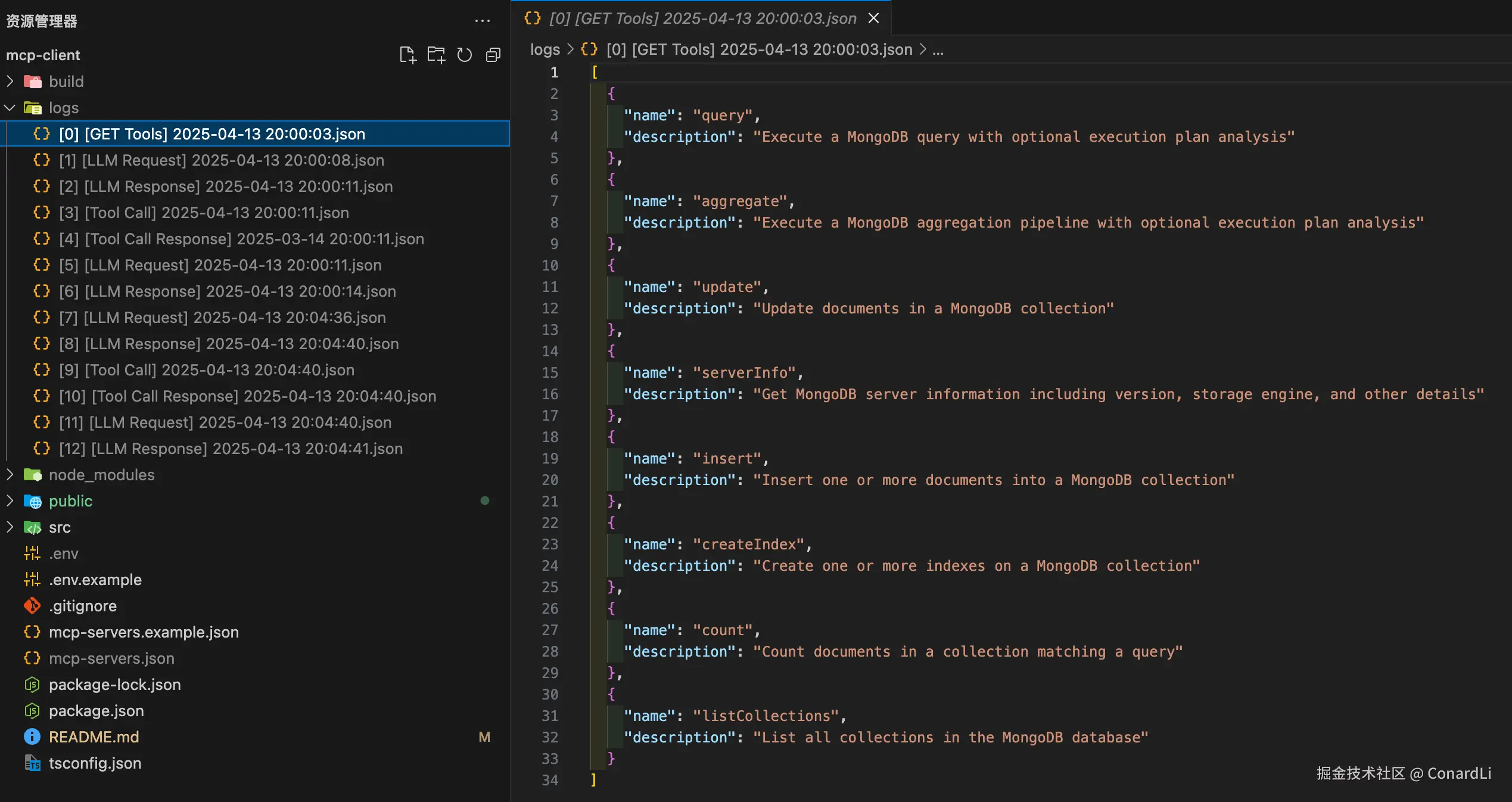
[0] [GET Tools]:在客户端初始化时,拉取当前配置的 MCP Server 下提供的所有工具列表:
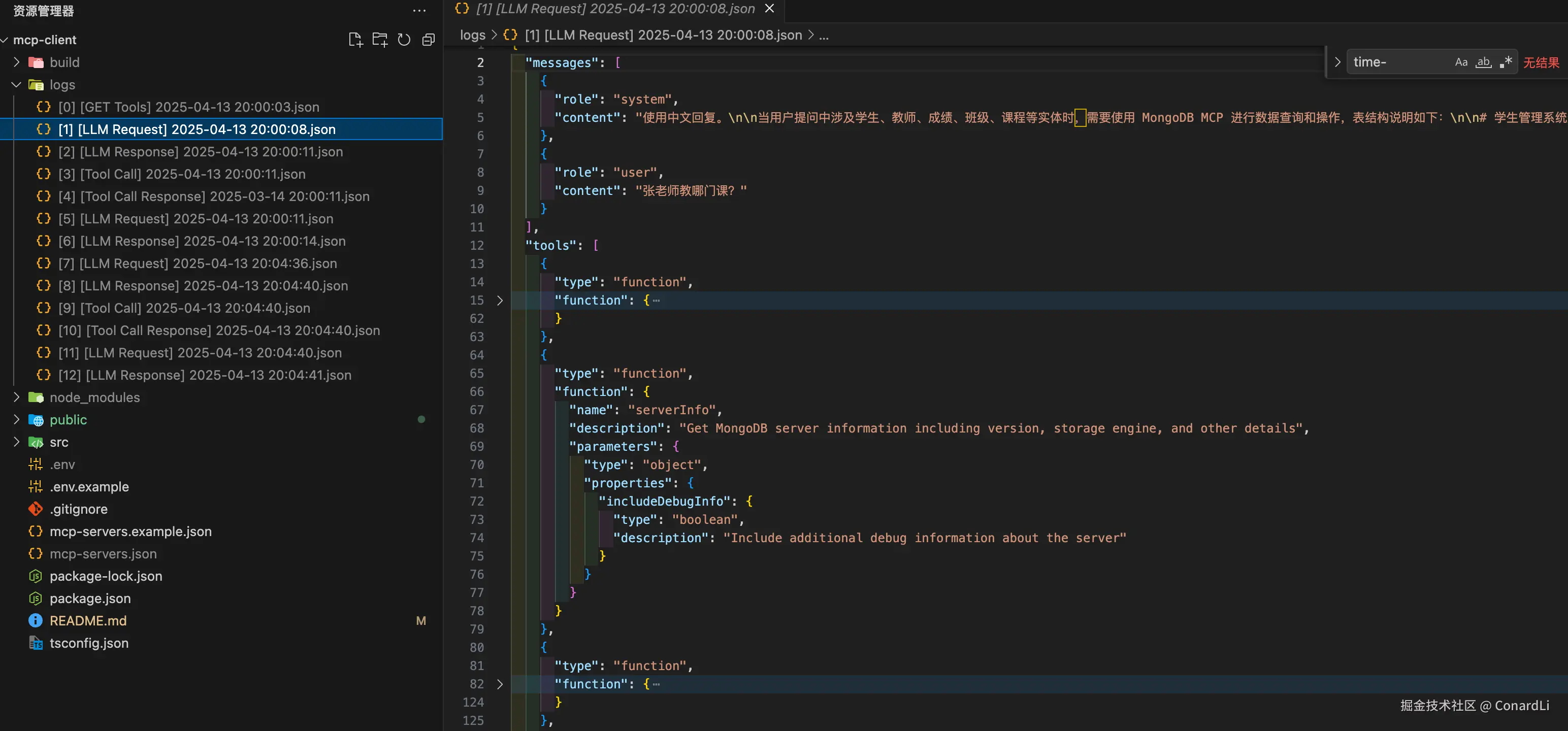
[1] [LLM Request]:向大模型发送 用户问题,并将所有工具列表(包含函数+参数的具体定义)通过 tools 字段传递过去:
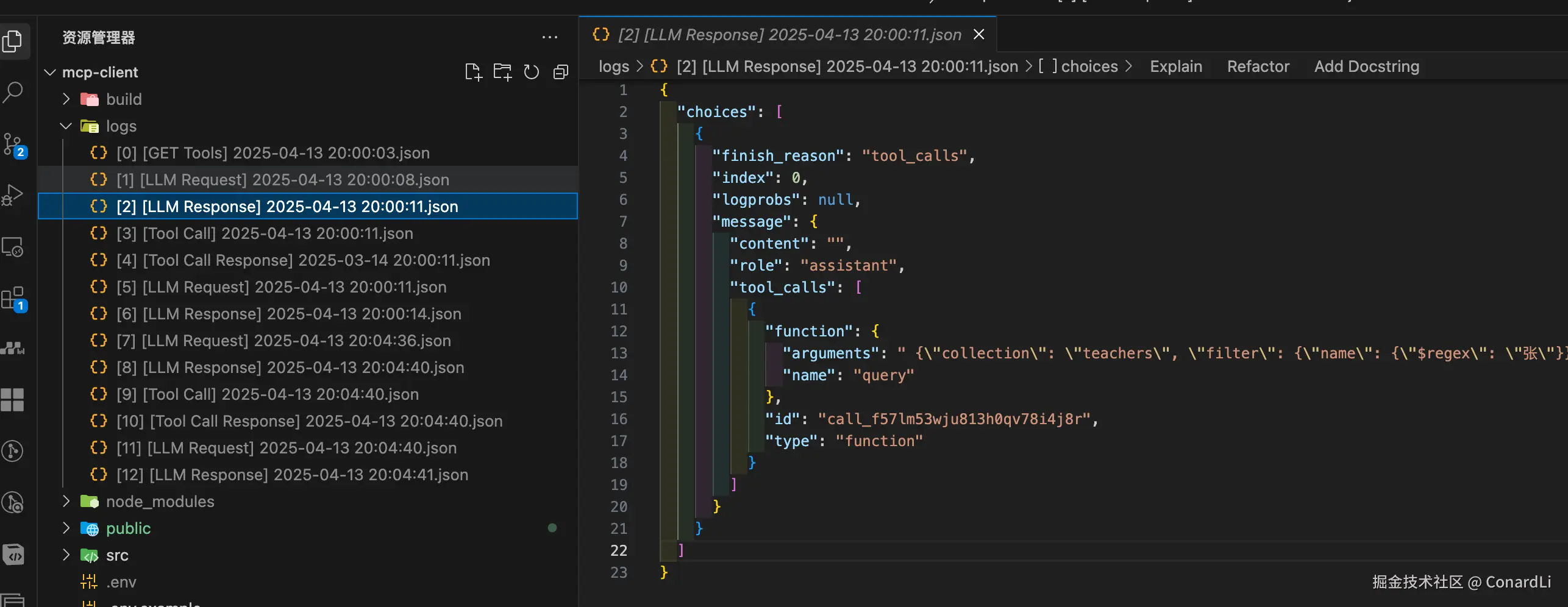
[2] [LLM Response]:模型根据用户输入 + 支持的参数列表判断需要使用的工具,并通过 tool_calls 字段返回:
[3] [Tool Call]:客户端根据模型返回的函数+参数+MCP 服务器的配置,拼接成一条可执行的命令,执行第一次工具调用:从 teachers 表中检索姓张的老师的信息:
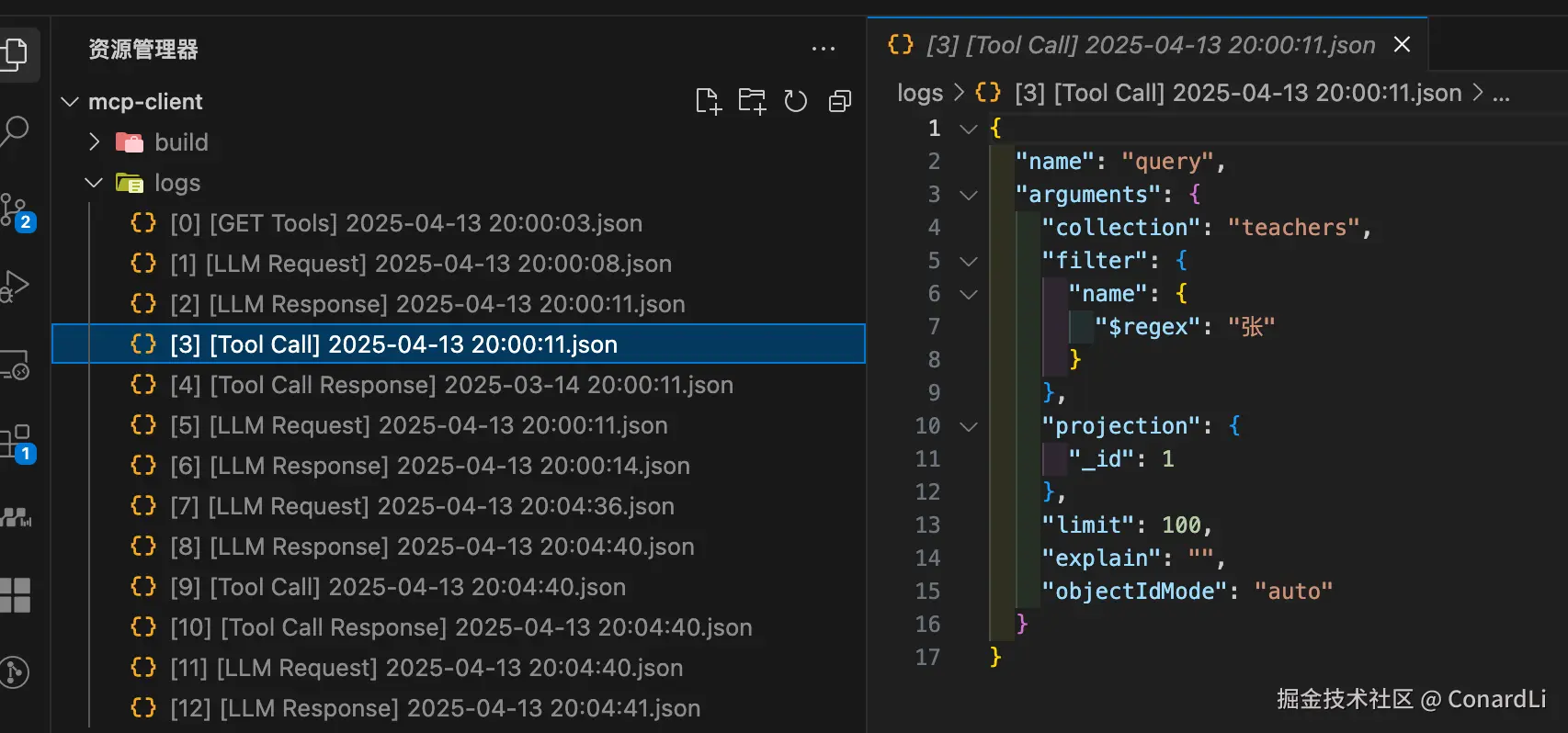
[4] [Tool Call Response]:工具返回结果:姓张的老师的 ID:
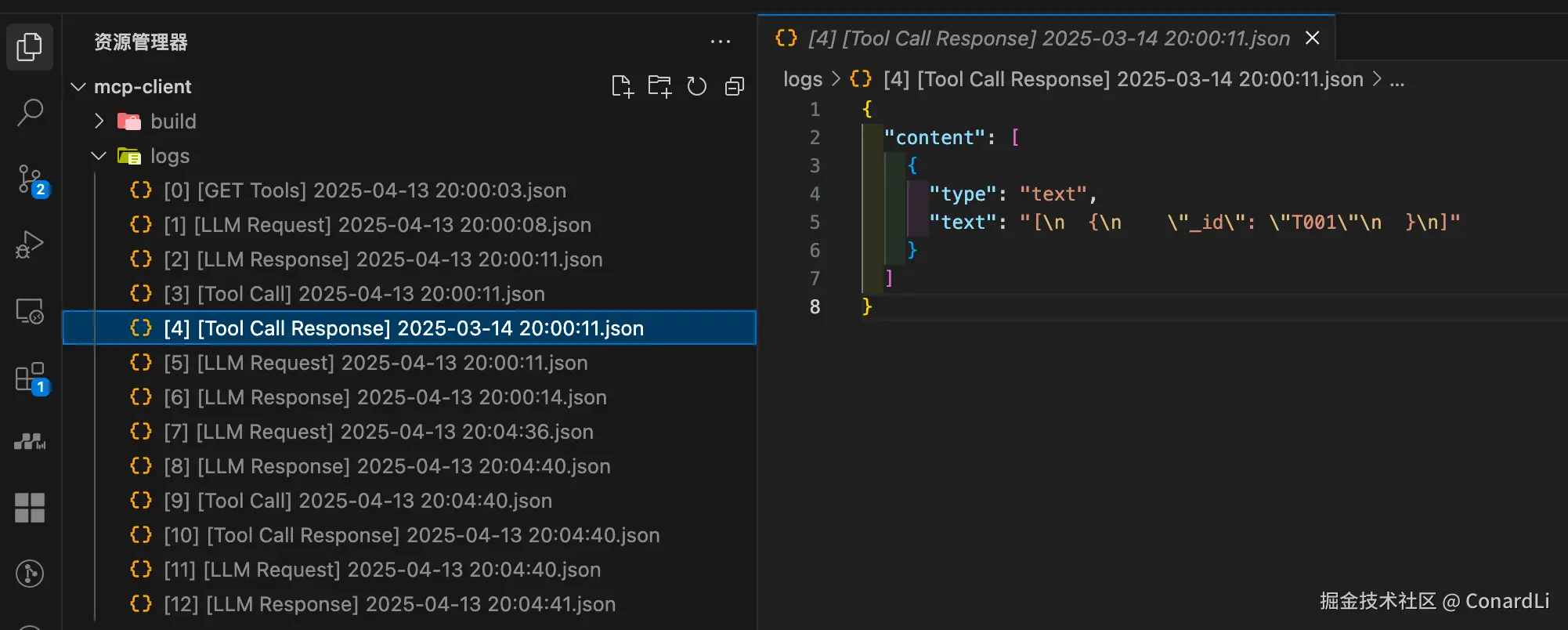
[5] [LLM Request]:客户端将工具调用的结果反馈给模型:
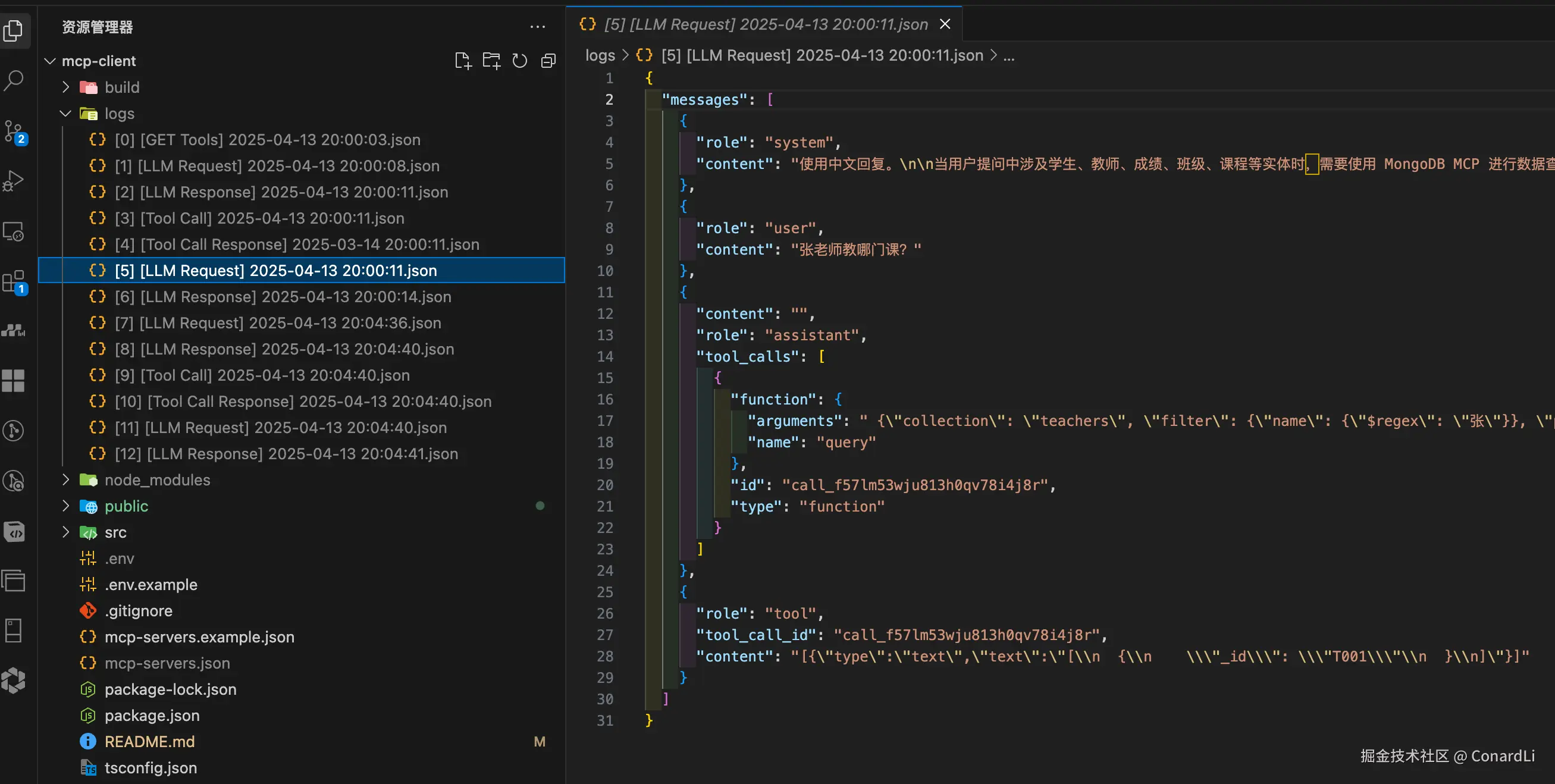
[6] [LLM Response]:模型判断本次任务没有完成,需要继续执行工具调用(根据教师 ID 去课程表查询课程信息):
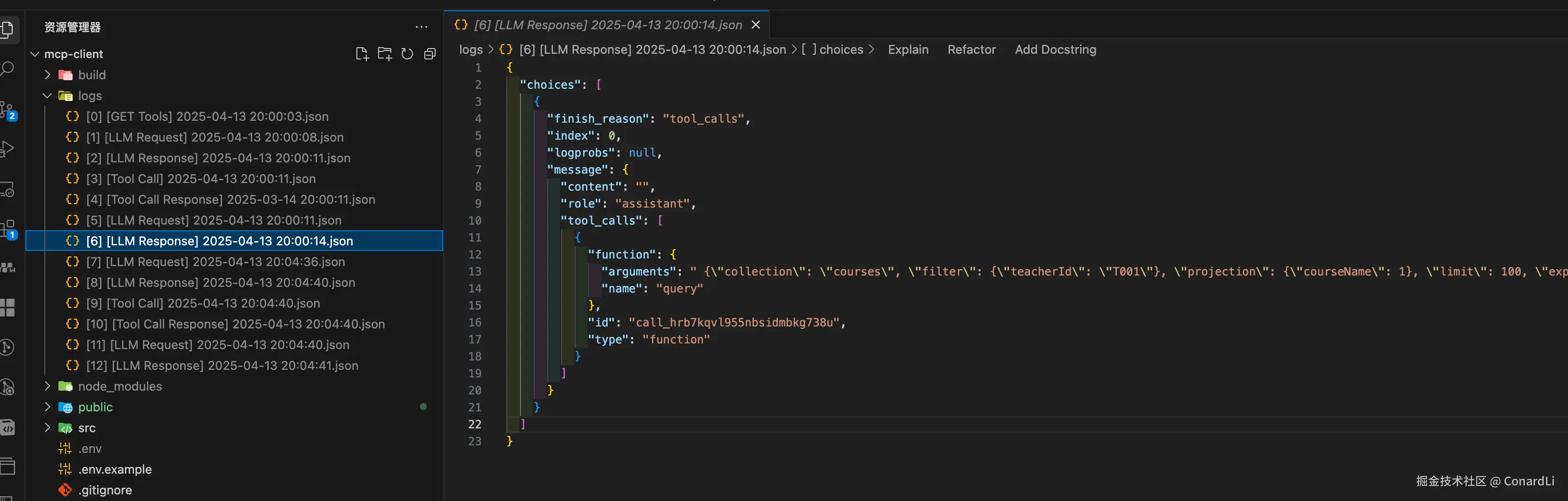
[7] [LLM Request]:因为一次交互已经完成,但并未完成任务,所以客户端主动询问用户是否继续,用户选择继续,所以再次发送请求:
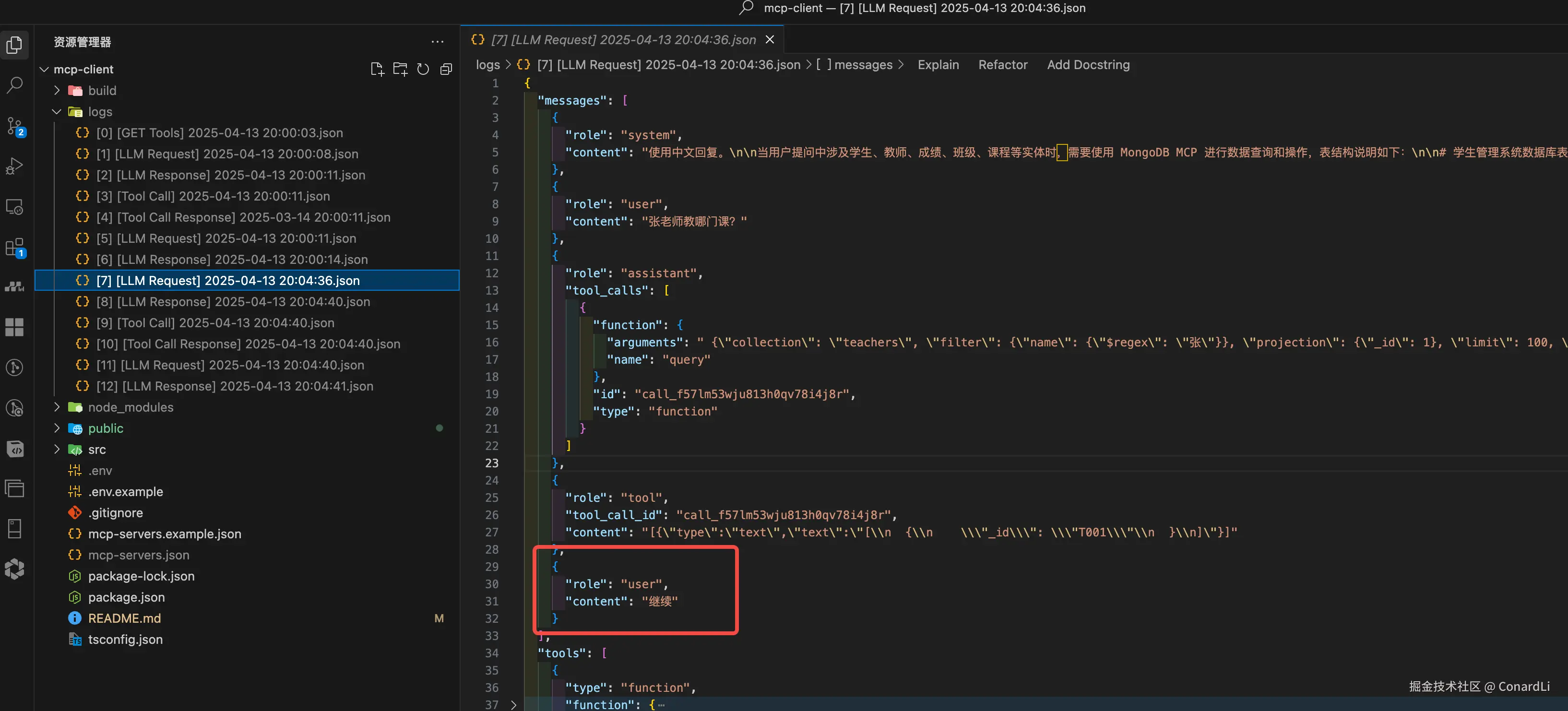
-
[8] [LLM Response]:和 6 返回的内容一样(实际上这一步有点重复),如果用户选择继续可以直接发起第二次工具调用 -
[9] [Tool Call]:客户端执行工具调用,查询课程信息:
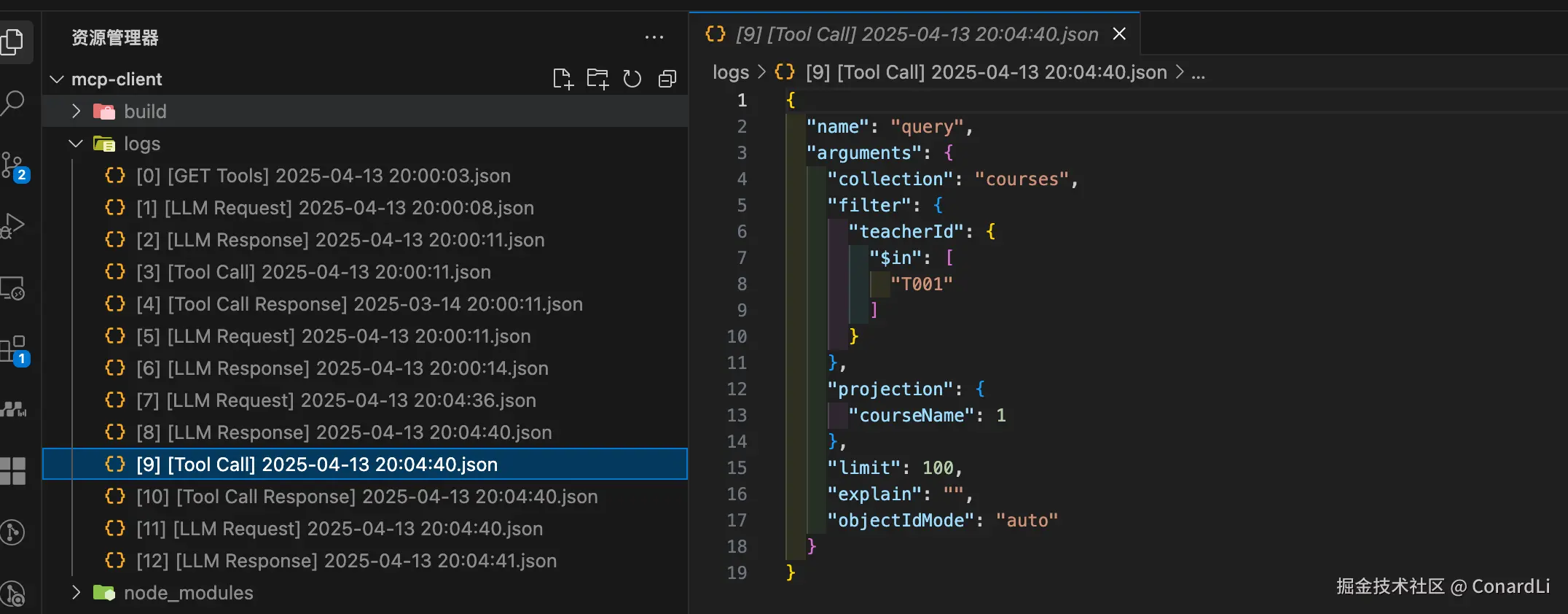
[10] [Tool Call Response]:工具返回班级信息:
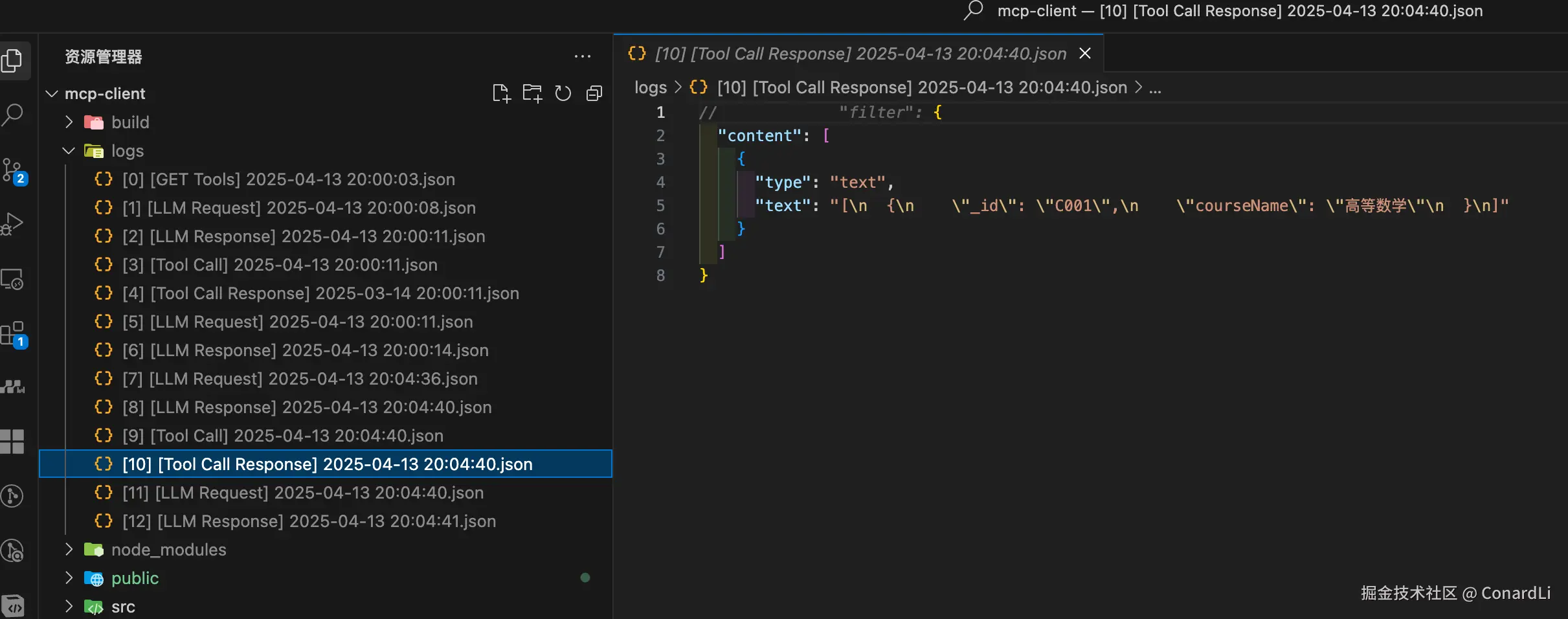
[11] [LLM Request]:客户端将之前工具调用的所有信息再次返回给模型:
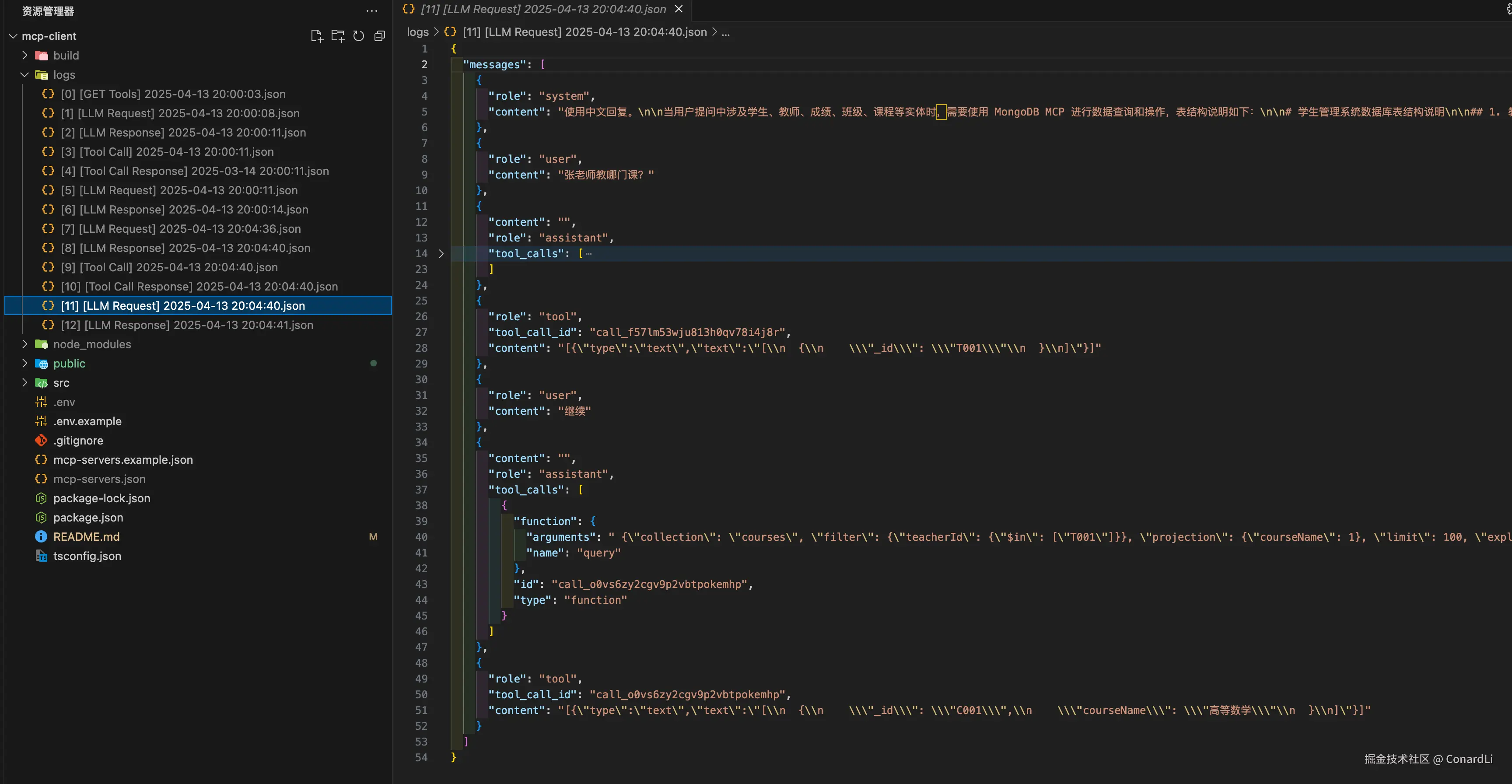
[12] [LLM Response]:模型最终给出人性化输出:
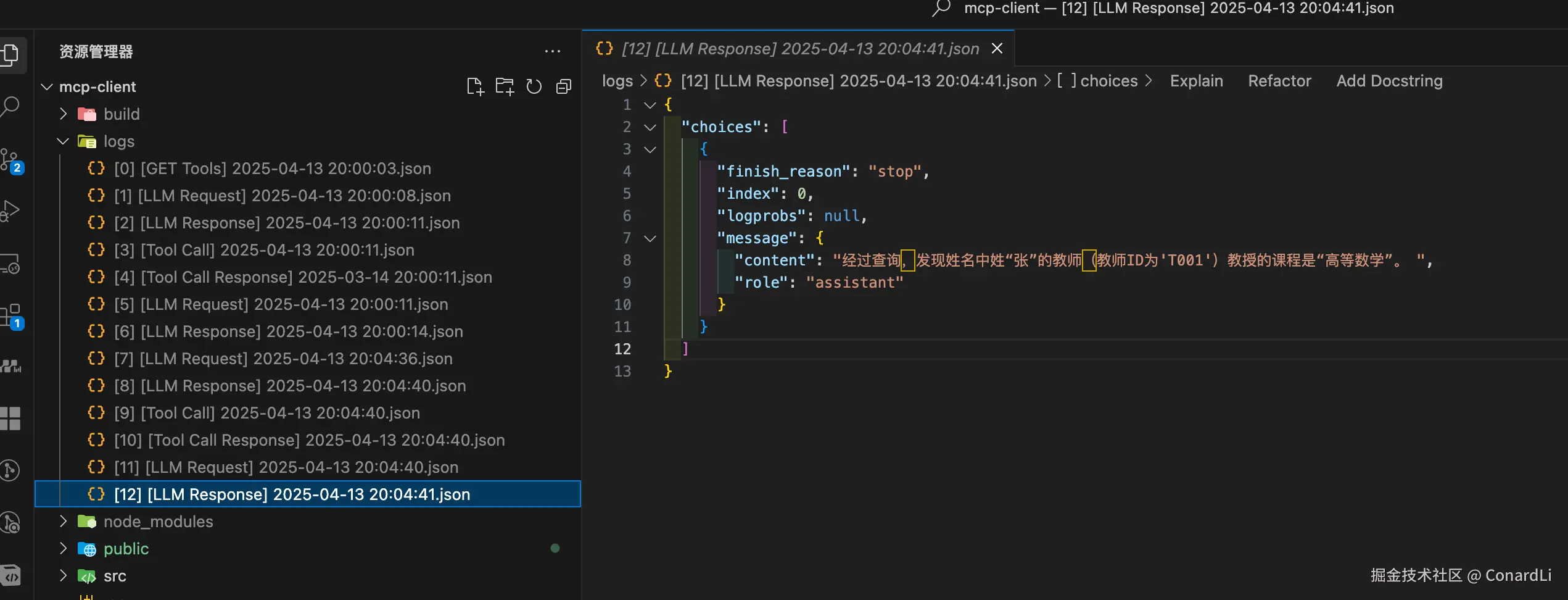
5.4 最终流程总结
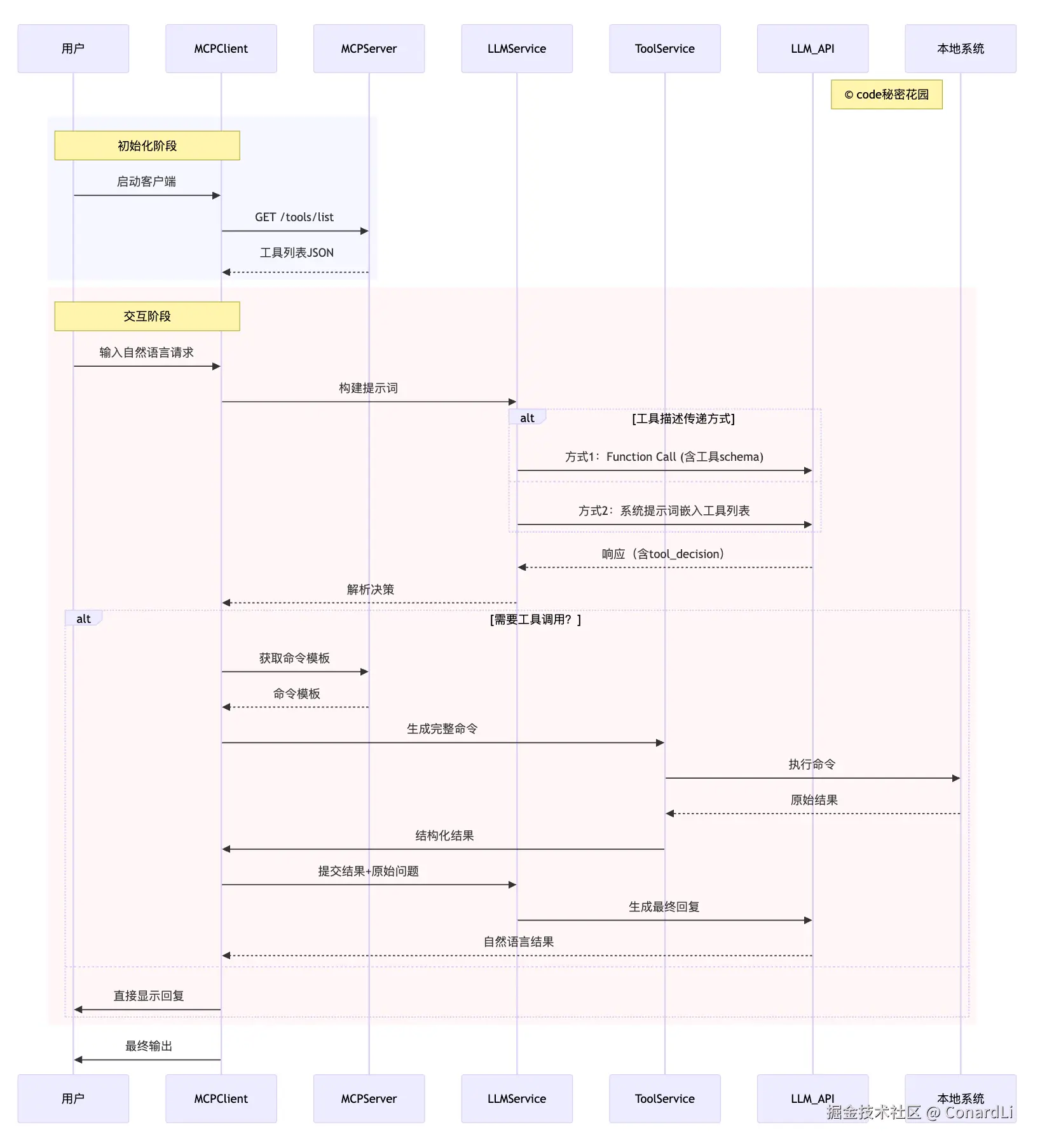
以上的过程,非常清晰的展示了整个 MCP 的交互流程,下面我们最后再总结一下:
一、初始化阶段
- 客户端启动与工具列表获取
- 用户首先启动 MCPClient,完成初始化操作。
- MCPClient 向 MCPServer 发送 GET /tools/list 请求,获取可用工具的元数据。
- MCPServer 返回包含工具名称、功能描述、参数要求等信息的 工具列表JSON,供客户端后续构建提示词使用。
二、交互阶段
1. 用户输入与提示词构建
- 用户通过 MCPClient 输入自然语言请求(如"查询服务器状态""生成文件报告"等)。
- MCPClient 将用户请求与初始化阶段获取的 工具列表 结合,生成包含任务目标和工具能力的提示词(Prompt),传递给 LLMService(大语言模型服务层)。
2. 工具描述传递方式(二选一)
- 方式1(Function Call) :
LLMService 通过 LLM_API 调用大语言模型时,在请求中直接携带 工具schema(结构化工具定义,如参数格式、调用格式),告知模型可用工具的调用方式。 - 方式2(系统提示词嵌入) :
LLMService 将工具列表以自然语言描述形式嵌入 系统提示词(System Prompt),让模型在理解用户需求时知晓可用工具的功能边界。
3. 模型决策与响应解析
- LLM_API 返回包含 tool_decision (工具调用决策)的响应:
- 若判定 无需工具(如简单文本回复),响应直接包含最终答案;
- 若判定 需要工具(如需要执行本地命令、调用外部接口),响应中包含所需工具的参数要求(如工具名称、入参格式)。
- LLMService 解析决策结果,将信息传递给 MCPClient。
4. 工具调用分支(需要工具时)
- 获取命令模板 : MCPClient 根据模型指定的工具名称,在初始化时保存的工具配置中取出对应的 命令模板(如Shell命令格式、API调用参数模板)。
- 生成与执行命令 : MCPClient 将用户输入参数与命令模板结合,通过 ToolService (工具执行服务)生成完整可执行命令,并提交给 本地系统 执行。
- 结果处理 :本地系统 返回原始执行结果(如命令输出文本、API返回数据),ToolService 将其转换为 结构化结果 (如JSON格式),反馈给 MCPClient。
- 二次调用模型生成最终回复 :MCPClient 将结构化结果与用户原始问题一并提交给 LLMService ,通过 LLM_API 调用模型,将技术化的执行结果转化为自然语言描述(如将"服务器CPU使用率80%"转化为"当前服务器CPU负载较高,建议检查进程")。
5. 直接回复分支(无需工具时)
- 若模型判定无需工具,MCPClient 直接将模型响应显示给用户(如简单的文本问答、信息总结)。
三、最终输出
无论是否经过工具调用,MCPClient 最终将处理后的 自然语言结果 呈现给用户,完成整个交互流程。
六、最后
关注《code秘密花园》从此学习 AI 不迷路,code秘密花园 AI 教程完整的学习资料汇总在这个飞书文档:rncg5jvpme.feishu.cn/wiki/U9rYwR...