在计算机科学领域,排序算法是基础且重要的内容。不同的排序算法在时间复杂度、空间复杂度以及稳定性上存在差异,合理选择排序算法能极大提升程序性能。本文将对常见排序算法进行全面剖析,并引入计数排序这一特殊的排序算法。
一、常见排序算法回顾
冒泡排序
冒泡排序是一种简单的比较排序算法。它通过多次比较相邻元素并交换位置,将最大(或最小)的元素逐步 "冒泡" 到数组末尾。平均和最坏时间复杂度为 \(O(n^{2})\) ,当数组本身有序时,最好情况时间复杂度为 \(O(n)\) ,辅助空间为 \(O(1)\) ,是稳定的排序算法。
直接选择排序
直接选择排序每次从未排序序列中选择最小(或最大)的元素,放到已排序序列的末尾。其平均、最好和最坏时间复杂度均为 \(O(n^{2})\) ,辅助空间 \(O(1)\) ,但它是不稳定的排序算法。
直接插入排序
直接插入排序类似于玩扑克牌时整理牌的过程,将一个数据插入到已经排好序的数组中的适当位置。平均和最坏时间复杂度是 \(O(n^{2})\) ,最好情况为 \(O(n)\) ,辅助空间 \(O(1)\) ,属于稳定排序算法 。
希尔排序
希尔排序是对直接插入排序的改进,通过将原始数据分成若干子序列进行插入排序,逐步缩小增量,最终使整个序列有序。时间复杂度在 \(O(nlogn) \sim O(n^{2})\) 之间,最好情况为 \(O(n^{1.3})\) ,辅助空间 \(O(1)\) ,是不稳定排序算法。
堆排序
堆排序利用堆这种数据结构所设计,将数组构建成大顶堆或小顶堆,然后不断取出堆顶元素并调整堆,实现排序。其平均、最好和最坏时间复杂度都是 \(O(nlogn)\) ,辅助空间 \(O(1)\) ,但不具备稳定性。
归并排序
归并排序采用分治思想,将数组不断二分,对左右子数组分别排序后再合并。时间复杂度在各种情况下均为 \(O(nlogn)\) ,不过需要额外的 \(O(n)\) 辅助空间,是稳定的排序算法。
快速排序
快速排序也是基于分治思想,选取一个基准元素,将数组分为两部分,左边小于基准,右边大于基准,再分别对两部分递归排序。平均和最好时间复杂度为 \(O(nlogn)\) ,最坏情况退化为 \(O(n^{2})\) ,辅助空间在 \(O(logn) \sim O(n)\) 之间,是不稳定排序算法。
计数排序
计数排序是一种非比较排序算法,适用于待排序元素取值范围相对较小的情况。它的基本思想是统计每个元素出现的次数,然后根据统计结果将元素依次放回原数组中。
计数排序的时间复杂度为 \(O(n + k)\) ,其中 n 是元素个数,k 是元素取值范围。辅助空间为 \(O(k)\) 。由于在排序过程中,相同元素的相对顺序不会改变,所以它是稳定的排序算法。例如,对于一组成绩在 0 - 100 之间的学生成绩排序,计数排序就能高效完成任务。
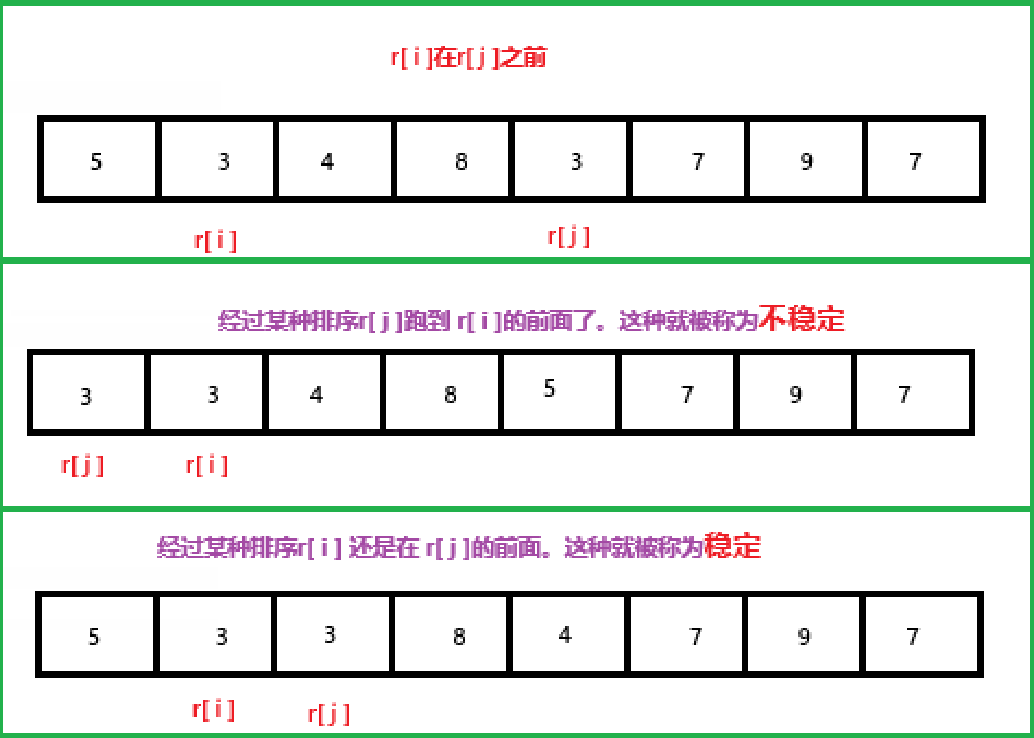
稳定性:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,⽽在排序后的序列中,ri仍在rj之 前,则称这种排序算法是稳定的;否则称为不稳定的。
常见的八种排序对比:
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | \(O(n^{2})\) | \(O(n)\) | \(O(n^{2})\) | \(O(1)\) | 稳定 |
| 直接选择排序 | \(O(n^{2})\) | \(O(n^{2})\) | \(O(n^{2})\) | \(O(1)\) | 不稳定 |
| 直接插入排序 | \(O(n^{2})\) | \(O(n)\) | \(O(n^{2})\) | \(O(1)\) | 稳定 |
| 希尔排序 | \(O(nlogn) \sim O(n^{2})\) | \(O(n^{1.3})\) | \(O(n^{2})\) | \(O(1)\) | 不稳定 |
| 堆排序 | \(O(nlogn)\) | \(O(nlogn)\) | \(O(nlogn)\) | \(O(1)\) | 不稳定 |
| 归并排序 | \(O(nlogn)\) | \(O(nlogn)\) | \(O(nlogn)\) | \(O(n)\) | 稳定 |
| 快速排序 | \(O(nlogn)\) | \(O(nlogn)\) | \(O(n^{2})\) | \(O(logn) \sim O(n)\) | 不稳定 |
| 计数排序 | \(O(n + k)\) | \(O(n + k)\) | \(O(n + k)\) | \(O(k)\) | 稳定 |
说明:在计数排序中,n 是待排序元素的个数,k 是待排序元素的取值范围(即最大值 - 最小值 + 1 )。
二、总结
不同的排序算法各有优劣,在实际应用中,需要根据具体场景选择合适的排序算法。若数据规模较小,直接插入排序、冒泡排序等简单算法可能更合适;对于大规模数据,归并排序、快速排序等平均性能较好的算法更受青睐;而当数据取值范围有限时,计数排序能展现出极高的效率。理解排序算法的复杂度和稳定性,有助于我们编写出更高效、可靠的程序。