在机器学习中,支持向量机 (Support Vector Machine)算法既可以用于回归问题,也可以用于分类问题。
支持向量机 (SVM)算法的历史可以追溯到1963年,当时前苏联统计学家弗拉基米尔·瓦普尼克(Vladimir N. Vapnik)和他的同事阿列克谢·切尔沃宁基斯(Alexey Ya. Chervonenkis)提出了支持向量机的概念。然而,由于当时的国际环境影响,他们用俄文发表的论文并没有受到国际学术界的关注。
直到20世纪90年代,瓦普尼克移民到美国,随后发表了SVM理论。
在此之后,SVM算法开始受到应有的重视。在1993年和1995年,Corinna Cortes和瓦普尼克提出了SVM的软间隔分类器,并对其进行了详细的研究和改进。随着机器学习领域的快速发展,SVM逐渐成为一种流行的监督学习算法,被广泛应用于分类 和回归问题。
一般来说,支持向量机用于分类问题时,会简称 SVC;用于回归问题时,会简称SVR。
1. 概述
支持向量机回归 (Support Vector Machine Regression,简称SVR)的基本思想是通过构建一个分类器,将输入数据映射到高维空间中,使得数据在高维空间中更加线性可分,从而得到一个最优的回归模型。
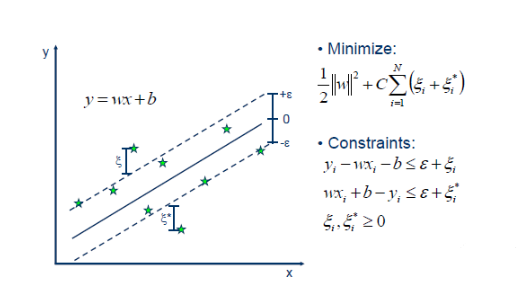
如上图所示,SVR的包括:
- 模型函数:f(x)=wTx+bf(x)=wTx+b
- 模型上下边缘分别为:wT+x+b+ϵwT+x+b+ϵ和 wT+x+b−ϵwT+x+b−ϵ
2. 创建样本数据
这次的回归样本数据,我们用 scikit-learn 自带的玩具数据集中的糖尿病数据集 。
关于玩具数据集的内容,可以参考:TODO
from sklearn.datasets import load_diabetes
# 糖尿病数据集
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target这个数据集中大约有400多条数据。
3. 模型训练
训练之前,为了减少算法误差,先对数据进行标准化处理。
from sklearn import preprocessing as pp
# 数据标准化
X = pp.scale(X)
y = pp.scale(y)接下来分割训练集 和测试集。
from sklearn.model_selection import train_test_split
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)然后用scikit-learn中的SVR模型来训练:
from sklearn.svm import SVR
# 定义支持向量机回归模型
reg = SVR(kernel='linear')
# 训练模型
reg.fit(X_train, y_train)SVR的主要参数包括:
- kernel :核函数类型,可以选择线性('
linear')、多项式('poly')、径向基('rbf')、sigmoid('sigmoid')等。 - degree :多项式核函数的度,仅当
kernel='poly'时有效。 - C:惩罚参数,控制对超出间隔的样本的惩罚力度。C值越大,对超出间隔的样本的惩罚力度越大;C值越小,模型越有可能出现过度拟合。
- epsilon :定义间隔的容忍度,
epsilon越大,间隔越大。 - gamma :定义了核函数的系数,
gamma越大,核函数的形状越窄,对数据的影响越小。 - tol :定义了优化算法的容忍度,
tol越大,算法越容易接受较差的解。 - max_iter:定义了优化算法的最大迭代次数。
最后验证模型的训练效果:
from sklearn import metrics
# 在测试集上进行预测
y_pred = reg.predict(X_test)
mse, r2, m_error = 0.0, 0.0, 0.0
y_pred = reg.predict(X_test)
mse = metrics.mean_squared_error(y_test, y_pred)
r2 = metrics.r2_score(y_test, y_pred)
m_error = metrics.median_absolute_error(y_test, y_pred)
print("均方误差:{}".format(mse))
print("复相关系数:{}".format(r2))
print("中位数绝对误差:{}".format(m_error))
# 运行结果
均方误差:0.6235345942607318
复相关系数:0.3106068096398569
中位数绝对误差:0.5861766809598691从预测的误差 来看,训练的效果还不错。
4. 总结
SVR算法的应用场景非常广泛,包括时间序列预测、金融市场分析、自然语言处理、图像识别等领域。
例如,在时间序列预测 中,SVR算法可以用于预测股票价格、房价等连续变量的未来值。
在金融市场分析 中,SVR算法可以用于预测股票指数的走势,帮助投资者做出更加明智的投资决策。
在自然语言处理 中,SVR算法可以用于文本分类和情感分析等任务。
在图像识别中,SVM回归算法可以用于图像分割和目标检测等任务。
总之,SVR算法是一种非常有效的机器学习算法,可以用于解决各种回归问题。
它的优点包括泛化能力强 、能够处理非线性问题 、对数据规模和分布不敏感 等。
然而,它的计算复杂度较高,需要使用高效的优化算法进行求解,同时也需要仔细地选择合适的参数以避免过拟合和欠拟合等问题。
