文章目录
- [0 相关资料](#0 相关资料)
- [1 源码安装](#1 源码安装)
- [2 Qwen2.5-0.5B-Instruct 模型下载](#2 Qwen2.5-0.5B-Instruct 模型下载)
- [3 训练demo](#3 训练demo)
- [4 在多个 GPU/节点上进行训练](#4 在多个 GPU/节点上进行训练)
- 总结
0 相关资料
https://github.com/huggingface/trl
https://blog.csdn.net/weixin_42486623/article/details/134326187
TRL 是一个先进的库,专为训练后基础模型而设计,采用了监督微调 (SFT)、近端策略优化 (PPO) 和直接偏好优化 (DPO) 等先进技术。TRL 建立在 🤗 Transformers 生态系统之上,支持多种模型架构和模态,并可在各种硬件配置上进行扩展。
b站视频:https://www.bilibili.com/video/BV18ndfYfEcz/
PyTorch / 2.3.0 / 3.12(ubuntu22.04) / 12.1

1 源码安装
source /etc/network_turbo
git clone https://github.com/huggingface/trl.git
cd trl/
pip install -e .
source /etc/network_turbo
pip install trl transformers datasets accelerate2 Qwen2.5-0.5B-Instruct 模型下载
https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
bash
source /etc/network_turbo
pip install modelscope采用SDK方式下载
bash
from modelscope import snapshot_download
# 指定模型的下载路径
cache_dir = '/root/'
# 调用 snapshot_download 函数下载模型
model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct', cache_dir=cache_dir)
print(f"模型已下载到: {model_dir}")3 训练demo
执行脚本前,输入:
source /etc/network_turbo
from trl import SFTTrainer
from datasets import load_dataset
dataset = load_dataset("trl-lib/Capybara", split="train")
trainer = SFTTrainer(
model="/root/Qwen/Qwen2.5-0.5B-Instruct",
train_dataset=dataset,
)
trainer.train()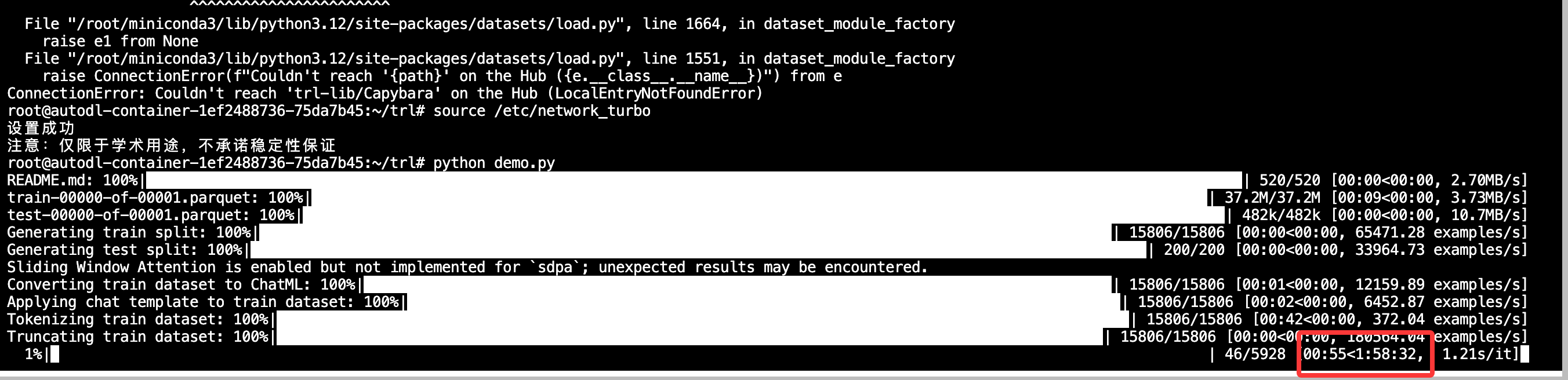
00:15<1:57:58,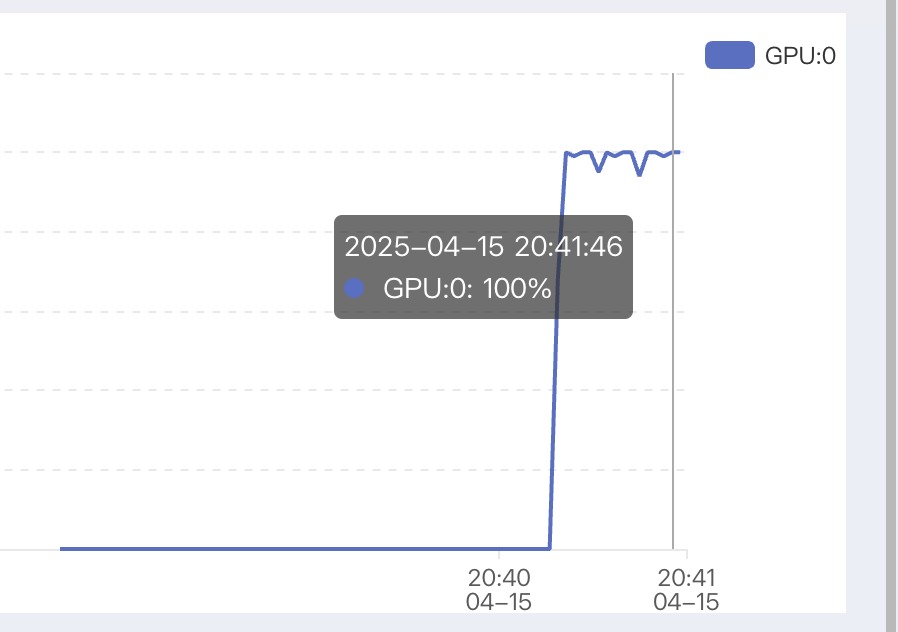
4 在多个 GPU/节点上进行训练
执行脚本前,输入:
source /etc/network_turbo
bash
accelerate launch --config_file=examples/accelerate_configs/multi_gpu.yaml --num_processes 2 demo.py --all_arguments_of_the_script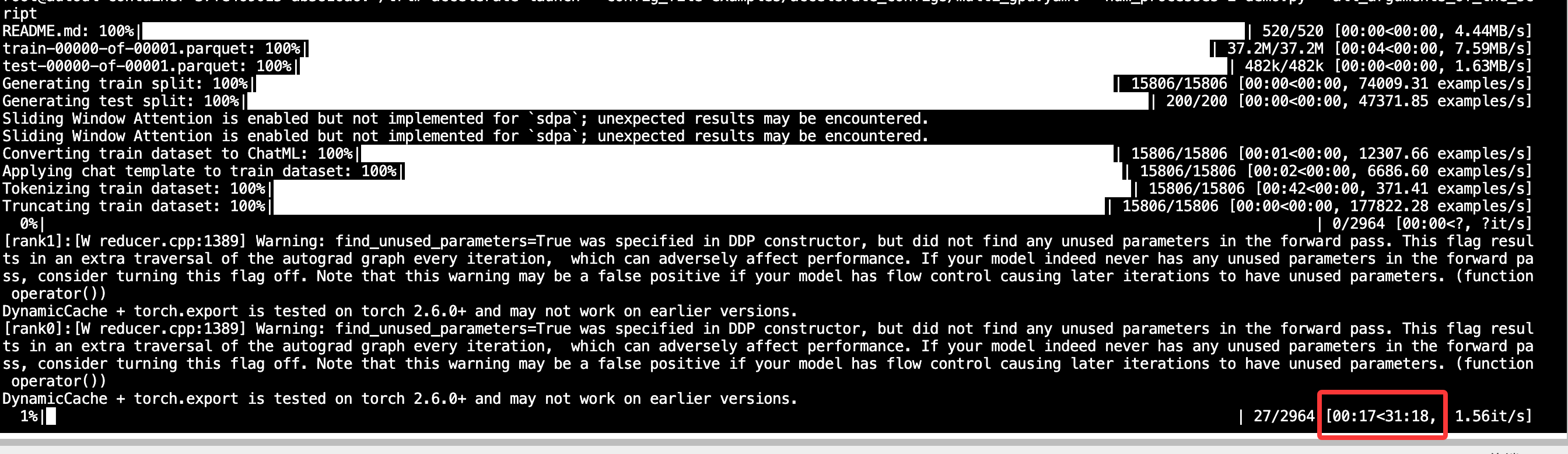
总结
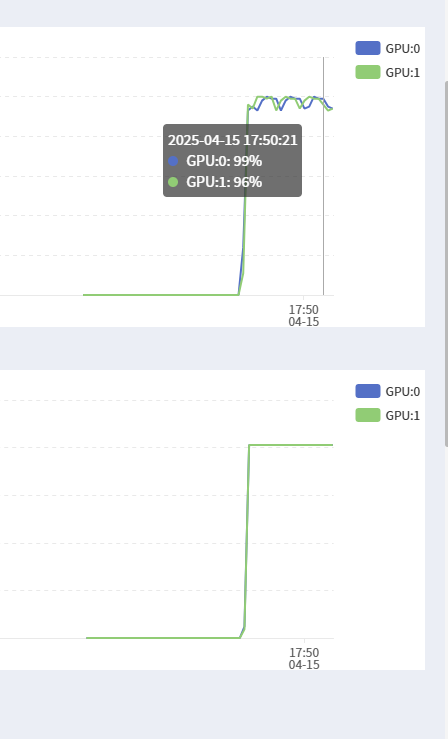
一块L20 GPU 48G,需要2小时
两块L20 GPU 48G,需要0.5小时
速度提升明显