文章目录
- 每日一句正能量
- [第4章 Spark SQL结构化数据文件处理](#第4章 Spark SQL结构化数据文件处理)
- 章节概要
-
- [4.5 Spark SQL操作数据源](#4.5 Spark SQL操作数据源)
-
- [4.5.1 Spark SQL操作MySQL](#4.5.1 Spark SQL操作MySQL)
- [4.5.2 操作Hive数据集](#4.5.2 操作Hive数据集)

每日一句正能量
努力学习,勤奋工作,让青春更加光彩。
第4章 Spark SQL结构化数据文件处理
章节概要
在很多情况下,开发工程师并不了解Scala语言,也不了解Spark常用API,但又非常想要使用Spark框架提供的强大的数据分析能力。Spark的开发工程师们考虑到了这个问题,利用SQL语言的语法简洁、学习门槛低以及在编程语言普及程度和流行程度高等诸多优势,从而开发了Spark SQL模块,通过Spark SQL,开发人员能够通过使用SQL语句,实现对结构化数据的处理。本章将针对Spark SQL的基本原理、使用方式进行详细讲解。
4.5 Spark SQL操作数据源
Spark SQL可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame进行一系列的操作后,还可以将数据重新写入到关系型数据中。关于Spark SQL对MySQL数据库的相关操作具体如下。
4.5.1 Spark SQL操作MySQL
- 读取MysQL数据库
通过SQLyog工具远程连接hadoop01节点的MySQL服务(这里选择的是SQLyog,用其它的工具也是一样的),并利用可视化操作界面创建名称为"spark"的数据库,并创建名称为"person"的数据表,以及向表中添加数据。
同样也可以在hadoop01节点上使用MySQL客户端创建数据库、数据表以及插入数据,具体命令如下。
- 启动mysql客户端
mysql -u root -p #屏幕提示输入密码
结果如下图所示
- 创建spark数据库
mysql > CREATE database spark ;
结果如下图所示

- 创建person数据表
mysql > CREATE TABLE person (id INT(4) , NAME CHAR(20) , age INT(4));
结果如下图所示

- 插入数据
sql
mysql > INSERT INTO person VALUE( 1 , ' zhangsan' , 18);
mysql > INSERT INTO person VALUE(2, ' lisi ' ,20);
mysql > SELECT * FROM person;结果如下图所示

数据库和数据表创建成功后,如果想通过Spark SQL API方式访问MySQL数据库,需要在pom.xml配置文件中添加MySQL驱动连接包,依赖参数如下。
xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version> 8.0.30 </version>
</ dependency>当所需依赖添加完毕后,就可以编写代码读取MySQL数据库中的数据,具体代码如文件所示:
SparkSqlToMysql.scala
scala
package cn.itcast.sql
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
//需要MySQL连接驱动包
object DataFromMysql {
def main(args: Array[String]): Unit = {
//1、创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("DataFromMysql")
.master("local[2]")
.getOrCreate()
//2、创建Properties对象,设置连接mysql的用户名和密码
val properties: Properties =new Properties()
properties.setProperty("user","root")
properties.setProperty("password","12345678")
//读取mysql中的数据
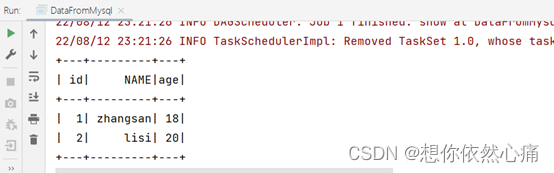
val mysqlDF : DataFrame = spark.read.jdbc("jdbc:mysql://192.168.121.128:3306/spark?useSSL=false","person",properties)
var str = ""
mysqlDF.collect().foreach(rdd => {
str = str+rdd.get(0).toString+":"+rdd.get(1).toString
val id = rdd
})
print(str)
mysqlDF.show()
spark.stop()
}
}运行结果如下图所示
- 向MySQL数据库写入数据
Spark SQL不仅能够查询MySQL数据库中的数据,还可以向表中插入新的数据,实现方式的具体代码如文件所示。
SparkSgIToMysql.scala
scala
package cn.itcast.sql
import java.util.Properties
import org.apache.calcite.avatica.ColumnMetaData.StructType
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StructField}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object SparkSqlToMysql01 {
def main(args: Array[String]): Unit = {
//1.创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlToMysql")
.master("local[2]")
.getOrCreate()
//2.读取数据
//val data: RDD[String] = spark.sparkContext.textFile("D://spark//student.txt")
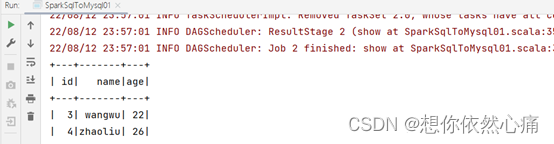
val data: RDD[String] = spark.sparkContext.parallelize(Array("3,wangwu,22","4,zhaoliu,26"))
//3.切分每一行,
val arrRDD: RDD[Array[String]] = data.map(_.split(","))
//4.RDD关联Student
val personRDD: RDD[Student] = arrRDD.map(x=>Student(x(0).toInt,x(1),x(2).toInt))
//导入隐式转换
import spark.implicits._
//5.将RDD转换成DataFrame
val personDF: DataFrame = personRDD.toDF()
//6.创建Properties对象,配置连接mysql的用户名和密码
val prop =new Properties()
prop.setProperty("user","root")
prop.setProperty("password","12345678")
prop.setProperty("driver","com.mysql.jdbc.Driver")
personDF.write.mode("append").jdbc("jdbc:mysql://192.168.121.128:3306/spark?useUnicode=true&characterEncoding=utf8","spark.person",prop)
personDF.show()
spark.stop()
}
}运行结果如下图所示
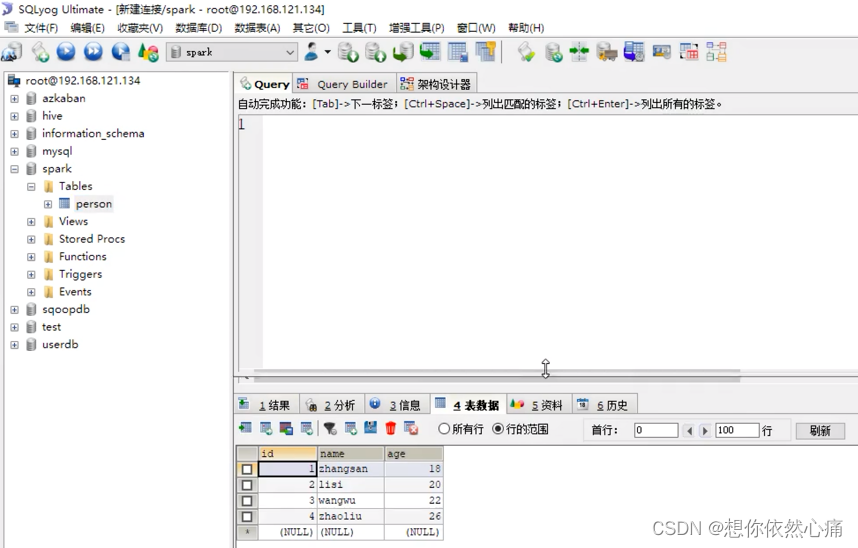
查看mysql中的数据表
4.5.2 操作Hive数据集
Apache Hive是Hadoop上的SQL引擎,也是大数据系统中重要的数据仓库工具,Spark SQL支持访问Hive数据仓库,然后在Spark引擎中进行统计分析。接下来介绍通过Spark SQL操作Hive数据仓库的具体实现步骤。
- 准备环境
Hive采用MySQL数据库存放Hive元数据,因此为了能够让Spark访问Hive,就需要将MySQL驱动包拷贝到Spark安装路径下的jars目录下,具体命令如下。
shell
cp mysql-connector-java-5.1.32.jar /export/servers/spark/jars/结果如下图所示


要将Spark SQL连接到一个部署好的Hive时,就必须要把hive-site.xml配置文件复制到Spark的配置文件目录中,这里采用软连接方式,具体命令如下。
ln -s /export/servers/apache-hive-1.2.1-bin/conf/hive-site.xml \ /export/servers/spark/conf/hive-site.xml
结果如下图所示

- 在Hive中创建数据库和表
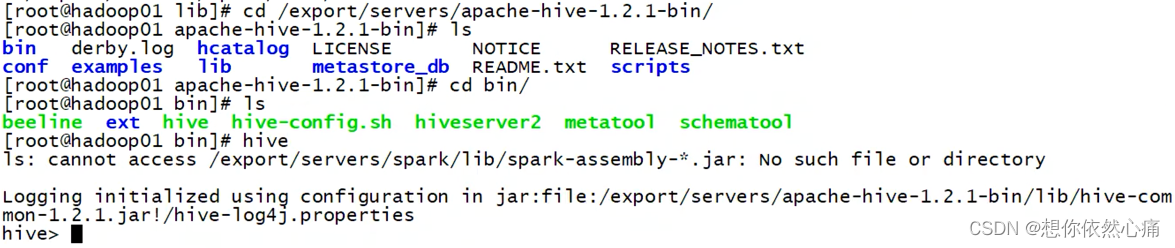
接下来,我们首先在hadoop01节点上启动Hive服务,创建数据库和表,具体命令如下所示。
启动hive程序
hive
hive结果如下图所示
创建数据仓库
sql
create database sparksqltest;结果如下图所示

创建数据表
sql
create table if not exists sparksqltest.person(id int,name string,age int);结果如下图所示

切换数据库
sql
use sparksqltest;结果如下图所示
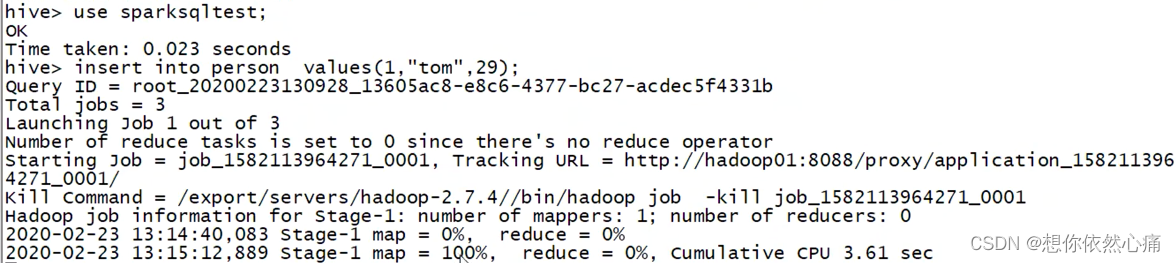
向数据表中添加数据
sql
insert into person values(1, "tom",29);
insert into person values(2, "jerry",20);结果如下图所示
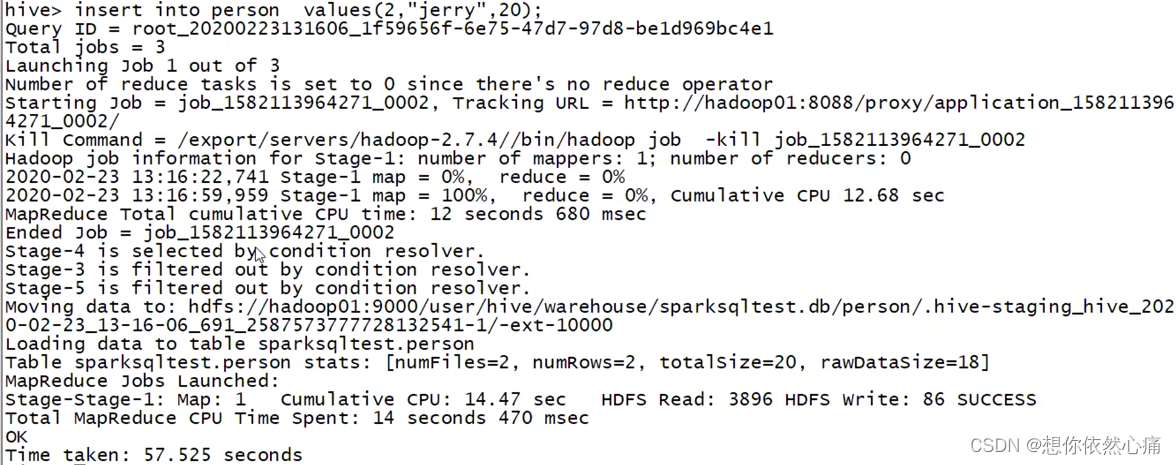
目前,我们创建成功了person数据表,并在该表中插入了两条数据,下面克隆hadoop01会话窗口,执行Spark-Shell。
- Spark SQL操作Hive数据库
执行Spark-Shell,首先进入sparksqltest数据仓库,查看当前数据仓库中是否存在person表,具体代码如下所示。
shell
spark-shell --master spark://hadoop01:7077
spark.sql("use sparksqltest")
spark.sql("show tables").show;结果如下图所示
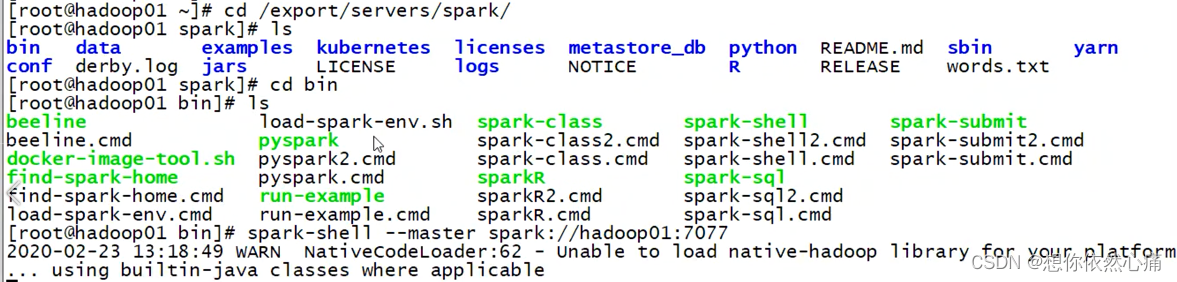
如果spark没有启动的话,需要启动一下
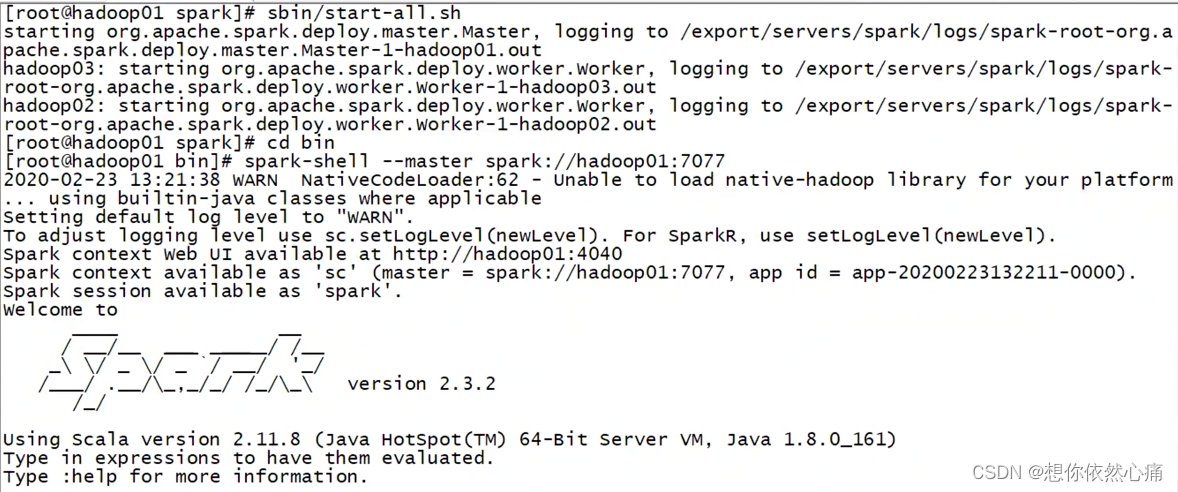
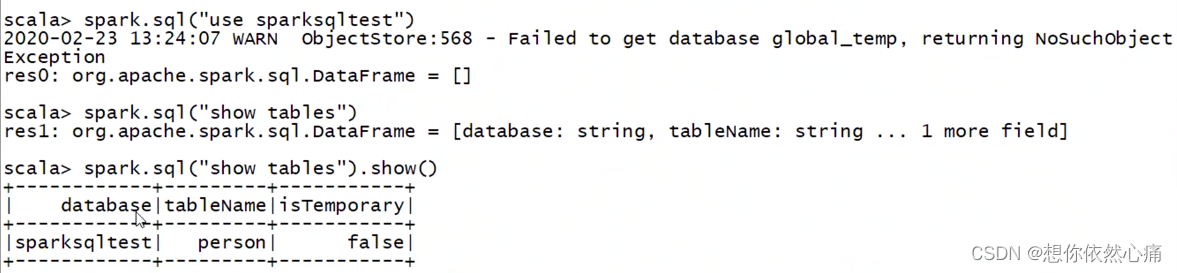
show()方法后面的()因为没有参数,是可以去掉的

从上述返回结果看出,当前Spark-Shell成功显示出Hive数据仓库中的person表。
- 向Hive表写入数据
在插入数据之前,首先查看当前表中数据,具体代码如下所示。
sql
spark.sql("select * from person").show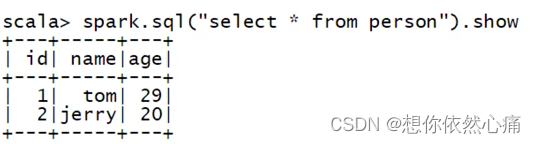
从上述返回结果看出,当前person表中仅有两条数据信息。
下面在Spark-Shell中编写代码,添加两条数据到person表中,代码具体如下所示。
scala
import java.util.Proerties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
#创建数据
val personRDD = spark.sparkContest.parallelize(Array("3 zhangsan 22", "4 lisi 29")).map(_.split(" "))
#设置personRDD的Schema
val schema = StructType(List(StructField("id", IntegerType, true), StructField("name", StringType,true),StructField("age", IntegerType,true)))
#创建Row对象,每个Row对象都是rowRDD中的一行
val rowRDD = personRdd.map(p=>Row(p(0).toInt, p(1).trim, p(2).toInt))
#建立rowRDD与Schema对应关系,创建DataFrame
val personDF = spark.createDataFrame(rowRDD,schema)
#注册临时表
personDF.registerTempTable("t_person")
#将数据插入Hive表
spark.sql("insert into person select * from t_person")
#查询表数据
spark.sql("select * from person").show

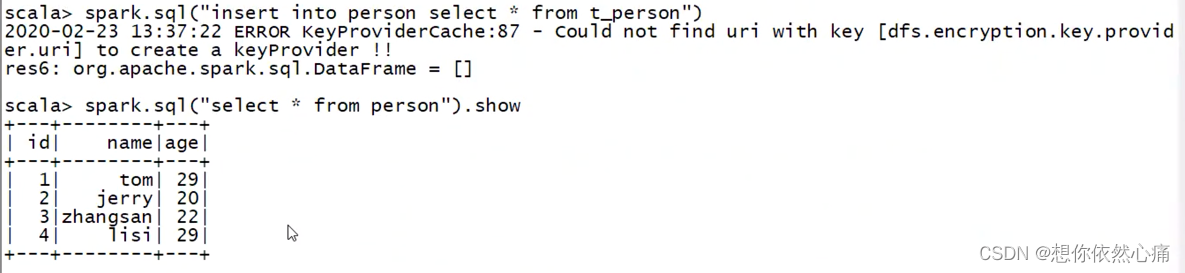
转载自:https://blog.csdn.net/u014727709/article/details/132515279
欢迎 👍点赞✍评论⭐收藏,欢迎指正