数据加载与保存:
通用方式:
SparkSQL 提供了通用的保存数据和数据加载的方式。
加载数据:
spark.read.load 是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定。
spark.read.format("...").option("...").load("...")
我们前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,其实,我们也可以直接在文件上进行查询: 文件格式.`文件路径`
spark.sql("select * from json.' Spark-SQL/input/user.json'").show
保存数据:
df.write.save 是保存数据的通用方法。如果保存不同格式的数据,可以对不同的数据格式进行设定。
df.write.format("...").option("...").save("...")
保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式
存储格式。数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format。修改配置项 spark.sql.sources.default,可修改默认数据源格式。
JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 DatasetRow. 可以
通过 SparkSession.read.json()去加载 JSON 文件。注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串
CSV
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为
数据列。
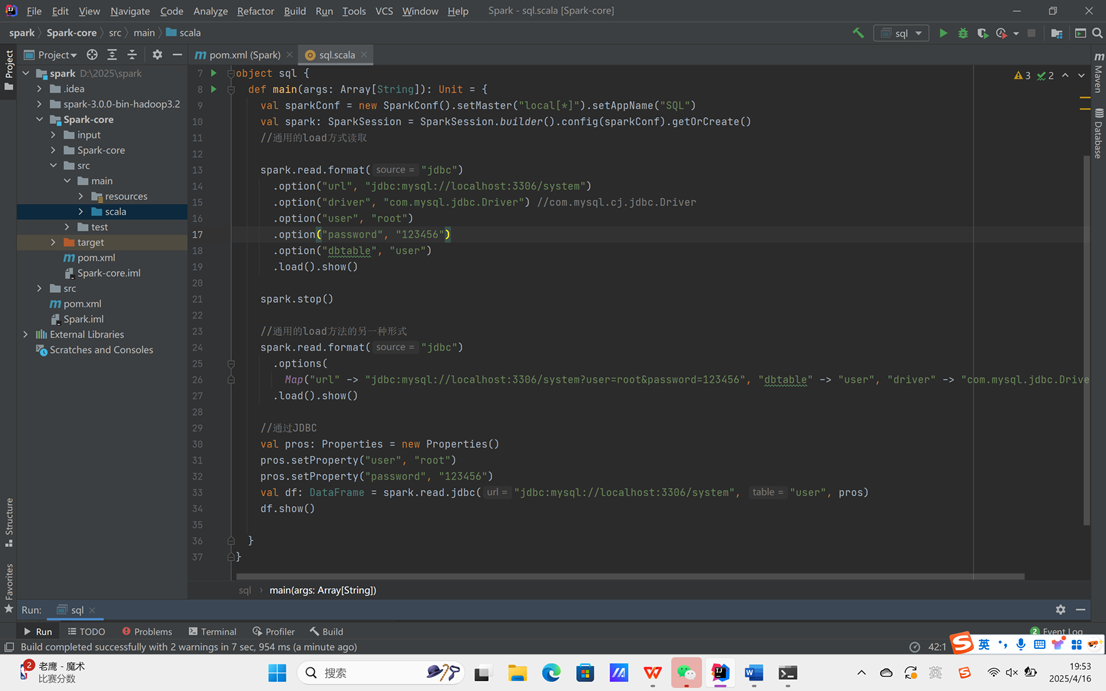
MySQL
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对
DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。
IDEA通过JDBC对MySQL进行操作:
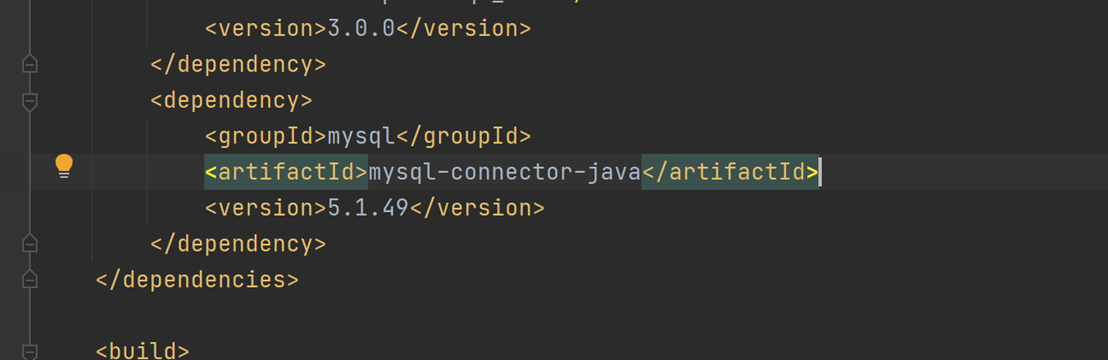
- 导入依赖
- 读取数据
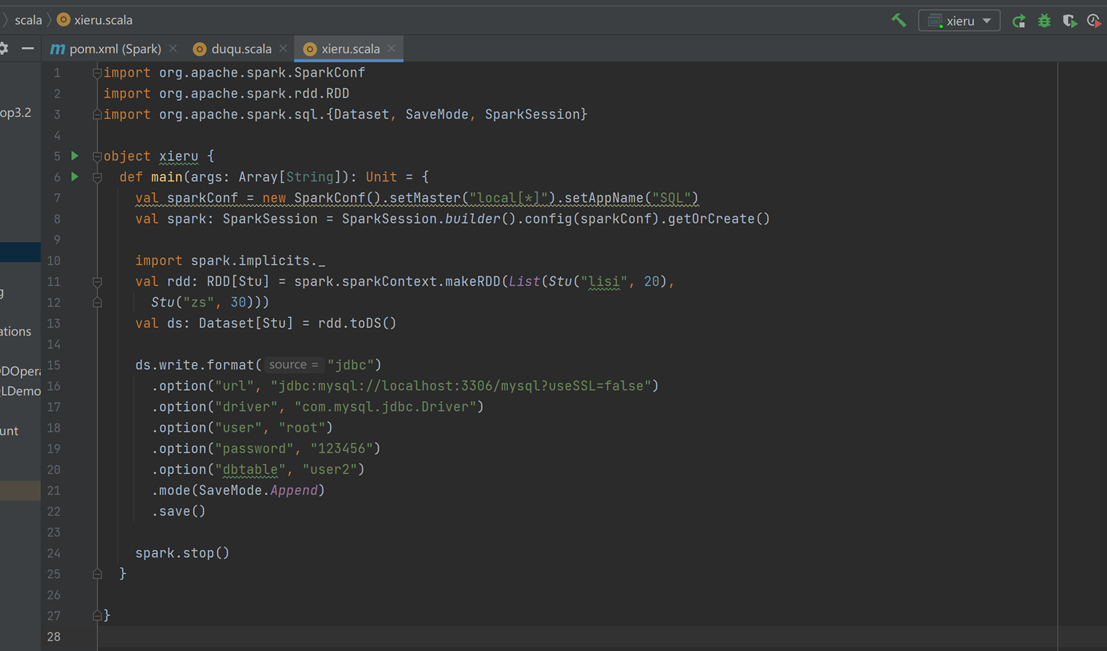
3写入数据
Spark-SQL连接Hive
Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)、Hive 查询语言(HQL)等。需要强调的一点是,如果要在 Spark SQL 中包含Hive 的库,并不需要事先安装 Hive。一般来说,最好还是在编译 Spark SQL 时引入 Hive支持,这样就可以使用这些特性了。
使用方式分为内嵌Hive、外部Hive、Spark-SQL CLI、Spark beeline 以及代码操作。
内嵌的 HIVE
如果使用 Spark 内嵌的 Hive, 则什么都不用做, 直接使用即可。但是在实际生产活动当中,几乎没有人去使用内嵌Hive这一模式。、
运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
- 将mysql的驱动放入jars/当中;
- 将hive-site.xml文件放入conf/当中;
- 运行bin/目录下的spark-sql.cmd 或者打开cmd,在
D:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql
可以直接运行SQL语句,如下所示:
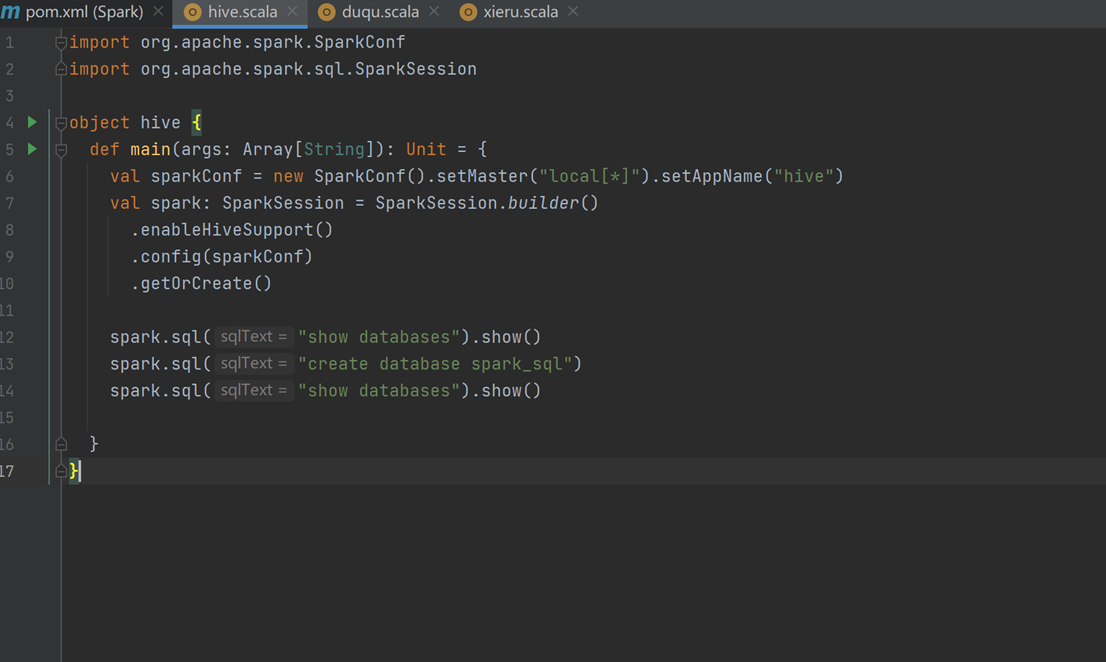
5)代码操作Hive
- 导入依赖。
可能出现下载jar包的问题:
- 代码实现。