注意:该项目只展示部分功能,如需了解,文末咨询即可。
本文目录
- [1 开发环境](#1 开发环境)
- [2 系统设计](#2 系统设计)
- [3 系统展示](#3 系统展示)
- [3.1 功能展示视频](#3.1 功能展示视频)
- [3.2 大屏页面](#3.2 大屏页面)
- [3.3 分析页面](#3.3 分析页面)
- [4 更多推荐](#4 更多推荐)
- [5 部分功能代码](#5 部分功能代码)
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着数字阅读产业蓬勃发展,网络文学平台积累了海量作品数据,但传统分析手段难以挖掘其深层价值。起点小说网作为国内头部文学平台,其内容生态、作者行为与用户偏好数据蕴含丰富的商业洞察,却面临着数据规模庞大、维度复杂、实时性要求高等挑战。本项目针对单一数据集15个核心字段,构建基于Python、Spark、Hadoop、Vue、Echarts与MySQL的端到端大数据分析系统,旨在通过分布式计算架构处理千万级数据,实现从原始文本清洗到多维可视化呈现的完整链路。系统通过量化分析小说类别分布、作者创作能力、作品热度质量等六大维度,不仅为平台优化内容策略、作者扶持机制、商业化变现提供数据支撑,也为读者提供选书决策参考,推动网络文学产业从经验驱动向数据驱动转型,释放大数据在内容创作与运营中的战略价值。
基于Spark的起点小说网大数据可视化分析系统
功能模块设计
紧扣数据特征与业务诉求,构建六大分析体系:
1)小说类别分布分析
模块涵盖大类别统计、子类别热度排行、类别质量对比、完结率与VIP占比分析,利用二级分类体系识别爆款赛道;
2)作者创作能力分析
模块聚焦作者产量、平均质量、跨类别创作与签约率,通过重复值挖掘高产优质作者,构建作者价值评估模型;
3)小说热度与质量分析
模块解析推荐数分布、字数相关性、周推荐占比及VIP作品质量对比,量化动态关系,区分经典长尾与新兴热门;
4)内容文本特征分析
模块研究标题长度、简介长度分布,并执行关键词提取与情感分析,探索文本特征与推荐数的关联;
5)平台商业化分析
模块评估VIP占比趋势、签约作品质量差异及类别商业化潜力,识别高商业价值作品与免费转VIP潜力股;
6)用户偏好与趋势分析
模块捕捉热门类别变迁、用户阅读偏好长度及连载关注度,通过周推荐数波动洞察市场趋势。各模块输出独立的CSV结果文件,支撑可视化看板实现下钻分析与交叉验证,确保每个功能点均具备明确的业务含义与论文撰写价值。
3 系统展示
3.1 功能展示视频
基于Hadoop+Spark的起点小说网大数据可视化分析系统 !!!请点击这里查看功能演示!!!
3.2 大屏页面
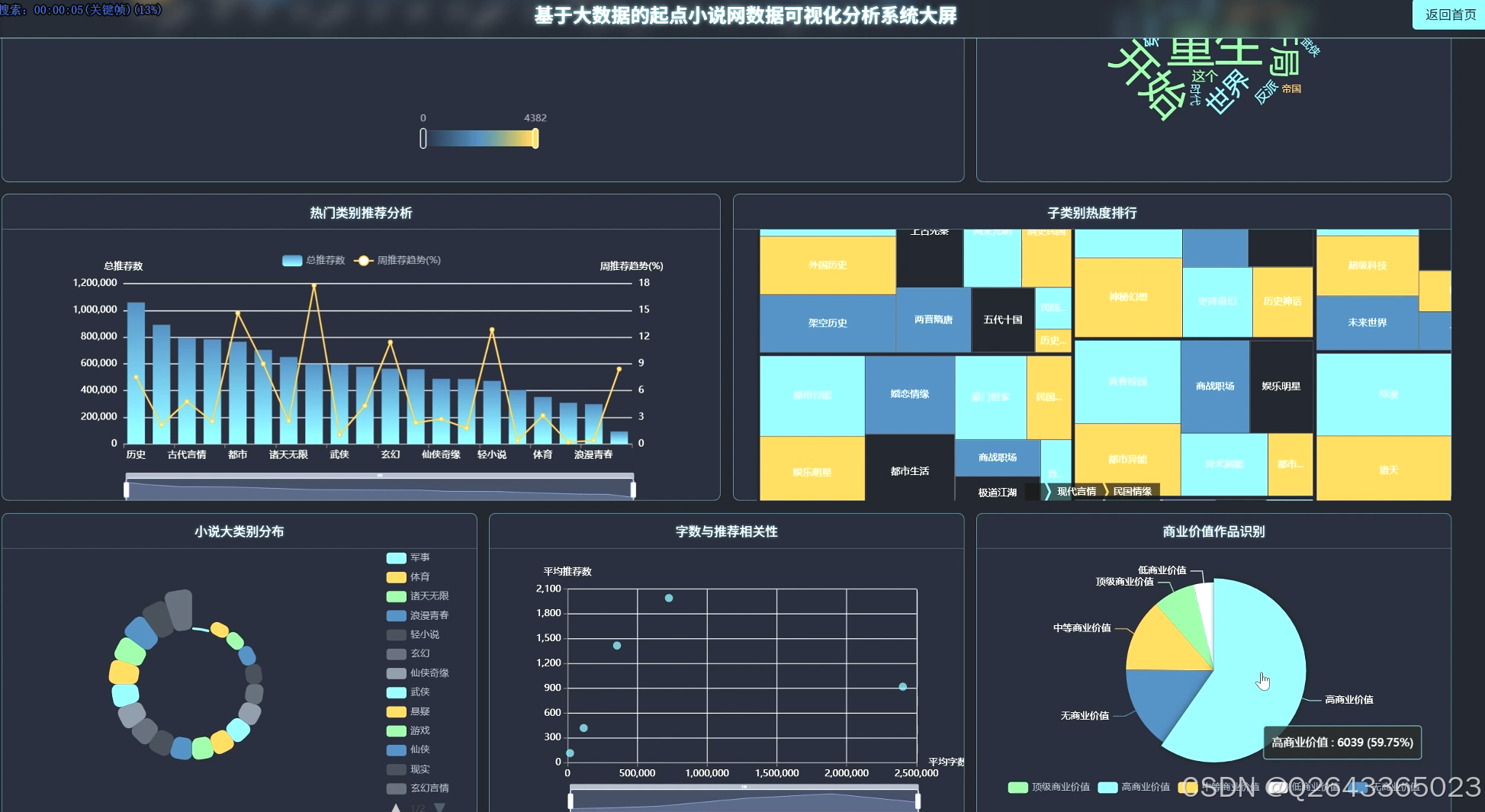
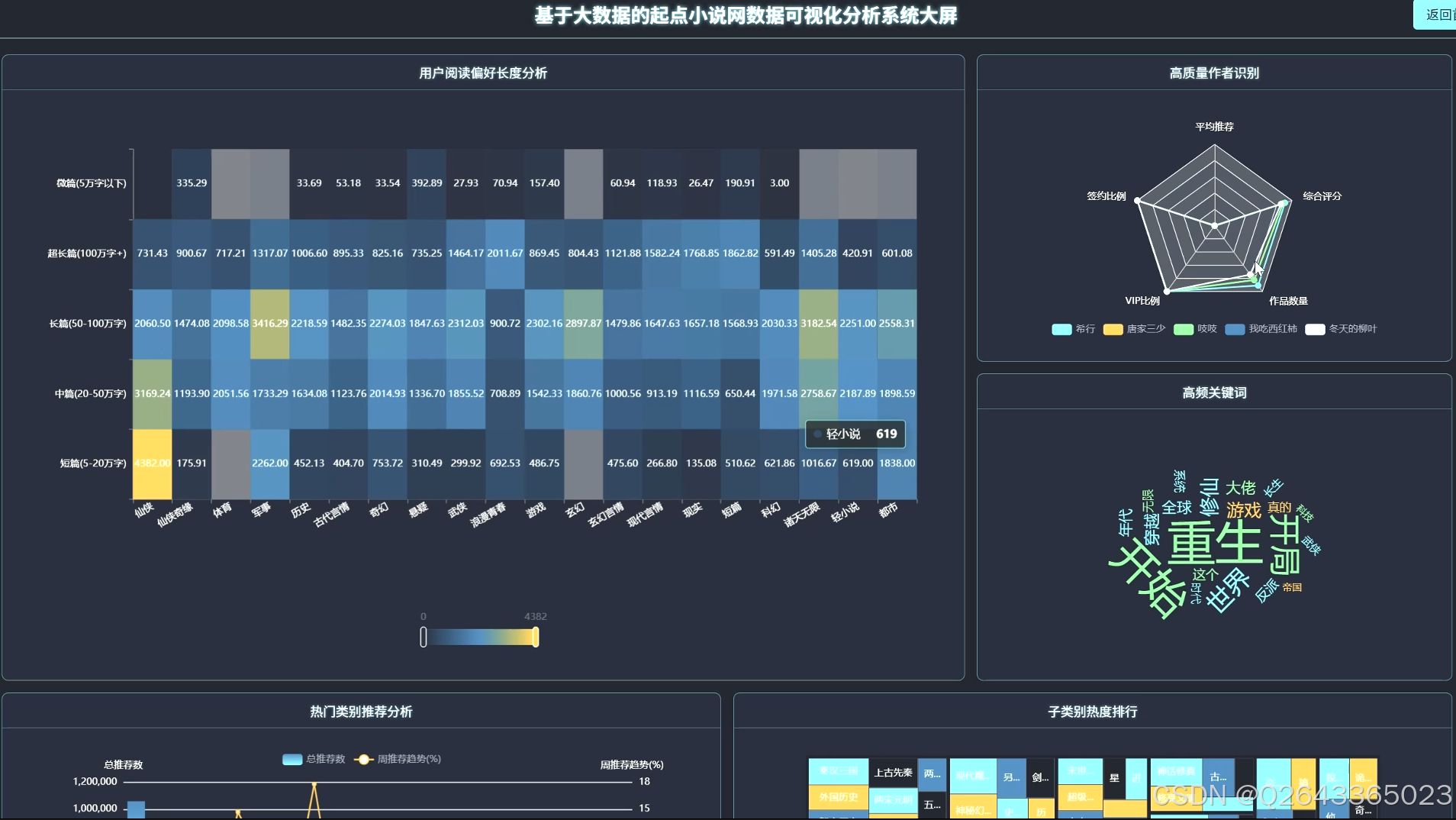
3.3 分析页面


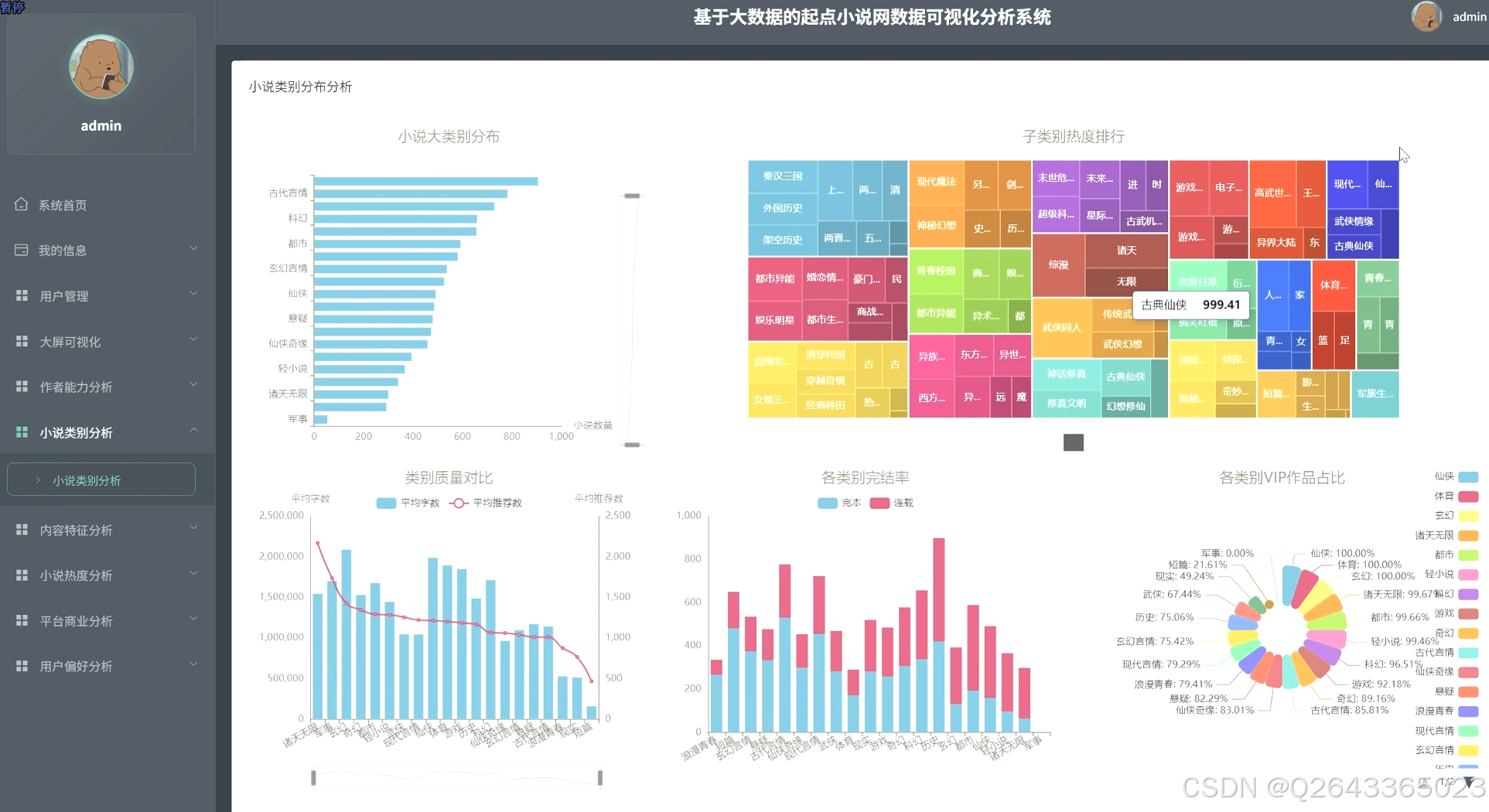
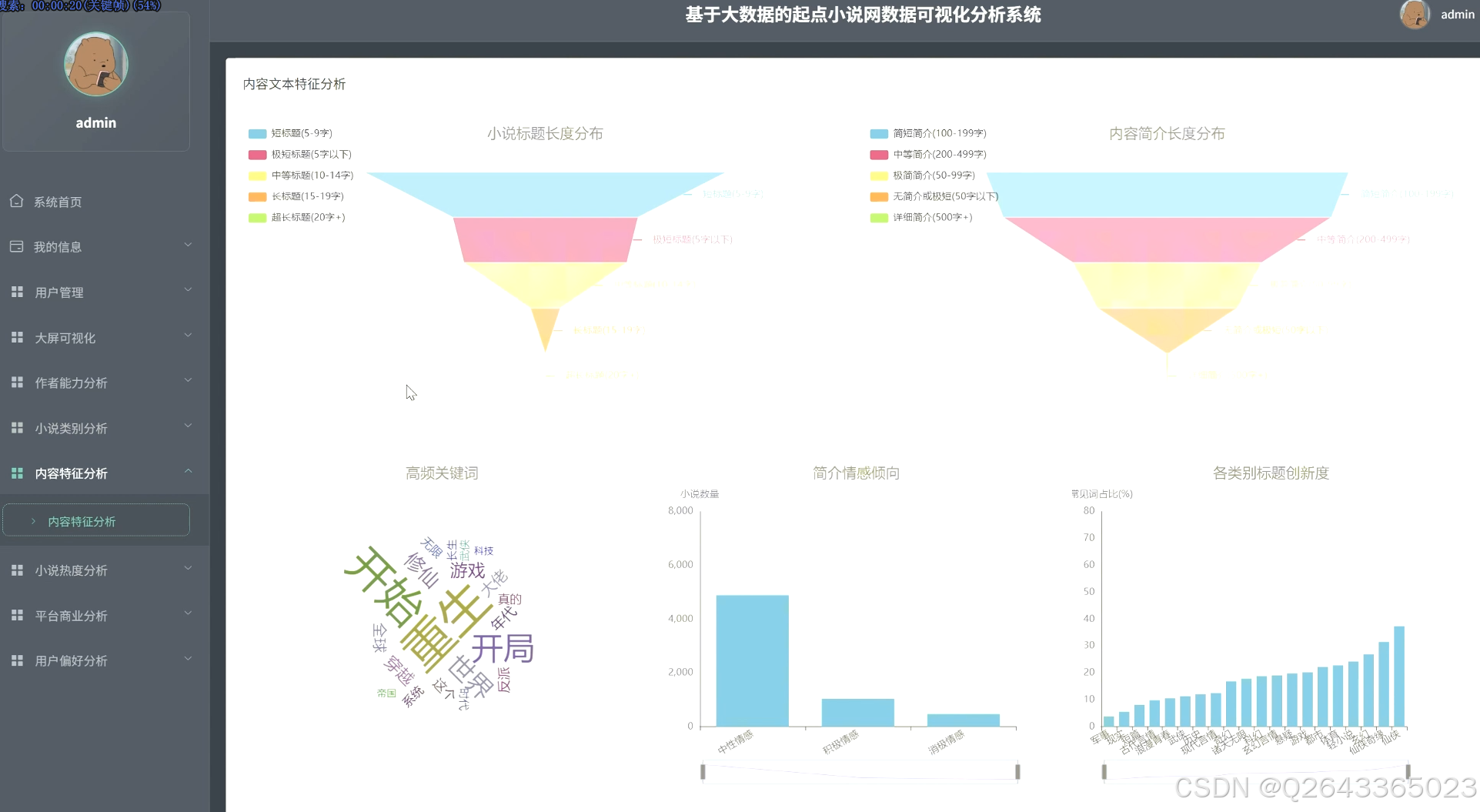
4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
紧跟风口!2026计算机毕设新赛道:精选三大热门领域下的创新选题, 拒绝平庸!毕设技术亮点+功能创新,双管齐下
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
5 部分功能代码
python
def preprocess_data_analysis():
"""
数据预处理核心函数
1. 从HDFS加载bookInfo.csv数据
2. 处理count字段的"万"单位转换为数值
3. 清洗空值和异常数据
4. 将处理结果保存至HDFS标准目录
"""
# 从项目dataset目录读取原始数据,使用绝对路径
raw_df = spark.read.csv(
"file:///absolute/path/to/project/dataset/bookInfo.csv",
header=True,
inferSchema=True,
encoding="utf-8"
)
# UDF:将字数字符串(如"62.97万")转换为整型(629700)
def convert_count(count_str):
if not count_str or count_str == "未知":
return 0
match = re.match(r"(\d+\.?\d*)万", str(count_str))
if match:
return int(float(match.group(1)) * 10000)
return 0
convert_count_udf = udf(convert_count, IntegerType())
# 数据清洗与转换
processed_df = raw_df \
.withColumn("word_count", convert_count_udf(col("count"))) \
.withColumn("total_recommend", when(col("total_recommend").isNull(), 0)
.otherwise(col("total_recommend").cast(IntegerType()))) \
.withColumn("total_week_recommend", when(col("total_week_recommend").isNull(), 0)
.otherwise(col("total_week_recommend").cast(IntegerType()))) \
.withColumn("is_vip", when(col("is_vip").isNull(), "未知").otherwise(col("is_vip"))) \
.withColumn("is_lianzai", when(col("is_lianzai").isNull(), "未知").otherwise(col("is_lianzai"))) \
.filter(col("word_count") > 0) \
.filter(col("total_recommend") >= 0)
# 写入HDFS标准目录(先删除旧目录避免冲突)
hdfs_path = "hdfs://namenode:9000/qidian/processed_data"
processed_df.write.mode("overwrite").parquet(hdfs_path)
print(f"预处理完成,数据已写入: {hdfs_path}")
return processed_df
def novel_class_distribution_analysis(df):
"""
小说类别分布分析核心函数
基于class_type字段统计大类别分布,计算平均推荐数、完结率、VIP占比
输出结果用于可视化展示类别结构
"""
result_df = df.groupBy("class_type") \
.agg(
count("*").alias("novel_count"),
round(avg("total_recommend"), 2).alias("avg_recommend"),
round(avg("word_count"), 2).alias("avg_word_count"),
round(count(when(col("is_lianzai") == "完本", True)) / count("*") * 100, 2).alias("completion_rate"),
round(count(when(col("is_vip") == "VIP", True)) / count("*") * 100, 2).alias("vip_ratio")
) \
.orderBy(col("novel_count").desc())
# 转换为Pandas并输出CSV(文件名不含数字)
result_df.toPandas().to_csv("/output/class_distribution_analysis.csv", index=False, encoding="utf-8")
print("类别分布分析完成,结果已保存")
return result_df
def author_creation_ability_analysis(df):
"""
作者创作能力分析核心函数
统计作者产量、平均质量、跨类别创作情况
识别高产优质作者,为平台签约策略提供依据
"""
# 计算每位作者的创作指标
author_metrics_df = df.groupBy("author_name") \
.agg(
count("*").alias("works_count"),
round(avg("total_recommend"), 2).alias("avg_recommend"),
round(avg("word_count"), 2).alias("avg_word_count"),
countDistinct("class_type").alias("cross_class_count"),
round(count(when(col("is_qianyue") == "签约", True)) / count("*") * 100, 2).alias("sign_rate")
) \
.filter(col("works_count") >= 2) \
.orderBy(col("works_count").desc())
author_metrics_df.toPandas().to_csv("/output/author_ability_analysis.csv", index=False, encoding="utf-8")
print("作者能力分析完成,结果已保存")
return author_metrics_df源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓