实战5:Python使用循环神经网络生成诗歌
在我们学习了课程8后,我们在实战练习一个例子。
你的主要任务:学习如何使用简单的循环神经网络(Vanilla RNN)生成诗歌。亚历山大·谢尔盖耶维奇·普希金的诗体小说《叶甫盖尼·奥涅金》将作为训练的文本语料库。
使用依赖
python
# 不要更改下面的代码块!所有必要的import都列在这里
# __________start of block__________
import string
import os
from random import sample
import numpy as np
import torch, torch.nn as nn
import torch.nn.functional as F
from IPython.display import clear_output
import matplotlib.pyplot as plt
%matplotlib inline
# __________end of block__________
python
# 不要更改下面的代码块!
# __________start of block__________
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print('{} device is available'.format(device))
# __________end of block__________加载数据
python
# 不要更改下面块中的代码
# __________start of block__________
!wget https://raw.githubusercontent.com/MSUcourses/Data-Analysis-with-Python/main/Deep%20Learning/onegin_hw07.txt -O ./onegin.txt
with open('onegin.txt', 'r') as iofile:
text = iofile.readlines()
text = "".join([x.replace('\t\t', '').lower() for x in text]) # 删除多余的制表符,将所有字母转换为小写
# __________end of block__________让我们输出输入文本的前几个字符。我们看到制表符已被删除,字母已转换为小写。我们保留 \n 符号,以便教会网络在需要转到新行时生成 \n 符号。
python
text[:36]输出:

词典构建和文本预处理
此任务要求您在符号级别构建语言模型。让我们将所有文本转换为小写,并根据可用文本语料库中的所有字符构建字典。我们还将添加技术令牌<sos>。
python
# 不要更改下面的代码块!
# __________start of block__________
tokens = sorted(set(text.lower())) + ['<sos>'] # 我们构建一个包含所有符号标记的集合,并将服务标记 <sos> 添加到其中
num_tokens = len(tokens)
assert num_tokens == 84, "Check the tokenization process"
token_to_idx = {x: idx for idx, x in enumerate(tokens)} # 构建一个包含 token 键和 token 列表中索引值的字典
idx_to_token = {idx: x for idx, x in enumerate(tokens)} # 构建一个反向字典(这样你就可以通过索引获取一个标记)
assert len(tokens) == len(token_to_idx), "Mapping should be unique"
print("Seems fine!")
text_encoded = [token_to_idx[x] for x in text]
# __________end of block__________输出:Seems fine!
其中:
-
set(text.lower()):将原始文本text中的所有字符提取出来,并转换为小写形式,然后使用set函数去除重复字符,得到一个包含文本中所有不同小写字符的集合。
-
sorted(set(text.lower())):对上述集合进行排序,排序后的结果是一个有序的字符列表。这样做的目的是为了确保每次运行代码时,字符的顺序都是固定的,方便后续建立字符到索引的映射。
-
+ ['<sos>']:在排好序的字符列表末尾添加一个特殊的服务标记,通常表示 "句子起始(Start of Sentence)" 标记,在文本生成任务中用于指示生成文本的起始位置。 -
token_to_idx构建字符到索引的映射字典:使用字典推导式创建一个名为token_to_idx的字典。enumerate(tokens)会同时返回每个字符在tokens列表中的索引idx和字符本身x。字典中的键是字符x,值是对应的索引idx。这个字典用于将字符转换为模型可以处理的数字索引。 -
idx_to_token构建反向映射字典:同样使用字典推导式创建一个反向映射字典idx_to_token。与token_to_idx相反,这个字典的键是索引idx,值是对应的字符x,用于将模型输出的索引转换回实际的字符。 -
text_encoded使用列表推导式将原始文本text中的每个字符根据token_to_idx字典转换为对应的索引,得到一个编码后的文本列表text_encoded。这个编码后的文本列表将用于后续的模型训练和处理。
你的任务:训练一个经典的循环神经网络(Vanilla RNN)来预测给定文本语料库中的下一个字符,并为固定的初始短语生成长度为 100 的序列。
您可以使用课程7中的代码或参考以下链接:
- Andrej Karpathy 撰写的关于使用 RNN 的精彩文章:链接
- Andrej Karpathy 的 Char-rnn 示例:github 存储库
- 生成莎士比亚诗歌的一个很好的例子:github repo
这个任务相当有创意。如果一开始很难也没关系。在这种情况下,上面列表中的最后一个链接可能特别有用。
下面,为了您的方便,实现了一个函数,该函数从长度为"seq_length"的字符串中生成大小为"batch_size"的随机批次。您可以在训练模型时使用它。(随机生成数据批次,每个批次包含 256 个长度为 100 的字符序列,并且在每个序列的开头添加 标记,为模型训练提供数据:
python
# 不要更改下面的代码
# __________start of block__________
batch_size = 256 # 批量大小。批次是一组字符序列。
seq_length = 100 # 一批字符序列的最大长度
start_column = np.zeros((batch_size, 1), dtype=int) + token_to_idx['<sos>'] # 在每行开头添加一个技术符号------确定网络的初始状态
def generate_chunk():
global text_encoded, start_column, batch_size, seq_length
start_index = np.random.randint(0, len(text_encoded) - batch_size*seq_length - 1) # 随机选择批次中起始符号的索引
# 构建一个连续的批次。
# 为此,我们在源文本中选择一个以索引 start_index 开头且大小为 batch_size*seq_length 的子序列。
# 然后我们将这个子序列分成大小为 seq_length 的 batch_size 个序列。这将是批次,大小为batch_size*seq_length的矩阵。
# 矩阵的每一行将包含索引
data = np.array(text_encoded[start_index:start_index + batch_size*seq_length]).reshape((batch_size, -1))
yield np.hstack((start_column, data))
# __________end of block__________其中:
- batch_size:指的是在一次训练迭代中同时处理的样本数量。在文本生成任务里,每个样本是一个字符序列。这里将 batch_size 设定为 256,意味着每次训练时会处理 256 个字符序列。
- seq_length:代表每个字符序列的最大长度。在训练时,会把文本分割成长度为 seq_length 的序列,这里设定为 100,即每个序列包含 100 个字符。
- start_column:这是一个 numpy 数组,形状为 (batch_size, 1)。借助 np.zeros((batch_size, 1), dtype=int) 生成一个全零的数组,再加上 token_to_idx'',让数组的每个元素都变为 标记对应的索引。此数组用于在每个序列的开头添加 标记,以此确定模型的初始状态。
- start_index = np.random.randint(0, len(text_encoded) - batch_size*seq_length - 1):随机选取一个索引 start_index,作为当前批次数据在编码后的文本 text_encoded 中的起始位置。这样做的目的是为了让每次生成的批次数据都不同,增加训练数据的随机性。
- data = np.array(text_encodedstart_index:start_index + batch_size\*seq_length).reshape((batch_size, -1)):从 text_encoded 里选取从 start_index 开始、长度为 batch_size * seq_length 的子序列,将其转换为 numpy 数组,再调整形状为 (batch_size, seq_length) 的矩阵。这个矩阵的每一行就代表一个长度为 seq_length 的字符序列。
- yield np.hstack((start_column, data)):运用 np.hstack 函数把 start_column 和 data 按水平方向拼接起来,在每个序列的开头添加 标记。yield 关键字让这个函数成为一个生成器,每次调用该函数时,会生成一个新的数据批次,而不是一次性生成所有批次数据,这样可以节省内存。
批次示例:
python
next(generate_chunk())输出:

编写网络:
python
# 定义 Vanilla RNN 模型
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(VanillaRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.rnn = nn.RNN(hidden_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
x = self.embedding(x)
out, hidden = self.rnn(x, hidden)
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
return torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)其中:
- input_size(输入特征的数量,即词汇表的大小)、hidden_size(隐藏层的大小,即隐藏状态的维度)、num_layers(RNN 的层数)和 output_size(输出特征的数量,通常也是词汇表的大小)。
构建模型训练和损失函数曲线图:
python
# 超参数设置
input_size = num_tokens
hidden_size = 128
num_layers = 2
output_size = num_tokens
learning_rate = 0.001
num_epochs = 2000 # 这里设置为 10 个 epoch,你可以根据需要调整
# 初始化模型、损失函数和优化器
model = VanillaRNN(input_size, hidden_size, num_layers, output_size).to(device)
criterion = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 用于存储每次迭代损失值的列表
history = []
# 训练循环
for epoch in range(num_epochs):
for i, batch in enumerate(generate_chunk()):
inputs = torch.tensor(batch[:, :-1], dtype=torch.long).to(device)
targets = torch.tensor(batch[:, 1:], dtype=torch.long).to(device)
hidden = model.init_hidden(batch_size)
logits, _ = model(inputs, hidden)
predictions_logp = F.log_softmax(logits, dim=-1)
loss = criterion(
predictions_logp.contiguous().view(-1, num_tokens),
targets.contiguous().view(-1)
)
loss.backward()
opt.step()
opt.zero_grad()
history.append(loss.item())
if (epoch + 1) % 100 == 0:
clear_output(True)
plt.plot(history, label='loss')
plt.legend()
plt.show()输出:
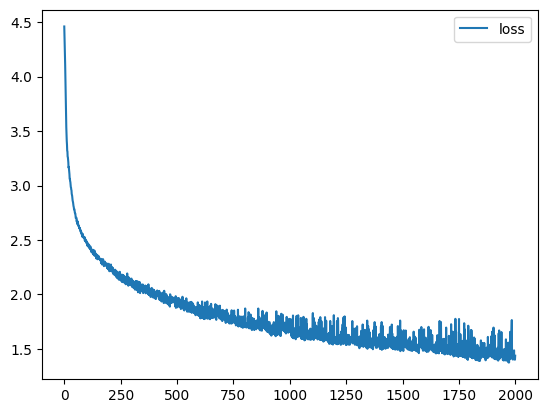
其中:
- inputs = torch.tensor(batch:, :-1, dtype=torch.long).to(device) 和 targets = torch.tensor(batch:, 1:, dtype=torch.long).to(device):将批次数据分为输入和目标。batch:, :-1 取批次数据的前 seq_length - 1 个字符作为输入,batch:, 1: 取批次数据的后 seq_length - 1 个字符作为目标。将它们转换为 torch.Tensor 类型,并移动到指定设备上。
紧接着我们编写文本生成函数,在训练语言模型之后(训练好的神经网络就是语言模型),我们开始进行数据生成。generate_sample 函数通过不断地根据模型的输出进行采样,逐步生成文本,直到达到指定的最大长度:
python
# 生成文本函数
def generate_sample(char_rnn, seed_phrase=None, max_length=200, temperature=1.0, device=device):
'''
The function generates text given a phrase of length at least SEQ_LENGTH.
:param seed_phrase: prefix characters. The RNN is asked to continue the phrase
:param max_length: maximum output length, including seed_phrase
:param temperature: coefficient for sampling. higher temperature produces more chaotic outputs,
smaller temperature converges to the single most likely output
'''
if seed_phrase is not None:
x_sequence = [token_to_idx['<sos>']] + [token_to_idx[token] for token in seed_phrase]
else:
x_sequence = [token_to_idx['<sos>']]
x_sequence = torch.tensor([x_sequence], dtype=torch.int64).to(device)
hidden = char_rnn.init_hidden(1)
# 输入种子短语
for i in range(len(x_sequence[0]) - 1):
_, hidden = char_rnn(x_sequence[:, i].unsqueeze(1), hidden)
# 生成剩余文本
for _ in range(max_length - len(x_sequence[0])):
logits, hidden = char_rnn(x_sequence[:, -1].unsqueeze(1), hidden)
probs = F.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs.view(-1), num_samples=1)
x_sequence = torch.cat([x_sequence, next_token.unsqueeze(0)], dim=1)
return ''.join([tokens[ix] for ix in x_sequence.cpu().data.numpy()[0]])- 参数:
- char_rnn:已经训练好的 RNN 模型,用于生成文本。
- seed_phrase:种子短语,是一个字符串,用于作为生成文本的起始部分。如果为 None,则从 标记开始生成。
- max_length:生成文本的最大长度,包含种子短语的长度,默认值为 200。
- temperature:采样系数,用于控制生成文本的随机性。较高的温度会产生更随机、混乱的输出;较低的温度会使输出更倾向于选择概率最大的字符,默认值为 1.0。
- device:指定运行模型的设备(如 CPU 或 GPU),默认使用之前定义的 device。
- 生成剩余文本:
通过循环不断生成新的字符,直到达到 max_length,在每次循环中:- 将当前序列的最后一个字符输入到 RNN 模型中,得到模型的输出 logits 和更新后的隐藏状态 hidden。
- logits / temperature:通过温度参数 temperature 调整 logits 的值,较高的温度会使概率分布更加均匀,增加随机性;较低的温度会使概率分布更加集中,输出更倾向于概率最大的字符。
- F.softmax(logits / temperature, dim=-1):对调整后的 logits 应用 softmax 函数,将其转换为概率分布 probs。
- torch.multinomial(probs.view(-1), num_samples=1):根据概率分布 probs 进行采样,随机选择一个字符的索引作为下一个字符。
- torch.cat(x_sequence, next_token.unsqueeze(0), dim=1):将采样得到的下一个字符的索引添加到 x_sequence 中。
下面是经过训练的模型生成的文本示例。文本中包含大量不存在的单词并不可怕。所使用的模型非常简单:它是一个简单的经典 RNN。
python
print(generate_sample(model, ' мой дядя самых честных правил', max_length=500, temperature=0.8))输出:

总代码
python
# 不要更改下面的代码块!所有必要的import都列在这里
# __________start of block__________
import string
import os
from random import sample
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from IPython.display import clear_output
import matplotlib.pyplot as plt
%matplotlib inline
# __________end of block__________
# 不要更改下面的代码块!
# __________start of block__________
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print('{} device is available'.format(device))
# __________end of block__________
# 不要更改下面块中的代码
# __________start of block__________
!wget https://raw.githubusercontent.com/MSUcourses/Data-Analysis-with-Python/main/Deep%20Learning/onegin_hw07.txt -O./onegin.txt
with open('onegin.txt', 'r') as iofile:
text = iofile.readlines()
text = "".join([x.replace('\t\t', '').lower() for x in text]) # Убираем лишние символы табуляций, приводим все буквы к нижнему регистру
# __________end of block__________
# 不要更改下面的代码块!
# __________start of block__________
tokens = sorted(set(text.lower())) + ['<sos>'] # 我们构建一个包含所有符号标记的集合,并将服务标记 <sos> 添加到其中
num_tokens = len(tokens)
assert num_tokens == 84, "Check the tokenization process"
token_to_idx = {x: idx for idx, x in enumerate(tokens)} # 构建一个包含 token 键和 token 列表中索引值的字典
idx_to_token = {idx: x for idx, x in enumerate(tokens)} # 构建一个反向字典(这样你就可以通过索引获取一个标记)
assert len(tokens) == len(token_to_idx), "Mapping should be unique"
print("Seems fine!")
text_encoded = [token_to_idx[x] for x in text]
# __________end of block__________
# 不要更改下面的代码
# __________start of block__________
batch_size = 256 # 批量大小。批次是一组字符序列。
seq_length = 100 # 一批字符序列的最大长度
start_column = np.zeros((batch_size, 1), dtype=int) + token_to_idx['<sos>'] # 在每行开头添加一个技术符号------确定网络的初始状态
def generate_chunk():
global text_encoded, start_column, batch_size, seq_length
start_index = np.random.randint(0, len(text_encoded) - batch_size * seq_length - 1) # 随机选择批次中起始符号的索引
# 构建一个连续的批次。
# 为此,我们在源文本中选择一个以索引 start_index 开头且大小为 batch_size*seq_length 的子序列。
# 然后我们将这个子序列分成大小为 seq_length 的 batch_size 个序列。这将是批次,大小为batch_size*seq_length的矩阵。
# 矩阵的每一行将包含索引
data = np.array(text_encoded[start_index:start_index + batch_size * seq_length]).reshape((batch_size, -1))
yield np.hstack((start_column, data))
# __________end of block__________
# 定义 Vanilla RNN 模型
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(VanillaRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.rnn = nn.RNN(hidden_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
x = self.embedding(x)
out, hidden = self.rnn(x, hidden)
out = self.fc(out)
return out, hidden
def init_hidden(self, batch_size):
return torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
# 超参数设置
input_size = num_tokens
hidden_size = 128
num_layers = 2
output_size = num_tokens
learning_rate = 0.001
num_epochs = 2000 # 这里设置为 10 个 epoch,你可以根据需要调整
# 初始化模型、损失函数和优化器
model = VanillaRNN(input_size, hidden_size, num_layers, output_size).to(device)
criterion = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 用于存储每次迭代损失值的列表
history = []
# 训练循环
for epoch in range(num_epochs):
for i, batch in enumerate(generate_chunk()):
inputs = torch.tensor(batch[:, :-1], dtype=torch.long).to(device)
targets = torch.tensor(batch[:, 1:], dtype=torch.long).to(device)
hidden = model.init_hidden(batch_size)
logits, _ = model(inputs, hidden)
predictions_logp = F.log_softmax(logits, dim=-1)
loss = criterion(
predictions_logp.contiguous().view(-1, num_tokens),
targets.contiguous().view(-1)
)
loss.backward()
opt.step()
opt.zero_grad()
history.append(loss.item())
if (epoch + 1) % 100 == 0:
clear_output(True)
plt.plot(history, label='loss')
plt.legend()
plt.show()
# 生成文本函数
def generate_sample(char_rnn, seed_phrase=None, max_length=200, temperature=1.0, device=device):
if seed_phrase is not None:
x_sequence = [token_to_idx['<sos>']] + [token_to_idx[token] for token in seed_phrase]
else:
x_sequence = [token_to_idx['<sos>']]
x_sequence = torch.tensor([x_sequence], dtype=torch.int64).to(device)
hidden = char_rnn.init_hidden(1)
# 输入种子短语
for i in range(len(x_sequence[0]) - 1):
_, hidden = char_rnn(x_sequence[:, i].unsqueeze(1), hidden)
# 生成剩余文本
while len(x_sequence[0]) < max_length:
logits, hidden = char_rnn(x_sequence[:, -1].unsqueeze(1), hidden)
probs = F.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs.view(-1), num_samples=1)
x_sequence = torch.cat([x_sequence, next_token.unsqueeze(0)], dim=1)
# print(f"当前生成的序列长度: {len(x_sequence[0])}")
return ''.join([tokens[ix] for ix in x_sequence.cpu().data.numpy()[0]])
# 添加你提供的测试文本生成
print(generate_sample(model, 'мой дядя самых честных правил', max_length=500, temperature=0.8))