目录
[三. selenium模块](#三. selenium模块)
此章节讲解,如今市面大多数爬虫最后技术,分别:处理cookie、防盗链、代理、线程、进程、协程、异步http请求aiohttp模块、selenium模块。
一.requests进阶
我们在之前的爬虫中其实已经使用过headers了.header为HTTP协议中的请求头,一般存放一些和请求内容无关的数据.有时也会存放一些安全验证信息.比如常见的User-Agent,token,cookie等。
通过requests发送的请求,我们可以把请求头信息放在headers中.也可以单独进行存放,最终由requests自动帮我们拼接成完整的http请求头
本小节内容
1.模拟浏览器登录->处理cookie
2.防盗链处理->抓取梨视频数据
3.代理 ->防止被封IP
(一)处理cookie
Cookies是服务器存储在客户端的一些信息,用于保持会话状态。处理Cookies可以让爬虫更像一个真实的用户,从而降低被封禁的风险。
在Python中,可以通过requests库的Session对象来处理Cookies。
例:
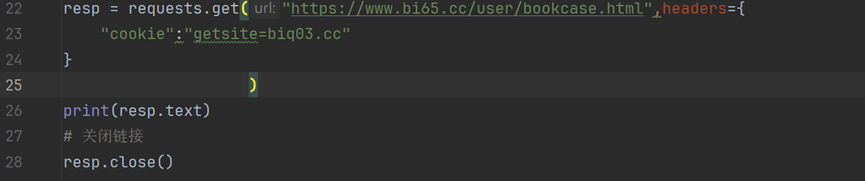
注:
get是获取Cookie
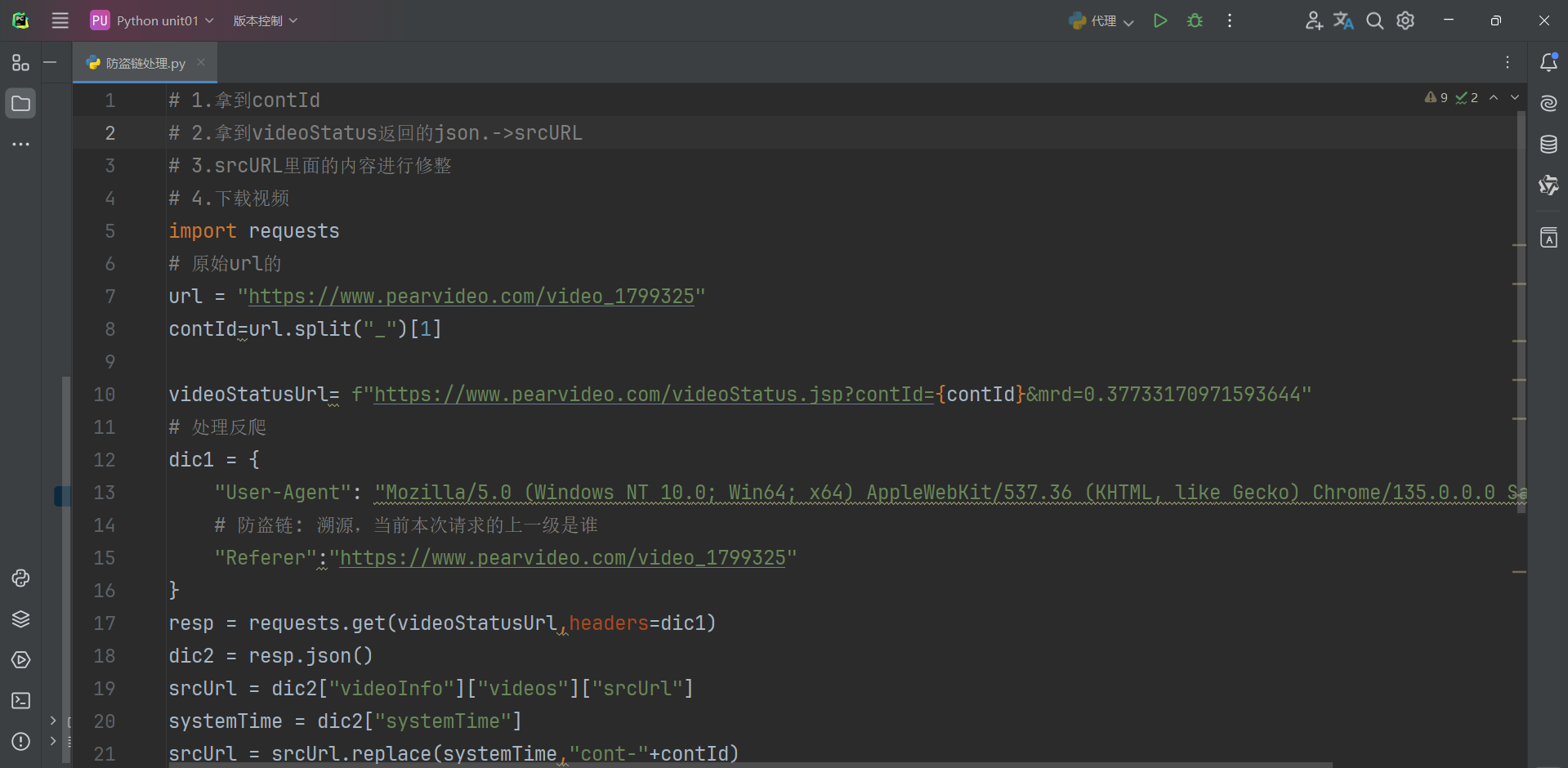
(二)防盗链
要防止盗链,使用合适的User-Agent、设置合理的爬取频率、使用代理IP、处理Cookies、遵守网站的Robots协议、模拟人类行为 等策略都很重要。使用合适的User-Agent是最基本的一步,因为它能让服务器认为你的请求来自一个真实的浏览器,从而避免被识别为爬虫。以下是关于如何防止盗链的详细描述。
- 使用合理User-Agent
- 设置合理的爬取频率
- 使用代理IP
防盗链处理代码如下:

(三)代理
在Python爬虫中为了更好地绕过反爬机制,获取网页信息,有时可能需要在Python中应用代理服务,这样做的目的就是防止自己的ip被服务器封禁,造成程序运行时中断连接,那么如何在python中设置代理呢?
如下是requests的代理处理方式如下:
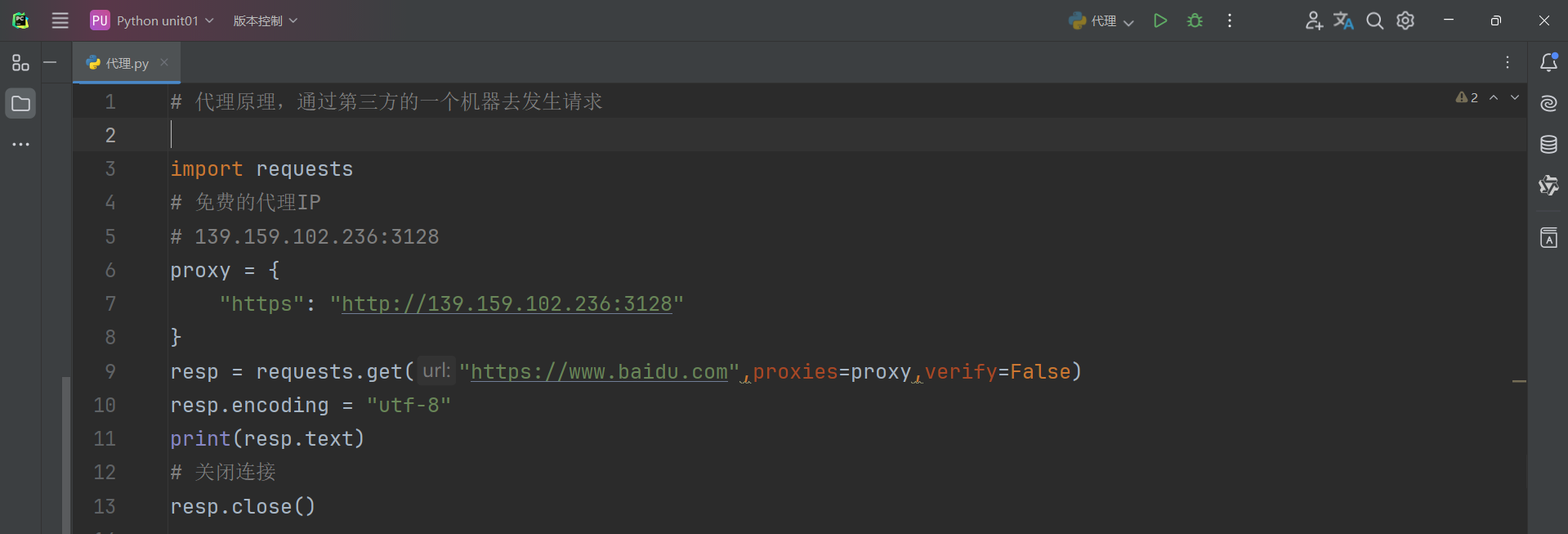
注:
你需要去网上找免费给代理的IP的网站,筛选它是否可以支持https和post,一定要学会开发者模式去查看网页。站大爷 - 企业级高品质代理IP云服务
如果你要访问的IP域名是https,那么你用的代理IP要写上https,若不需要https,只需要http即可。
二.爬虫提速
到目前为止,我们可以解决爬虫的基本抓取流程了,但是抓取效率还是不够高 如何提高抓取效率呢?我们可以选择多
线程,多进程,协程等操作完成异步爬虫.
何为异步?这里我们不讨论蹩脚的概念性问题.直接说效果
打个比方,我们目前写的爬虫可以理解为单线程,比喻为单车道公路,如何提高效率呢? 很简单,搞成多车道就OK了啊异步爬虫你就可以理解为多车道同时进行爬取。
本小节涉及内容:
1.线程池和进程池
2.协程
3.多任务异步协程实现
4.aiohttp模块详解
(一)线程池和进程池
线程和进程的区别。
线程是一个执行单位,而进程是一个资源单位。每一个进程至少需要一个线程。
注:
input()程序也是处于阻塞状态
requests.get(bilibili)在网络请求返回数据之前,程序也是处于阻塞状态的
一般情况下,当程序处于 I0操作的时候。线程都会处于阻塞状态。
由此协程可以解决这个问题。
协程:当程序遇见了I0操作的时候。可以选择性的切换到其他任务上。
协程在微观上是一个任务一个任务的进行切换,切换条件一般就是IO操作。
协程在宏观上,我们能看到的其实是多个任务一起在执行。这样的称作"多任务异步"操作
以上都是在单线程的条件下。
此小节可以看我之前Python基础篇第十一章 Python语言-高阶技巧(终章)-CSDN博客
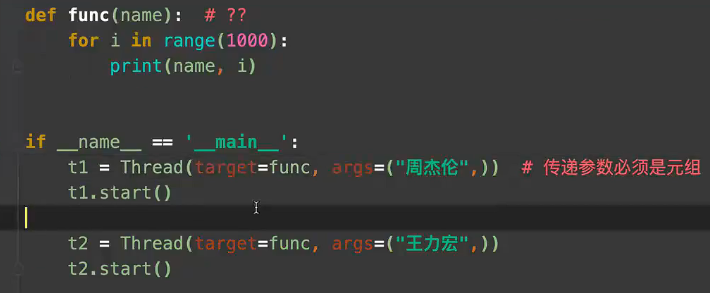
多进程的代码如下:
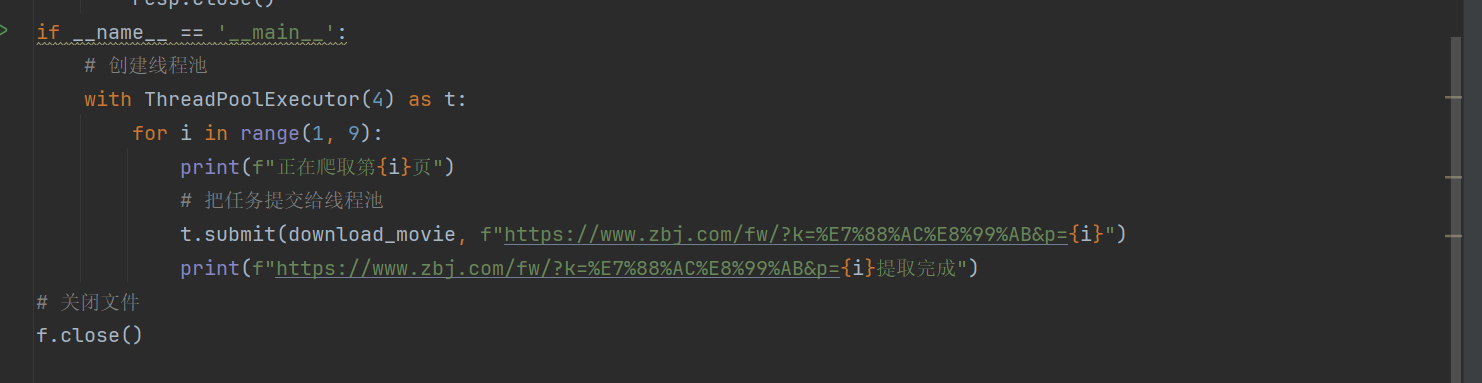
线程提速代码案例如下:
(二)协程
input()程序也是处于阻塞状态
requests.get(bilibili)在网络请求返回数据之前,程序也是处于阻塞状态的
一般情况下,当程序处于 I0操作的时候。线程都会处于阻塞状态
协程:当程序遇见了工0操作的时候,可以选择性的切换到其他任务上。
协程代码如下:
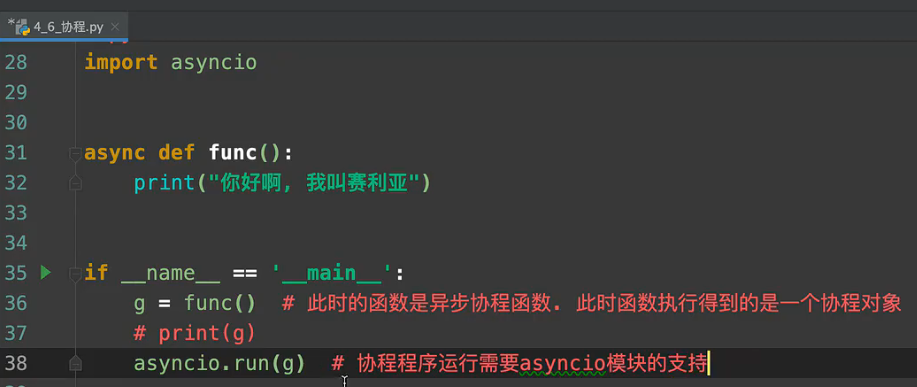
注:
asyncio是异步操作代码块。
py3.7以前协程同步代码如下:

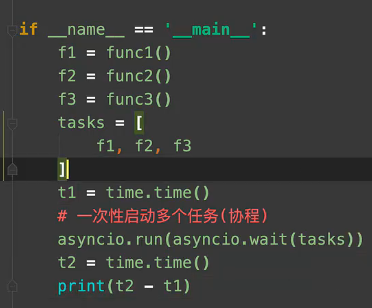
注:
time.sleep是个同步操作,当程序出现了同步操作的时候,异步就中断了。
异步操作如下:
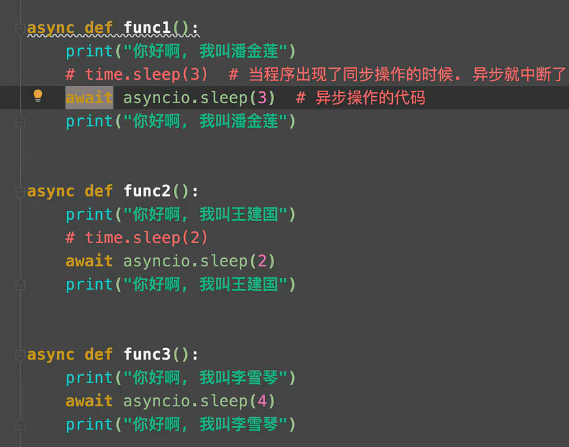
Py3.8以后协程的写法如下:
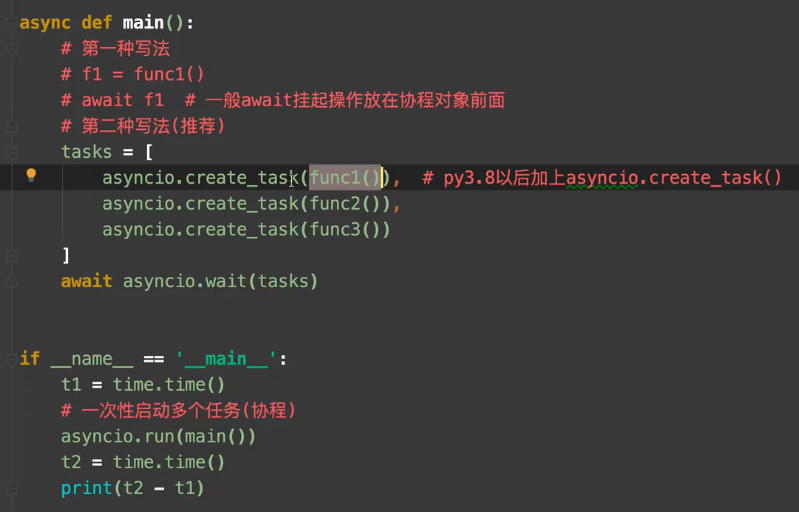
注:
ayncio需要第三方安装,需要在命令提示符下输入 pip install -i ayncio下载ayncio库
(三)异步http请求-aiohttp
requests.get()同步的代码->异步操作aiohttp
aiohttp需要第三方安装,需要在命令提示符下输入 pip install aiohttp 下载aiohttp库
aiohttp代码如下:
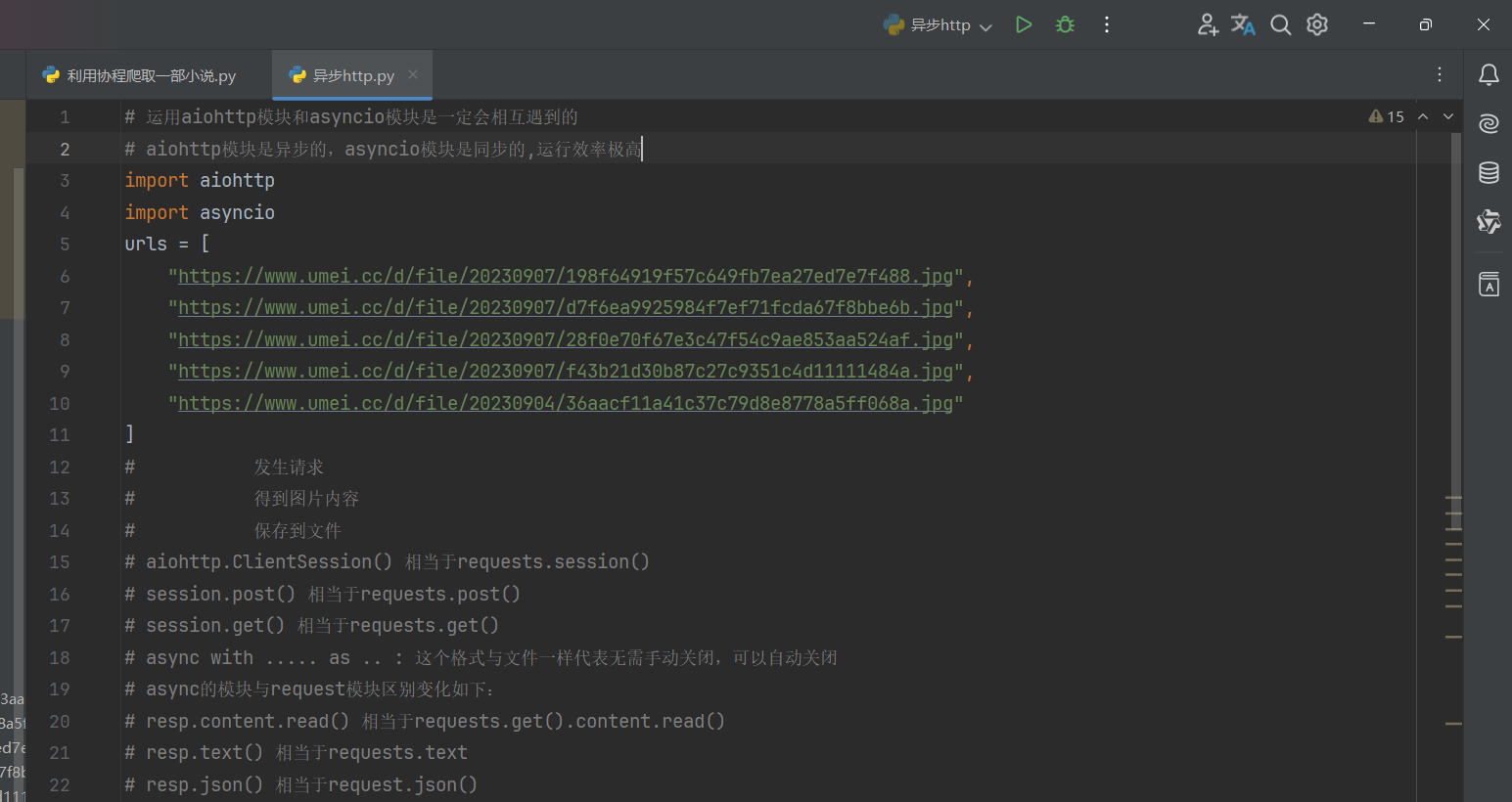
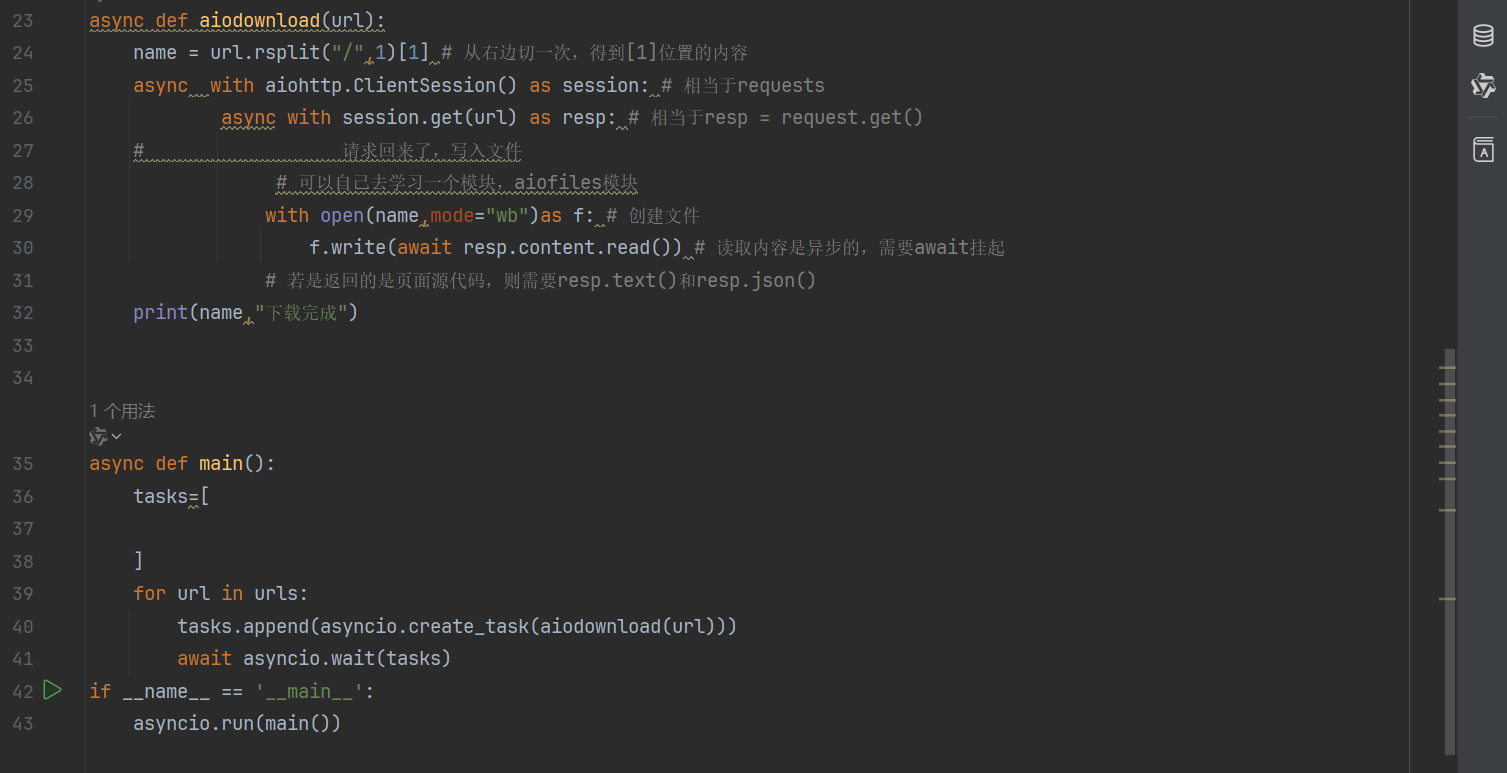
三. selenium模块
selenium:自动化测试工具
可以:打开浏览器。然后像人一样去操作浏览器,程序员可以从selenium中直接提取网页上的各种信息
环境搭建:
pip install selenium -i 清华源
下载浏览器驱动:https://npm,taobao.org/mirrors/chrcmedriver
把解压缩的浏览器驱动 chromedriver 放在python解释器所在的文件夹。
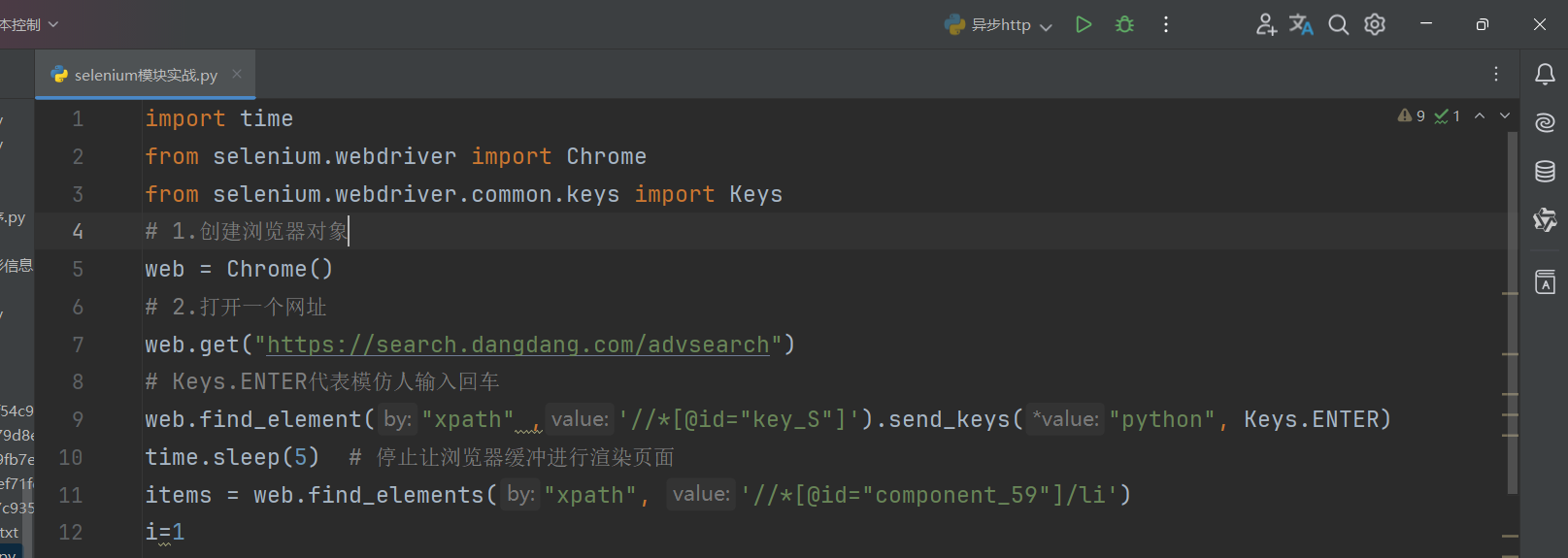
让selenium启动谷歌浏览器如下:
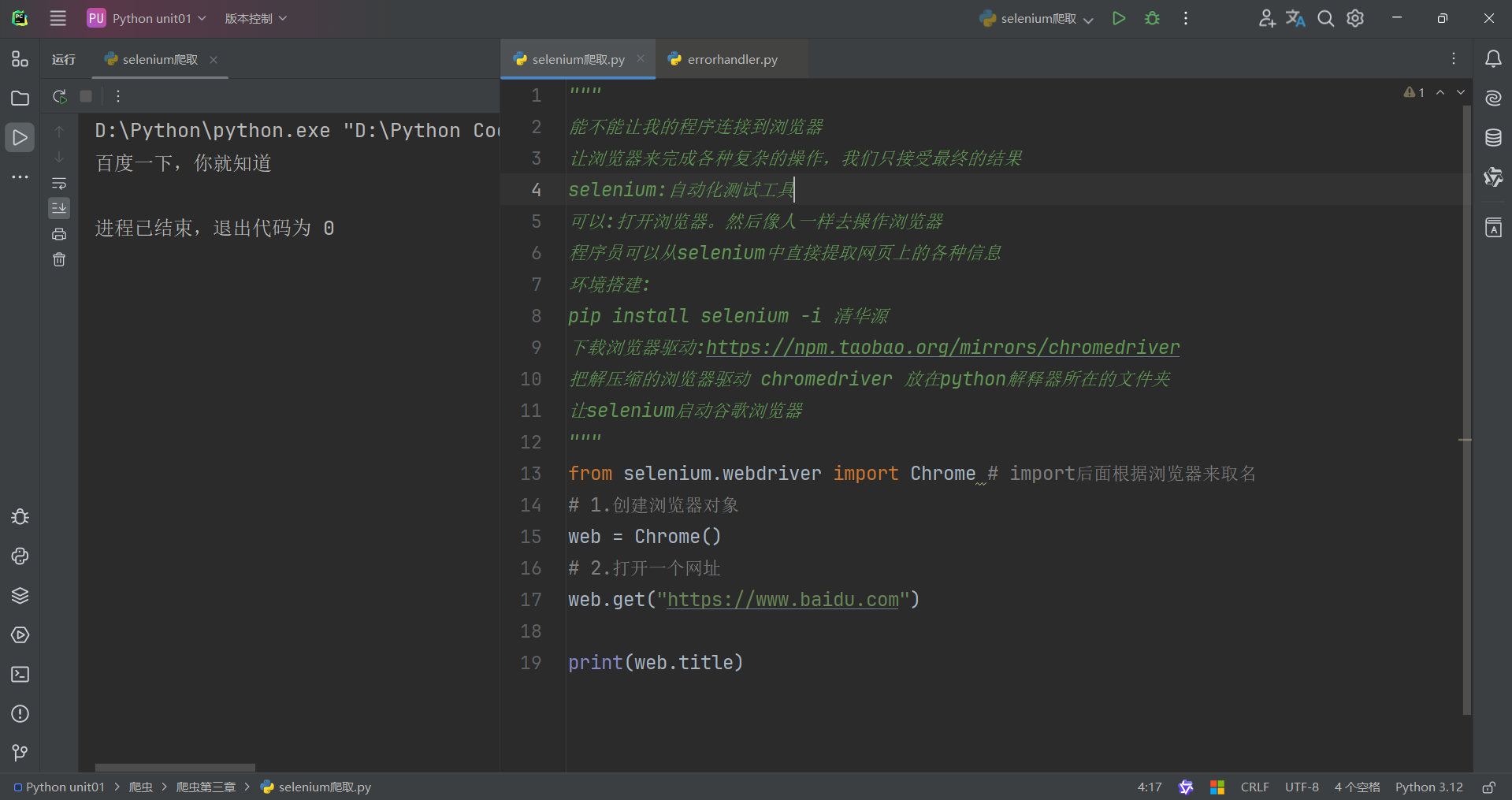
注:
selenium模块一定需要配置相应的浏览器驱动,根据浏览器的驱动,在import后面输入相应的代码,在创建对象的时候同理。
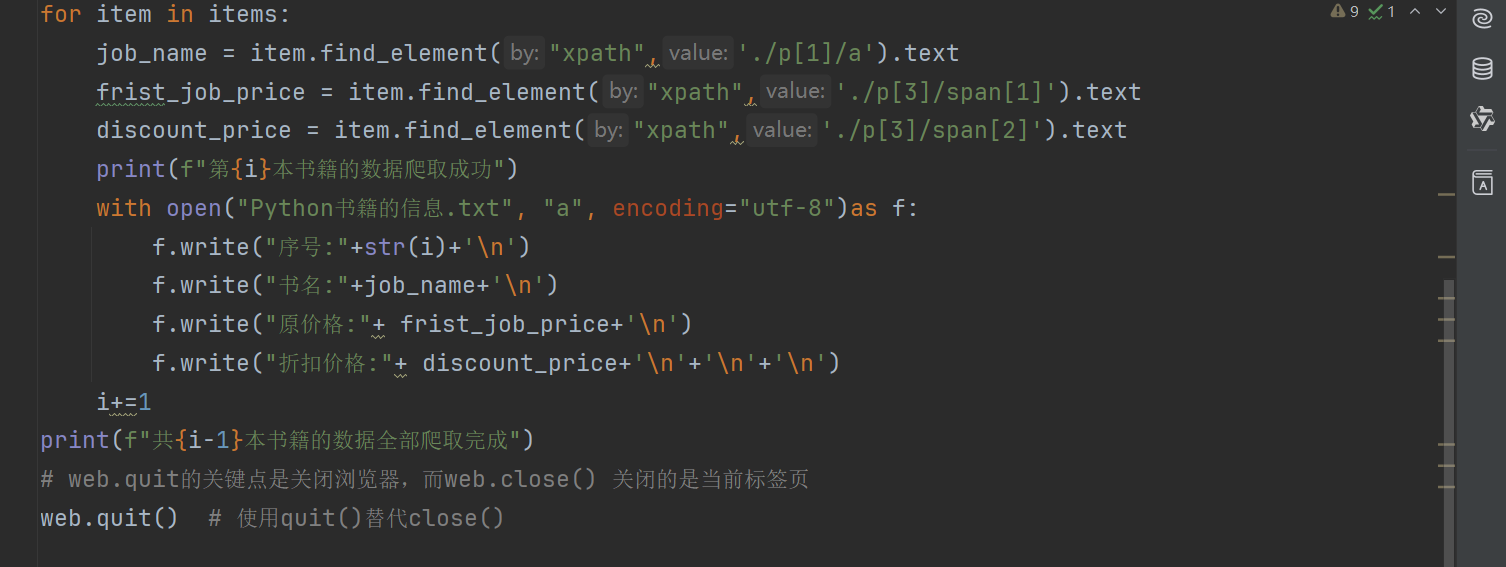
selenium实战演示代码如下: