概述
正确的身体姿势是个人整体健康的关键。然而,保持正确的身体姿势可能会很困难,因为我们常常会忘记。本博客文章将逐步指导您构建一个解决方案。最近,我们使用 MediaPipe POSE 进行身体姿势检测,效果非常好!
一、使用 MediaPipe Pose 进行身体姿势检测
MediaPipe Pose 是一种高保真度的身体姿势追踪解决方案,可以从 RGB 帧中渲染 33 个 3D 关键点和一个背景分割掩码(注意是 RGB 图像帧)。它利用了 BlazePose拓扑结构,这是 COCO、BlazeFace和 BlazePalm拓扑结构的超集。
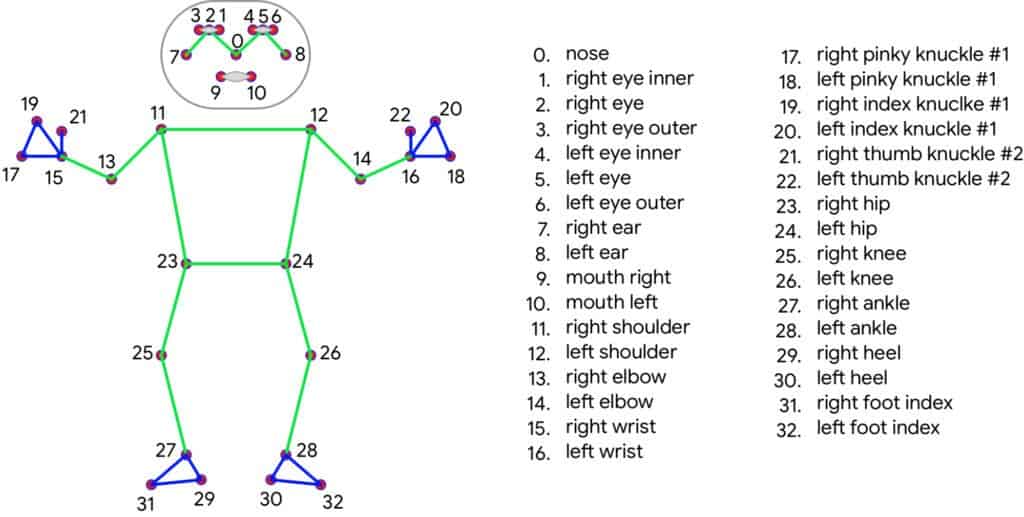
1. 应用目标 ------ MediaPipe 身体追踪
我们的目标是从完美的侧视图中检测一个人,并测量颈部和躯干相对于某个参考轴的倾斜角度。通过监控当人弯腰低于某个特定阈值角度时的倾斜角度来实现。
其他功能包括测量特定姿势的时间和相机对齐。我们必须确保相机能够正确地拍摄到侧面视角,因此我们需要对齐功能。

2. 身体姿势检测与分析应用工作流程
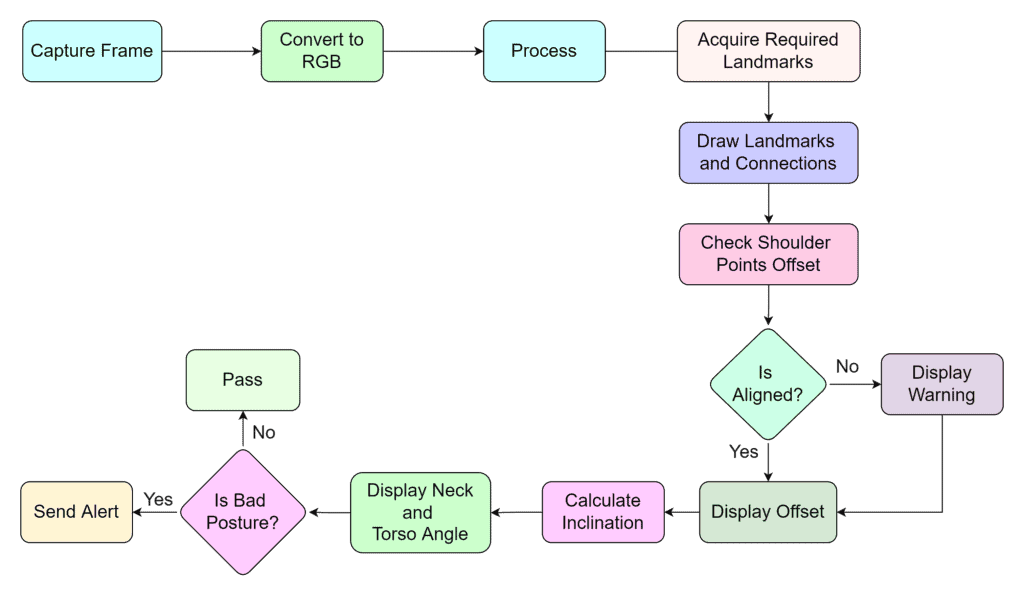
3. 准备工作
OpenCV 和 MediaPipe 是我们需要的主要包。使用代码文件夹中提供的 requirements.txt 文件来安装依赖项。
bash
pip install -r requirements.txt您需要具备 OpenCV Python 的基础知识才能理解代码。如果您是 OpenCV 的新手,这里有一些专门为初学者准备的 OpenCV 教程。
二、代码实现
1. 导入库
python
import cv2
import time
import math as m
import MediaPipe as mp2. 计算偏移距离的函数
设置要求人处于正确的侧视图中。findDistance 函数帮助我们确定两点之间的偏移距离。它可以是臀部点、眼睛或肩膀。
这些点被选中是因为它们总是或多或少关于人体中心轴对称。通过这种方式,我们可以在脚本中加入相机对齐功能。
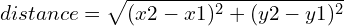

python
def findDistance(x1, y1, x2, y2):
dist = m.sqrt((x2 - x1)**2 + (y2 - y1)**2)
return dist3. 计算身体姿势倾斜角度的函数
角度是判断姿势的主要决定性因素。我们使用颈部线 和躯干线与 y 轴之间的夹角。颈部线连接肩膀和眼睛,这里我们以肩膀为支点。
同样,躯干线连接臀部和肩膀,其中臀部被视为支点。
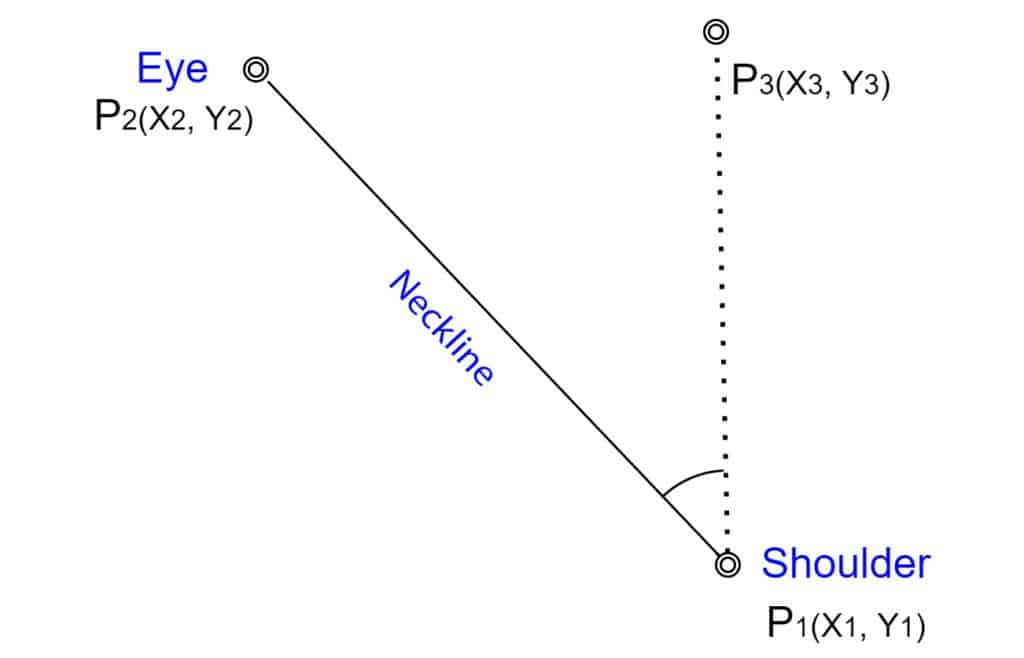
图:颈部倾斜角度测量
以颈部线为例,我们有以下点:
- P1(x1, y1):肩膀
- P2(x2, y2):眼睛
- P3 (x3, y3):通过 P1 的垂直轴上的任意一点
显然,对于 P3 ,x 坐标与 P1 相同。由于 y3 对所有 y 都有效,为了简单起见,我们取 y3 = 0。
我们采用向量方法来求三个点之间的夹角。向量 P****12 和 P****13 之间的夹角由以下公式给出:
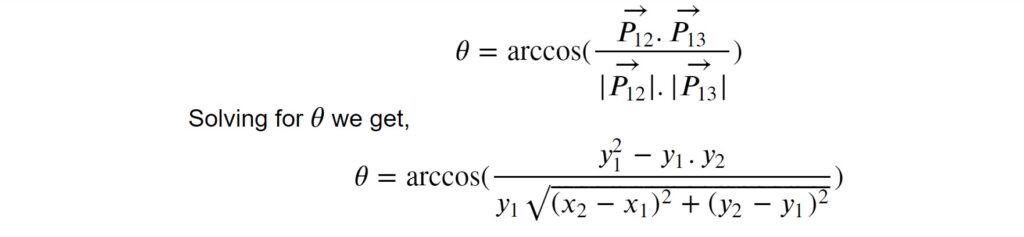
python
# 计算角度。
def findAngle(x1, y1, x2, y2):
theta = m.acos((y2 - y1) * (-y1) / (m.sqrt(
(x2 - x1)**2 + (y2 - y1)**2) * y1))
degree = int(180 / m.pi) * theta
return degree4. 发送不良姿势警报的函数
当检测到不良姿势时,使用此函数发送警报。我们将其保留为空,供您自行发挥创意并根据需要进行自定义。例如,您可以连接一个 Telegram Bot 来发送警报,这非常简单。链接在参考资料部分6。或者您可以更进一步,创建一个安卓应用。
python
def sendWarning(x):
pass5. 初始化
在这里初始化常量和方法。这些应该通过内联注释一目了然。
python
# 初始化帧计数器。
good_frames = 0
bad_frames = 0
# 字体类型。
font = cv2.FONT_HERSHEY_SIMPLEX
# 颜色。
blue = (255, 127, 0)
red = (50, 50, 255)
green = (127, 255, 0)
dark_blue = (127, 20, 0)
light_green = (127, 233, 100)
yellow = (0, 255, 255)
pink = (255, 0, 255)
# 初始化 MediaPipe 姿势类。
mp_pose = mp.solutions.pose
pose = mp_pose.Pose()6.身体姿势检测
6.1 创建视频捕获和视频写入对象
为了演示,我们使用预先录制的视频样本。在实际应用中,您需要将网络摄像头定位以捕捉您的侧视图。在以下代码片段中,创建了视频捕获和视频写入对象。
正如您所看到的,我们正在获取视频元数据以创建视频捕获对象。如果您想以 mp4 格式写入,请将编码器改为 *'mp4v' 。有关视频写入器和处理编码器的更直观指南,请查看有关 OpenCV 视频写入器(https://learnopencv.com/
reading-and-writing-videos-using-opencv/)的文章。
python
# 对于网络摄像头输入,将文件名替换为 0。
file_name = 'input.mp4'
cap = cv2.VideoCapture(file_name)
# 元数据。
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
frame_size = (width, height)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 视频写入器。
video_output = cv2.VideoWriter('output.mp4', fourcc, fps, frame_size)6.2 身体姿势检测主循环
Pose() 解决方案的可配置 API 不需要太多调整。默认值足以检测姿势关键点。然而,如果我们要生成分割掩码,则必须将 ENABLE_SEGMENTATION 标志设置为 True 。以下是 MediaPipe 姿势解决方案中的一些可配置 API。
-
STATIC_IMAGE_MODE :这是一个布尔值。如果设置为 True ,则会对每个输入图像运行人物检测。对于视频来说,这不是必要的,因为在视频中,检测运行一次后会跟随关键点跟踪。默认值为 False。
-
MODEL_COMPLEXITY:默认值为 1。它可以是 0、1 或 2。如果选择更高的复杂性,则推理时间会增加。
-
ENABLE_SEGMENTATION :如果设置为 True ,则解决方案会生成一个分割掩码以及姿势关键点。默认值为 False。
-
MIN_DETECTION_CONFIDENCE:范围为 0.0 -- 1.0。顾名思义,这是检测被认为有效的最低置信度值。默认值为 0.5。
-
MIN_TRACKING_CONFIDENCE:范围为 0.0 -- 1.0。这是关键点被认为被跟踪的最低置信度值。默认值为 0.5。
通常,默认值表现良好。因此,我们没有在 mp_pose.Pose() 中传递任何参数。以下部分涉及处理 RGB 帧,以便我们稍后从中提取姿势关键点。最后,我们将图像转换回 OpenCV 友好的 BGR 颜色空间。
python
# 捕获帧。
success, image = cap.read()
if not success:
print("Null.Frames")
break
# 获取 fps。
fps = cap.get(cv2.CAP_PROP_FPS)
# 获取帧的高度和宽度。
h, w = image.shape[:2]
# 将 BGR 图像转换为 RGB。
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 处理图像。
keypoints = pose.process(image)
# 将图像转换回 BGR。
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)6.3 获取身体姿势关键点坐标
解决方案输出对象的 pose_landmarks 属性提供了关键点的归一化 x 和 y 坐标。因此,要获取实际值,我们需要分别将输出乘以图像的 宽度 和 高度。
关键点的 LEFT_SHOULDER 、'RIGHT_SHOULDER' 等是 PoseLandmark 类的属性。要获取归一化坐标,我们使用以下语法。
python
norm_coordinate = pose.process(image).pose_landmark.landmark[MediaPipe.solutions.pose.PoseLandmark.<SPECIFIC_LANDMARK>].coordinate为了简化表示,我们使用以下简写方法。
python
# 使用 lm 和 lmPose 作为以下方法的简写。
lm = keypoints.pose_landmarks
lmPose = mp_pose.PoseLandmark
# 左肩膀。
l_shldr_x = int(lm.landmark[lmPose.LEFT_SHOULDER].x * w)
l_shldr_y = int(lm.landmark[lmPose.LEFT_SHOULDER].y * h)
# 右肩膀。
r_shldr_x = int(lm.landmark[lmPose.RIGHT_SHOULDER].x * w)
r_shldr_y = int(lm.landmark[lmPose.RIGHT_SHOULDER].y * h)
# 左耳。
l_ear_x = int(lm.landmark[lmPose.LEFT_EAR].x * w)
l_ear_y = int(lm.landmark[lmPose.LEFT_EAR].y * h)
# 左臀部。
l_hip_x = int(lm.landmark[lmPose.LEFT_HIP].x * w)
l_hip_y = int(lm.landmark[lmPose.LEFT_HIP].y * h)6.4 对齐相机
这是为了确保相机能够正确地拍摄到人的侧视图。我们测量左肩点和右肩点之间的水平距离。在正确对齐的情况下,左点和右点应该几乎重合。
请注意,偏移距离阈值是基于对具有与视频样本完全相同尺寸的数据集进行分析的结果得出的。如果您尝试使用更高分辨率的样本,这个值将会改变。它不需要非常精确,您可以根据自己的直觉设置一个阈值。
实际上,距离方法根本不是确定对齐的正确方式。它应该是基于角度的。
我们为了简化而使用距离方法。
python
# 计算左肩点和右肩点之间的距离。
offset = findDistance(l_shldr_x, l_shldr_y, r_shldr_x, r_shldr_y)
# 协助对齐相机以拍摄人的侧视图。
# 偏移阈值 30 是基于对 100 个样本进行分析的结果得出的。
if offset < 100:
cv2.putText(image, str(int(offset)) + ' Aligned', (w - 150, 30), font, 0.9, green, 2)
else:
cv2.putText(image, str(int(offset)) + ' Not Aligned', (w - 150, 30), font, 0.9, red, 2)6.5 计算身体姿势倾斜角度并绘制关键点
使用预先定义的 findAngle 函数获得倾斜角度。如下所示绘制关键点及其连接线。
python
# 计算角度。
neck_inclination = findAngle(l_shldr_x, l_shldr_y, l_ear_x, l_ear_y)
torso_inclination = findAngle(l_hip_x, l_hip_y, l_shldr_x, l_shldr_y)
# 绘制关键点。
cv2.circle(image, (l_shldr_x, l_shldr_y), 7, yellow, -1)
cv2.circle(image, (l_ear_x, l_ear_y), 7, yellow, -1)
# 为了显示的优雅,我们取 x1 的 y 坐标上方 100px 处。
# 虽然我们在计算 P1、P2、P3 之间的角度时取 y = 0。
cv2.circle(image, (l_shldr_x, l_shldr_y - 100), 7, yellow, -1)
cv2.circle(image, (r_shldr_x, r_shldr_y), 7, pink, -1)
cv2.circle(image, (l_hip_x, l_hip_y), 7, yellow, -1)
# 同样地,这里我们取 x1 的 y 坐标上方 100px。注意
# 您可以取任意值作为 y,不一定是 100 或 200 像素。
cv2.circle(image, (l_hip_x, l_hip_y - 100), 7, yellow, -1)
# 添加文本,姿势和角度倾斜。
# 文本字符串用于显示。
angle_text_string = 'Neck : ' + str(int(neck_inclination)) + ' Torso : ' + str(int(torso_inclination))6.6 身体姿势检测条件语句
根据姿势是良好还是不良,显示结果。再次强调,阈值角度是基于直觉的。您可以根据需要设置阈值。每次检测时,分别增加良好姿势和不良姿势的帧计数器。
通过将帧数 除以fps 可以计算出特定姿势的时间。有关 fps 测量方法,请查看我们之前的博客文章。
python
# 判断是良好姿势还是不良姿势。
# 阈值角度是基于直觉设置的。
if neck_inclination < 40 and torso_inclination < 10:
bad
_frames = 0
good_frames += 1
cv2.putText(image, angle_text_string, (10, 30), font, 0.9, light_green, 2)
cv2.putText(image, str(int(neck_inclination)), (l_shldr_x + 10, l_shldr_y), font, 0.9, light_green, 2)
cv2.putText(image, str(int(torso_inclination)), (l_hip_x + 10, l_hip_y), font, 0.9, light_green, 2)
# 连接关键点。
cv2.line(image, (l_shldr_x, l_shldr_y), (l_ear_x, l_ear_y), green, 4)
cv2.line(image, (l_shldr_x, l_shldr_y), (l_shldr_x, l_shldr_y - 100), green, 4)
cv2.line(image, (l_hip_x, l_hip_y), (l_shldr_x, l_shldr_y), green, 4)
cv2.line(image, (l_hip_x, l_hip_y), (l_hip_x, l_hip_y - 100), green, 4)
else:
good_frames = 0
bad_frames += 1
cv2.putText(image, angle_text_string, (10, 30), font, 0.9, red, 2)
cv2.putText(image, str(int(neck_inclination)), (l_shldr_x + 10, l_shldr_y), font, 0.9, red, 2)
cv2.putText(image, str(int(torso_inclination)), (l_hip_x + 10, l_hip_y), font, 0.9, red, 2)
# 连接关键点。
cv2.line(image, (l_shldr_x, l_shldr_y), (l_ear_x, l_ear_y), red, 4)
cv2.line(image, (l_shldr_x, l_shldr_y), (l_shldr_x, l_shldr_y - 100), red, 4)
cv2.line(image, (l_hip_x, l_hip_y), (l_shldr_x, l_shldr_y), red, 4)
cv2.line(image, (l_hip_x, l_hip_y), (l_hip_x, l_hip_y - 100), red, 4)
# 计算保持特定姿势的时间。
good_time = (1 / fps) * good_frames
bad_time = (1 / fps) * bad_frames
# 姿势时间。
if good_time > 0:
time_string_good = 'Good Posture Time : ' + str(round(good_time, 1)) + 's'
cv2.putText(image, time_string_good, (10, h - 20), font, 0.9, green, 2)
else:
time_string_bad = 'Bad Posture Time : ' + str(round(bad_time, 1)) + 's'
cv2.putText(image, time_string_bad, (10, h - 20), font, 0.9, red, 2)
# 如果保持不良姿势超过 3 分钟(180 秒),发送警报。
if bad_time > 180:
sendWarning()结论
以上就是使用 MediaPipe Pose 构建姿势校正应用的全部内容。在本篇博文中,我们讨论了如何实现 MediaPipe Pose 以检测人体姿势。您了解了如何获取姿势关键点、可配置 API、输出等。希望本篇博文帮助您了解了 MediaPipe 姿势的基础知识,并为您的下一个项目带来一些新的想法。