AI的"孤岛困境"
周三下午,你正在开发用户统计报表功能。打开Cursor,准备让AI帮忙:
第一回合:查询数据库
你:「帮我写个查询用户的SQL」
AI:「好的,这是查询代码:」
sql
SELECT * FROM users WHERE status = 'active';你皱起眉头:「等等,我们的用户表到底叫什么?有哪些字段?email字段是user_email还是email?」
→ 打开Navicat,切换到数据库标签页
→ 找到users表,双击查看结构
→ 发现表名其实是sys_users,字段叫user_email
→ 复制字段列表回到Cursor
→ 重新告诉AI:「表名是sys_users,字段有id, username, user_email, status, created_at...」
5分钟过去了。
第二回合:生成API接口
你:「帮我生成用户统计的API接口」
AI生成了代码,你粘贴到项目里,准备测试。突然想起:「咦,我们的API响应格式是什么来着?」
→ 切换到Confluence,搜索"API规范文档"
→ 找到文档:统一返回 { code, message, data }
→ 复制规范回到Cursor
→ 告诉AI:「响应格式要改成我们的统一格式」
→ AI重新生成
又是5分钟。
第三回合:前端图表展示
你:「生成前端统计图表页面」
AI:「好的,使用Chart.js绘制图表」
你:「等等,我们用的是ECharts,不是Chart.js!而且项目里已经有图表组件了...」
→ 打开项目目录,找到components/charts
→ 查看现有的LineChart.tsx组件
→ 复制组件代码给AI
→ 告诉AI:「参考这个组件的写法」
再过5分钟,你已经切换了6次工具窗口。
你抬头看了眼时间:20分钟过去了,代码还没写完。
更糟糕的是,你的思绪已经被这些上下文切换打断了。你不记得最初是想做什么了,得重新理一遍思路。
这就是AI的"孤岛困境":
Cursor AI只能看到编辑器里的代码,无法访问数据库、API文档、设计稿、云服务...
它像一个戴着眼罩的程序员,需要你不断地"口述"外部世界的信息。
如果AI能直接查询数据库、读取API文档、访问GitHub仓库,岂不是能减少90%的上下文切换?
这就是MCP(Model Context Protocol)要解决的核心问题。
本文将带你:
- 理解MCP协议的核心概念
- 5分钟配置第一个MCP服务器
- 实战配置5个核心MCP服务器
- 打造"AI + 工具生态"的完整工作流
什么是MCP?3分钟理解核心概念
MCP = Model Context Protocol(模型上下文协议)
通俗解释:
如果把Cursor AI比作一个程序员,MCP就是给他装了**"USB接口"**,可以插入各种外部工具------数据库、GitHub、云服务、设计工具...
没有MCP的AI(孤岛模式):
你 → [描述数据库结构] → AI → [生成代码]
你 → [粘贴API文档] → AI → [生成代码]
你 → [描述现有组件] → AI → [生成代码]→ 你是信息的"搬运工",不断在工具间复制粘贴
有了MCP的AI(生态模式):
你 → [提出需求] → AI → [自动查询数据库] → [自动读取文档] → [自动参考现有代码] → [生成代码]→ AI主动获取所需信息,你只需专注于需求本身
MCP架构图
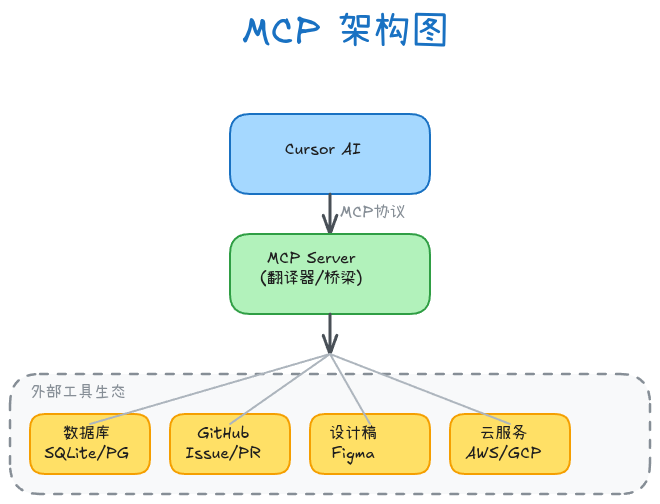
架构说明:
工作流程:
- 你在Cursor中提问:"查询最近7天注册的用户数量"
- AI识别需要数据库信息
- AI通过MCP调用SQLite服务器
- 服务器执行SQL查询
- 结果返回给AI
- AI基于真实数据生成完整代码
MCP的3个核心概念
1. Resources(资源)
定义 :AI可以读取的外部数据
示例:
- 数据库表结构:
sqlite://users - API文档:
docs://api-conventions.md - 设计稿:
figma://file/abc123 - Git历史:
github://repo/commits
使用场景:
你: "列出数据库中所有表"
AI: [通过MCP读取数据库]
"数据库有3个表: users, posts, comments"2. Tools(工具)
定义 :AI可以调用的外部功能
示例:
- 执行SQL:
execute_query(sql) - 发送HTTP请求:
http_request(url, method) - 创建GitHub Issue:
create_issue(title, body) - 截图网页:
screenshot(url)
使用场景:
你: "查询昨天新增的用户数"
AI: [通过MCP执行SQL]
"昨天新增了42个用户"3. Prompts(提示词模板)
定义:预定义的上下文模板
示例:
- 数据库性能分析模板
- API接口生成模板
- Bug修复模板
使用场景:
你: "使用 analyze-db-performance 模板"
AI: [加载预定义的分析流程]
自动检查索引、慢查询、表大小...关键价值:从"单机工具"到"生态中枢"
| 维度 | 传统模式 | MCP模式 |
|---|---|---|
| 信息获取 | 手动复制粘贴 | AI自动查询 |
| 工具切换 | 频繁切换窗口 | 一站式操作 |
| 上下文理解 | 碎片化描述 | 完整真实数据 |
| 代码质量 | 基于"想象" | 基于真实环境 |
| 开发效率 | 3x | 10x |
MCP的本质:让AI从"听你描述世界"升级为"亲眼看见世界"。
快速上手:5分钟配置你的第一个MCP服务器
让我们从最实用的场景开始:让AI直接查询你的项目数据库。
实战案例:配置SQLite MCP
假设你有一个Next.js项目,使用SQLite作为开发数据库。
Step 1: 准备测试数据库
如果还没有数据库,快速创建一个:
bash
# 创建数据库文件
sqlite3 ./dev.db
# 创建测试表
sqlite> CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
# 插入测试数据
sqlite> INSERT INTO users (name, email) VALUES
('张三', 'zhangsan@example.com'),
('李四', 'lisi@example.com'),
('王五', 'wangwu@example.com');
# 退出
sqlite> .quitStep 2: 配置Cursor的MCP服务器
打开Cursor设置:
方式1:图形界面配置
- 打开
Cursor Settings→Features→MCP - 点击
Edit Config
方式2:直接编辑配置文件
- 打开
~/.cursor/config.json(macOS/Linux) - 或
%APPDATA%\Cursor\config.json(Windows)
添加配置:
json
{
"mcpServers": {
"sqlite": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sqlite",
"/absolute/path/to/your/dev.db"
]
}
}
}⚠️ 注意:
- 路径必须是绝对路径,不能用相对路径
- macOS/Linux示例:
/Users/yourname/projects/myapp/dev.db - Windows示例:
C:\\Users\\yourname\\projects\\myapp\\dev.db
Step 3: 重启Cursor
关闭并重新打开Cursor,让配置生效。
Step 4: 验证连接
打开Cursor Chat,输入:
列出数据库中的所有表如果配置成功,AI会返回:
数据库中有以下表:
1. users
- id (INTEGER, PRIMARY KEY)
- name (TEXT, NOT NULL)
- email (TEXT, UNIQUE, NOT NULL)
- created_at (DATETIME)🎉 恭喜!你的第一个MCP服务器已经工作了!
Step 5: 实战测试
现在试试让AI直接操作数据库:
测试1:查询数据
查询users表中的所有用户AI会执行SQL并返回结果:
找到3个用户:
1. 张三 (zhangsan@example.com) - 注册于 2026-01-06
2. 李四 (lisi@example.com) - 注册于 2026-01-06
3. 王五 (wangwu@example.com) - 注册于 2026-01-06测试2:统计分析
统计最近7天每天新增的用户数量AI会生成并执行SQL:
sql
SELECT
DATE(created_at) as date,
COUNT(*) as count
FROM users
WHERE created_at >= datetime('now', '-7 days')
GROUP BY DATE(created_at)
ORDER BY date DESC;并返回分析结果。
测试3:生成代码
帮我写一个Next.js API路由,查询所有用户并返回JSONAI会基于真实的数据库结构生成代码:
typescript
// app/api/users/route.ts
import { NextResponse } from 'next/server';
import Database from 'better-sqlite3';
const db = new Database('./dev.db');
export async function GET() {
try {
const users = db.prepare('SELECT id, name, email, created_at FROM users').all();
return NextResponse.json({
code: 200,
message: 'success',
data: users
});
} catch (error) {
console.error('[GET /api/users]', error);
return NextResponse.json({
code: 500,
message: error instanceof Error ? error.message : 'Unknown error',
data: null
}, { status: 500 });
}
}注意到了吗?
- ✅ 字段名完全正确(id, name, email, created_at)
- ✅ 表名正确(users)
- ✅ 使用了better-sqlite3库(基于项目实际情况)
- ✅ 错误处理完整
这就是MCP的威力 :AI基于真实数据生成代码,而不是"猜测"。
效果对比
| 方式 | 操作步骤 | 用时 | 准确率 |
|---|---|---|---|
| 传统 | 打开Navicat → 查看表结构 → 复制字段 → 告诉AI | 2分钟 | 60% |
| MCP | 直接问AI | 10秒 | 95% |
效率提升:12倍!
核心MCP服务器实战配置
掌握了SQLite MCP的基础用法后,让我们扩展AI的能力,连接更多外部工具。
1. 文件系统MCP - 让AI管理项目文件
使用场景
- AI需要读取项目配置文件
- 批量分析代码文件
- 检查项目结构
- 自动生成文件清单
配置方式
json
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/your/project"
]
}
}
}⚠️ 安全提示:
- 只授权项目目录,不要授权整个硬盘
- 避免授权包含敏感信息的目录
实战案例1:检查依赖版本一致性
检查项目中所有 package.json 的依赖版本,找出版本不一致的依赖包AI会:
-
扫描所有
package.json文件 -
提取依赖版本
-
对比分析
-
生成报告:
发现3处版本不一致:
-
react
- 主项目: 18.2.0
- packages/admin: 18.3.1
- packages/mobile: 18.2.0
⚠️ 建议统一到 18.3.1
-
typescript
- 主项目: 5.3.3
- packages/admin: 5.2.2
✅ 差异较小,可接受
-
eslint
- 主项目: 8.56.0
- packages/admin: 8.55.0
- packages/mobile: 未安装
⚠️ mobile包缺少eslint配置
-
实战案例2:生成项目文档
分析项目结构,生成 ARCHITECTURE.md 文档AI会自动:
- 遍历目录结构
- 识别关键文件和模块
- 分析依赖关系
- 生成Markdown文档
生成的文档示例:
markdown
# 项目架构文档
## 目录结构
\`\`\`
project/
├── src/
│ ├── app/ # Next.js App Router页面
│ ├── components/ # React组件
│ ├── lib/ # 工具函数
│ └── types/ # TypeScript类型
├── public/ # 静态资源
└── prisma/ # 数据库Schema
\`\`\`
## 核心模块
1. **认证模块** (src/lib/auth/)
- 使用NextAuth.js
- 支持GitHub和Google登录
2. **数据库** (prisma/)
- PostgreSQL
- Prisma ORM
...2. GitHub MCP - 连接代码仓库
使用场景
- 查看Issue和PR
- 分析提交历史
- 自动生成Release Notes
- 代码审查辅助
配置方式
json
{
"mcpServers": {
"github": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-github"
],
"env": {
"GITHUB_TOKEN": "ghp_your_token_here"
}
}
}
}如何获取GitHub Token:
- 访问 https://github.com/settings/tokens
- 点击
Generate new token (classic) - 勾选权限:
repo,read:org - 复制生成的token
实战案例1:分析最近的代码变更
查看最近10个PR中,哪些涉及到认证模块的修改AI会:
-
通过GitHub API获取最近10个PR
-
分析每个PR的文件变更
-
筛选出涉及
src/lib/auth/的PR -
生成摘要报告:
找到3个相关PR:
-
#156: 添加Google OAuth登录
- 修改文件: src/lib/auth/providers.ts
- 状态: 已合并
- 作者: @zhangsan
- 合并时间: 2天前
-
#142: 修复JWT过期处理
- 修改文件: src/lib/auth/jwt.ts, src/middleware.ts
- 状态: 已合并
- 作者: @lisi
- 合并时间: 5天前
-
#138: 重构认证中间件
- 修改文件: src/lib/auth/* (多个文件)
- 状态: 进行中
- 作者: @wangwu
-
实战案例2:自动生成Release Notes
基于最近20个已合并的PR,生成v1.5.0的Release NotesAI会分析PR标题、标签、描述,自动分类并生成:
markdown
# Release v1.5.0
## 🚀 新功能
- 添加Google OAuth登录支持 (#156)
- 支持用户头像上传 (#151)
- 新增数据导出功能 (#149)
## 🐛 Bug修复
- 修复JWT过期后无法刷新的问题 (#142)
- 修复分页组件在移动端的显示问题 (#145)
## 🔨 重构
- 重构认证中间件,提升性能 (#138)
- 优化数据库查询逻辑 (#140)
## 📝 文档
- 更新API文档 (#147)
- 添加部署指南 (#143)3. Postgres MCP - 企业级数据库操作
使用场景
- 生产环境数据库查询(只读)
- 数据库性能分析
- 生成数据库迁移脚本
- 复杂SQL优化
配置方式
json
{
"mcpServers": {
"postgres": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-postgres",
"postgresql://user:password@localhost:5432/dbname"
]
}
}
}⚠️ 安全建议:
- 使用只读账号
- 连接开发/测试数据库,避免直连生产库
- 敏感数据脱敏
实战案例:数据库性能分析
分析users表的查询性能,提出优化建议AI会:
-
查询表结构和索引
-
分析表大小和行数
-
检查索引使用率
-
生成优化建议:
📊 users表性能分析报告
基本信息
- 行数: 1,245,678
- 大小: 248 MB
- 索引数: 3
当前索引
- PRIMARY (id) - 正常使用 ✅
- idx_email (email) - 正常使用 ✅
- idx_created_at (created_at) - 使用率低 ⚠️
性能问题
-
缺少复合索引
- 常见查询: WHERE status = ? AND created_at > ?
- 建议: CREATE INDEX idx_status_created ON users(status, created_at)
-
created_at索引使用率低
- 原因: 大多数查询都包含status条件
- 建议: 删除单独的created_at索引,使用复合索引
优化SQL
```sql
-- 添加复合索引
CREATE INDEX CONCURRENTLY idx_status_created
ON users(status, created_at);-- 删除低效索引
DROP INDEX idx_created_at;
```预期效果
- 查询速度提升: 3-5倍
- 索引存储减少: 20MB
4. Puppeteer MCP - Web自动化测试
使用场景
- 自动化UI测试
- 网页截图
- 性能监控
- 数据抓取
配置方式
json
{
"mcpServers": {
"puppeteer": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-puppeteer"
]
}
}
}实战案例:自动化测试登录流程
测试我们的登录页面 http://localhost:3000/login
检查表单验证是否正常工作AI会:
- 启动无头浏览器
- 访问登录页
- 测试各种输入场景
- 截图并分析
测试报告:
🧪 登录页面测试报告
**测试场景1: 空表单提交**
- 操作: 直接点击"登录"按钮
- 结果: ✅ 显示错误提示 "请输入邮箱"
- 截图: [附带截图]
**测试场景2: 邮箱格式错误**
- 操作: 输入 "invalid-email" 并提交
- 结果: ✅ 显示 "邮箱格式不正确"
**测试场景3: 密码太短**
- 操作: 输入邮箱,密码只输入"123"
- 结果: ✅ 显示 "密码至少6位"
**测试场景4: 正确登录**
- 操作: 输入正确的测试账号
- 结果: ✅ 成功跳转到首页
**总结**
- 通过率: 4/4 (100%)
- 表单验证工作正常 ✅5. 自定义MCP - 连接你的业务系统
使用场景
- 连接公司内部API
- 集成CRM/ERP系统
- 对接监控告警系统
- 自定义工作流
最简MCP服务器实现
创建文件 my-custom-mcp.ts:
typescript
#!/usr/bin/env node
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
// 创建服务器
const server = new Server({
name: 'my-custom-mcp',
version: '1.0.0',
}, {
capabilities: {
resources: {},
tools: {},
},
});
// 定义Resources - AI可以读取的数据
server.setRequestHandler('resources/list', async () => ({
resources: [
{
uri: 'custom://internal-api/docs',
name: 'Internal API Documentation',
description: '公司内部API文档',
mimeType: 'text/markdown',
},
],
}));
server.setRequestHandler('resources/read', async (request) => {
const uri = request.params.uri;
if (uri === 'custom://internal-api/docs') {
return {
contents: [{
uri,
mimeType: 'text/markdown',
text: `
# 内部API文档
## 用户服务
- GET /api/v1/users - 获取用户列表
- POST /api/v1/users - 创建用户
...
`,
}],
};
}
throw new Error('Resource not found');
});
// 定义Tools - AI可以调用的功能
server.setRequestHandler('tools/list', async () => ({
tools: [
{
name: 'query_crm',
description: '查询CRM系统中的客户数据',
inputSchema: {
type: 'object',
properties: {
customer_id: {
type: 'string',
description: '客户ID',
},
},
required: ['customer_id'],
},
},
],
}));
server.setRequestHandler('tools/call', async (request) => {
const { name, arguments: args } = request.params;
if (name === 'query_crm') {
// 调用你的内部API
const response = await fetch(`https://internal-crm.company.com/api/customers/${args.customer_id}`);
const data = await response.json();
return {
content: [{
type: 'text',
text: JSON.stringify(data, null, 2),
}],
};
}
throw new Error('Tool not found');
});
// 启动服务器
const transport = new StdioServerTransport();
await server.connect(transport);配置使用
json
{
"mcpServers": {
"my-custom": {
"command": "node",
"args": ["/path/to/my-custom-mcp.ts"]
}
}
}使用示例
查询客户ID为12345的详细信息AI会通过你的自定义MCP调用内部CRM系统,返回客户数据。
完整工作流案例:MCP加持的全栈开发
让我们通过一个真实场景,看看MCP如何改变开发流程。
场景:开发用户统计报表功能
需求:
- 统计最近30天的用户增长趋势
- 支持按日/周/月分组
- 前端用ECharts展示图表
- 符合团队的API规范
传统开发流程(约30分钟)
1. 打开Navicat,查看users表结构
→ 确认字段名和类型
⏱️ 2分钟
2. 手动写SQL测试查询
→ 确认数据正确
⏱️ 5分钟
3. 复制SQL到代码,写API接口
→ 打开Confluence查API规范
→ 复制响应格式模板
⏱️ 10分钟
4. 找现有的图表组件
→ 打开项目目录查找
→ 阅读组件源码
⏱️ 5分钟
5. 写前端页面调用API
→ 调试图表参数
⏱️ 8分钟
总计: 30分钟 + 5次工具切换MCP加持的开发流程(约5分钟)
打开Cursor Chat,一句话搞定:
开发一个用户增长统计报表功能
需求:
- 统计最近30天用户增长趋势
- 支持按日/周/月分组
- 使用ECharts展示
请完成:
1. 后端API接口 (按照 @docs/api-conventions.md 规范)
2. 前端页面 (参考 @src/components/charts/ 中的图表组件)AI自动执行(全程无需人工干预):
步骤1: 查询数据库结构(通过SQLite MCP)
[MCP] 连接数据库...
[MCP] 查询表结构: users
[MCP] 字段: id, username, email, created_at, status步骤2: 生成并测试SQL
sql
-- AI自动生成并测试
SELECT
DATE(created_at) as date,
COUNT(*) as count
FROM users
WHERE created_at >= datetime('now', '-30 days')
GROUP BY DATE(created_at)
ORDER BY date ASC;步骤3: 读取API规范(通过Filesystem MCP)
[MCP] 读取 docs/api-conventions.md
[MCP] 识别响应格式: { code, message, data }步骤4: 生成后端API
typescript
// app/api/stats/users/route.ts
import { NextResponse } from 'next/server';
import Database from 'better-sqlite3';
const db = new Database('./dev.db');
export async function GET(request: Request) {
try {
const { searchParams } = new URL(request.url);
const groupBy = searchParams.get('groupBy') || 'day';
// 根据groupBy参数调整SQL
const dateFormat = {
'day': "DATE(created_at)",
'week': "strftime('%Y-W%W', created_at)",
'month': "strftime('%Y-%m', created_at)"
}[groupBy];
const stats = db.prepare(`
SELECT
${dateFormat} as period,
COUNT(*) as count
FROM users
WHERE created_at >= datetime('now', '-30 days')
GROUP BY ${dateFormat}
ORDER BY period ASC
`).all();
return NextResponse.json({
code: 200,
message: 'success',
data: stats
});
} catch (error) {
console.error('[GET /api/stats/users]', error);
return NextResponse.json({
code: 500,
message: error instanceof Error ? error.message : 'Unknown error',
data: null
}, { status: 500 });
}
}步骤5: 参考现有组件(通过Filesystem MCP)
[MCP] 扫描 src/components/charts/
[MCP] 找到参考: LineChart.tsx
[MCP] 分析组件API步骤6: 生成前端页面
typescript
// app/dashboard/user-growth/page.tsx
'use client';
import { useState, useEffect } from 'react';
import { LineChart } from '@/components/charts/LineChart';
export default function UserGrowthPage() {
const [data, setData] = useState([]);
const [groupBy, setGroupBy] = useState('day');
const [loading, setLoading] = useState(true);
useEffect(() => {
fetchStats();
}, [groupBy]);
const fetchStats = async () => {
setLoading(true);
try {
const res = await fetch(`/api/stats/users?groupBy=${groupBy}`);
const json = await res.json();
if (json.code === 200) {
setData(json.data);
}
} catch (error) {
console.error(error);
} finally {
setLoading(false);
}
};
return (
<div className="p-6">
<h1 className="text-2xl font-bold mb-4">用户增长趋势</h1>
<div className="mb-4">
<select
value={groupBy}
onChange={(e) => setGroupBy(e.target.value)}
className="border rounded px-3 py-2"
>
<option value="day">按日</option>
<option value="week">按周</option>
<option value="month">按月</option>
</select>
</div>
{loading ? (
<div>加载中...</div>
) : (
<LineChart
data={data}
xKey="period"
yKey="count"
title="用户增长趋势"
height={400}
/>
)}
</div>
);
}AI总结:
✅ 已完成:
1. 后端API: app/api/stats/users/route.ts
- 支持day/week/month三种分组
- 符合API规范
- 包含错误处理
2. 前端页面: app/dashboard/user-growth/page.tsx
- 使用现有的LineChart组件
- 支持动态切换分组方式
- 包含loading状态
建议测试:
1. 访问 http://localhost:3000/dashboard/user-growth
2. 切换分组方式,验证数据更新
3. 检查API响应格式是否正确
⏱️ 总用时: 约5分钟效果对比
| 指标 | 传统方式 | MCP方式 | 提升 |
|---|---|---|---|
| 开发时间 | 30分钟 | 5分钟 | 6倍 |
| 工具切换 | 5次 | 0次 | - |
| 代码质量 | 需要手动检查 | 基于真实数据验证 | ⬆️ |
| 规范遵守 | 容易遗漏 | 自动遵守 | ✅ |
| 上下文理解 | 碎片化 | 完整准确 | ⬆️ |
MCP生态图谱:官方服务器一览
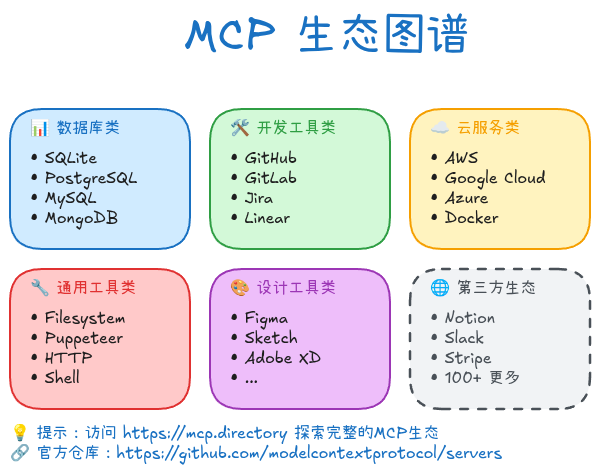
数据库类
| 服务器 | 支持数据库 | npm包名 |
|---|---|---|
| SQLite | SQLite | @modelcontextprotocol/server-sqlite |
| Postgres | PostgreSQL | @modelcontextprotocol/server-postgres |
| MySQL | MySQL/MariaDB | @modelcontextprotocol/server-mysql |
| MongoDB | MongoDB | @modelcontextprotocol/server-mongodb |
开发工具类
| 服务器 | 功能 | npm包名 |
|---|---|---|
| GitHub | Issue, PR, Commits | @modelcontextprotocol/server-github |
| GitLab | MR, Issues | @modelcontextprotocol/server-gitlab |
| Jira | 任务管理 | @modelcontextprotocol/server-jira |
| Linear | 项目管理 | @modelcontextprotocol/server-linear |
云服务类
| 服务器 | 支持服务 | npm包名 |
|---|---|---|
| AWS | S3, Lambda, DynamoDB | @modelcontextprotocol/server-aws |
| Google Cloud | Cloud Storage, Functions | @modelcontextprotocol/server-gcp |
| Azure | Blob Storage, Functions | @modelcontextprotocol/server-azure |
| Docker | 容器管理 | @modelcontextprotocol/server-docker |
通用工具类
| 服务器 | 功能 | npm包名 |
|---|---|---|
| Filesystem | 文件系统操作 | @modelcontextprotocol/server-filesystem |
| Puppeteer | 浏览器自动化 | @modelcontextprotocol/server-puppeteer |
| HTTP | HTTP请求 | @modelcontextprotocol/server-http |
| Shell | 命令行执行 | @modelcontextprotocol/server-shell |
设计工具类
| 服务器 | 功能 | npm包名 |
|---|---|---|
| Figma | 设计稿读取 | @modelcontextprotocol/server-figma |
| Sketch | 设计稿读取 | @modelcontextprotocol/server-sketch |
第三方生态
社区已开发100+ MCP服务器,覆盖各种场景:
- 数据分析:Tableau, Metabase
- 文档协作:Notion, Confluence
- 通讯工具:Slack, Discord
- 支付系统:Stripe, PayPal
- 监控告警:Datadog, Prometheus
- ...更多
查找更多MCP服务器:
常见问题与避坑指南
问题1: MCP服务器启动失败
错误信息:
Failed to start MCP server: command not found原因分析:
- Node.js版本过低(需要18+)
- npx未正确安装
- 路径配置错误
解决方案:
bash
# 检查Node.js版本
node --version
# 如果低于18,升级Node.js
# 检查npx
npx --version
# 测试MCP服务器
npx -y @modelcontextprotocol/server-sqlite --help如果仍然失败,尝试全局安装:
bash
npm install -g @modelcontextprotocol/server-sqlite然后修改配置:
json
{
"mcpServers": {
"sqlite": {
"command": "server-sqlite",
"args": ["/path/to/db.db"]
}
}
}问题2: AI不使用MCP
现象 :
配置了MCP,但AI还是"假装"查询数据库,不调用真实的MCP。
原因:
- Prompt不明确
- AI没有意识到可以使用MCP
解决方案:
❌ 不明确的Prompt:
查询用户数量→ AI可能直接"编造"一个数字
✅ 明确的Prompt:
从数据库查询users表的总行数→ AI会通过MCP执行真实查询
更好的做法:
使用MCP连接的数据库,查询users表的总行数问题3: 数据库连接安全风险
错误做法:
json
{
"mcpServers": {
"postgres": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-postgres",
"postgresql://admin:password@production-db:5432/maindb"
]
}
}
}→ ⚠️ 直接连接生产数据库,风险极高!
正确做法:
- 使用本地/测试数据库
json
{
"mcpServers": {
"postgres": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-postgres",
"postgresql://readonly:safe_password@localhost:5432/dev_db"
]
}
}
}- 配置只读账号
sql
-- 创建只读用户
CREATE USER readonly WITH PASSWORD 'safe_password';
GRANT CONNECT ON DATABASE dev_db TO readonly;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly;- 敏感数据脱敏
sql
-- 创建脱敏视图
CREATE VIEW users_safe AS
SELECT
id,
username,
CONCAT(LEFT(email, 3), '***@', SPLIT_PART(email, '@', 2)) AS email,
created_at
FROM users;
-- 只授权访问脱敏视图
GRANT SELECT ON users_safe TO readonly;问题4: MCP服务器性能问题
现象 :
AI调用MCP很慢,甚至超时。
原因:
- 数据库查询太慢
- 返回数据量过大
- 网络延迟
解决方案:
- 限制查询结果
sql
-- ❌ 查询所有数据
SELECT * FROM users;
-- ✅ 限制返回行数
SELECT * FROM users LIMIT 100;- 添加索引
sql
-- 慢查询分析
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'xxx';
-- 添加索引
CREATE INDEX idx_email ON users(email);- 使用缓存
自定义MCP中添加缓存:
typescript
import { LRUCache } from 'lru-cache';
const cache = new LRUCache({
max: 100,
ttl: 1000 * 60 * 5, // 5分钟
});
server.setRequestHandler('tools/call', async (request) => {
const cacheKey = JSON.stringify(request.params);
// 检查缓存
if (cache.has(cacheKey)) {
return cache.get(cacheKey);
}
// 执行查询
const result = await executeQuery(request.params);
// 存入缓存
cache.set(cacheKey, result);
return result;
});问题5: 自定义MCP开发难度
困难点:
- MCP协议规范复杂
- TypeScript配置繁琐
- 调试困难
解决方案:
- 从官方示例开始
bash
# 克隆官方示例
git clone https://github.com/modelcontextprotocol/servers
cd servers/src/sqlite
# 学习源码
cat index.ts- 使用MCP SDK
bash
npm install @modelcontextprotocol/sdk- 参考完整模板
创建 package.json:
json
{
"name": "my-mcp-server",
"version": "1.0.0",
"type": "module",
"bin": {
"my-mcp": "./dist/index.js"
},
"scripts": {
"build": "tsc",
"dev": "tsc --watch"
},
"dependencies": {
"@modelcontextprotocol/sdk": "^1.0.0"
},
"devDependencies": {
"@types/node": "^20.0.0",
"typescript": "^5.3.0"
}
}总结与行动清单
核心要点回顾
MCP的3大价值:
-
🔗 连接生态
- AI从"孤岛"变成"中枢"
- 一次配置,终身受益
-
⚡ 效率飞跃
- 减少工具切换 90%
- 开发速度提升 5-10倍
-
🎯 质量提升
- 基于真实数据生成代码
- 自动遵守项目规范
立即行动清单
markdown
□ 第1步: 配置SQLite MCP(5分钟)
- 创建测试数据库
- 修改~/.cursor/config.json
- 测试AI查询功能
□ 第2步: 配置Filesystem MCP(3分钟)
- 授权项目目录
- 测试AI读取文件
□ 第3步: 配置GitHub MCP(5分钟)
- 生成GitHub Token
- 测试AI查询Issue/PR
□ 第4步: 实战测试(20分钟)
- 用MCP开发一个完整功能
- 对比传统方式,记录效率提升
□ 第5步: 探索更多MCP(按需)
- 访问 https://mcp.directory
- 根据团队需求配置更多服务器进阶方向
对于个人开发者:
- 配置本地工具链(数据库、文件系统、浏览器)
- 探索第三方MCP(Notion、Figma等)
- 开发自己的MCP服务器
对于团队:
- 建立团队MCP服务器库
- 开发连接内部系统的自定义MCP
- 制定MCP使用规范和安全策略
对于企业:
- 构建企业级MCP基础设施
- 集成ERP、CRM、监控系统
- 实现"AI驱动的DevOps"
预期收益
配置MCP后,你将获得:
| 维度 | 传统开发 | MCP加持 | 提升 |
|---|---|---|---|
| 信息获取 | 手动查找复制 | AI自动获取 | 10倍 |
| 工具切换 | 10次/小时 | 1次/小时 | 90%↓ |
| 代码准确率 | 60-70% | 90-95% | +30% |
| 开发速度 | 1x | 5-10x | 5-10倍 |
| 工作体验 | 频繁被打断 | 专注流畅 | ⬆️ |
相关资源:
- MCP官方文档: https://modelcontextprotocol.io
- MCP服务器目录: https://mcp.directory
- MCP GitHub仓库: https://github.com/modelcontextprotocol
- Cursor官方文档: https://cursor.com/docs
系列文章
- 【Cursor进阶实战·01】Figma设计稿一键还原
- 【Cursor进阶实战·02】告别丑陋界面
- 【Cursor进阶实战·03】四大模式完全指南:Agent/Plan/Debug/Ask的正确打开方式
- 【Cursor进阶实战·04】工作流革命:从"手动驾驶"到"自动驾驶"
- 【Cursor进阶实战·05】复述确认法:让AI先理解再执行,避免"瞎改"代码
感谢阅读!如果这篇文章对你有帮助,欢迎点赞、收藏、分享。我们下期见!👋
有问题欢迎在评论区讨论,我会尽量回复每一条评论。