前期知识背景
binlog
什么是binlog
它记录了所有的DDL和DML(除 了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。一般来说开启二进制日志大概会有1%的性能损耗。
binlog分类
MySQL Binlog的格式有三种,分别是STATEMENT,MIXED,ROW。在配置文件可以选择配置:binlog_format= statement|mixed|row
statement
binlog 会记录每次一执行写操作的语句。相对row模式节省空间,但是可能产生不一致性,比如"update tt set create_date=now()", 如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点:节省空间。
缺点:有可能造成数据不一致。
row
binlog会记录每次操作前后每行记录的变化。
优点:保持数据的绝对一致性。
缺点:占用较大空间。
mixed
以上两种结合
综合上面对比,Canal想做监控分析,选择row格式比较合适。
binlog查看命令
java
#查看binlog日志是否开启
SHOW VARIABLES LIKE 'log_bin';
#查看binlog模式
SHOW VARIABLES LIKE 'binlog_format';
#查看binlog写入的二进制日志文件的名称和偏移量(Position)
SHOW MASTER STATUS;


canal
介绍
Canal,译意为水道/管道/沟渠,主要用途是基于M小ySQL数据库增量日志解析,提供增量数据订阅和消费。同步增量数据的一个工具
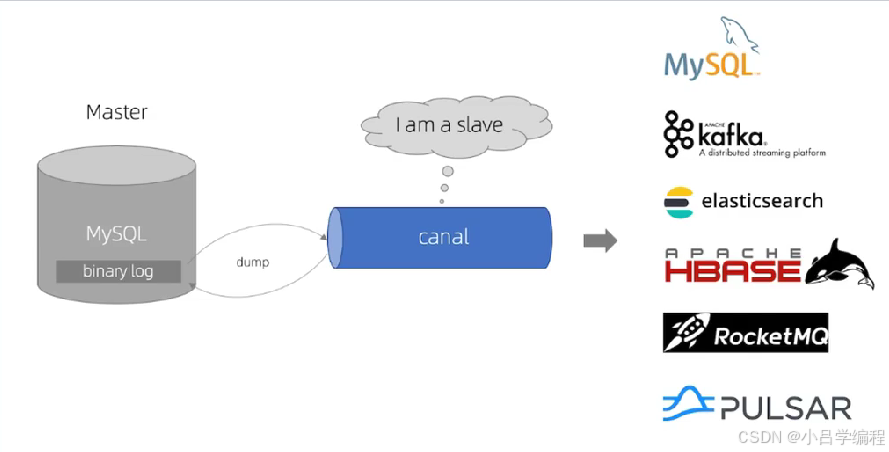
应用场景
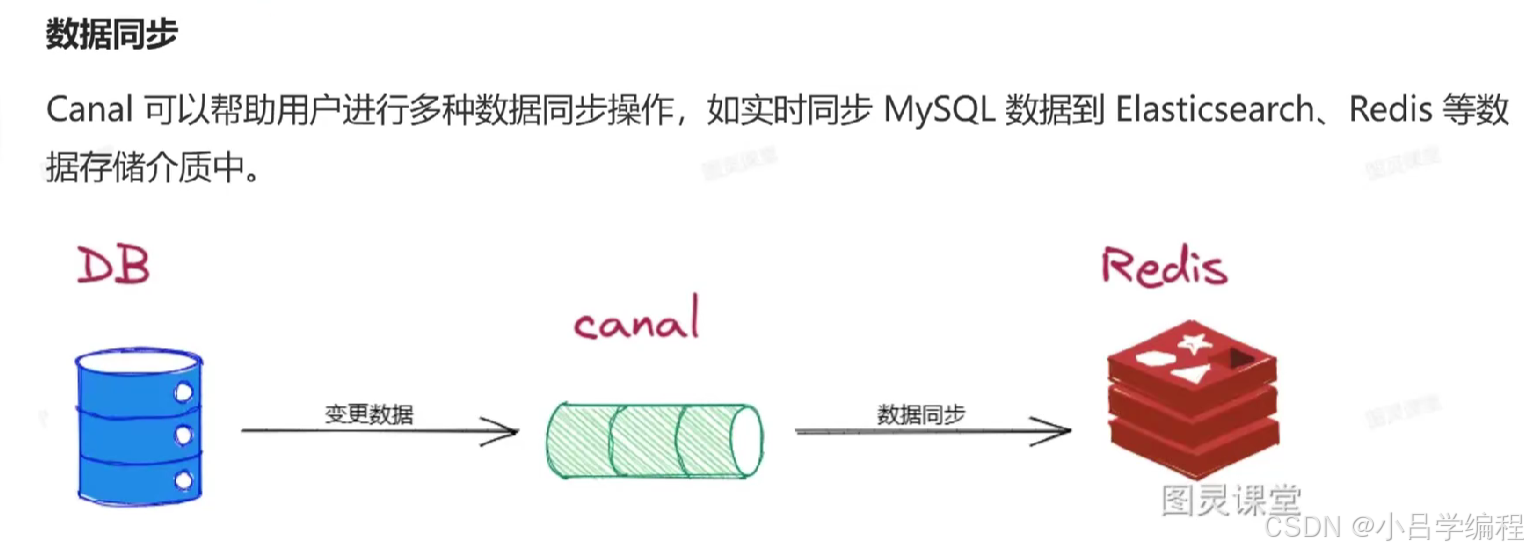
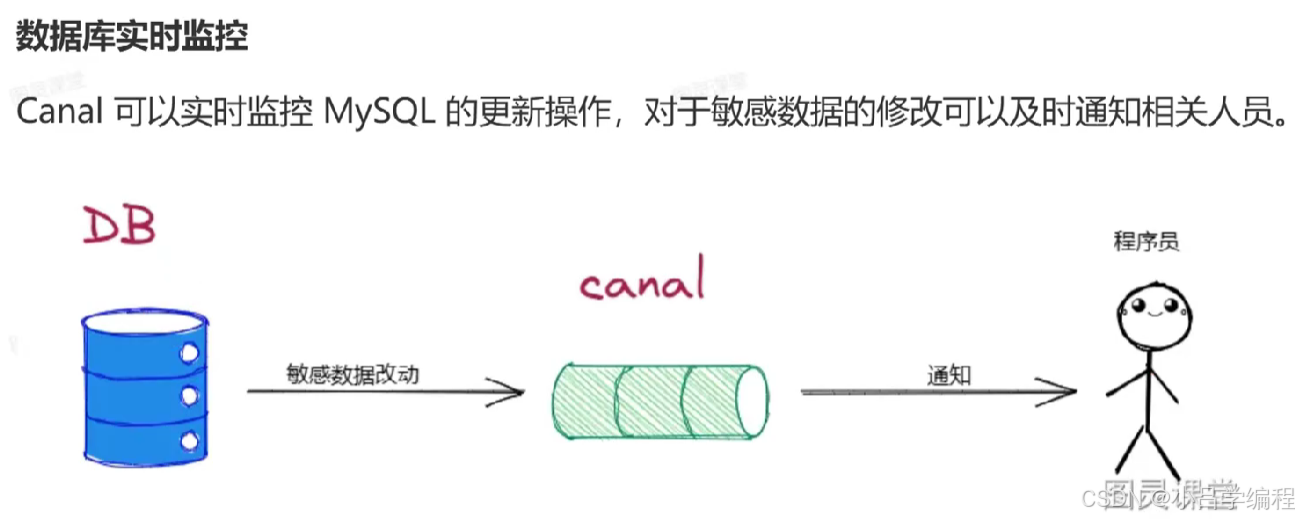
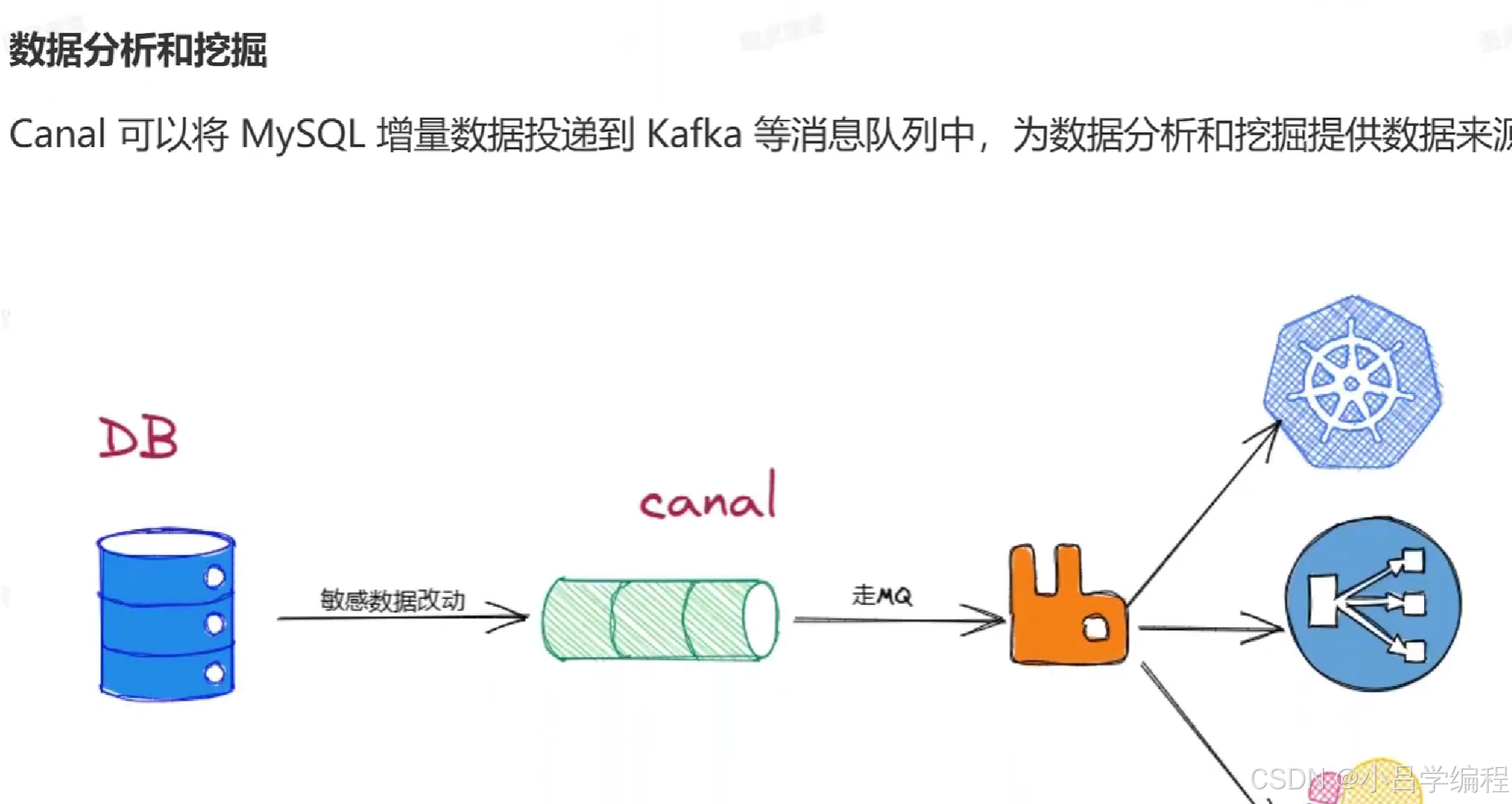
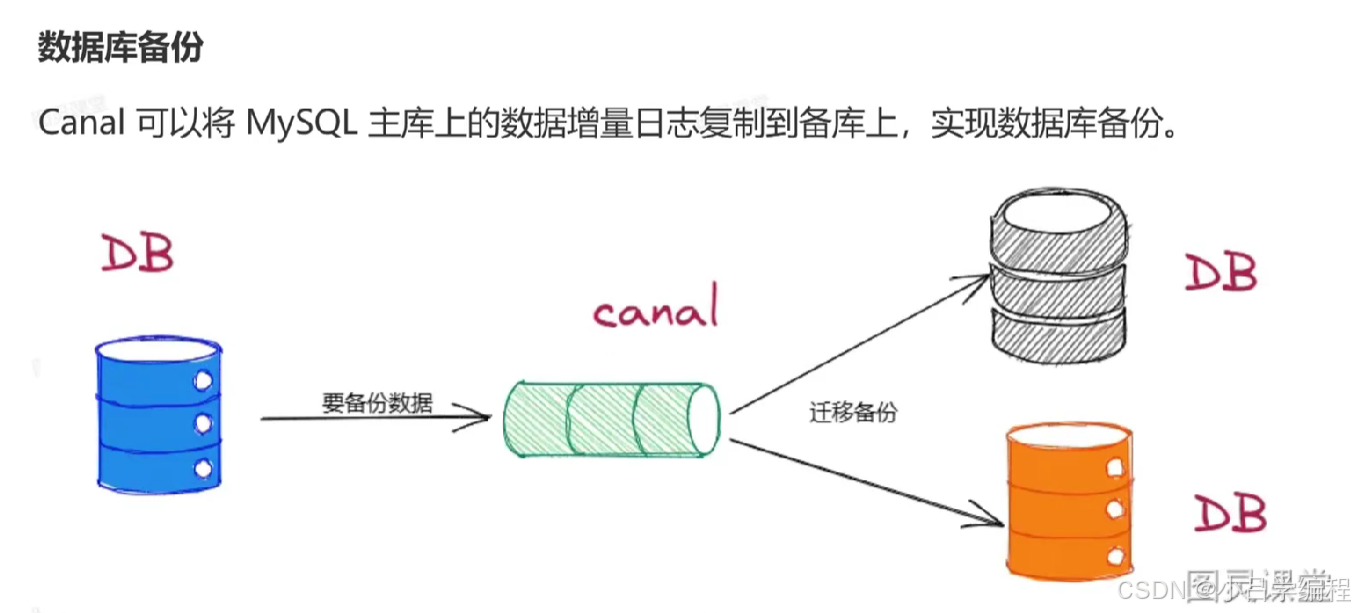
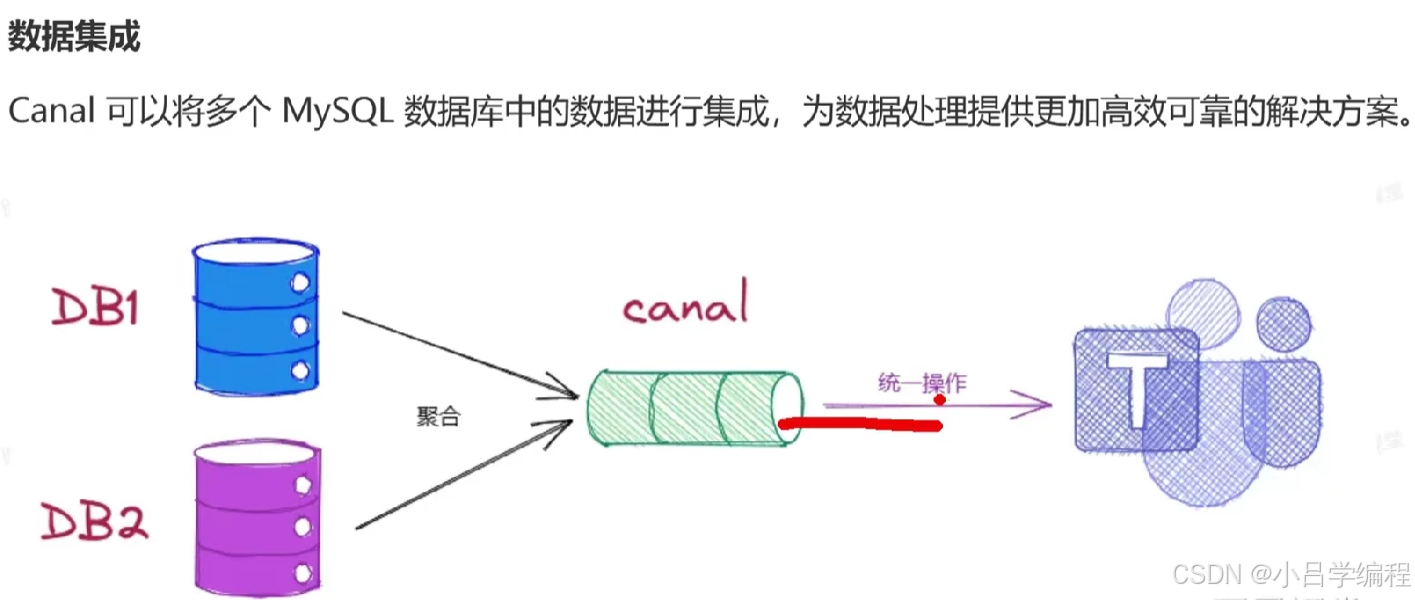
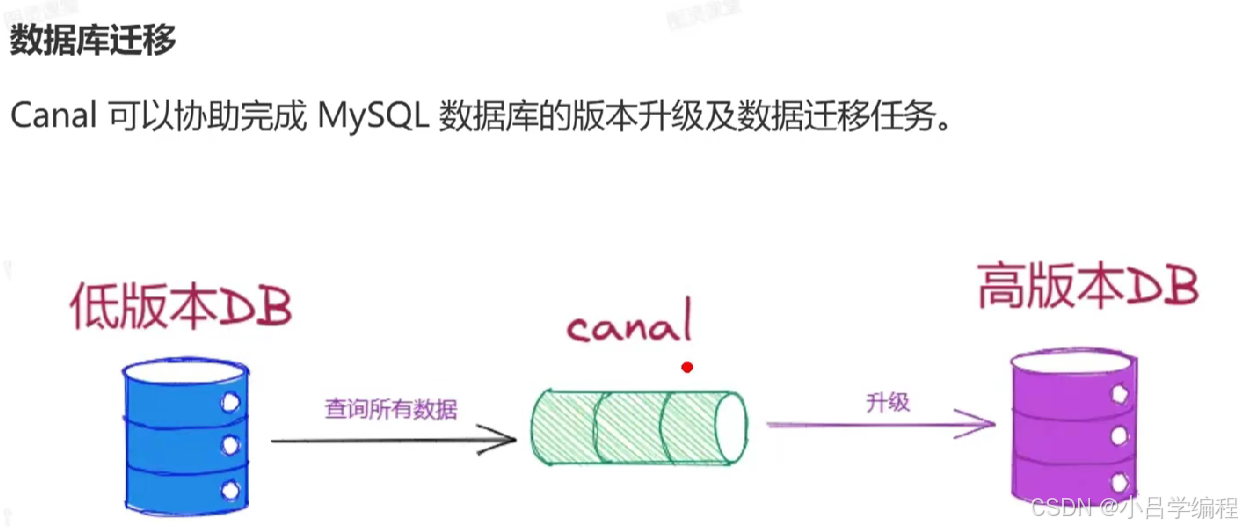
安装
windows版本
kafka和zookepeer安装和配置
这几篇文章有着安装详细步骤和安装中问题的解决方案,写的很棒!!
这里着重讲一下配置和创建所需的topic步骤~
bash
windows中:(都使用管理员cmd)
1.运行zoopker
执行:zkserver
2.运行kafka
进入:
cd D:\QT\canal\kafka
运行:
.\bin\windows\kafka-server-start.bat .\config\server.properties
创建topic
进入:
D:\QT\canal\kafka\bin\windows
执行命令:创建canal-test主题
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic canal-test
查看:
kafka-topics.bat --bootstrap-server localhost:9092 --listcanal安装和配置
提供安装包需要可以拿去(注意:版本是1.1.4的,对应的mysql版本是5.7的),版本不匹配大家可以去官网安装
链接: https://pan.baidu.com/s/12ryIoh0YTuiYAF5YRsVy9g?pwd=pd8b
提取码: pd8b
第一步:解压缩
第二步:配置文件
D:\QT\canal\canal.deployer-1.1.4\conf\canal.properties
修改这几个配置:
#支持rocketmq、tcp、kafka三种模式
canal.serverMode = kafka
#kafka的topic名称
canal.destinations = canal-test
#kafka的端口地址
canal.mq.servers = localhost:9092
D:\QT\canal\canal.deployer-1.1.4\conf\example\instance.properties
修改这几个配置:
#binlog监听文件
canal.instance.master.journal.name=mysql-bin.000010
#用户名(可以自己创建用户,我这里使用默认的)
canal.instance.dbUsername=root
#密码
canal.instance.dbPassword=lyt123456@
#监听表库
canal.instance.filter.regex=.*\\..*
#kafka的topic名称
canal.mq.topic=canal-test
docker版本
compose安装mysq、kafka、zookepeer
参考文档
使用docker-compose 部署 MySQL(所有版本通用)_docker compose mysql-CSDN博客
编写docker-compose.yml
使用 vim docker-compose.yml 将以下数据添加进去
bash
version: '3'
services:
mysql:
image: mysql:5.7
container_name: mysql5
environment:
- MYSQL_ROOT_PASSWORD=lyt123456@
volumes:
- /home/docker/mysql8/log:/var/log/mysql
- /home/docker/mysql8/data:/var/lib/mysql
- /home/docker/mysql8/conf.d:/etc/mysql/conf.d
- /etc/localtime:/etc/localtime:ro
ports:
- 3306:3306
restart: always
zookeeper:
image: zookeeper:3.4.14
container_name: zookeeper
ports:
- "2181:2181"
volumes:
- ./zookeeper/data:/data
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zookeeper:2888:3888
kafka:
image: wurstmeister/kafka:2.13-2.8.1
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://47.108.199.244:9092 # 替换为实际IP:cite[8]:cite[6]
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true' # 自动创建Topic:cite[8]
volumes:
- /var/run/docker.sock:/var/run/docker.sock # 容器管理权限:cite[7]
- ./kafka/logs:/kafka
depends_on:
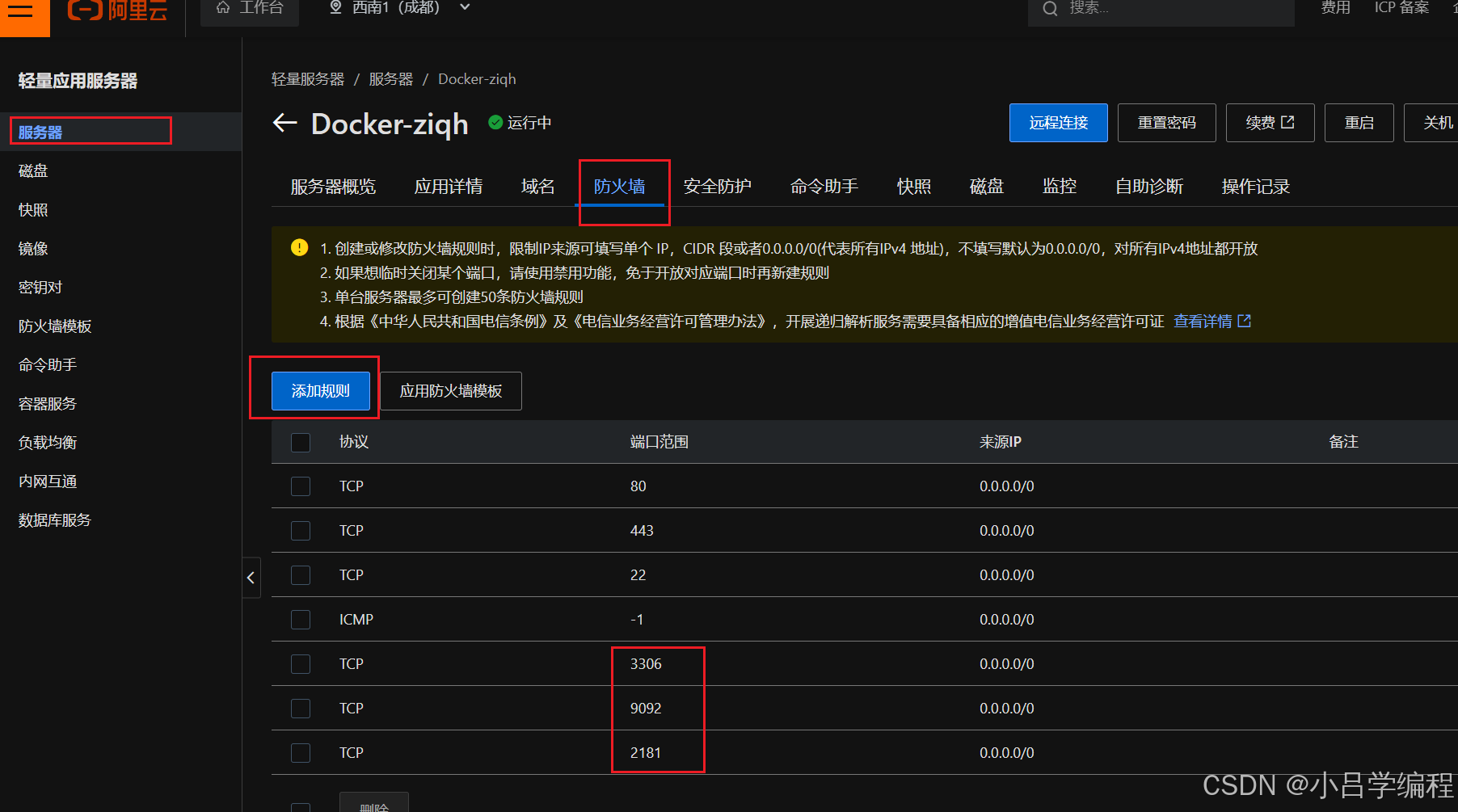
- zookeeper防火墙开启端口访问权限
docker pull拉取失败使用阿里镜像
获取阿里云镜像加速器地址:
-
登录 阿里云容器镜像服务控制台
-
左侧菜单选择「镜像工具」→「镜像加速器」
-
复制专属加速器地址(需阿里云账号)
bash
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://[你的镜像地址].aliyuncs.com"]
}
EOF启动
docker-compose -f docker-compose.yml up -d
查看
docker ps

canal安装
注意:canal依赖jdk,先下载jdk
链接: https://pan.baidu.com/s/1uiJXmGQsTT_lxLyDajj6DQ?pwd=vuha
提取码: vuha
注意:mysql5.7版本使用百度网盘提供的canal版本,其余的官网自行下载
第一步:下载并解压 Canal
bash
tar -zxvf canal.deployer-1.1.7.tar.gz第二步:修改 Canal 配置
上面有配置修改信息哦,直接进入修改就ok啦~~~~
第三步:启动 Canal
bash
# 进入 Canal 部署目录
cd /path/to/canal
sh bin/startup.sh第四步:查看是否启动
如果输出包含 CanalLauncher,说明 Canal 已启动
bash
jps -l | grep canalSpringboot项目实战
第一步:创建springboot项目
第二步:添加配置文件
bash
#数据库配置
spring:
datasource:
url: jdbc:mysql://47.108.199.244:3306/canal?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: lyt123456@
driver-class-name: com.mysql.jdbc.Driver
kafka:
bootstrap-servers: 127.0.0.1:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: cache-group
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer第三步:导入依赖
XML
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.66</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>第四步:消费者定义
java
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class KafkaMsg {
@KafkaListener(topics = "canal-test", groupId = "cache-group")
public void handleMessage(ConsumerRecord<?, ?> cus) {
try {
System.out.println(cus);
} catch (Exception e) {
e.printStackTrace();
}
}
}第五步:验证
执行:
UPDATE user SET name = 'name6' WHERE id = 1;
打断点后会进入到消费者中消费信息啦~~~
输出数据格式:
java
{
"data": [{
"id": "1",
"name": "name6"
}
],
"database": "canal",
"es": 1744815531000,
"id": 2,
"isDdl": false,
"mysqlType": {
"id": "bigint(20)",
"name": "varchar(255)"
},
"old": [{
"name": "name8"
}
],
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": -5,
"name": 12
},
"table": "user",
"ts": 1744815532842,
"type": "UPDATE"
}如果到这个时候依旧不能成功监听到数据表中变化的数据,那就拆分检查一下
binlog -> canal -> kafka
1.首先检查一下 binlog -> canal 链路是否通
- binlog日志是否开启
- 模式是否为ROW
- 如果还不行就拆开跑这一个链路是否成功(更改 canal.serverMode 为 tcp,使用下面的代码验证)
2.kafka
- 自己写个生产者和消费者看是否可以触发
bug得靠自己去解决啦!!!!程序员只有自己救自己~~~~~
java
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
import java.net.InetSocketAddress;
import java.util.List;
@Component
public class CannalClient implements InitializingBean {
private final static int BATCH_SIZE = 1000;
@Override
public void afterPropertiesSet() throws Exception {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
try {
//打开连接
connector.connect();
//订阅数据库表,全部表
connector.subscribe(".*\\..*");
//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();
while (true) {
// 获取指定数量的数据
Message message = connector.getWithoutAck(BATCH_SIZE);
//获取批量ID
long batchId = message.getId();
//获取批量的数量
int size = message.getEntries().size();
//如果没有数据
if (batchId == -1 || size == 0) {
try {
//线程休眠2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//如果有数据,处理数据
printEntry(message.getEntries());
}
//进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。
connector.ack(batchId);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
}
/**
* 打印canal server解析binlog获得的实体类信息
*/
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
//开启/关闭事务的实体类型,跳过
continue;
}
//RowChange对象,包含了一行数据变化的所有特征
//比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等
RowChange rowChage;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
//获取操作类型:insert/update/delete类型
EventType eventType = rowChage.getEventType();
//打印Header信息
System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
//判断是否是DDL语句
if (rowChage.getIsDdl()) {
System.out.println("================》;isDdl: true,sql:" + rowChage.getSql());
}
//获取RowChange对象里的每一行数据,打印出来
for (RowData rowData : rowChage.getRowDatasList()) {
//如果是删除语句
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
//如果是新增语句
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
//如果是更新的语句
} else {
//变更前的数据
System.out.println("------->; before");
printColumn(rowData.getBeforeColumnsList());
//变更后的数据
System.out.println("------->; after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}补充
这是我在写这个demo的时候用的命令,大家可以看看有没有可以用的
bash
#更新数据
UPDATE user SET name = 'name6' WHERE id = 1;
#查看开关是否打开
SHOW VARIABLES LIKE 'log_bin';
#binlog模式
SHOW VARIABLES LIKE 'binlog_format';
#文件位置
SHOW MASTER STATUS;
#创建用户
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'47.108.199.244' IDENTIFIED BY 'lyt123456@' WITH GRANT OPTION;
FLUSH PRIVILEGES;
-- 查看用户权限
SHOW GRANTS FOR 'canal'@'%';
-- 使用命令登录:mysql -u root -p
-- 创建用户 用户名:canal 密码:Canal@123456
create user 'canal'@'%' identified by 'Canal@123456';
-- 授权 *.*表示所有库
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by 'Canal@123456';
cd /home/canal/bin
sh stop.sh
sh startup.sh
jps -l | grep canal
cd /home/canal/logs/canal
tail -f canal.log
docker-compose -f docker-compose.yml up -d
docker ps
docker exec -it 515cfc22985a bash
mysql -u root -p
SELECT User, Host FROM mysql.user;
DROP USER 'test1'@'localhost';
47.108.199.244
CREATE USER 'root'@'%' IDENTIFIED BY '你的新密码'; -- 替换 '你的新密码' 为实际密码
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
docker
kafka-topics.sh --create \
--bootstrap-server 47.108.199.244:9092 \
--replication-factor 1 \
--partitions 1 \
--topic canal-topic-2
kafka-topics.sh --list --bootstrap-server 47.108.199.244:9092
windows:
运行zoopker
zkserver
运行kafka
cd D:\QT\canal\kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
创建topic
D:\QT\canal\kafka\bin\windows
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic canal-test
kafka-topics.bat --bootstrap-server localhost:9092 --list