首先创建一个文件,1.py,2.pytemplates/fruilt,我的程序是3.py,4.py.这个无所谓,自己命名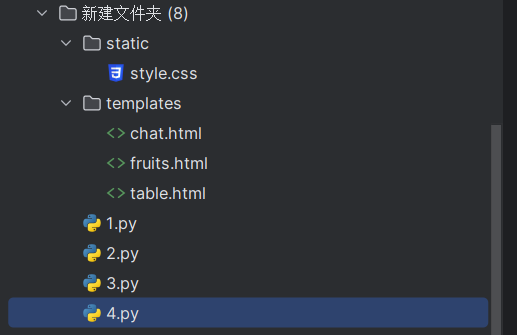
爬取的网站是
https://www.guo68.com网站页面如下,读者可以自行了解
下面是爬取代码(完整版)
import requests
from bs4 import BeautifulSoup
import concurrent.futures
import threading
from tqdm import tqdm
import pandas as pd
import time
from urllib.parse import quote
#水果爬虫
# 定义基本URL模板
base_url_template = "https://www.guo68.com/sell?kw={}&page="
# 支持爬取的水果列表及其中文名称映射
FRUIT_MAPPING = {
'1': ('xigua', '西瓜'),
'2': ('pingguo', '苹果'),
'3': ('chengzi', '橙子'),
'4': ('xiangjiao', '香蕉'),
'5': ('putao', '葡萄')
}
# 定义请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"Referer": "https://www.guo68.com/",
}
data = []
data_lock = threading.Lock()
def get_fruit_choice():
"""获取用户选择的水果"""
print("请选择要爬取的水果(可多选,用逗号分隔):")
for num, (eng, chs) in FRUIT_MAPPING.items():
print(f"{num}. {chs}")
while True:
choices = input("请输入编号(例如 1,3): ").split(',')
valid_choices = [c for c in choices if c in FRUIT_MAPPING]
if valid_choices:
return [FRUIT_MAPPING[c] for c in valid_choices]
print("输入无效,请重新选择!")
def fetch_page(fruit_info, page, retries=3):
"""爬取指定水果和页码的数据"""
eng_name, chs_name = fruit_info
encoded_name = quote(chs_name) # URL编码中文名
url = base_url_template.format(encoded_name) + str(page)
for attempt in range(retries):
try:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
return parse_html(response.text, chs_name)
except Exception as e:
print(f"请求失败: {chs_name}第{page}页,尝试重试 ({attempt + 1}/{retries})...")
time.sleep(2)
return []
def parse_html(html, fruit_type):
"""解析HTML并提取数据"""
soup = BeautifulSoup(html, 'lxml')
items = soup.find_all('li', class_='fruit')
page_data = []
for item in items:
try:
info = {
'种类': fruit_type,
'价格': item.find('span', class_='price').get_text(strip=True),
'名称': item.find('span', class_='name').get_text(strip=True),
'描述': item.find('p', class_='describe').get_text(strip=True),
'地址': item.find('p', class_='address').get_text(strip=True),
'认证': item.find('span', class_='simin').get_text(strip=True)
}
page_data.append(info)
except AttributeError as e:
continue
return page_data
def worker(params):
"""多线程工作函数"""
fruit_info, page = params
page_data = fetch_page(fruit_info, page)
with data_lock:
data.extend(page_data)
def main():
# 获取用户输入
selected_fruits = get_fruit_choice()
pages = int(input("请输入每类水果要爬取的页数:"))
# 准备任务参数
task_params = []
for fruit in selected_fruits:
for page in range(1, pages + 1):
task_params.append((fruit, page))
# 多线程爬取
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as executor:
list(tqdm(executor.map(worker, task_params),
total=len(task_params),
desc="爬取进度",
unit="页"))
# 保存结果
if data:
df = pd.DataFrame(data)
timestamp = time.strftime("%Y%m%d%H%M", time.localtime())
# 保存为CSV
csv_file = f'水果数据_{timestamp}.csv'
df.to_csv(csv_file, index=False, encoding='utf_8_sig')
# 保存为Excel
excel_file = f'水果数据_{timestamp}.xlsx'
df.to_excel(excel_file, index=False)
print(f"数据已保存: {csv_file} 和 {excel_file}")
print(f"共爬取 {len(df)} 条记录,种类分布:")
print(df['种类'].value_counts())
else:
print("没有爬取到有效数据")
if __name__ == "__main__":
main()需要安装库pip install requests beautifulsoup4 pandas tqdm openpyxl
运行之后会生成
读者要 换成自己的储存地址的话问ai,这里程序默认和程序同文件夹目录下
下面是flask后端主程序用来构建网页
from flask import Flask, render_template, request
import pandas as pd
import os
from datetime import datetime
app = Flask(__name__)
# 配置数据路径(使用原始字符串处理Windows路径)
DATA_DIR = r"C:\Users\林\Desktop\FLASK与mysql\新建文件夹 (8)"
CSV_PREFIX = "水果数据_"
def get_latest_data():
"""获取最新的CSV文件"""
csv_files = [f for f in os.listdir(DATA_DIR) if f.startswith(CSV_PREFIX) and f.endswith('.csv')]
if not csv_files:
return None, None
# 按修改时间排序获取最新文件
latest_file = max(csv_files, key=lambda f: os.path.getmtime(os.path.join(DATA_DIR, f)))
file_path = os.path.join(DATA_DIR, latest_file)
modify_time = datetime.fromtimestamp(os.path.getmtime(file_path))
return file_path, modify_time
@app.route('/', methods=['GET', 'POST'])
def index():
# 获取最新数据文件
data_path, modify_time = get_latest_data()
if not data_path:
return "未找到数据文件,请先运行爬虫程序"
# 读取数据
try:
df = pd.read_csv(data_path, encoding='utf-8-sig')
except Exception as e:
return f"读取数据失败: {str(e)}"
# 处理搜索
search_term = request.form.get('search', '').lower()
if search_term:
mask = df.apply(lambda row: row.astype(str).str.lower().str.contains(search_term).any(), axis=1)
results = df[mask]
else:
results = df
return render_template('fruits.html',
data=results.to_dict(orient='records'),
search_term=search_term,
update_time=modify_time.strftime('%Y-%m-%d %H:%M:%S'),
total=len(df),
showing=len(results))
if __name__ == '__main__':
app.run(debug=True, port=5000)fruits.html代码
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>多品种水果数据看板</title>
<link href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/5.1.3/css/bootstrap.min.css" rel="stylesheet">
<link rel="stylesheet" href="https://cdn.datatables.net/1.13.6/css/dataTables.bootstrap5.min.css">
<style>
.dashboard-header {
background: linear-gradient(45deg, #4CAF50, #8BC34A);
color: white;
padding: 2rem;
margin-bottom: 2rem;
border-radius: 8px;
}
.stats-card {
background: white;
border-radius: 8px;
padding: 1rem;
margin-bottom: 1rem;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
.highlight {
color: #4CAF50;
font-weight: bold;
}
</style>
</head>
<body>
<div class="container-fluid">
<!-- 数据看板头部 -->
<div class="dashboard-header">
<h1>多品种水果市场实时数据</h1>
<div class="update-time">最后更新: {{ update_time }}</div>
</div>
<!-- 统计卡片 -->
<div class="row">
<div class="col-md-4">
<div class="stats-card">
总数据量 <span class="highlight">{{ total }}</span> 条
</div>
</div>
<div class="col-md-4">
<div class="stats-card">
当前显示 <span class="highlight">{{ showing }}</span> 条
</div>
</div>
</div>
<!-- 搜索框 -->
<div class="card mb-4">
<div class="card-body">
<form method="post">
<div class="input-group">
<input type="text" class="form-control" name="search"
placeholder="输入水果名称、种类、价格范围或地址搜索..."
value="{{ search_term }}">
<button type="submit" class="btn btn-success">智能搜索</button>
</div>
<small class="form-text text-muted mt-2">
示例搜索:苹果 | 5元 | 北京 | 已认证
</small>
</form>
</div>
</div>
<!-- 数据表格 -->
<div class="card">
<div class="card-body">
<table class="table table-hover" id="dataTable">
<thead>
<tr>
<th>种类</th>
<th>名称</th>
<th>价格</th>
<th>地址</th>
<th>认证状态</th>
<th>详细描述</th>
</tr>
</thead>
<tbody>
{% for item in data %}
<tr>
<td>{{ item.种类 }}</td>
<td>{{ item.名称 }}</td>
<td class="text-success">{{ item.价格 }}</td>
<td>{{ item.地址 }}</td>
<td>
<span class="badge rounded-pill bg-{% if item.认证 == '已认证' %}success{% else %}warning text-dark{% endif %}">
{{ item.认证 }}
</span>
</td>
<td>{{ item.描述 }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
<!-- 脚本 -->
<script src="https://code.jquery.com/jquery-3.7.0.min.js"></script>
<script src="https://cdn.datatables.net/1.13.6/js/jquery.dataTables.min.js"></script>
<script src="https://cdn.datatables.net/1.13.6/js/dataTables.bootstrap5.min.js"></script>
<script>
$(document).ready(function() {
$('#dataTable').DataTable({
"language": {
"url": "//cdn.datatables.net/plug-ins/1.13.6/i18n/zh-CN.json"
},
"dom": '<"row"<"col-sm-12 col-md-6"l><"col-sm-12 col-md-6"f>>rt<"row"<"col-sm-12 col-md-5"i><"col-sm-12 col-md-7"p>>',
"pageLength": 25,
"order": [[2, 'asc']]
});
});
</script>
</body>
</html>