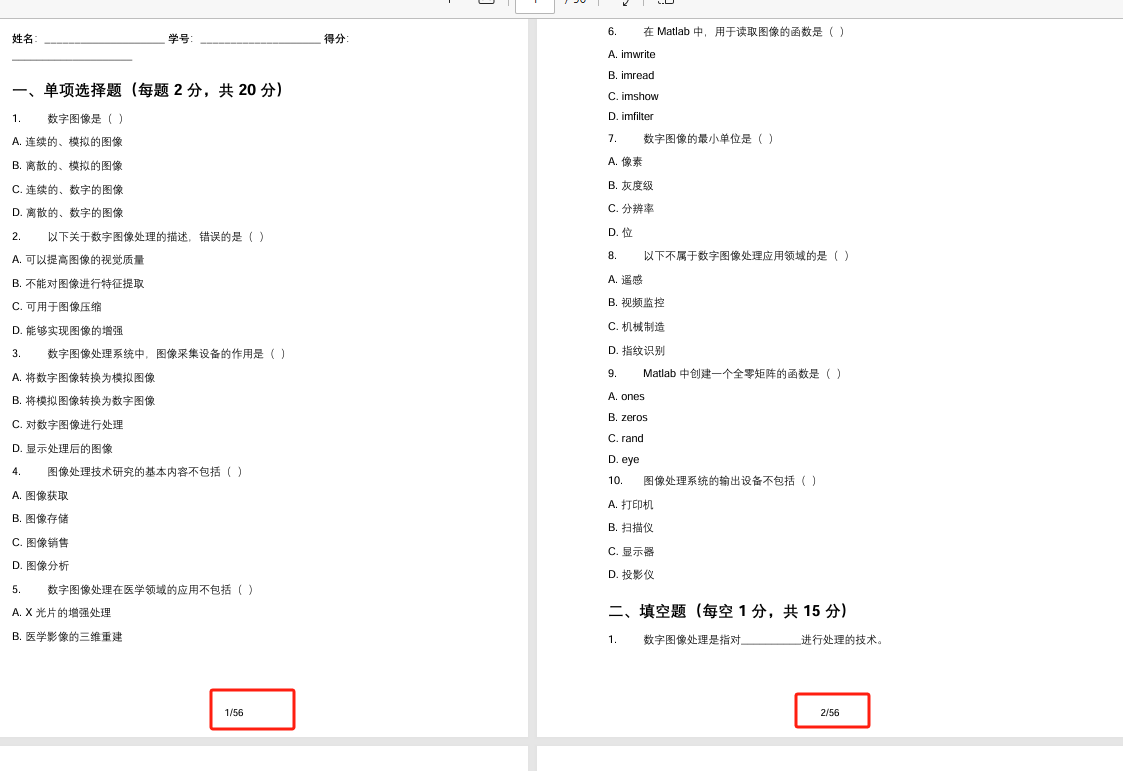
'''
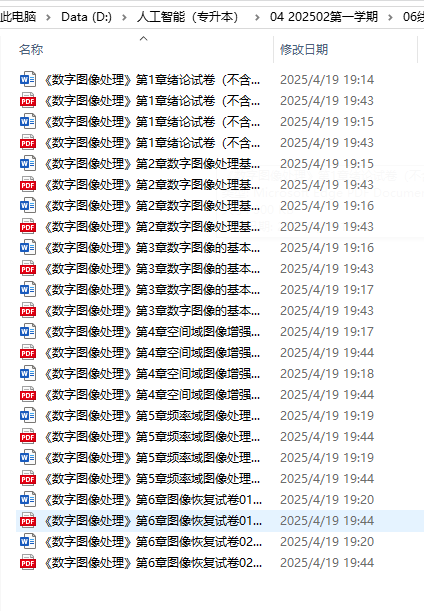
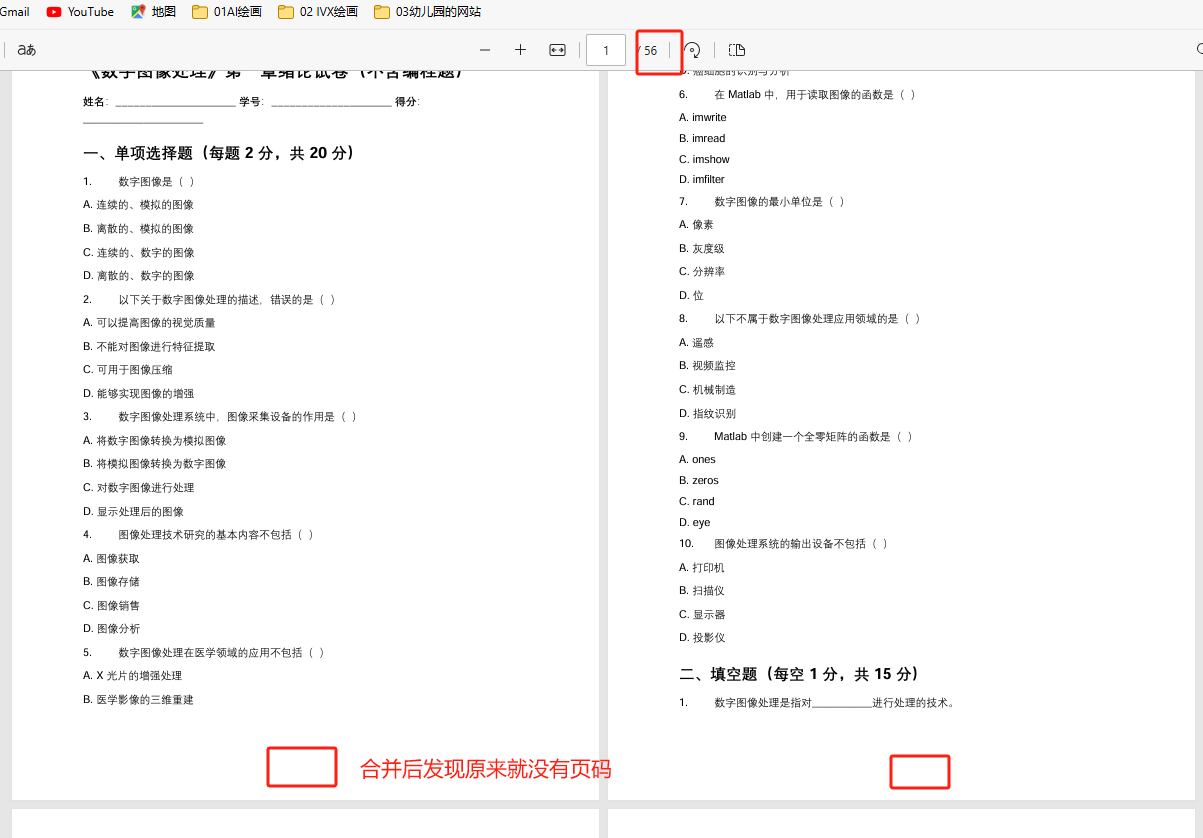
上师大继续教育人工智能-数字图像处理复习题合并+pdf页码
deepseek,阿夏
20250419
'''
import os
from docx2pdf import convert
from PyPDF2 import PdfReader, PdfWriter
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
import io
def convert_docx_to_pdf(input_folder):
"""将指定文件夹中的所有DOCX文件转换为PDF"""
for filename in os.listdir(input_folder):
if filename.lower().endswith('.docx'):
docx_path = os.path.join(input_folder, filename)
try:
print(f"正在转换: {filename}")
convert(docx_path, docx_path.replace('.docx', '.pdf'))
print(f"转换完成: {filename}")
except Exception as e:
print(f"转换 {filename} 时出错: {e}")
def create_page_num_pdf(page_num, total_pages, pagesize):
"""创建包含页码的单个PDF页面"""
packet = io.BytesIO()
# 确保pagesize是float类型
if hasattr(pagesize, '__iter__'):
pagesize = (float(pagesize[0]), float(pagesize[1]))
else:
pagesize = letter
can = canvas.Canvas(packet, pagesize=pagesize)
# 设置页码文本 (底部居中)
text = f"{page_num}/{total_pages}"
width, height = pagesize
can.setFont("Helvetica", 10) # 设置字体和大小
can.drawCentredString(width / 2, 20, text) # 在底部居中位置绘制页码
can.save()
packet.seek(0)
return PdfReader(packet)
def add_page_numbers(input_pdf_path, output_pdf_path):
"""为PDF文件添加页码"""
reader = PdfReader(input_pdf_path)
writer = PdfWriter()
total_pages = len(reader.pages)
for page_num in range(total_pages):
# 获取原始页面
page = reader.pages[page_num]
# 获取页面尺寸并确保是float类型
if '/MediaBox' in page:
media_box = page['/MediaBox']
pagesize = (float(media_box[2]), float(media_box[3]))
else:
pagesize = letter # 默认使用letter尺寸
# 创建带页码的PDF
page_num_pdf = create_page_num_pdf(page_num + 1, total_pages, pagesize)
# 将原始页面与页码合并
page.merge_page(page_num_pdf.pages[0])
writer.add_page(page)
# 保存带页码的PDF
with open(output_pdf_path, "wb") as output_pdf:
writer.write(output_pdf)
def merge_pdfs(input_folder, output_folder, output_filename='20250419(合并打印版本)数字图像处理考试.pdf'):
"""合并指定文件夹中的所有PDF文件并添加页码"""
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
merger = PdfWriter()
pdf_files = []
# 收集所有PDF文件
for filename in os.listdir(input_folder):
if filename.lower().endswith('.pdf'):
pdf_path = os.path.join(input_folder, filename)
pdf_files.append(pdf_path)
if not pdf_files:
print("没有找到PDF文件可合并")
return
# 按文件名排序
pdf_files.sort()
# 合并PDF
for pdf in pdf_files:
try:
reader = PdfReader(pdf)
for page in reader.pages:
merger.add_page(page)
print(f"已添加: {os.path.basename(pdf)}")
except Exception as e:
print(f"添加 {pdf} 时出错: {e}")
# 保存临时合并PDF
temp_output_path = os.path.join(output_folder, 'temp_' + output_filename)
final_output_path = os.path.join(output_folder, output_filename)
try:
with open(temp_output_path, "wb") as temp_pdf:
merger.write(temp_pdf)
# 为合并后的PDF添加页码
add_page_numbers(temp_output_path, final_output_path)
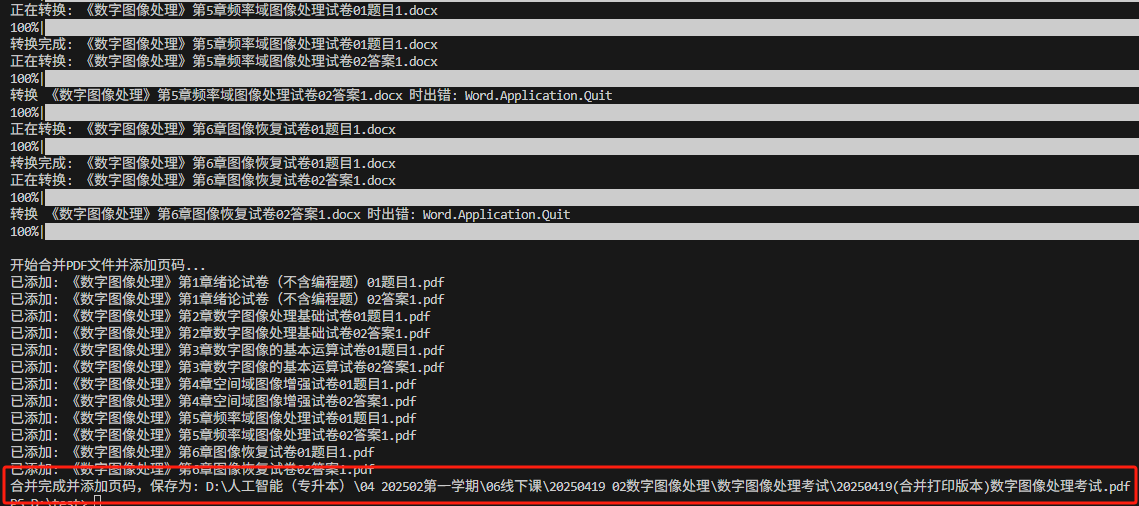
print(f"合并完成并添加页码,保存为: {final_output_path}")
# 删除临时文件
os.remove(temp_output_path)
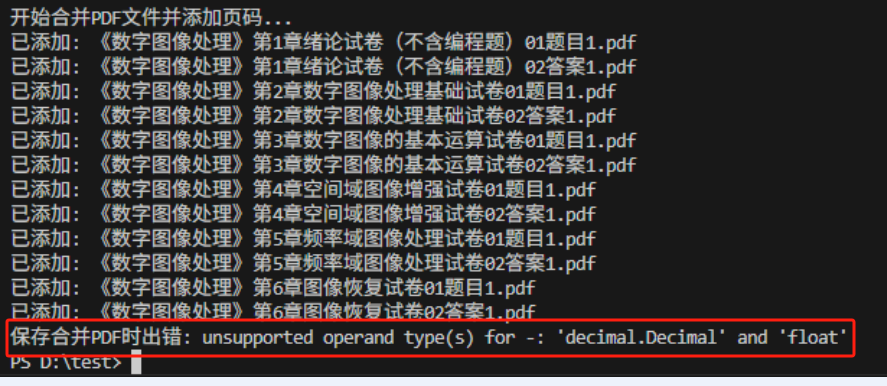
except Exception as e:
print(f"保存合并PDF时出错: {e}")
finally:
pass
def main():
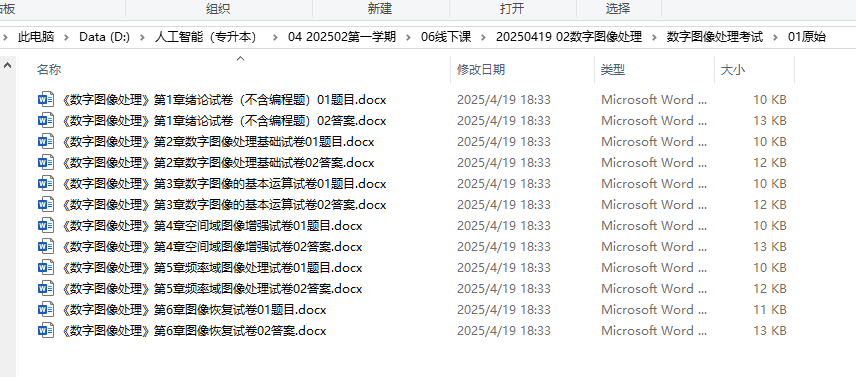
path = r'D:\人工智能(专升本)\04 202502第一学期\06线下课\20250419 02数字图像处理\数字图像处理考试'
input_folder = os.path.join(path, '02处理后')
output_folder = path
# 第一步:转换所有DOCX为PDF
print("开始转换DOCX文件为PDF...")
convert_docx_to_pdf(input_folder)
# 第二步:合并所有PDF并添加页码
print("\n开始合并PDF文件并添加页码...")
merge_pdfs(input_folder, output_folder)
if __name__ == '__main__':
main()