Spark-SQL核心编程(四)
实验内容:
利用IDEA开发Spark-SQL。
实验步骤:
利用IDEA开发Spark-SQL
- 创建子模块Spark-SQL,并添加依赖
<dependency >
<groupId >org.apache.spark</groupId >
<artifactId >spark-sql_2.12</artifactId >
<version >3.0.0</version >
</dependency >
- 创建Spark-SQL的测试代码:
case class User(id:Int,name:String,age:Int)
object SparkSQLDemo {
def main(args: ArrayString): Unit = {
// 创建上下文环境配置对象
val sparkConf = new SparkConf().setMaster("local\*" ).setAppName("SQLDemo" )
// 创建 SparkSession 对象
val spark :SparkSession = SparkSession.builder ().config(sparkConf).getOrCreate()
import spark.implicits._
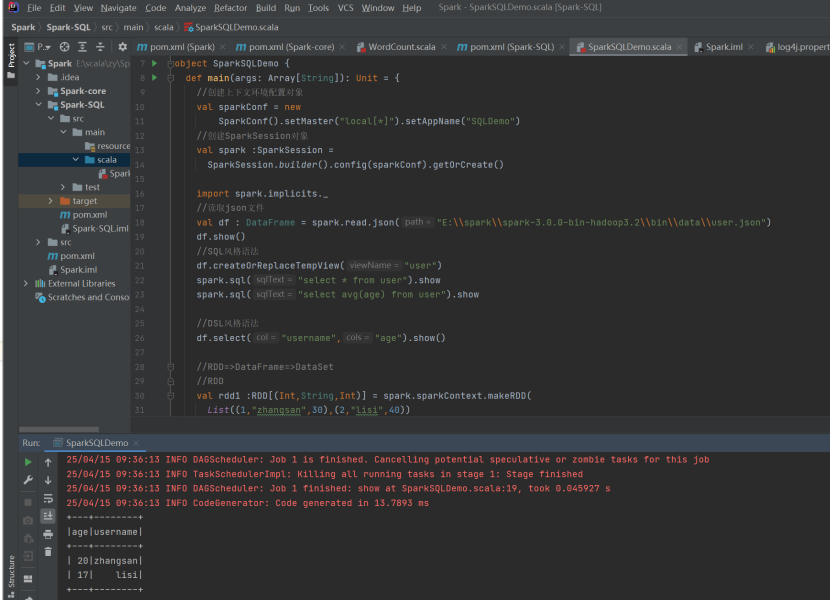
// 读取 json 文件
val df : DataFrame = spark.read.json("Spark-SQL/input/user.json" )
df.show()
//SQL 风格语法
df.createOrReplaceTempView("user" )
spark.sql("select * from user" ).show
spark.sql("select avg(age) from user" ).show
//DSL 风格语法
df.select("username" ,"age" ).show()
//RDD=>DataFrame=>DataSet
//RDD
val rdd1 :RDD(Int,String,Int) = spark.sparkContext.makeRDD(
List ((1,"zhangsan" ,30),(2,"lisi" ,40))
)
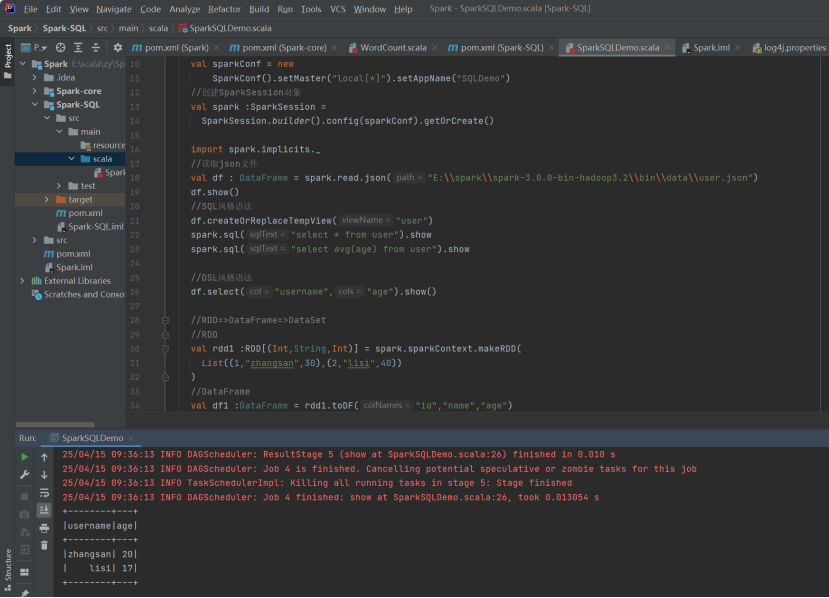
//DataFrame
val df1 :DataFrame = rdd1.toDF("id" ,"name" ,"age" )
df1.show()
//DataSet
val ds1 :DatasetUser = df1.asUser
ds1.show()
//DataSet=>DataFrame=>RDD
val df2 =ds1.toDF()
df2.show()
val rdd2 :RDDRow = df2.rdd
rdd2.foreach(a=>println (a.getString(1)))
rdd1.map{
case (id,name,age)=>User (id,name,age)
}.toDS().show()
val rdd3 = ds1.rdd
rdd3.foreach(a=>println (a.age))
rdd3.foreach(a=>println (a.id))
rdd3.foreach(a=>println (a.name))
spark.stop()
}
}
Spark-SQL核心编程(五)
自定义函数:
UDF:
val sparkConf = new SparkConf().setMaster("local\*" ).setAppName("SQLDemo" )
// 创建 SparkSession 对象
val spark :SparkSession = SparkSession.builder ().config(sparkConf).getOrCreate()
import spark.implicits._
// 读取 json 文件
val df : DataFrame = spark.read.json("Spark-SQL/input/user.json" )
spark.udf.register("addName" ,(x:String)=>"Name:" +x)
df.createOrReplaceTempView("people" )
spark.sql("select addName(username),age from people" ).show()
spark.stop()
UDAF(自定义聚合函数)
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),
countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。Spark3.0之前我们使用的是UserDefinedAggregateFunction作为自定义聚合函数,从 Spark3.0 版本后可以统一采用强类型聚合函数 Aggregator
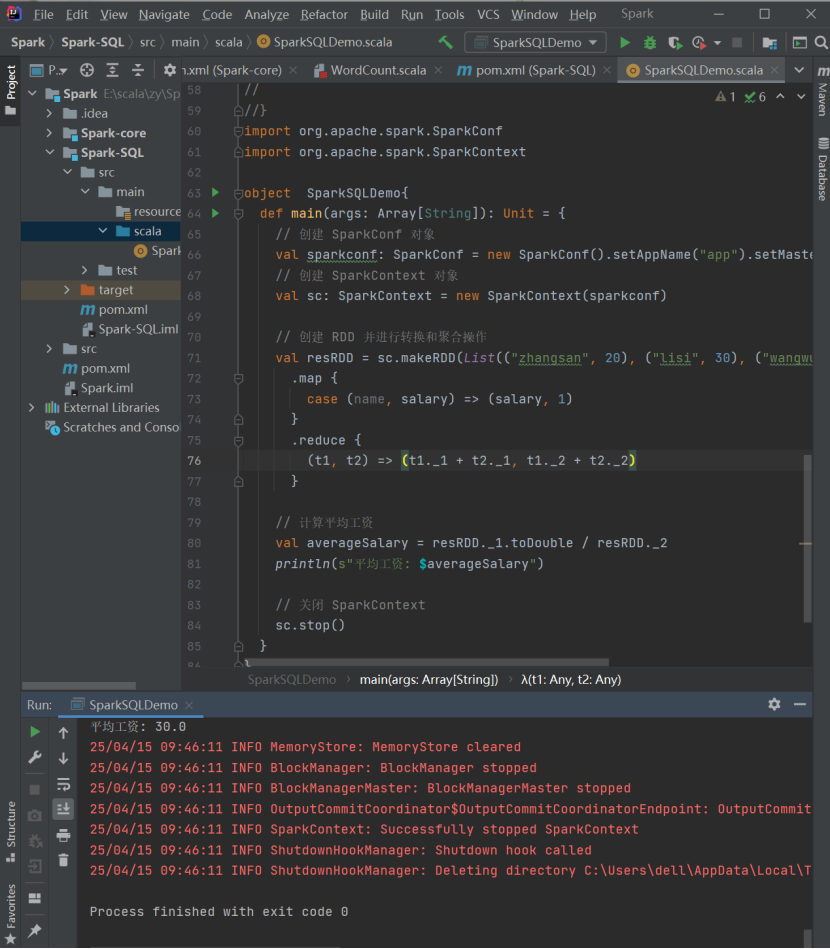
实验需求:计算平均工资
实现方式一:RDD
val sparkconf: SparkConf = new SparkConf().setAppName("app" ).setMaster("local\*" )
val sc: SparkContext = new SparkContext(conf)
val resRDD: (Int, Int) = sc.makeRDD(List (("zhangsan" , 20), ("lisi" , 30), ("wangw u " ,40))).map {
case (name, salary) => {
(salary, 1)
}
}.reduce {
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
}
println (resRDD._1/resRDD._2)
// 关闭连接
sc.stop()
实现方式三:强类型UDAF
case class Buff(var sum:Long,var cnt:Long)
class MyAverageUDAF extends AggregatorLong,Buff,Double{
override def zero: Buff = Buff (0,0)
override def reduce(b: Buff, a: Long): Buff = {
b.sum += a
b.cnt += 1
b
}
override def merge(b1: Buff, b2: Buff): Buff = {
b1.sum += b2.sum
b1.cnt += b2.cnt
b1
}
override def finish(reduction: Buff): Double = {
reduction.sum.toDouble/reduction.cnt
}
override def bufferEncoder: EncoderBuff = Encoders.product
override def outputEncoder: EncoderDouble = Encoders.scalaDouble
}
val sparkconf: SparkConf = new SparkConf().setAppName("app" ).setMaster("local\*" )
val spark:SparkSession = SparkSession.builder ().config(conf).getOrCreate()
import spark.implicits._
val res :RDD(String,Int)= spark.sparkContext.makeRDD(List (("zhangsan" , 20), ("lisi" , 30), ("wangwu" ,40)))
val df :DataFrame = res.toDF("name" ,"salary" )
df.createOrReplaceTempView("user" )
var myAverage = new MyAverageUDAF
// 在 spark 中注册聚合函数
spark.udf.register("avgSalary" ,functions.udaf (myAverage))
spark.sql("select avgSalary(salary) from user" ).show()
// 关闭连接
spark.stop()