前面我们分享了关于大语言模型的相关技术,包括前向推理、LoRa挂载、MoE模型、模型预训练等;后续还是会基于MiniMindLM模型继续分享关于大语言模型的SFT指令微调、LoRa微调、基于人类偏好的强化学习微调以及模型蒸馏相关的技术,请大家持续关注。
一、LLM和VLM推理流程叙述
1.1 LLM
今天我们基于MiniMind-V项目,分享一些关于多模态大模型的相关技术 ;首先我们回顾一下大语言模型是如何进行推理的:
大语言模型LLM推理流程:
- 首先,大语言模型的输入只有文本信息,输入的文本信息会通过分词器(tokenizer)将文本信息对应词汇表转变为tokenID;
- 然后会将转变出来的tokenID送入到词嵌入模型(embedding)进行向量化,将每一个tokenID转变为固定维度的张量,比如512、768维等;
- 转变完成后将其送入transformer模块进行自注意力运算和前馈神经变换,同时通过旋转位置编码的方式将编码信息嵌入到Q、K张量上;
- 进过N个transformer模块,将输出张量映射到词汇表的数量维度;
- 选取最后一个token张量进行softmax归一化运算,将其转化到概率域;
- 通过Top-p的方式选择出对应的预测tokenID,通过分词器将其转换回文本信息,就完成了一轮的推理运算;
- 然后缓存KVcache,拼接新预测的token再次按照上面的流程进行运算,直到预测token为终止符号或者达到上下文的最大长度则停止运算;
1.2 VLM
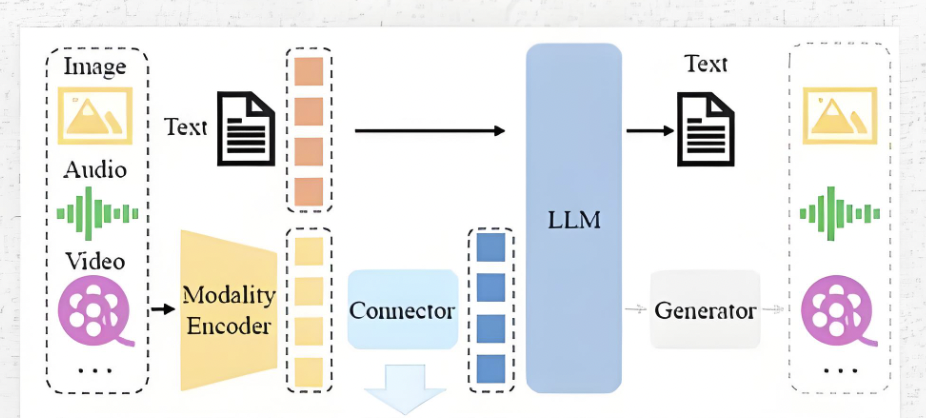
了解了大语言模型的推理流程,我们就可以有针对性的分析多模态VL模型在推理过程上与大语言模型的异同点; 首先在模型输入上有很大的不同,多模态VL模型可以接受图片的输入,然后就是在输入transformer模块之前的分词方式不同和embedding词嵌入方式不同;多模态大模型的整体推理流程如下:
多模态VL模型推理流程:
- 首先,多模态模型的输入是图片路径/URL和文本信息;
- 对于文本信息部分的分词处理大致与大语言模型相同,有一点区别是在送入分词器之前需要在文本信息中添加图片信息的占位符,就是图片的tokenID所对应的文本符号;
- 将添加图片占位符的文本信息进行分词处理,生成tokenID,再送入Embedding词嵌入模型进行向量化;
- 对于图片信息,需要先通过给定的图片路径/URL加载图片到内存;
- 引入CLIP模型,或者其他优化的CLIP结构模型对图片进行分块和特征提取,生成相应数量的token序列,需要注意的是文本信息中的图片占位符的数量需要与图片生成的token序列数量一致;
- 通过一个全链接层将图片的token维度与文本信息的token维度对齐,比如生成的文本token的维度是(N,512),生成图片token的维度是(N,768),需要将图片的token序列进过一个【768,512】维度的一个全链接层,将图片的token维度变为(N,512);
- 通过文本信息的tokenID锁定在文本token张量中图片占位符的起止位置,然后将对齐维度的图片token序列插入到对应的文本token张量中,替换掉原来图片占位符tokenID所生成的张量,这样就将文本张量和图片张量融合为一个张量矩阵;
- 后面的操作就和大语言模型没有什么区别了,送入N个transformer模块进行自注意力计算、旋转位置编码、前馈神经网络运算,预测下一个token,循环往复,直到预测终止符或者达到最大上下文长度停止推理;
二、VLM推理流程源码
项目基于minimind-v,大家自行下载源码和对应模型权重,这里不做过多赘述,下载好后在项目中的一级目录下创建一个jujupyterNotebook文件;项目的推理代码是minimind-v/eval_vlm.py,以下是该脚本的全部代码,我们通过jujupyterNotebook将其拆解;
python
# minimind-v/eval_vlm.py
import argparse
import os
import random
import numpy as np
import torch
import warnings
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
from model.model_vlm import MiniMindVLM
from model.VLMConfig import VLMConfig
from transformers import logging as hf_logging
hf_logging.set_verbosity_error()
warnings.filterwarnings('ignore')
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def init_model(lm_config, device):
tokenizer = AutoTokenizer.from_pretrained('./model/minimind_tokenizer')
if args.load == 0:
moe_path = '_moe' if args.use_moe else ''
modes = {0: 'pretrain_vlm', 1: 'sft_vlm', 2: 'sft_vlm_multi'}
ckp = f'./{args.out_dir}/{modes[args.model_mode]}_{args.dim}{moe_path}.pth'
model = MiniMindVLM(lm_config)
state_dict = torch.load(ckp, map_location=device)
model.load_state_dict({k: v for k, v in state_dict.items() if 'mask' not in k}, strict=False)
else:
transformers_model_path = 'MiniMind2-V'
tokenizer = AutoTokenizer.from_pretrained(transformers_model_path)
model = AutoModelForCausalLM.from_pretrained(transformers_model_path, trust_remote_code=True)
print(f'VLM参数量:{sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6:.3f} 百万')
vision_model, preprocess = MiniMindVLM.get_vision_model()
return model.eval().to(device), tokenizer, vision_model.eval().to(device), preprocess
def setup_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Chat with MiniMind")
parser.add_argument('--lora_name', default='None', type=str)
parser.add_argument('--out_dir', default='out', type=str)
parser.add_argument('--temperature', default=0.65, type=float)
parser.add_argument('--top_p', default=0.85, type=float)
parser.add_argument('--device', default='cuda' if torch.cuda.is_available() else 'cpu', type=str)
# MiniMind2-Small (26M):(dim=512, n_layers=8)
# MiniMind2 (104M):(dim=768, n_layers=16)
parser.add_argument('--dim', default=512, type=int)
parser.add_argument('--n_layers', default=8, type=int)
parser.add_argument('--max_seq_len', default=8192, type=int)
parser.add_argument('--use_moe', default=False, type=bool)
# 默认单图推理,设置为2为多图推理
parser.add_argument('--use_multi', default=1, type=int)
parser.add_argument('--stream', default=True, type=bool)
parser.add_argument('--load', default=0, type=int, help="0: 原生torch权重,1: transformers加载")
parser.add_argument('--model_mode', default=1, type=int,
help="0: Pretrain模型,1: SFT模型,2: SFT-多图模型 (beta拓展)")
args = parser.parse_args()
lm_config = VLMConfig(dim=args.dim, n_layers=args.n_layers, max_seq_len=args.max_seq_len, use_moe=args.use_moe)
model, tokenizer, vision_model, preprocess = init_model(lm_config, args.device)
def chat_with_vlm(prompt, pixel_tensors, image_names):
messages = [{"role": "user", "content": prompt}]
new_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)[-args.max_seq_len + 1:]
print(f'[Image]: {image_names}')
with torch.no_grad():
x = torch.tensor(tokenizer(new_prompt)['input_ids'], device=args.device).unsqueeze(0)
outputs = model.generate(
x,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=args.max_seq_len,
temperature=args.temperature,
top_p=args.top_p,
stream=True,
pad_token_id=tokenizer.pad_token_id,
pixel_tensors=pixel_tensors
)
print('🤖️: ', end='')
try:
if not args.stream:
print(tokenizer.decode(outputs.squeeze()[x.shape[1]:].tolist(), skip_special_tokens=True), end='')
else:
history_idx = 0
for y in outputs:
answer = tokenizer.decode(y[0].tolist(), skip_special_tokens=True)
if (answer and answer[-1] == '�') or not answer:
continue
print(answer[history_idx:], end='', flush=True)
history_idx = len(answer)
except StopIteration:
print("No answer")
print('\n')
# 单图推理:每1个图像单独推理
if args.use_multi == 1:
image_dir = './dataset/eval_images/'
prompt = f"{model.params.image_special_token}\n描述一下这个图像的内容。"
for image_file in os.listdir(image_dir):
image = Image.open(os.path.join(image_dir, image_file)).convert('RGB')
pixel_tensors = MiniMindVLM.image2tensor(image, preprocess).to(args.device).unsqueeze(0)
chat_with_vlm(prompt, pixel_tensors, image_file)
# 2图推理:目录下的两个图像编码,一次性推理(power by )
if args.use_multi == 2:
args.model_mode = 2
image_dir = './dataset/eval_multi_images/bird/'
prompt = (f"{lm_config.image_special_token}\n"
f"{lm_config.image_special_token}\n"
f"比较一下两张图像的异同点。")
pixel_tensors_multi = []
for image_file in os.listdir(image_dir):
image = Image.open(os.path.join(image_dir, image_file)).convert('RGB')
pixel_tensors_multi.append(MiniMindVLM.image2tensor(image, preprocess))
pixel_tensors = torch.cat(pixel_tensors_multi, dim=0).to(args.device).unsqueeze(0)
# 同样内容重复10次
for _ in range(10):
chat_with_vlm(prompt, pixel_tensors, (', '.join(os.listdir(image_dir))))2.1 导包
代码:
python
import argparse
import os
import random
import numpy as np
import torch
import warnings
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
from model.model_vlm import MiniMindVLM
from model.VLMConfig import VLMConfig
from transformers import logging as hf_logging
hf_logging.set_verbosity_error()
warnings.filterwarnings('ignore')2.2 定义超参类
代码:
python
class Args():
def __init__(self):
self.lora_name = None
self.out_dir = 'out'
self.temperature = 0.65
self.top_p = 0.85
self.device = 'cpu'
self.dim = 512
self.n_layers = 8
self.max_seq_len = 8192
self.use_moe = False
self.use_multi = 1
self.stream = True
self.load = 0
self.model_mode = 1
args = Args()2.3 定义模型加载配置参数
这里选择sft_vlm_512.pth权重文件;
代码:
python
lm_config = VLMConfig(dim=args.dim, n_layers=args.n_layers, max_seq_len=args.max_seq_len, use_moe=args.use_moe)2.4 加载VLM模型和分词器
通过代码2的输出结果,我们可以看到VLM模型里面有CLIP模型结构;
代码1:
python
tokenizer = AutoTokenizer.from_pretrained('./model/minimind_tokenizer')
moe_path = '_moe' if args.use_moe else ''
modes = {0: 'pretrain_vlm', 1: 'sft_vlm', 2: 'sft_vlm_multi'}
ckp = f'./{args.out_dir}/MiniMind2-V-PyTorch/{modes[args.model_mode]}_{args.dim}{moe_path}.pth'
model = MiniMindVLM(lm_config)
state_dict = torch.load(ckp, map_location=device)
model.load_state_dict({k: v for k, v in state_dict.items() if 'mask' not in k}, strict=False)代码2:
python
for name, tensor in model.state_dict().items():
print(name)输出结果2:
python
tok_embeddings.weight
layers.0.attention.wq.weight
layers.0.attention.wk.weight
layers.0.attention.wv.weight
layers.0.attention.wo.weight
layers.0.attention_norm.weight
layers.0.ffn_norm.weight
layers.0.feed_forward.w1.weight
layers.0.feed_forward.w2.weight
layers.0.feed_forward.w3.weight
layers.1.attention.wq.weight
layers.1.attention.wk.weight
layers.1.attention.wv.weight
layers.1.attention.wo.weight
layers.1.attention_norm.weight
layers.1.ffn_norm.weight
layers.1.feed_forward.w1.weight
layers.1.feed_forward.w2.weight
layers.1.feed_forward.w3.weight
layers.2.attention.wq.weight
layers.2.attention.wk.weight
layers.2.attention.wv.weight
layers.2.attention.wo.weight
layers.2.attention_norm.weight
layers.2.ffn_norm.weight
layers.2.feed_forward.w1.weight
layers.2.feed_forward.w2.weight
layers.2.feed_forward.w3.weight
layers.3.attention.wq.weight
layers.3.attention.wk.weight
layers.3.attention.wv.weight
layers.3.attention.wo.weight
layers.3.attention_norm.weight
layers.3.ffn_norm.weight
layers.3.feed_forward.w1.weight
layers.3.feed_forward.w2.weight
layers.3.feed_forward.w3.weight
layers.4.attention.wq.weight
layers.4.attention.wk.weight
layers.4.attention.wv.weight
layers.4.attention.wo.weight
layers.4.attention_norm.weight
layers.4.ffn_norm.weight
layers.4.feed_forward.w1.weight
layers.4.feed_forward.w2.weight
layers.4.feed_forward.w3.weight
layers.5.attention.wq.weight
layers.5.attention.wk.weight
layers.5.attention.wv.weight
layers.5.attention.wo.weight
layers.5.attention_norm.weight
layers.5.ffn_norm.weight
layers.5.feed_forward.w1.weight
layers.5.feed_forward.w2.weight
layers.5.feed_forward.w3.weight
layers.6.attention.wq.weight
layers.6.attention.wk.weight
layers.6.attention.wv.weight
layers.6.attention.wo.weight
layers.6.attention_norm.weight
layers.6.ffn_norm.weight
layers.6.feed_forward.w1.weight
layers.6.feed_forward.w2.weight
layers.6.feed_forward.w3.weight
layers.7.attention.wq.weight
layers.7.attention.wk.weight
layers.7.attention.wv.weight
layers.7.attention.wo.weight
layers.7.attention_norm.weight
layers.7.ffn_norm.weight
layers.7.feed_forward.w1.weight
layers.7.feed_forward.w2.weight
layers.7.feed_forward.w3.weight
norm.weight
output.weight
vision_encoder.logit_scale
vision_encoder.text_model.embeddings.token_embedding.weight
vision_encoder.text_model.embeddings.position_embedding.weight
vision_encoder.text_model.encoder.layers.0.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.0.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.0.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.0.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.0.layer_norm1.weight
vision_encoder.text_model.encoder.layers.0.layer_norm1.bias
vision_encoder.text_model.encoder.layers.0.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.0.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.0.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.0.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.0.layer_norm2.weight
vision_encoder.text_model.encoder.layers.0.layer_norm2.bias
vision_encoder.text_model.encoder.layers.1.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.1.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.1.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.1.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.1.layer_norm1.weight
vision_encoder.text_model.encoder.layers.1.layer_norm1.bias
vision_encoder.text_model.encoder.layers.1.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.1.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.1.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.1.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.1.layer_norm2.weight
vision_encoder.text_model.encoder.layers.1.layer_norm2.bias
vision_encoder.text_model.encoder.layers.2.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.2.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.2.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.2.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.2.layer_norm1.weight
vision_encoder.text_model.encoder.layers.2.layer_norm1.bias
vision_encoder.text_model.encoder.layers.2.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.2.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.2.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.2.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.2.layer_norm2.weight
vision_encoder.text_model.encoder.layers.2.layer_norm2.bias
vision_encoder.text_model.encoder.layers.3.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.3.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.3.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.3.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.3.layer_norm1.weight
vision_encoder.text_model.encoder.layers.3.layer_norm1.bias
vision_encoder.text_model.encoder.layers.3.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.3.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.3.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.3.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.3.layer_norm2.weight
vision_encoder.text_model.encoder.layers.3.layer_norm2.bias
vision_encoder.text_model.encoder.layers.4.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.4.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.4.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.4.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.4.layer_norm1.weight
vision_encoder.text_model.encoder.layers.4.layer_norm1.bias
vision_encoder.text_model.encoder.layers.4.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.4.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.4.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.4.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.4.layer_norm2.weight
vision_encoder.text_model.encoder.layers.4.layer_norm2.bias
vision_encoder.text_model.encoder.layers.5.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.5.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.5.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.5.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.5.layer_norm1.weight
vision_encoder.text_model.encoder.layers.5.layer_norm1.bias
vision_encoder.text_model.encoder.layers.5.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.5.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.5.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.5.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.5.layer_norm2.weight
vision_encoder.text_model.encoder.layers.5.layer_norm2.bias
vision_encoder.text_model.encoder.layers.6.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.6.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.6.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.6.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.6.layer_norm1.weight
vision_encoder.text_model.encoder.layers.6.layer_norm1.bias
vision_encoder.text_model.encoder.layers.6.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.6.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.6.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.6.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.6.layer_norm2.weight
vision_encoder.text_model.encoder.layers.6.layer_norm2.bias
vision_encoder.text_model.encoder.layers.7.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.7.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.7.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.7.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.7.layer_norm1.weight
vision_encoder.text_model.encoder.layers.7.layer_norm1.bias
vision_encoder.text_model.encoder.layers.7.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.7.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.7.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.7.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.7.layer_norm2.weight
vision_encoder.text_model.encoder.layers.7.layer_norm2.bias
vision_encoder.text_model.encoder.layers.8.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.8.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.8.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.8.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.8.layer_norm1.weight
vision_encoder.text_model.encoder.layers.8.layer_norm1.bias
vision_encoder.text_model.encoder.layers.8.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.8.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.8.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.8.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.8.layer_norm2.weight
vision_encoder.text_model.encoder.layers.8.layer_norm2.bias
vision_encoder.text_model.encoder.layers.9.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.9.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.9.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.9.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.9.layer_norm1.weight
vision_encoder.text_model.encoder.layers.9.layer_norm1.bias
vision_encoder.text_model.encoder.layers.9.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.9.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.9.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.9.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.9.layer_norm2.weight
vision_encoder.text_model.encoder.layers.9.layer_norm2.bias
vision_encoder.text_model.encoder.layers.10.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.10.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.10.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.10.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.10.layer_norm1.weight
vision_encoder.text_model.encoder.layers.10.layer_norm1.bias
vision_encoder.text_model.encoder.layers.10.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.10.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.10.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.10.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.10.layer_norm2.weight
vision_encoder.text_model.encoder.layers.10.layer_norm2.bias
vision_encoder.text_model.encoder.layers.11.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.11.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.11.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.11.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.11.layer_norm1.weight
vision_encoder.text_model.encoder.layers.11.layer_norm1.bias
vision_encoder.text_model.encoder.layers.11.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.11.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.11.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.11.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.11.layer_norm2.weight
vision_encoder.text_model.encoder.layers.11.layer_norm2.bias
vision_encoder.text_model.final_layer_norm.weight
vision_encoder.text_model.final_layer_norm.bias
vision_encoder.vision_model.embeddings.class_embedding
vision_encoder.vision_model.embeddings.patch_embedding.weight
vision_encoder.vision_model.embeddings.position_embedding.weight
vision_encoder.vision_model.pre_layrnorm.weight
vision_encoder.vision_model.pre_layrnorm.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.0.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.0.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.0.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.0.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.0.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.0.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.0.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.0.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.1.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.1.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.1.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.1.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.1.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.1.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.1.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.1.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.2.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.2.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.2.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.2.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.2.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.2.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.2.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.2.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.3.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.3.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.3.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.3.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.3.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.3.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.3.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.3.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.4.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.4.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.4.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.4.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.4.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.4.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.4.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.4.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.5.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.5.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.5.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.5.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.5.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.5.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.5.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.5.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.6.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.6.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.6.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.6.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.6.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.6.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.6.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.6.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.7.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.7.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.7.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.7.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.7.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.7.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.7.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.7.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.8.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.8.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.8.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.8.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.8.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.8.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.8.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.8.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.9.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.9.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.9.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.9.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.9.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.9.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.9.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.9.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.10.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.10.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.10.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.10.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.10.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.10.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.10.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.10.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.11.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.11.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.11.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.11.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.11.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.11.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.11.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.11.layer_norm2.bias
vision_encoder.vision_model.post_layernorm.weight
vision_encoder.vision_model.post_layernorm.bias
vision_encoder.visual_projection.weight
vision_encoder.text_projection.weight
vision_proj.vision_proj.0.weight2.5 加载CLIP模型
代码:
python
from transformers import CLIPProcessor, CLIPModel
vision_model = CLIPModel.from_pretrained('./model/vision_model/clip-vit-base-patch16')
vision_processor = CLIPProcessor.from_pretrained('./model/vision_model/clip-vit-base-patch16')2.6 加载图片及提示词
输出结果中的"@"就是图片的占位符,一共有196个,对应之后图片编码后的196个token序列;
代码:
python
image_dir = './dataset/eval_images/彩虹瀑布-Rainbow-Falls.jpg'
image = Image.open(os.path.join(image_dir, image_file)).convert('RGB')
prompt = f"{model.params.image_special_token}\n描述一下这个图像的内容。"
print(prompt)输出结果:
python
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
描述一下这个图像的内容。2.7 图片转tensor
通过vision_processor将图片进行了resize操作、维度转换操作和归一化操作,这是常见的图片进行深度学习模型推理前的预处理操作;
代码1:
python
def image2tensor(image, processor):
if image.mode in ['RGBA', 'LA']: image = image.convert('RGB')
inputs = processor(images=image, return_tensors="pt")['pixel_values']
return inputs代码2:
python
inputs = image2tensor(image, vision_processor)
print(inputs.shape)
pixel_tensors = inputs.to('cpu').unsqueeze(0)
print(pixel_tensors.shape)
bs, num, c, im_h, im_w = pixel_tensors.shape输出结果2:
python
torch.Size([1, 3, 224, 224])
torch.Size([1, 1, 3, 224, 224])2.8 图片Embedding
上面我们将图片预处理后的长和宽为224,然后使用的是patch=16的CLIP模型,那么就会得到(224/16)^2=196个序列;
代码1:
python
import torch
def get_image_embeddings(image_tensors, vision_model):
with torch.no_grad():
outputs = vision_model.vision_model(pixel_values=image_tensors)
img_embedding = outputs.last_hidden_state[:, 1:, :].squeeze()
return img_embedding代码2:
python
b = get_image_embeddings(a, vision_model)
print(b.shape)
vision_tensors = torch.stack([b], dim=stack_dim)
print(vision_tensors.shape)输出结果2:
python
torch.Size([196, 768])
torch.Size([1, 196, 768])2.9 整体forward推理
代码:
python
def forward(self,
input_ids: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
**args):
start_pos = args.get('start_pos', 0)
# 0
pixel_tensors = args.get('pixel_tensors', None)
# 1
h = self.tok_embeddings(input_ids)
# 2
if pixel_tensors is not None and start_pos == 0:
if len(pixel_tensors.shape) == 6:
pixel_tensors = pixel_tensors.squeeze(2)
bs, num, c, im_h, im_w = pixel_tensors.shape
stack_dim = 1 if bs > 1 else 0
# 2.1
vision_tensors = torch.stack([
MiniMindVLM.get_image_embeddings(pixel_tensors[:, i, :, :, :], self.vision_encoder)
for i in range(num)
], dim=stack_dim)
# 2.2
h = self.count_vision_proj(tokens=input_ids, h=h, vision_tensors=vision_tensors, seqlen=input_ids.shape[1])
# 3
pos_cis = self.pos_cis[start_pos:start_pos + input_ids.shape[1]]
past_kvs = []
for l, layer in enumerate(self.layers):
h, past_kv = layer(
h, pos_cis,
past_key_value=past_key_values[l] if past_key_values else None,
use_cache=use_cache
)
past_kvs.append(past_kv)
logits = self.output(self.norm(h))
aux_loss = sum(l.feed_forward.aux_loss for l in self.layers if isinstance(l.feed_forward, MOEFeedForward))
self.OUT.__setitem__('logits', logits)
self.OUT.__setitem__('aux_loss', aux_loss)
self.OUT.__setitem__('past_key_values', past_kvs)
return self.OUT
- 0------ pixel_tensors是上面通过对图片预处理获得的归一化后的张量;
- 1------h是通过模型的Embedding层转化后的token张量;
- 2------判断有图片信息,并且是第一轮推理时,嵌入图片token张量到h里;
- 2.1------vision_tensors就是上面讲到的通过CLIP模型将图片进行patch分割后通过VIT进行特征提取后的特征图;
- 2.2------count_vision_proj()函数就是将图片的token序列添加到h中的具体实现,返回的h就是已经嵌入了图片token序列的文本图片融合的token序列;下面我们具体看一下count_vision_proj函数;
- 3------再往下的操作,包括进行旋转位置编码,进行自注意力机制的运算就和LLM完全相同了,这里就不再赘述,可以查看之前关于LLM模型推理的博客;
2.9.1 图像token与文本token融合------count_vision_proj
代码:
python
def count_vision_proj(self, tokens, h, vision_tensors=None, seqlen=512):
# 1
def find_indices(tokens, image_ids):
image_ids_tensor = torch.tensor(image_ids).to(tokens.device)
len_image_ids = len(image_ids)
if len_image_ids > tokens.size(1):
return None
tokens_view = tokens.unfold(1, len_image_ids, 1)
matches = (tokens_view == image_ids_tensor).all(dim=2)
return {
batch_idx: [(idx.item(), idx.item() + len_image_ids - 1) for idx in
matches[batch_idx].nonzero(as_tuple=True)[0]]
for batch_idx in range(tokens.size(0)) if matches[batch_idx].any()
} or None
# 2
image_indices = find_indices(tokens, self.params.image_ids)
# 3
if vision_tensors is not None and image_indices:
# 3.1
vision_proj = self.vision_proj(vision_tensors)
if len(vision_proj.shape) == 3:
vision_proj = vision_proj.unsqueeze(0)
new_h = []
# 3.2
for i in range(h.size(0)):
if i in image_indices:
h_i = h[i]
img_idx = 0
for start_idx, end_idx in image_indices[i]:
if img_idx < vision_proj.size(1):
h_i = torch.cat((h_i[:start_idx], vision_proj[i][img_idx], h_i[end_idx + 1:]), dim=0)[
:seqlen]
img_idx += 1
new_h.append(h_i)
else:
new_h.append(h[i])
return torch.stack(new_h, dim=0)
return h
- 1------find_indices函数用于在文本tokenID中寻找图片占位tokenID的起止位置的索引,返回是一个字典,每个key对应一个图片占位,value对应该图片占位的起止索引;
- 2------输入文本tokenID和图片占位tokenID寻找对应索引;
- 3------vision_tensors是clip输出的图片的特征图,如果图片特征存在并且在文本tokenID中找到对应位置,则进行图片token序列嵌入;
- 3.1------vision_proj层是一个全链接层,目的是将图片token张量的维度与文本token维度对齐,在这里文本的维度是512,但是通过clip输出的图片的token维度是768维,所以需要通过一个【768,512】的全链接层矩阵进行维度转换;
- 3.2------下面的for循环就是根据找到的具体位置索引,将对应的图片的token序列按照对应位置替换掉文本token序列中的图片占位符张量,全部替换后返回新的h,这时的token序列就包含了文本和图片的融合信息;
三、总结
通过该博客,分享了LLM和VLM在模型前处理阶段等一些方面的区别;相较于LLM模型,VLM只是在输入信息转换为token序列时有所不同,目的就是将图片的特征与文本的特征可以结合在一起,形成统一的token序列,在位置编码上、模型的自注意力运算、模型预测token转化后处理的流程上其实都是一致的。