一、模型介绍
HunyuanVideo 是腾讯推出的一款开源视频生成基础模型,拥有超过 130 亿个参数,是当前规模最大的开源视频生成模型。
它在视频生成方面表现出与领先的闭源模型相当甚至优于领先闭源模型的性能。HunyuanVideo 具有一个全面的框架,集成了多项关键贡献,包括数据管理、图像-视频联合模型训练以及旨在促进大规模模型训练和推理的高效基础设施。
团队进行了广泛的实验并实施了一系列有针对性的设计,以确保高视觉质量、运动多样性、文本-视频对齐和生成稳定性。根据专业的人体测评结果,混元视频的表现优于之前最先进的模型,包括 Runway Gen-3、Luma 1.6 和 3 款性能最好的中国视频生成模型。
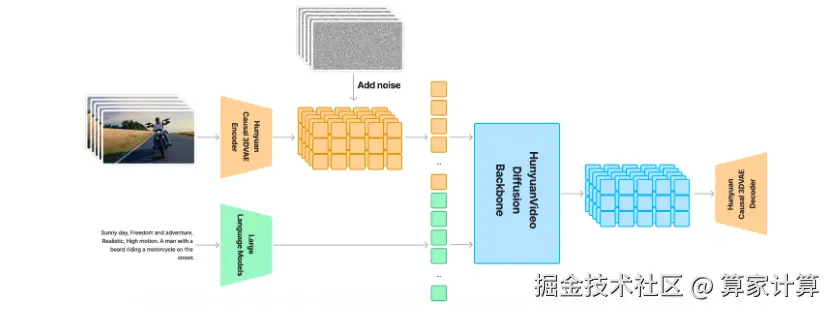
HunyuanVideo 整体设计
HunyuanVideo 在时空上进行了训练 压缩的潜在空间,通过因果 3D VAE 进行压缩。
二、模型部署步骤
基础环境
| Ubuntu | 22.04 |
|---|---|
| cuda | 12.4 |
| python | 3.10.9 |
| NVIDIA corporation | A100 SXM4 |
1.更新基础的软件包
查看系统版本信息
bash
#查看系统的版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release配置国内源
apt 配置阿里源
将以下内容粘贴进文件中
arduino
deb http://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb http://mirrors.aliyun.com/debian-security/ bullseye-security main
deb-src http://mirrors.aliyun.com/debian-security/ bullseye-security main
deb http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib2.基础Miniconda3环境
查看系统是否有 miniconda 的环境
conda -V
显示如上输出,即安装了相应环境,若没有 miniconda 的环境,通过以下方法进行安装
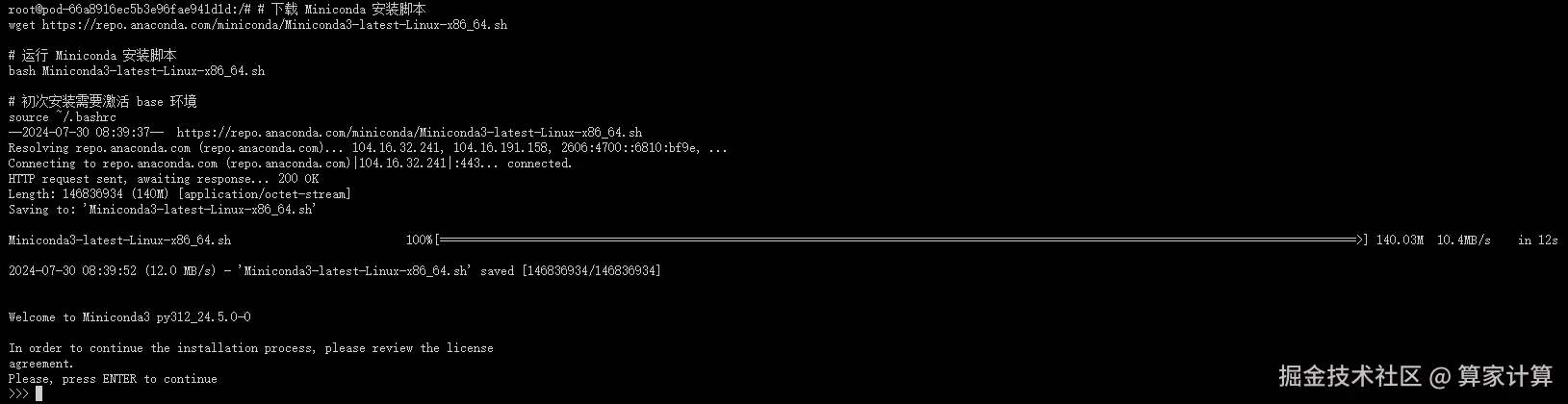
bash
#下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
#运行 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
#初次安装需要激活 base 环境
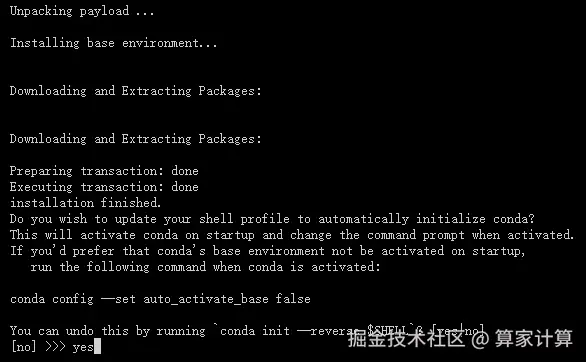
source ~/.bashrc按下回车键(enter)
输入 yes
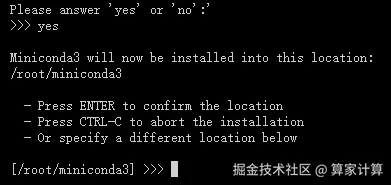
输入 yes
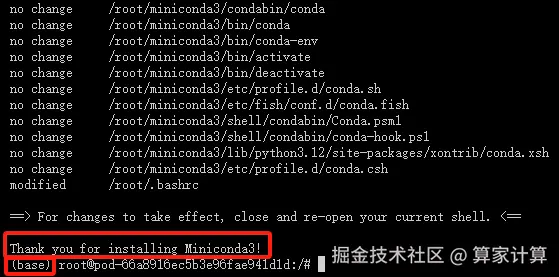
安装成功如下图所示
3.克隆仓库并进入项目
bash
git clone https://github.com/Tencent-Hunyuan/HunyuanVideo
cd HunyuanVideo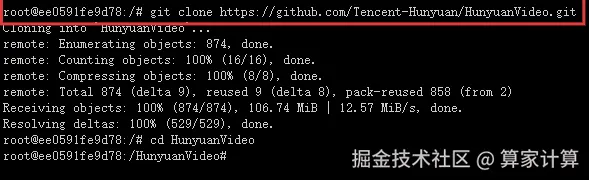

4.创建虚拟环境
创建并激活虚拟环境
ini
# 1. Create conda environment
conda create -n HunyuanVideo python==3.10.9
# 2. Activate the environment
conda activate HunyuanVideo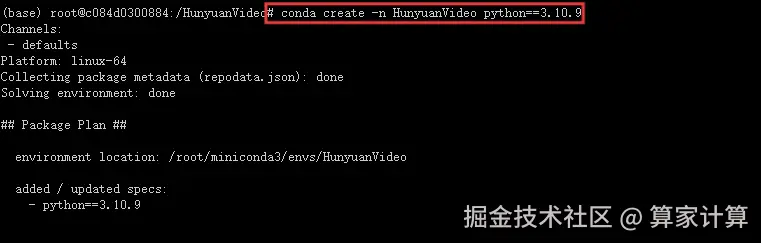

5.安装pytorch环境
ini
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia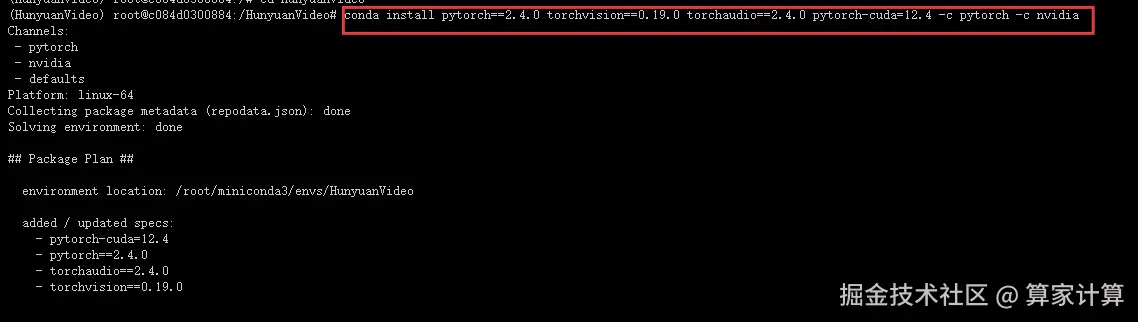
6.下载依赖
python -m pip install -r requirements.txt
7.装 Flash Attention v2 (版本 2.6.3)
python -m pip install ninja
出现successfully installed 为安装成功
bash
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3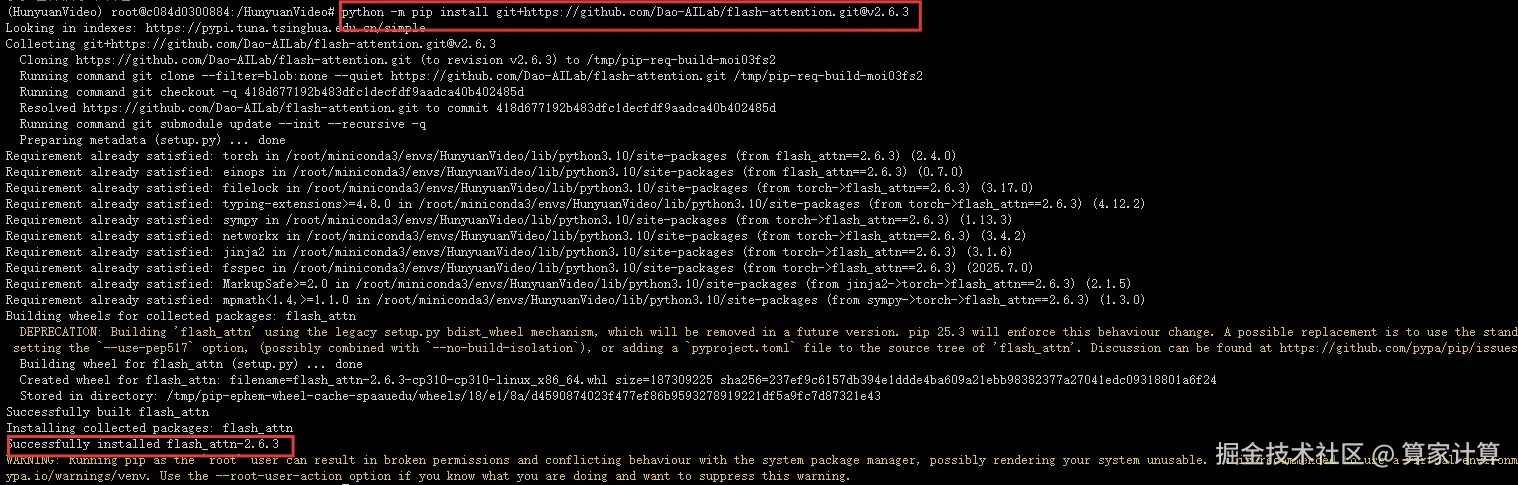
8.安装xDiT以进行并行推理(建议使用torch 2.4.0和flash-attn 2.6.3)
ini
python -m pip install xfuser==0.4.09.下载HunyuanVideo模型
要下载 HunyuanVideo 模型,请先安装 huggingface-cli。
arduino
python -m pip install "huggingface_hub[cli]"
然后使用以下命令下载模型:
bash
# Switch to the directory named 'HunyuanVideo'
cd HunyuanVideo
# Use the huggingface-cli tool to download HunyuanVideo model in HunyuanVideo/ckpts dir.
# The download time may vary from 10 minutes to 1 hour depending on network conditions.
hf download tencent/HunyuanVideo --local-dir ./ckpts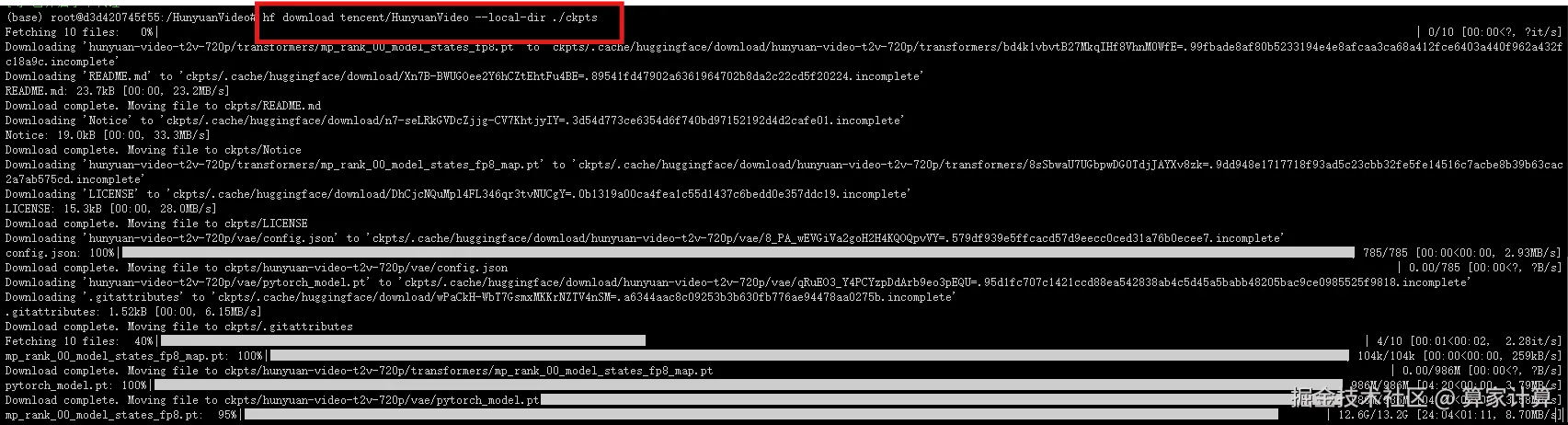
出现下载拒绝是因为没有加载密钥
vim download.py
python
from huggingface_hub import snapshot_download, login
import os
def download_hunyuan_video(local_dir="./ckpts", token="替换为实际密钥"):
try:
# 使用提供的密钥登录
login(token=token)
# 下载模型仓库到指定目录
print(f"开始下载 tencent/HunyuanVideo 到 {local_dir}...")
snapshot_download(
repo_id="tencent/HunyuanVideo",
local_dir=local_dir,
local_dir_use_symlinks=False, # 避免使用符号链接,直接下载文件
max_workers=4 # 并发下载线程数
)
print("下载完成!")
except Exception as e:
print(f"下载过程中出现错误: {str(e)}")
finally:
# 退出登录(可选)
login(token=None)
if __name__ == "__main__":
# 调用下载函数
download_hunyuan_video()下载完成
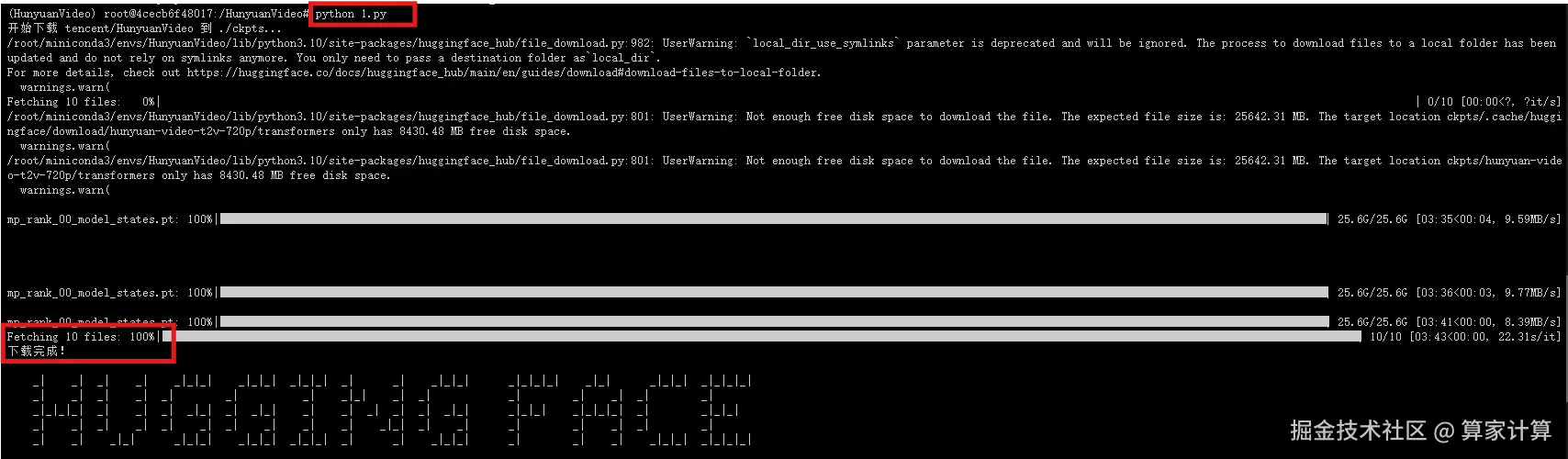
10.下载文本编码器
混元视频使用 MLLM 模型和 CLIP 模型作为文本编码器。
1.MLLM模型(text_encoder文件夹)
混元视频支持不同的 MLLM(包括混元 MLLM 和开源 MLLM 模型)。现阶段,我们还没有发布混元 MLLM。我们建议社区用户使用 Xtuer 提供的 llava-llama-3-8b,可以通过以下命令下载
bash
cd HunyuanVideo/ckpts
huggingface-cli download xtuner/llava-llama-3-8b-v1_1-transformers --local-dir ./llava-llama-3-8b-v1_1-transformers
下载完成会显示匹配所有文件100%
以及出现文件下载目录
为了节省模型加载的 GPU 内存资源,我们将语言模型的各个部分分离成 llava-llama-3-8b和text_encoder
bash
cd HunyuanVideo
python hyvideo/utils/preprocess_text_encoder_tokenizer_utils.py --input_dir ckpts/llava-llama-3-8b-v1_1-transformers --output_dir ckpts/text_encoder
加载完成会显示Loading checkpoint shards: 100%
如果显示 no nms 则是torch 与torchvision版本不匹配
首先检查 PyTorch 和 torchvision 的安装情况:
perl
pip list | grep torch
pip list | grep torchvision
卸载当前版本
bash
# 若用 conda
conda uninstall -y torchvision
# 若用 pip
pip uninstall -y torchvision
安装0.21.0版本
ini
# conda 安装(需匹配 CUDA 版本,以 12.4 为例)
conda install torchvision==0.21.0 -c pytorch -c nvidia
# 或 pip 安装(更稳定,避免 conda 源问题)
pip install torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu124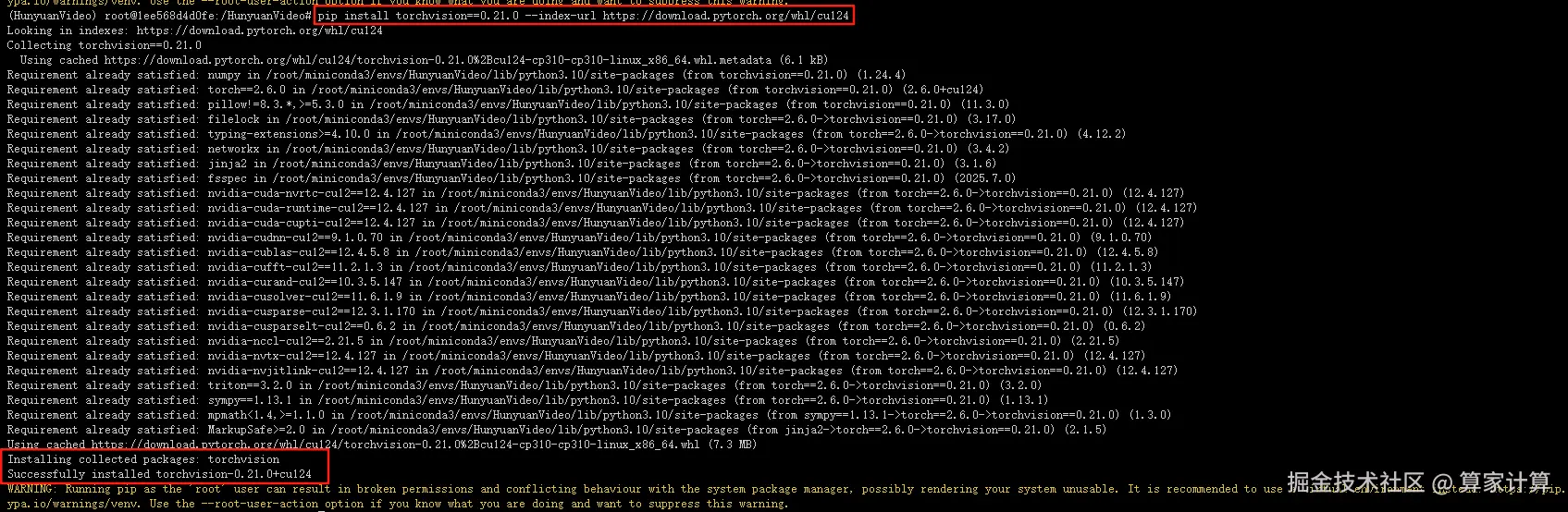
2.CLIP模型(text_encoder_2文件夹)
我们使用 OpenAI 提供的 CLIP 作为另一个文本编码器,社区中的用户可以通过以下命令下载该模型
bash
cd HunyuanVideo/ckpts
huggingface-cli download openai/clip-vit-large-patch14 --local-dir ./text_encoder_2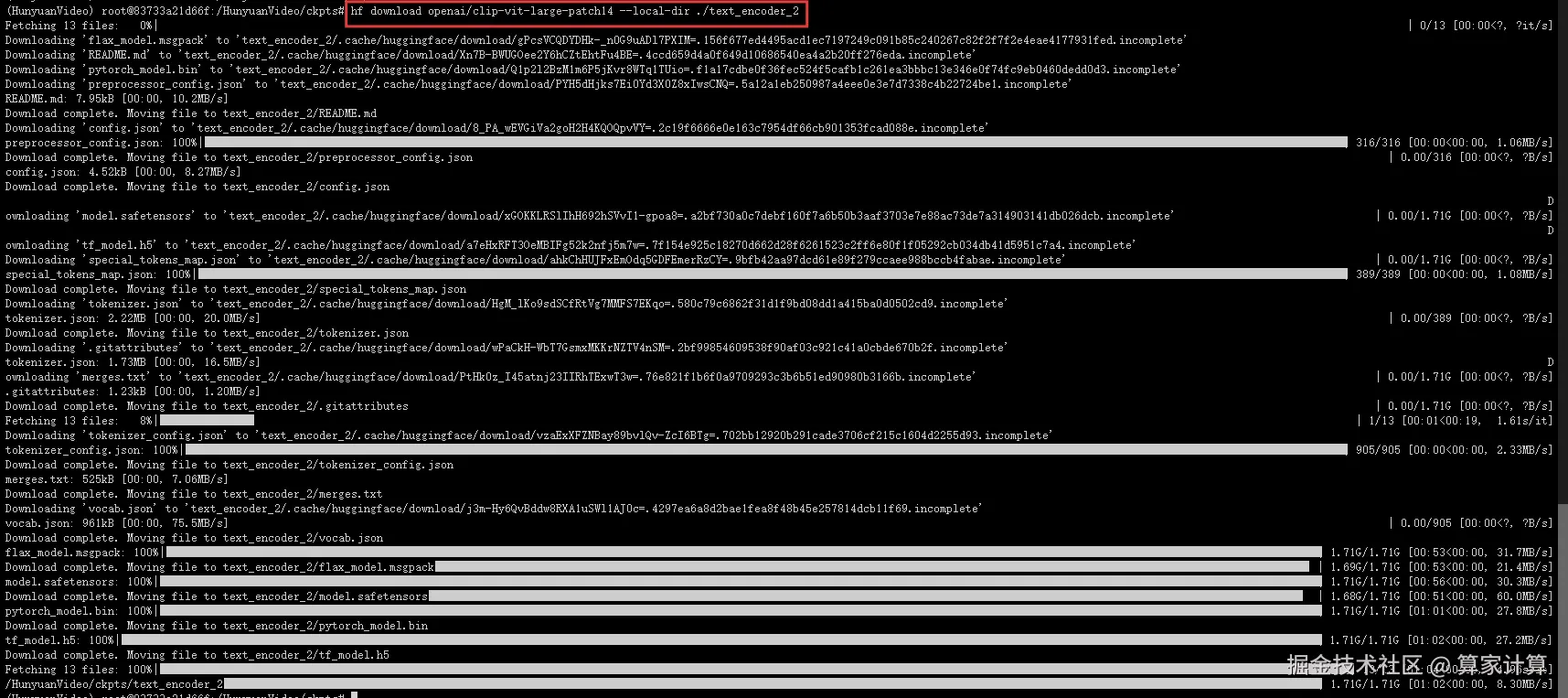
运行Gradio服务器
css
python3 gradio_server.py --flow-reverse三、模型页面
通过开放端口来直接访问页面
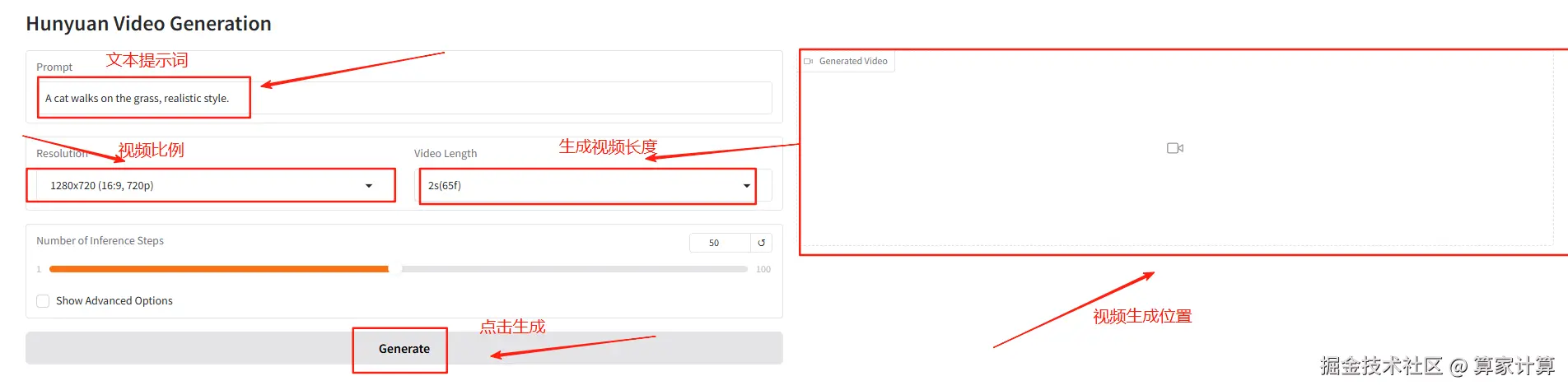
通过选择不同的提示词来生成不同的视频
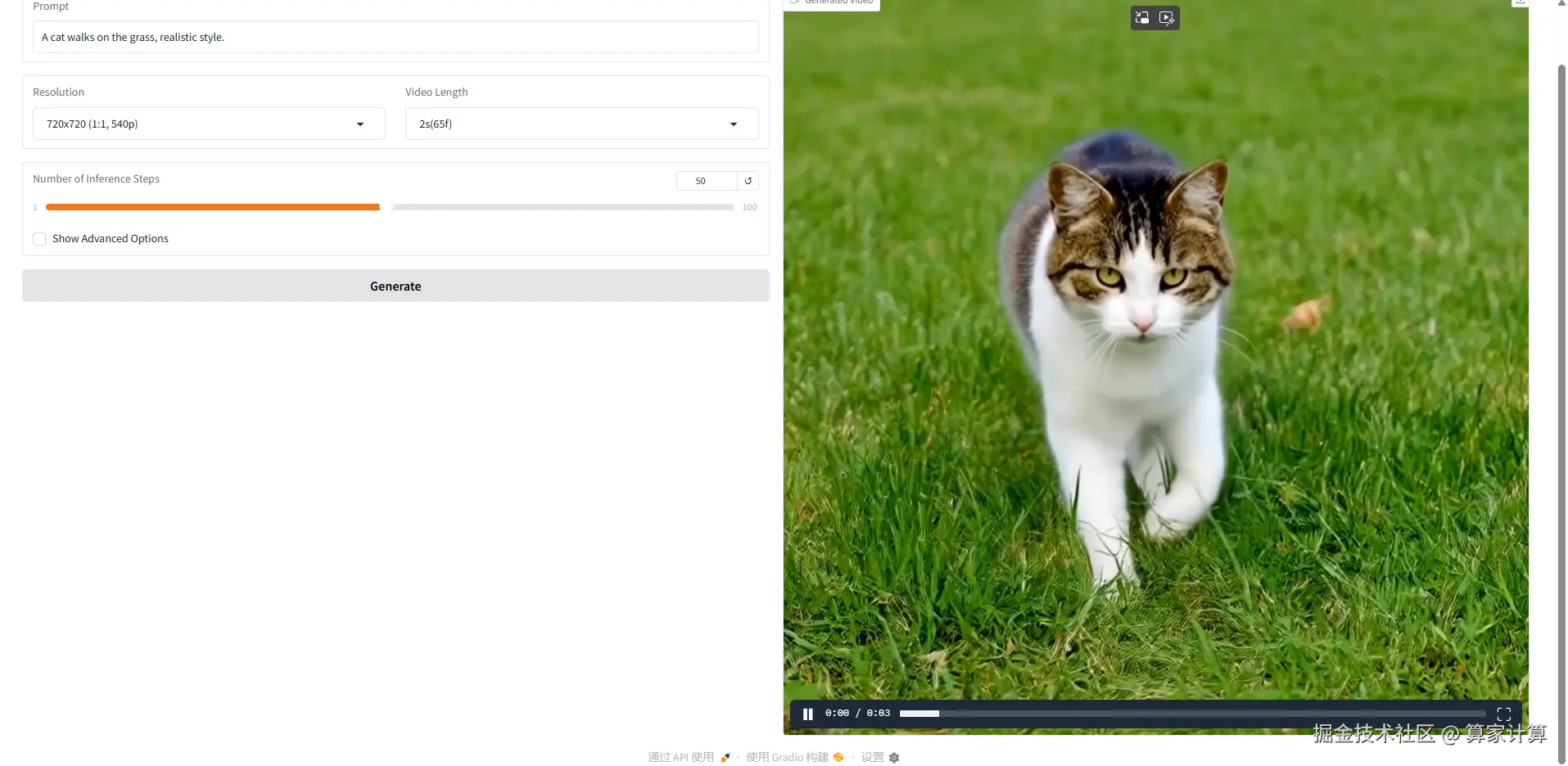
提示词:A cat walks on the grass, realistic style.步数设置为10步
参数设置

生成的结果显示,以及耗费时间
花费时间约1:15分钟 ,大小为809KB
步数设置为50步时间约为6分钟 ,大小为953.22KB
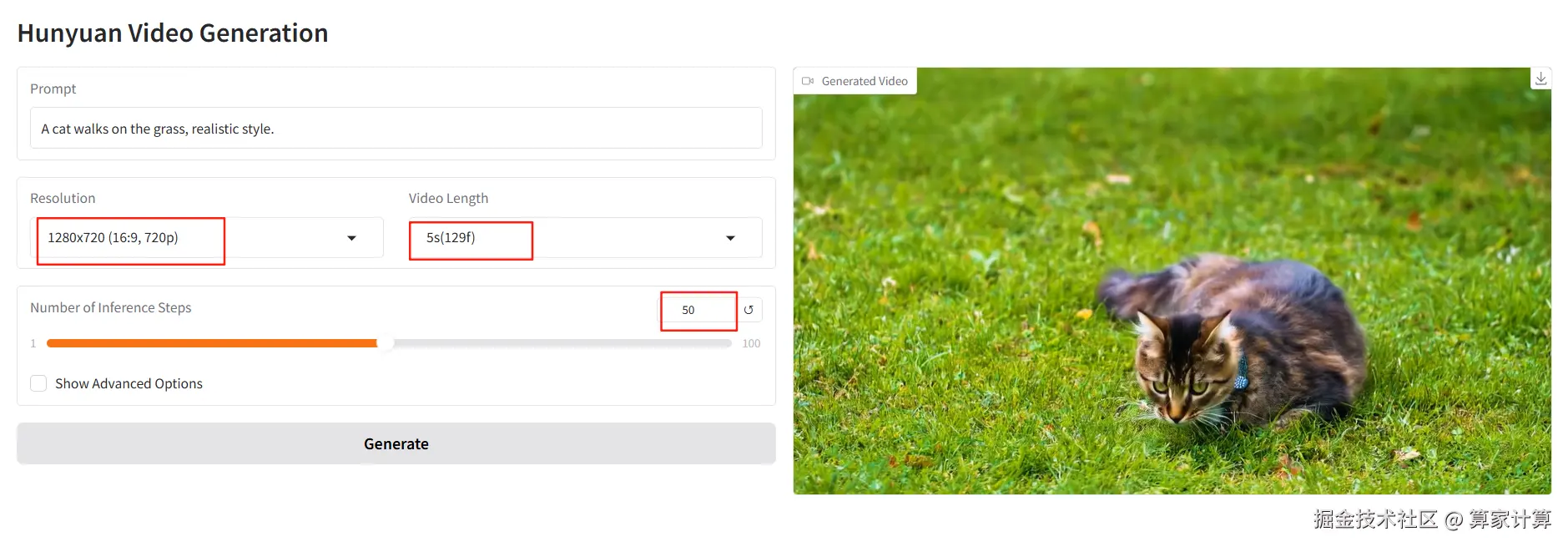
修改参数为最高1280x720 (16:9, 720p),5s(129f),50步
时间约为50分钟,大小为2.64MB

提示词不要设置太长,会导致错误File name too long错误