在国产AI大模型高歌猛进的浪潮中,一颗芯片很可能就成了"绊脚石"。
原本备受期待的 DeepSeek R2 大模型,其发布计划一再延期。据《金融时报》等多方消息透露,此次延期的原因,在于团队在训练阶段遭遇了持续的技术问题。
此前,DeepSeek 作为国产开源之光,承载着无数开发者的希望,业内也持续关注着 DeepSeek-R2 的发布动向。2025 年 2 月,路透社首度透露 DeepSeek 计划"最迟 5 月初"发布 R2 版本。然而,到了 5 月,仍未见新模型。
科技媒体 The Information 曾于 6 月 透露, DeepSeek 内部的 R2 模型开发遇到了两个关键瓶颈:一是 CEO 梁文锋对模型当前性能不满意,拒绝批准发布;二是受限于美国政府对 NVIDIA H20 芯片的新一轮出口管制,算力短缺正实质性阻碍新模型的训练与部署。

R2 迟迟不上线的背后,除了性能问题,更有可能是千亿级大模型训练时所面临的现实瓶颈,以及背后复杂的系统性难题。
为何芯片性能对千亿级大模型训练如此至关重要?
本质上,训练一个像 DeepSeek R2 这样参数规模达到千亿以上的大模型,是在挑战一个近乎"不可能三角"的平衡:即算力规模、训练效率与系统稳定性三者难以同时完美兼顾。

在技术层面,这需要协调成千上万枚芯片持续稳定地协同工作数月之久。在这个过程中,任何一个节点的故障都可能导致整个训练中断,需要回滚到最近的检查点重新开始。因此,这对芯片的性能、稳定性以及相互之间的兼容性都提出了极高的要求。芯片的可靠性在相似场景下的微小差距,在万卡级别的庞大集群中都会被急剧放大,转化为每天数次的实际故障,严重拖累训练进度。
其中,内存带宽更是一个难以回避的关键问题。模型的参数量越大,对权重数据高速加载的需求就越迫切。英伟达 GPU 借助先进的 HBM3e 高带宽内存技术,能够提供高达 3.6TB/s 的惊人带宽。相比之下,其他芯片较低的内存带宽在面对千亿参数模型实时加载海量数据的压力时,可能会造成严重的"算力空转"现象,硬件潜力无法有效释放。
当前,全球大部分千亿参数大模型训练都依赖英伟达平台,其难以撼动的地位并非仅来源于硬件本身。经过二十年持续构建的 CUDA 软件生态是其最深的护城河,包含了数百万个经过深度优化的算子,为开发者提供了无与伦比的效率和灵活性。
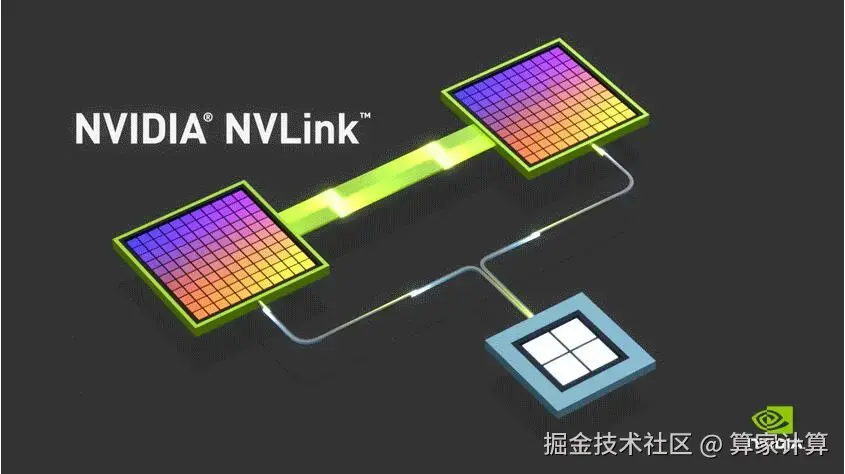
在内存技术方面,英伟达的 HBM 持续领先,新一代架构已能实现单芯片 512Gbit 的容量和数倍于传统方案的带宽。更重要的是其超算级的芯片互联能力,通过 NVLink 技术,芯片间的直连带宽可达 900GB/s,分布式训练的延迟控制在极低的 2 微秒以内。这些系统级的综合能力,使得英伟达在部署超大规模千卡集群进行训练时,能保持有效算力利用率。
 【图片来源于网络,侵删】
【图片来源于网络,侵删】
随着国产大模型的技术进展,未来可能会出现更多千亿级甚至万亿级的大模型,要支撑起构建万卡级训练集群的庞大需求,AI 芯片不能仅仅聚焦于芯片设计本身,还必须在软件生态、内存架构创新以及芯片制造能力等多个关键领域实现协同突破。
这场围绕芯片与大模型的竞赛,是一场需要从最底层的晶体管设计,到中间的编译器优化,再到顶层的分布式训练框架协同创新,贯穿整个技术栈的艰巨长征。