参考资料:R试验设计与数据分析------基于R语言应用
2、单因素方差分析
单因素方差分析是指对单因素试验结果进行分析,检验因素对试验结果有无显著性影响的方法。单因素方差分析用于多个样本均数间的比较其统计推断是推断各样本所代表的各总体均数是否相等。R语言的aov()函数提供了方差分析的计算和检验,其使用格式如下:
R
aov(formula, data = NULL, contrasts = NULL, ...)formula是方差分析的公式,在单因素方差分析中,可表示为x~A;data是数据框。可以用summary函数列出方差分析表的详细信息。
R
# 生成案例数据
x<-c(25.6,22.2,28.0,29.8,
24.4,30.0,29.0,27.5,
25.0,27.7,23.0,32.2,
28.8,28.0,31.5,25.9,
20.6,21.2,22.0,21.2)
method<-factor(rep(1:5,each=4))
aov.data<-data.frame(x,method)
# 方差分析
aov.model<-aov(x~method,data=aov.data)
# 查看反差分析结果
summary(aov.model)
输出结果中,Df表示自由度;Sum Sq表示平方和,Mean Sq表示均方和;F value表示F检验统计量的值,即F比;P(>F)表示检验的p值;method为本例中所考察的因素量,即方法;Residuals为残差。可以看出F=4.306,p=0.0162<0.05,说明拒绝原假设,即认为五种除杂方法有显著差异。
(1)方差分析表的计算
在进行方差分析时,通常会将结果以下面的形式列出,称为方差分析表:

从R的输出结果可以看出,summary()函数没有输出最后一行的总和行,可以自行编写一个anova.table()函数,将summary()函数输出的第一行和第二行求和,得到总和行。
R
anova.table<-function(fm){
table<-summary(fm)
k<-length(table[[1]])-2
tmp<-c(sum(table[[1]][,1]),sum(table[[1]][,2]),rep(NA,k))
table[[1]]["Total",]<-tmp
table
}
anova.table(aov.model)
我们也可以调整函数,将输出结果调整为可以进行数据导出的data.frame格式。
R
anova.table<-function(fm){
table<-summary(fm)
k<-length(table[[1]])-2
tmp<-c(sum(table[[1]][,1]),sum(table[[1]][,2]),rep(NA,k))
table[[1]]["Total",]<-tmp
table<-data.frame(table[[1]][1:3,])
table
}
res<-anova.table(aov.model)
class(res)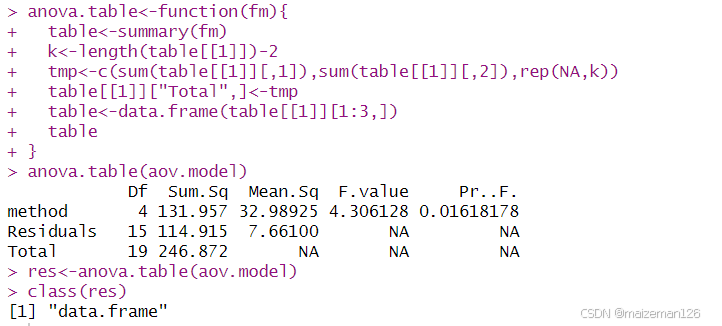
我们利用自定义函数anova.table()可以得到完整的方差分析表。
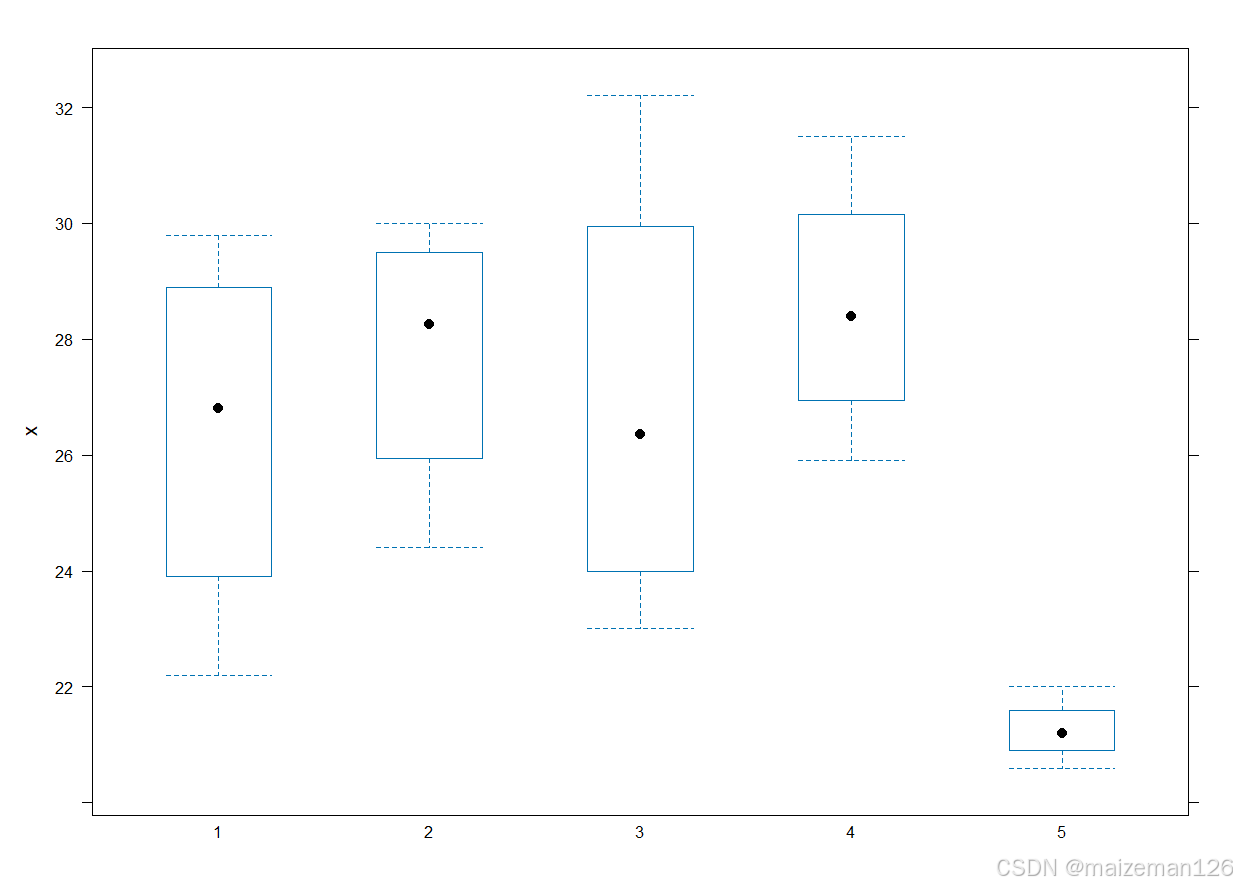
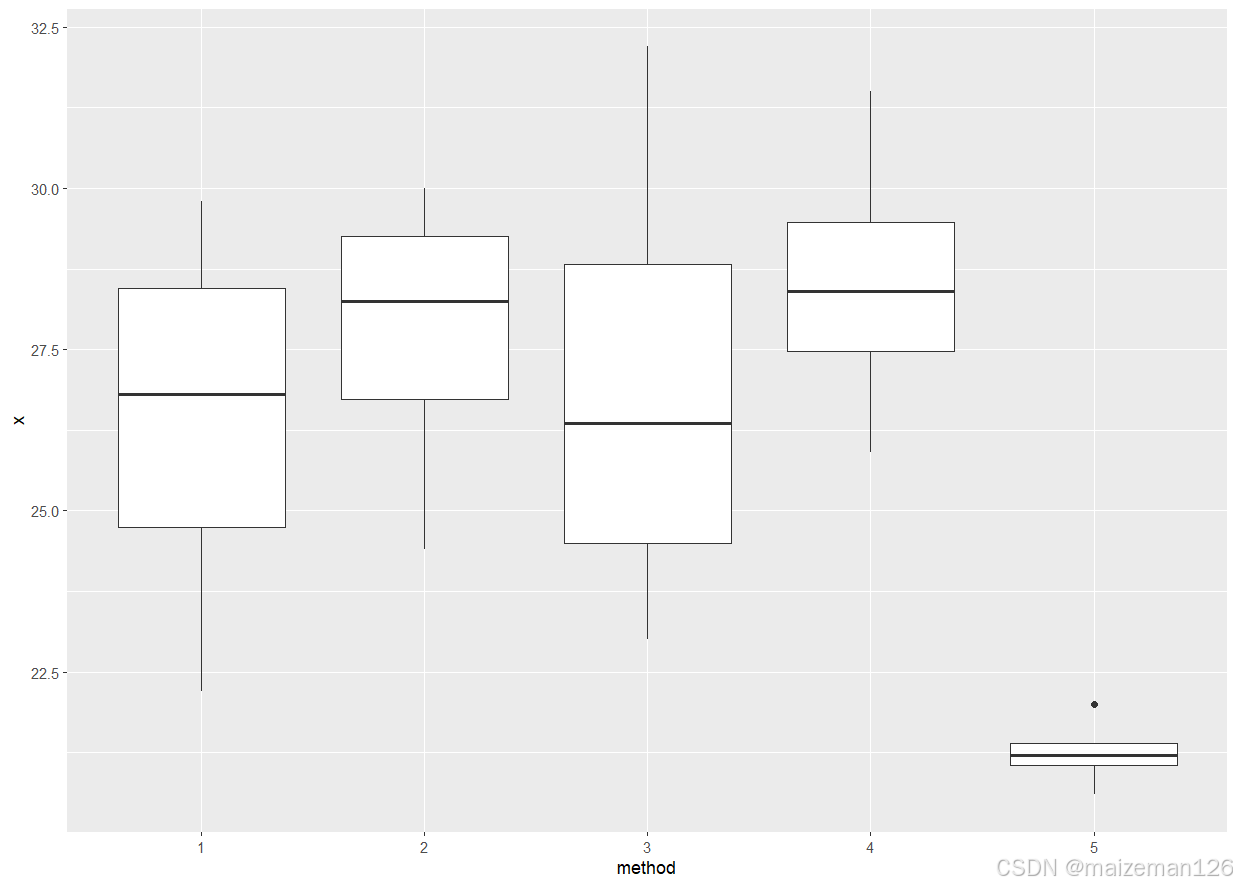
方差分析结果仅表明了多组是有差异的,但具体差异还需要进一步进行分析。可以通过plot()函数进行绘图,查看每组观察数据的箱线图,直观描述因素各水平均值的差异。
R
plot(x~method,data=aov.data)
boxplot(x~method,data=aov.data)
library(lattice)
bwplot(x~method,data=aov.data)
library(ggplot2)
ggplot(data=aov.data,aes(method,x))+
geom_boxplot()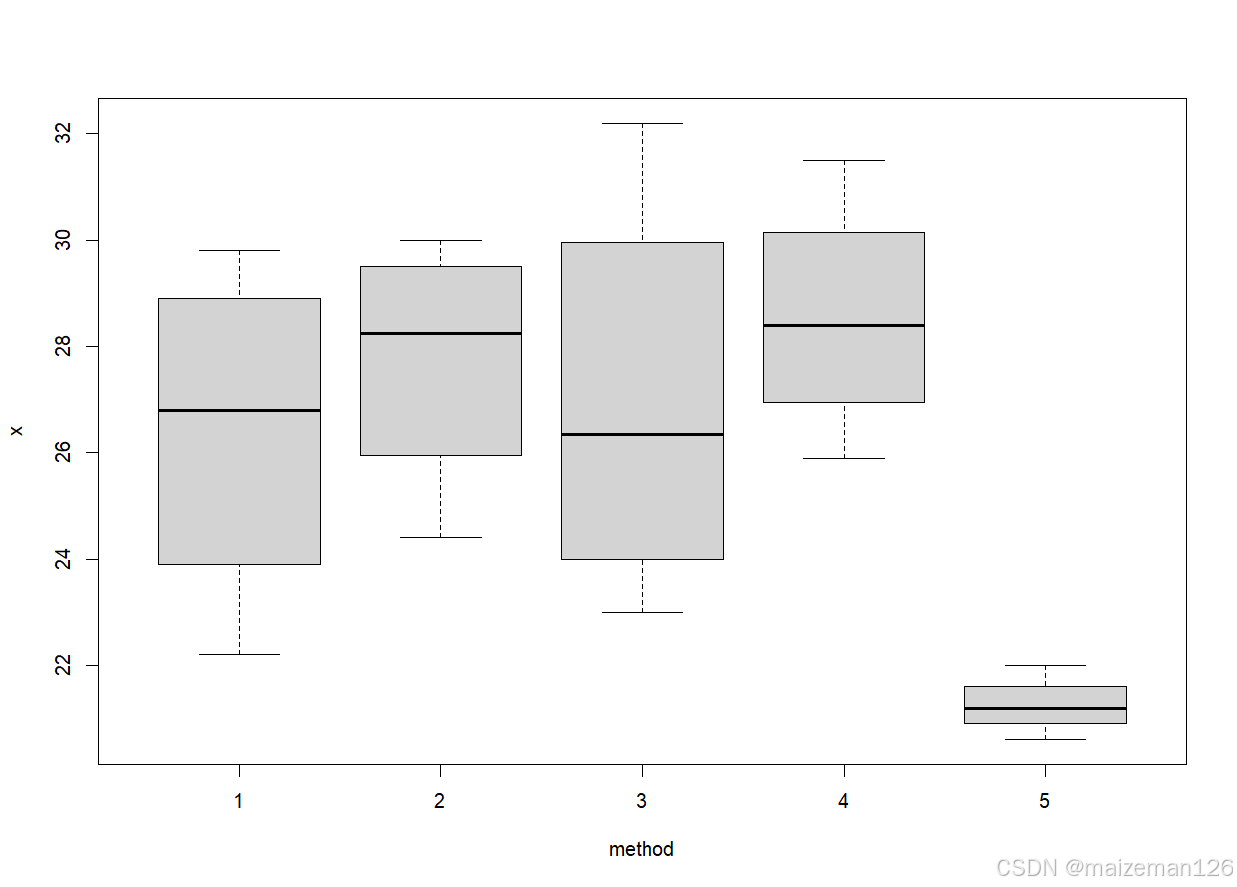
(2)均值的多重比较
方差分析的F检验结论是拒绝H0,则说明因素A的r个水平效应有显著的差异 ,也就是说r个均值之间有显著差异。但是这并不意味着所有均值都存在差异,这时还需要对每一对均值做一对一的比较,即多重比较。
①多重t检验方法
这种方法本质上是对每组数据进行t检验,只不过估计方法的时候利用的是全体数据,因而自由度变大。多重t检验方法的优点是使用方便。但在均值的多重检验中,如果因素的水平较多,而检验又是同时进行,多次重复使用t检验会增大犯第一类错误的概率,所得到的"有显著差异"的结论不一定可靠。
为了克服多重t检验方法的缺点,我们需要调整p值。在R中,函数pairwise.t.test()可以得到多重比较的p值:
pairwise.t.test(x, g, p.adjust.method = p.adjust.methods,
pool.sd = !paired, paired = FALSE,
alternative = c("two.sided", "less", "greater"),
...)其中x为响应变量构成的向量,g为分组向量(因子),p.adjust.methods是p值调整的方法,具体有"holm", "hochberg", "hommel", "bonferroni", "BH", "BY", "fdr", "none"。当比较次数较多,bonferroni方法的效果较好,所以在作多重检验时常采用bonferroni方法对p值进行调整。
R
pairwise.t.test(x,method,p.adjust.method = "bonferroni")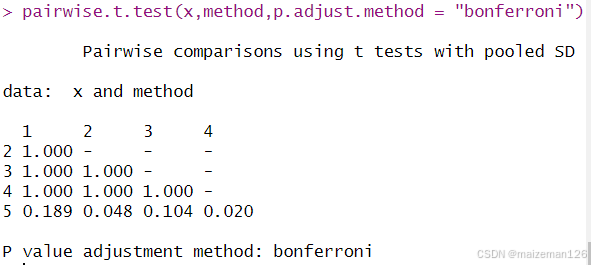
根据结果显示:只有方法5和方法2、方法5和方法4之间的差异显著,其他各种方法之间没有显著差异。
②Tukey法
R中的TukeyHSD()函数提供了对多组均值差异的成对检验。
TukeyHSD(x, which, ordered = FALSE, conf.level = 0.95, ...)其中,x为方差分析的对象,conf.level为置信水平,ordered为逻辑值,如果为TRUE,则按因子的水平递增排序,从而使得因子间差异均以正值形式出现。
R
aov.model<-aov(x~method,data=aov.data)
TukeyHSD(aov.model,order=FALSE)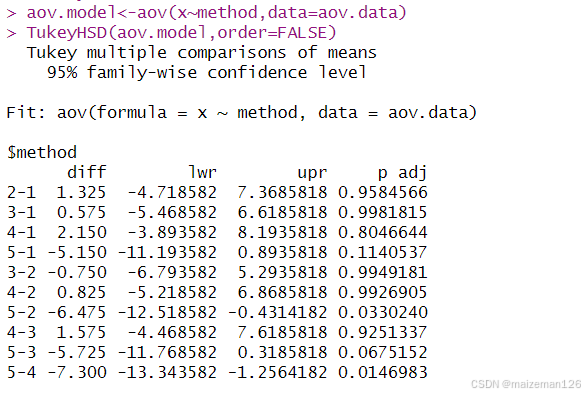
输出结果表明方法5与方法2、方法5与方法4除杂量均值有显著差异,其他方法之间的除杂量均值差异不显著。
TukeyHSD()输出结果还可以用图形展示,直观描述多重TukeyHSD法比较。下面代码中对par参数进行相应设置,las=2语句用来旋转坐标轴,mar=c(5,8,4,2)用来增大左边边界的面积,可以使标签摆放更加美观。
R
par(las=2,mar=c(5,8,4,2))
plot(TukeyHSD(aov.model))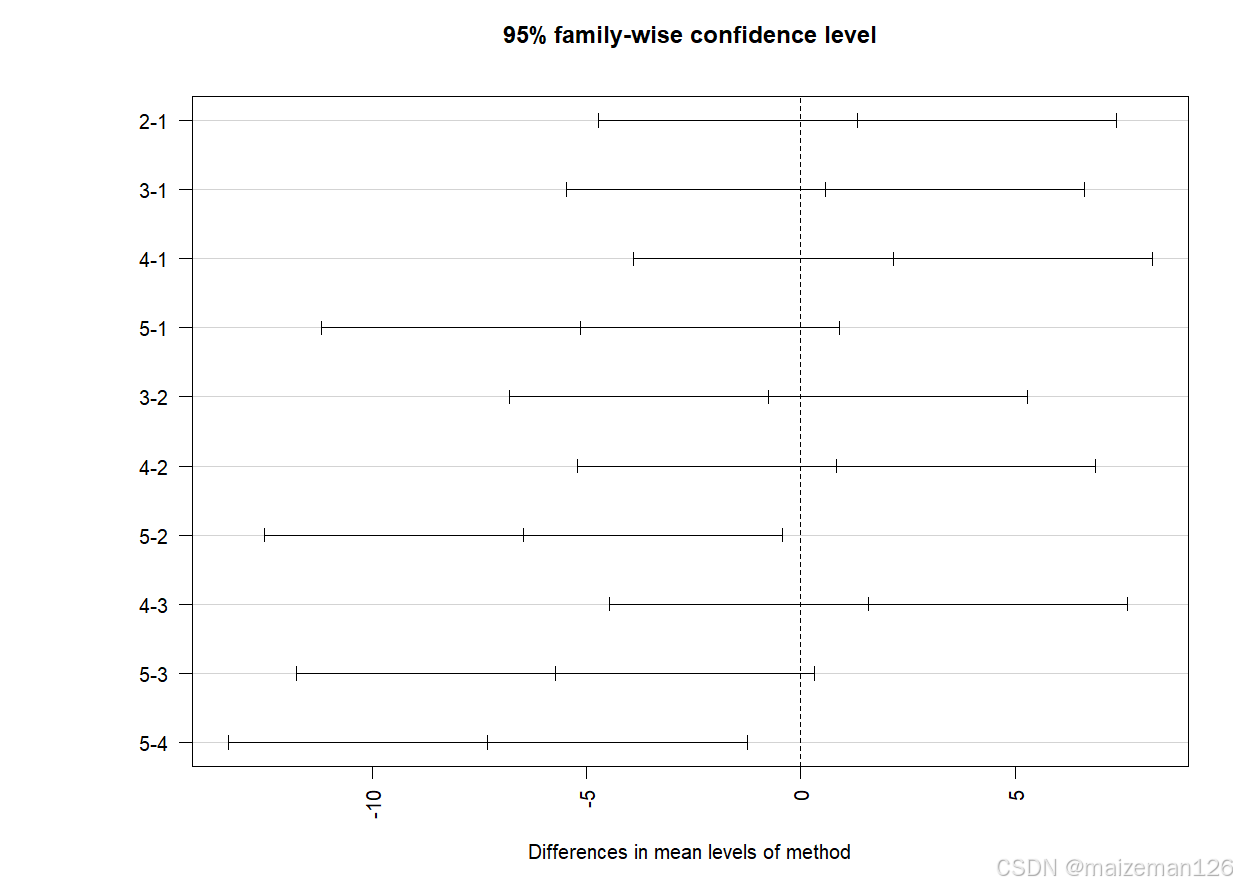
上图包含组间多重比较的置信区间,凡置信区间包含0的方法,说明除杂量均值差异不显著。
R的扩展包multcomp中的glht()函数提供了多重均值两一中图形展示方法,如下:
R
library(multcomp)
par(mar=c(5,4,6,2))
tuk<-glht(aov.model,linfct=mcp(method="Tukey"))
plot(cld(tuk,level=0.05),col="lightgrey")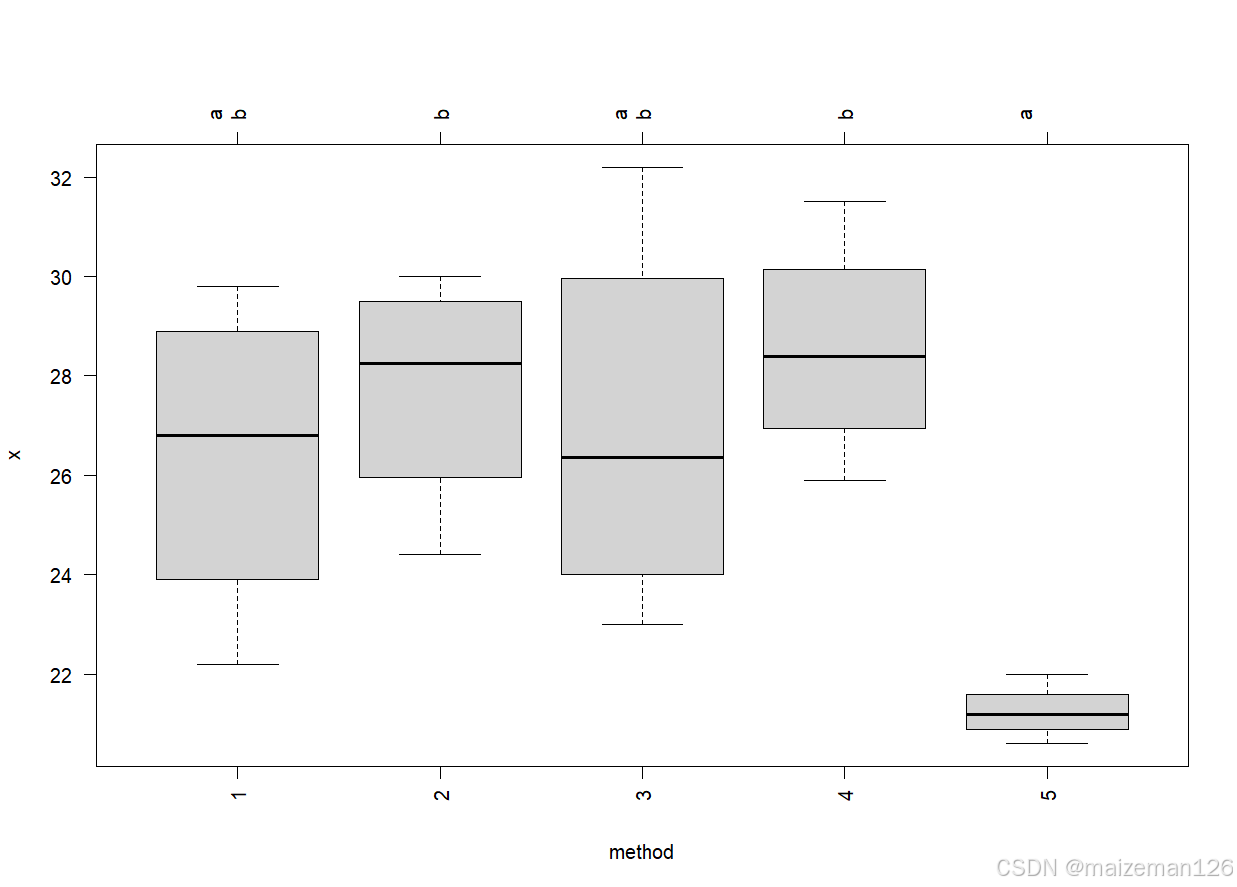
上图中有相同字母的组均值差异不显著。方法1、3、5有相同字母a,方法1、2、3、4有相同字母b;方法5和方法2、方法5和方法4差异显著,它们没有共同的字母。