Making Retrieval-Augmented Language Models Robust to Irrelevant Context
2310.01558v2 Making Retrieval-Augmented Language Models Robust to Irrelevant Context
检索增强语言模型(RALMs),它包含一个检索机制,以减少将信息存储在 LLM 参数中的需求。
这项工作分析并提高了 RALM 对嘈杂检索上下文的鲁棒性。 对检索鲁棒性大语言模型 的定义指出:(a)当相关时,检索到的上下文应该提高模型性能; (b) 当不相关时,检索到的上下文不应损害模型性能。 为此提出了两种方法,用于在 RALMs 中进行检索鲁棒性:
1.对大模型是黑盒访问权限,把检索器的稳健性视为自然语言推理NLI问题,给定一个问题和检索到的上下文,NLI模型可以预测上下文是否包含问答对,因此使用这样的NLI模型来识别不相关的上下文,如果上下文被标注为和问答对无关,就使用LLM的不检索的退避策略生成答案,这个方法太过严格,会舍弃相关的上下文。
2.提出一种训练RALM的方法。主要是对LLM进行微调。直观上,LLM没有用检索到的段落进行训练,因此对噪声检索的脆弱性在某种程度上是可以预料的。 因此执行了额外的微调步骤,教导LLM对嘈杂的环境具有鲁棒性。 核心挑战是生成用于微调的数据 ,我们描述了为单跳和多跳 问题自动生成此类数据的过程。 在单跳设置 中,假设可以访问黄金 QA 对和检索器,我们使用检索到的上下文创建训练示例,其中我们可以使用低排名或随机段落作为噪声上下文 。 在多跳设置 中,训练示例不仅需要包含检索到的上下文,还需要包含中间问题、答案和相关上下文,这些构成 问题分解(图3),这被证明对于多跳问题的高性能是必要的。 为了生成训练分解,使用强大的LLM,提示分解而无需任何检索。 然后对多个分解进行采样,并使用自一致性来识别高质量的训练示例。
【人话:单跳问题使用低排名或者随机段落作为噪声上下文;多跳问题先用LLM对问题及逆行分解,再对每一个分解进行采样。】
在五个 ODQA 基准上评估检索稳健性,其中四个包含多跳问题,其中检索器被多次调用
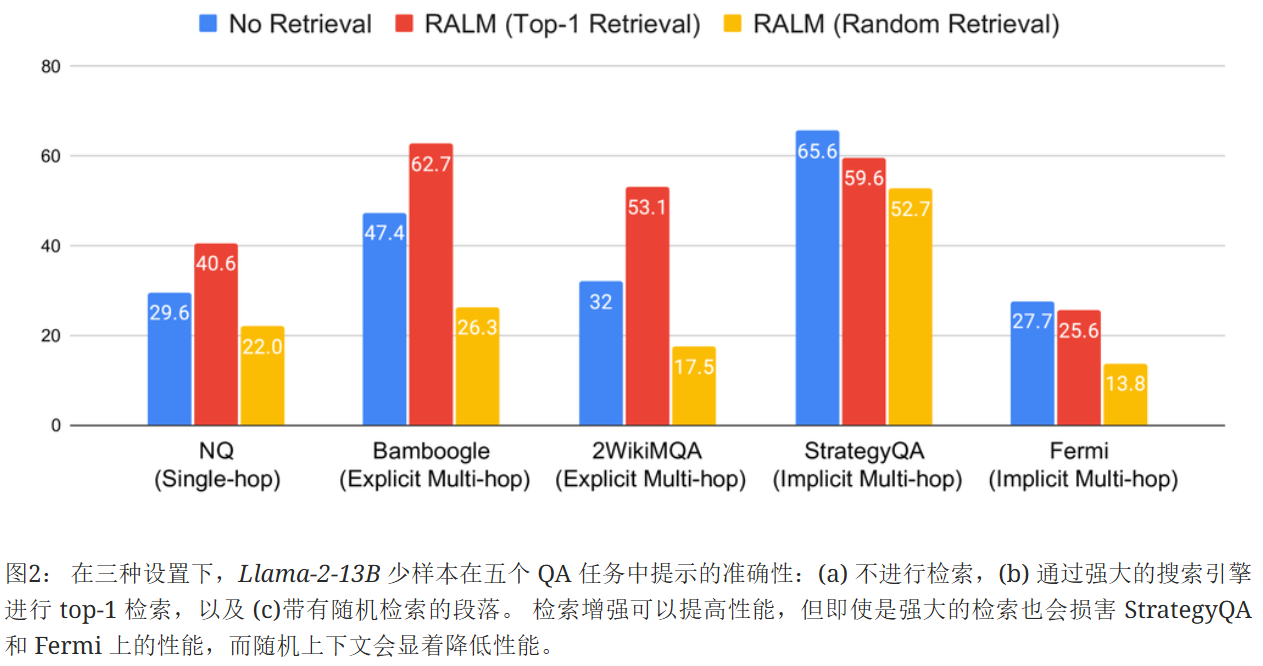
如图2,即使使用强大的检索器(前 1 名谷歌搜索),合并检索到的上下文实际上 损害 了模型在两个基准上的性能(StrategyQA 和 Fermi)。 此外,添加随机检索的上下文会显着降低所有五个数据集的准确性。 分析表明,不相关上下文会导致各种错误,包括从检索到的句子中复制不相关的答案,以及幻觉错误的答案和分解。
结果表明,微调 LLM 使其具有检索鲁棒性,使其能够忽略不相关上下文,同时提高其整体准确性。 当在测试时使用强大的检索器时,我们的微调模型优于没有检索的微调模型以及使用上下文学习提示的未训练模型。 为了测试对嘈杂上下文 的鲁棒性,我们在给模型随机检索上下文时评估 QA 准确性。 在此设置中,我们的微调模型与没有检索的微调模型的性能相当,证明了检索的稳健性。 此外,我们的消融研究表明,在相关和不相关上下文混合上训练模型,会导致模型对不相关上下文更具鲁棒性。
方法
专注于 ODQA 的 RALM。
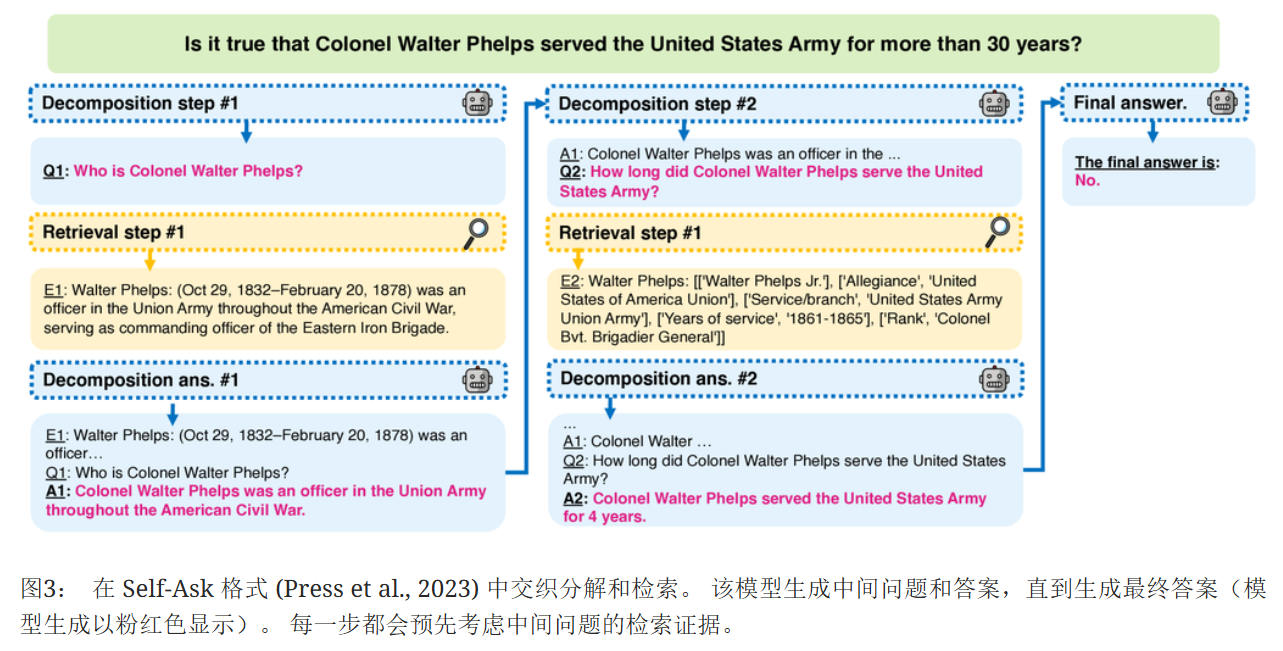
遵循最近的方法,例如 Self-Ask 和 IR-CoT,将检索与多跳问答交织在一起(参见图3)。 对每个中间问题执行检索,并将每个上下文添加到问题之前。 在单跳设置中,模型必须根据给定的问题和检索到的上下文生成答案。 在多跳设置中,模型必须生成中间问题和答案,直到得出最终答案,并且在每个中间问题之后调用检索器来处理原始问题。
使用NLI模型识别不相关的上下文
NLI 模型主要用于判断一个文本假设(hypothesis)在给定文本前提(premise)的情况下,是被蕴含(entailed)、中立(neutral)还是矛盾(contradicted)。在本文的研究场景中,将不相关上下文的识别转化为 NLI 问题。具体而言,把检索到的上下文作为前提,而最终答案以及中间的问答对作为假设。
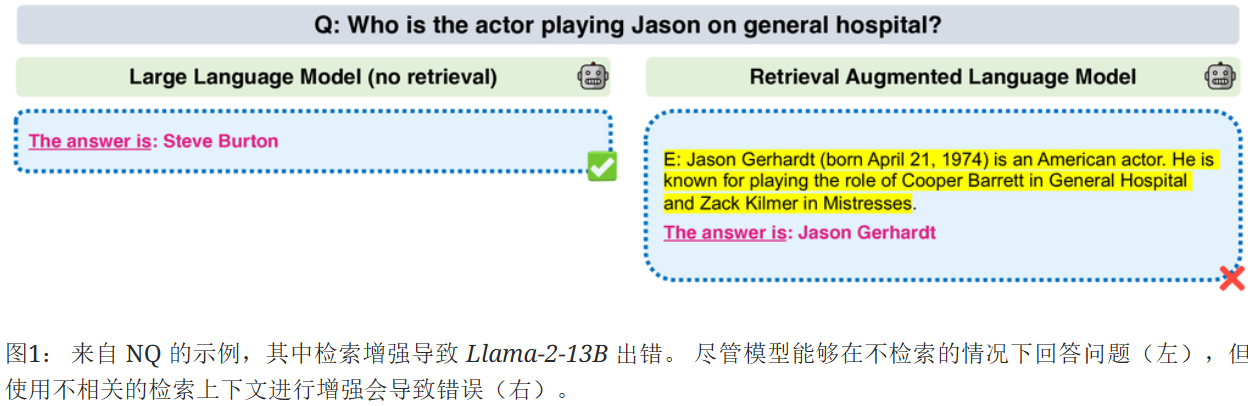
对于单跳问题,以 "谁在《综合医院》中饰演杰森?" 为例,检索到的证据 "杰森・格哈特是一名美国演员,以在《综合医院》中饰演库珀・巴雷特而闻名" 作为前提,问题和生成的答案 "谁在《综合医院》中饰演杰森?答:史蒂夫・伯顿" 作为假设。若 NLI 模型判定该假设与前提矛盾或中立,就表明检索到的上下文不相关,此时会采用标准的语言模型(不使用可能产生干扰的检索上下文)来生成答案。对于多跳问题,除了最终答案,还需使用所有检索到的证据作为前提,对每个中间问答对作为假设进行验证。例如在 "谁是沃尔特・菲尔普斯上校?" 这个多跳问题的求解过程中,对于中间问答对 "Q:谁是沃尔特・菲尔普斯上校?A:沃尔特・菲尔普斯上校是美国内战期间联邦军队的一名军官",需用检索到的相关证据来验证其是否被蕴含。
文中使用了一种简单的回退策略,即进行两次答案生成,一次基于标准语言模型pLM ,一次基于检索增强语言模型pRALM 。只有当 NLI 模型判定所有生成的答案(包括中间问题和最终答案)都被检索到的证据所蕴含时,才会使用pRALM生成的答案;否则,就使用pLM生成的答案。
这种利用 NLI 模型识别不相关上下文的方法,为提高 RALMs 对不相关上下文的鲁棒性提供了一种有效的思路,在一定程度上能够减少不相关信息对模型回答准确性的影响。但该方法也存在局限性,它可能会过于严格,导致一些相关的上下文被误判为不相关而被丢弃,进而影响模型在某些任务上的性能提升幅度 。
训练鲁棒的RALM
训练的必要性:由于上下文相关的 RALMs 在使用检索到的文本方面缺乏训练,面对噪声检索时较为脆弱。因此,训练 RALMs 忽略不相关上下文,比事后使用 NLI 过滤更为有效。并且,研究旨在探究使用相对较小的数据集(几百个示例)进行训练是否足够。
自动生成训练数据
- 单跳问题训练数据生成
- 数据基础:需要一个包含大量问题 - 答案对(q,a)的数据集,注意这里的数据集最初不包含上下文信息,同时还需要一个检索器R_C 。
- 相关上下文获取:为了让模型学习如何利用相关上下文,从检索器RC中获取与问题q相关的上下文。具体做法是,选取RC返回结果中排名第一的上下文,因为它通常与问题的相关性较高。
- 不相关上下文获取:一种是从RC(q)中选择低排名的结果,这些结果虽然与问题有一定关联,但关联程度较低,可视为不相关;另一种是随机选择其他问题q′的检索结果RC(q′)作为不相关上下文。比如,原本问题是关于历史事件,却选择一个体育赛事相关的检索结果作为不相关上下文,让模型学习区分相关性。
- 构建训练数据集:将选取的上下文rq与对应的问题q进行拼接,形成输入数据rq;q,再结合答案a,最终构建出训练数据集D=(rq;q,a)。这样,模型在训练过程中就能学习到不同上下文与问题、答案之间的关系。
- 多跳问题训练数据生成
- 多跳问题特点:模型需要生成一系列中间问题和答案,逐步推导出最终答案,这个过程中检索器会多次被调用。
- 初步生成与验证:利用一个强大的语言模型(如 GPT-3 的 code-davinci-002),在不借助检索的情况下,根据问题提示生成可能的分解步骤。由于语言模型生成的分解可能存在错误,所以需要进行验证。
- 有中间答案标注的情况:对于像 2WIKIMQA 这样包含中间答案标注的数据集,直接过滤掉那些生成的分解中不包含正确中间答案的示例。因为如果生成的分解与已知的中间答案不匹配,说明这个分解可能是错误的,不能用于训练模型。
- 无中间答案标注的情况:对于如 STRATEGYQA 这类没有中间答案标注的数据集,采用多次采样和自一致性验证的方法。具体来说,对每个问题,从生成分解的语言模型中采样 5 次(1 次贪婪解码和 4 次温度为 0.7 的解码)。只有当这 5 个分解都能得出正确的最终答案时,才保留其中贪婪解码的分解作为有效的训练数据。这是因为多次采样且结果一致,说明该分解的可靠性较高。
- 构建多跳训练数据集:经过上述验证后,将符合要求的检索上下文rx、之前生成的步骤x以及正确的生成内容y组合起来,形成训练数据集D=(rx;x,y) ,用于训练模型在多跳问题中正确处理上下文和生成答案。
模型训练:利用自动生成的数据D,通过标准最大似然法对模型进行微调,使模型能够基于rx;x生成y。在低数据场景下,单跳设置中限制数据集中的问题数量为 1000 个,多跳设置中为 500 个(将多跳问题的每个步骤拆分为多个示例),并使用参数高效微调(parameter efficient fine - tuning,如 QLoRA)技术。所有模型的训练时间不超过几个小时
实验设置
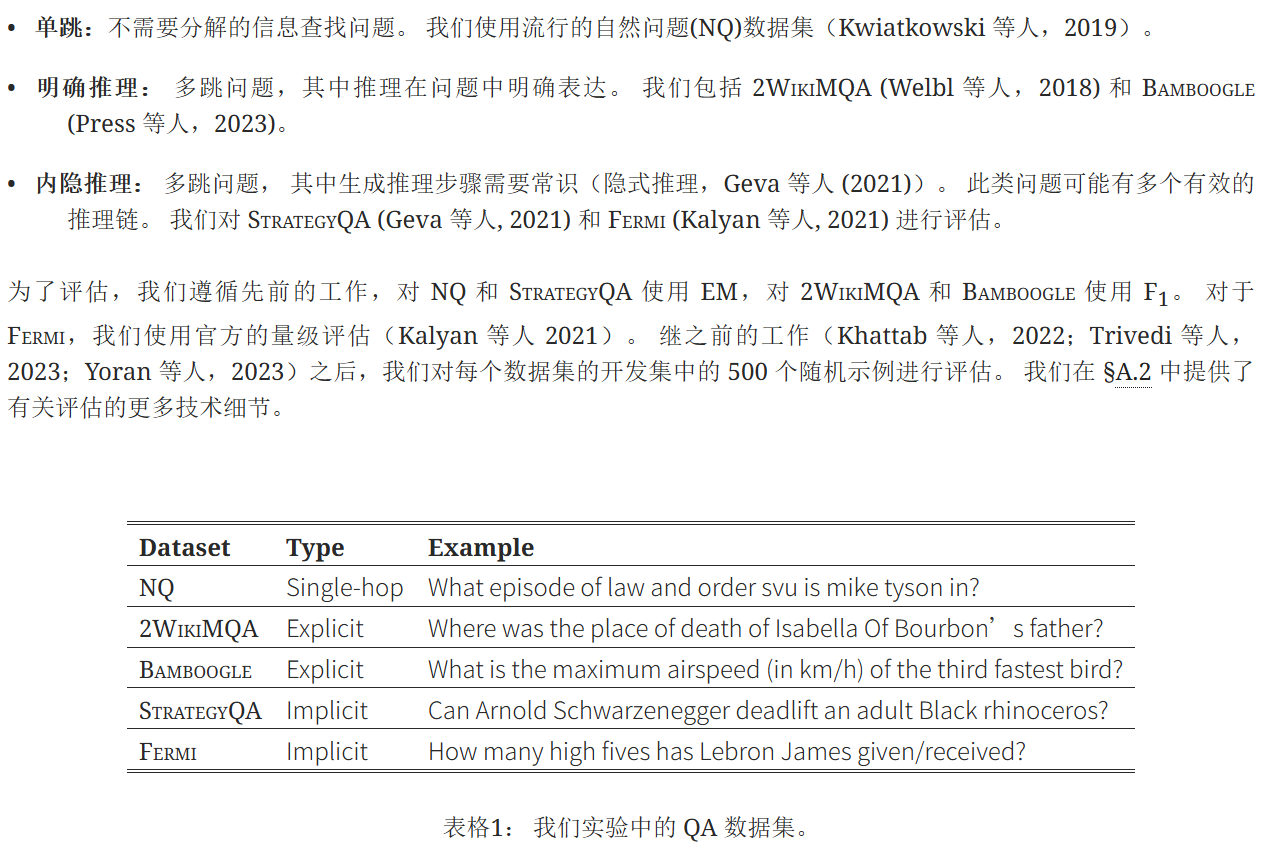
数据集:
模型
检索器:通过 SerpAPI 服务查询 Google 搜索以及开源 ColBERTV2
语料库是维基百科,因此使用API查询的时候定死查询的目标网站是wiki的
小样本提示基线:LLAMA2-13B,通过上下文学习(4-6个示例),以自问格式提示词进行QA
再NQ上用LLAMA2-70B进行评估。基线根据实例中的检索上下文二不同:
- 自问不检索 (SA-NR): 例子是没有 检索到证据的黄金分解。 我们使用此提示来评估模型在没有检索的情况下,仅依靠其参数记忆(即模型参数中编码的信息)时的性能。 作为额外的基线,我们使用此非检索提示,但在推理过程中仍然应用检索。
- 自问检索@1 (SA-R@1): 示例是黄金分解,每个步骤都预先添加了从 Google 搜索 检索到的最相关证据。
- 自问检索@10 (SA-R@10): 示例是黄金分解,在前面加上来自 Google 的最低排名段落(在大多数情况下排名第 10)。
- 自问随机检索 (SA-RMix) 示例是黄金分解,前面带有来自 Google 搜索 的排名前 1 或排名最低的证据,可互换。
基于NLI的模型:使用BART-large(在MNLI数据集上训练)。如果蕴含标签的概率为 ≥0.5,则一对问答是蕴含的。 所有提示基线的少样本都有 NLI 变体,称为 SA-*-NLI。 当没有蕴含时,我们使用来自 SA-NR 模型的生成,该模型仅使用参数化内存作为回退策略。
微调模型
在3个ODQA上对LLAMA2-13B进行微调,其中一个是单跳(NQ,1000 个训练样本),一个是显式(2WikiMQA,500 个问题,1,539 个样本),另一个是隐式(StrategyQA,414 个问题,1,584 个样本)。
数据生成:提示GPT3模型使用 SA-NR 提示生成分解。 2WikiMQA 包含中间答案,使用它们来验证生成的分解。 对于隐式 StrategyQA,我们仅使用最终答案,因此使用自一致性。 对每个问题进行 5 个分解采样(一个使用贪婪解码,四个使用温度 0.7),并且仅当所有分解都得出相同的正确答案时才保留贪婪解码分解。 为了验证生成的分解的质量,我们手动检查了每个数据集的 50 个分解,发现对于 StrategyQA,生成的分解在 90% 的时间内是正确的,对于 2WikiMQA,该比例超过 95%。 由于 Fermi 和 Bamboogle 包含的示例少于 300 个,因此我们仅将它们用于评估,并且不将它们包含在这些实验中。
将检索到的证据纳入训练示例中:
为了确保模型暴露在相关和不相关的上下文中,我们在每一步都以相同的概率使用前 1、低排名或随机证据。 我们将训练后的模型称为 SA-RetRobust。 我们包括训练没有检索到的上下文 (SA-NoRet) 或仅具有 top-1 证据 (SA-Ret@1) 的消融。
结果
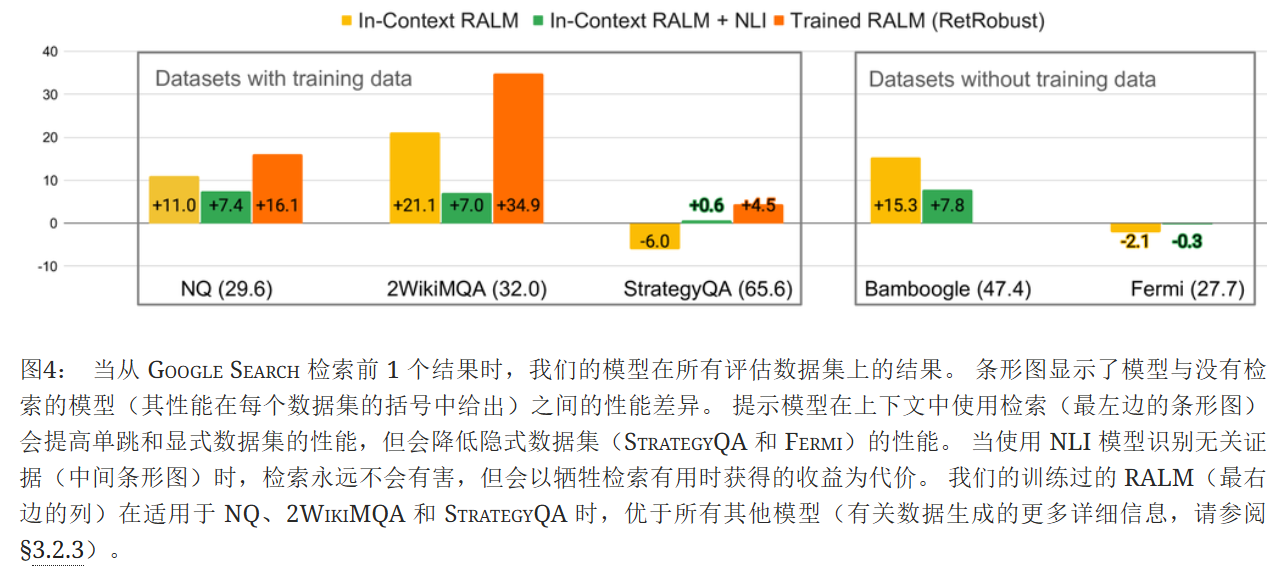
检索对模型性能的影响各异:在不同数据集上,检索对模型性能影响不同。对于单跳的 NQ 和显式推理的 2WIKIMQA、BAMBOOGLE,检索能提升性能;但在隐式推理的 STRATEGYQA 和 FERMI 上,检索反而降低性能。例如,使用 GOOGLE SEARCH 检索 top-1 结果时,在 NQ 数据集上,上下文检索增强的 RALM 相比无检索模型性能提升明显,而在 STRATEGYQA 数据集上性能下降。
NLI 模型的效果与局限:NLI 模型能有效识别不相关上下文,防止检索降低性能,但会限制检索带来的性能增益。在检索随机上下文或评估隐式推理任务时,NLI 变体模型表现最佳;然而在检索有帮助的情况下,如显式推理的 2WIKIMQA 和 BAMBOOGLE 数据集上,使用 NLI 模型会降低性能。
训练能提升模型鲁棒性和性能:在相关和不相关上下文混合数据上训练的 SA - RetRobust 模型表现最佳。在不同检索条件下,该模型在多数数据集上均优于其他模型。当检索随机上下文时,SA - RetRobust 模型能保持较好性能,与未使用检索训练的模型表现相近,表明其学会了忽略不相关上下文并更好地利用相关上下文。
增加模型规模并非提升鲁棒性的关键:对比 Llama-2-70B 和经过训练的 Llama-2-13B 的 SA - RetRobust 模型,在无检索时,Llama-2-70B 性能更优;但在检索 top-1 结果时,SA - RetRobust 模型超越所有 Llama-2-70B 的提示变体,说明增加模型规模不能充分提升模型对检索的利用能力。
分析
不相关上下文导致错误的情况:通过人工标注分析发现,不相关上下文在 73% 的情况下会导致模型出错。在 NQ 数据集中,使用低排名上下文时,多数错误(77%)是生成的错误答案实体出现在检索上下文中;检索随机上下文时,错误比例为 37%。对于多跳问题,在 2WIKIMQA 中,检索低排名段落时,多数错误(68%)出现在中间答案;而在 STRATEGYQA 中,错误更多出现在中间问题(77%)。
NLI 模型失败的原因:NLI 模型在识别相关上下文时,存在概率判断不准确的情况。在 NQ 和 2WIKIMQA 数据集中,许多检索有帮助的情况被 NLI 模型误判为低蕴含概率。人工分析发现,约一半情况是 NLI 模型判断错误,生成文本实际蕴含于检索上下文;其余情况中,至少三分之一是生成答案或分解正确,但检索上下文未直接蕴含生成内容,这可能是模型结合检索和参数知识的能力导致的。