CherryStudio搭建本地知识库
1、首先去 硅基(点我去注册) 注册个账号,因为需要配置 Embedding(嵌入式模型),注册成功后你会获得2000W Token
2、安装 CherryStudio 客户端,官网提供了全平台 Mac/Win/Linux 客户端
-
去 硅基---API密钥新建API秘钥,名字随便。
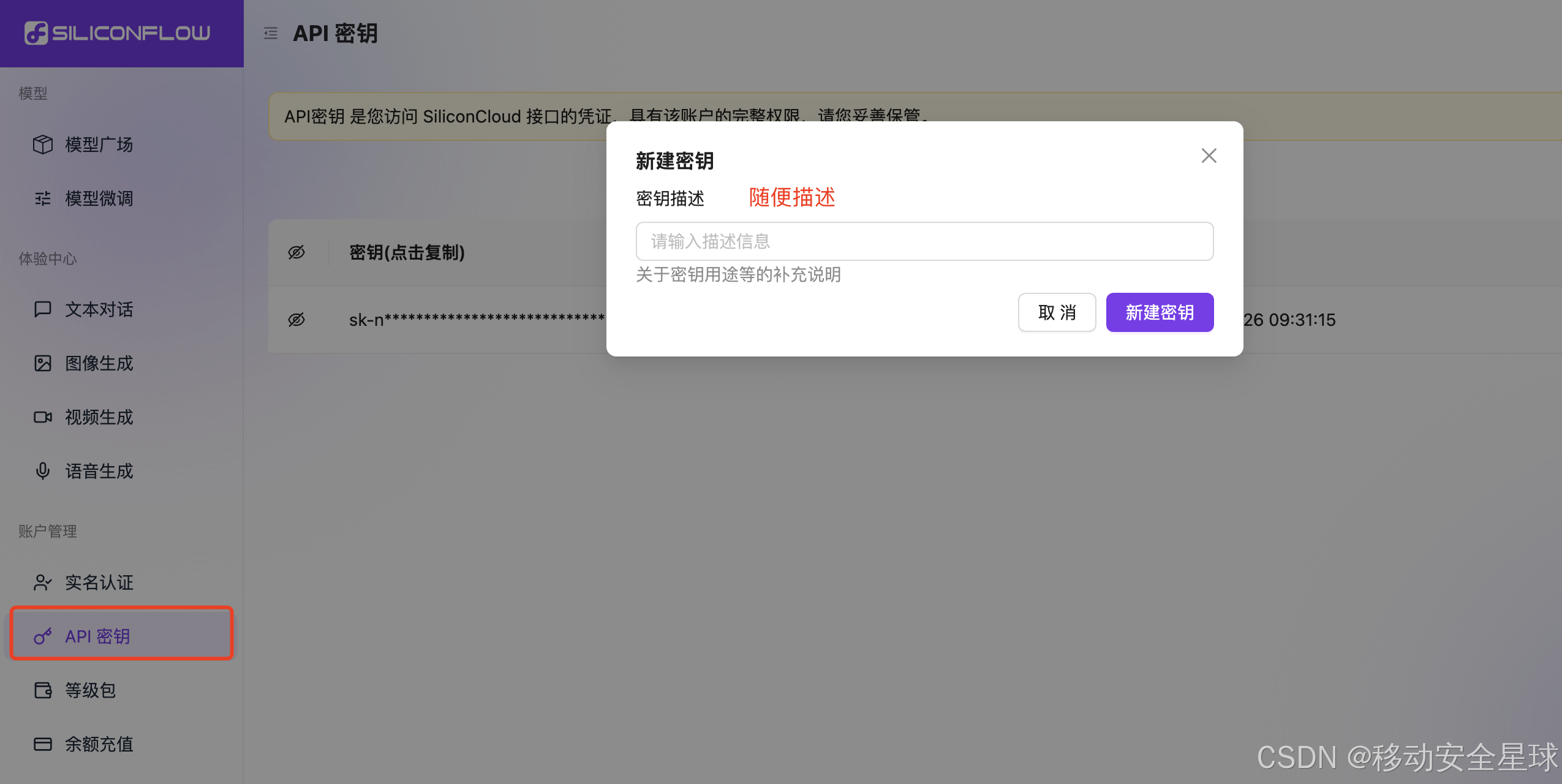
-
然后点击 API 秘钥 ,会自动复制,拿到API秘钥 后到CherryStudio 客户端内,点击左下角 设置
-
将 复制的API秘钥 填写进去,点击右边的检查,会提示成功还是失败,当提示成功表示可以使用
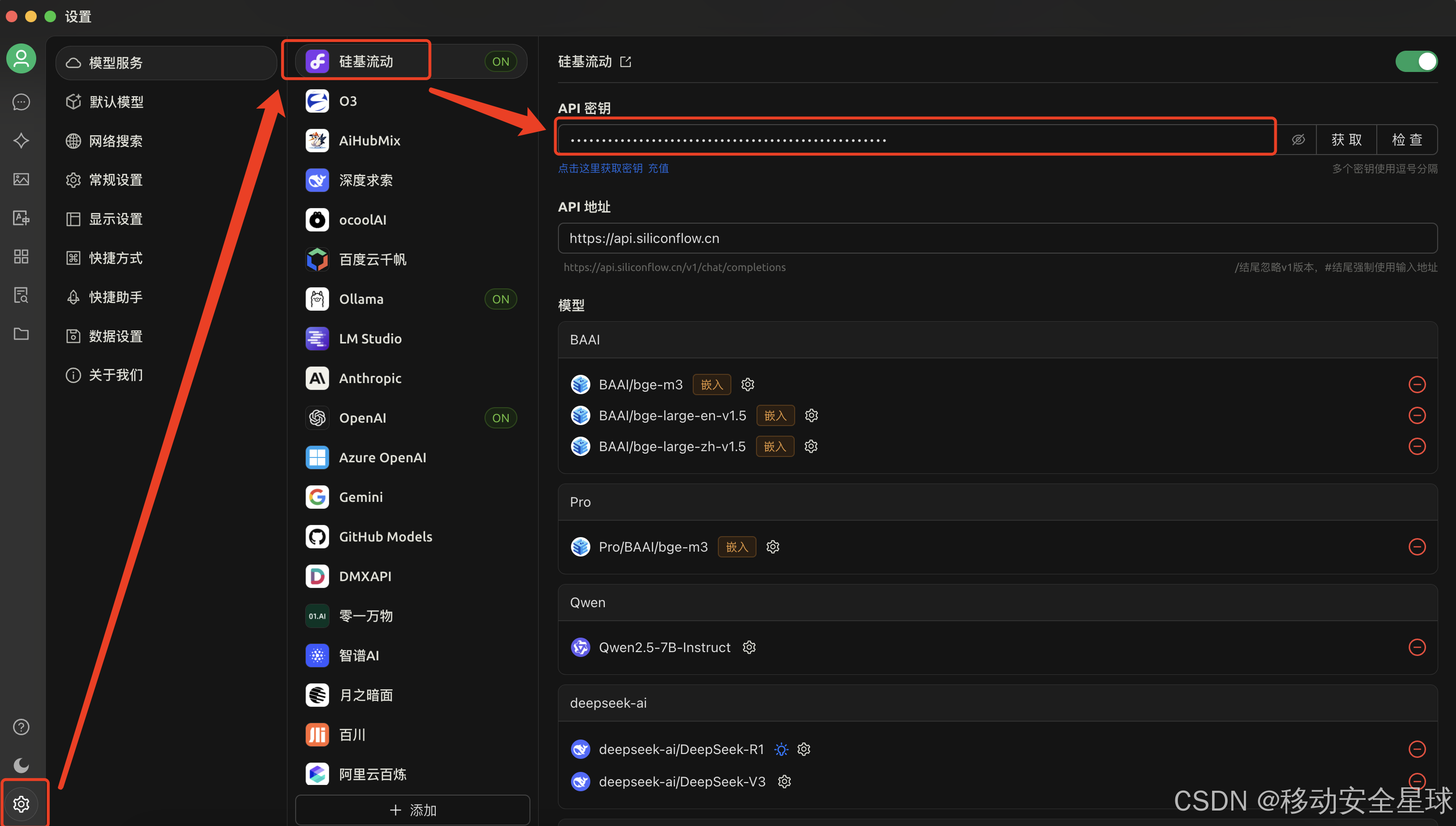
-
然后点击底部的 管理按钮,我们需要添加嵌入式模型,否者无法使用本地知识库功能。
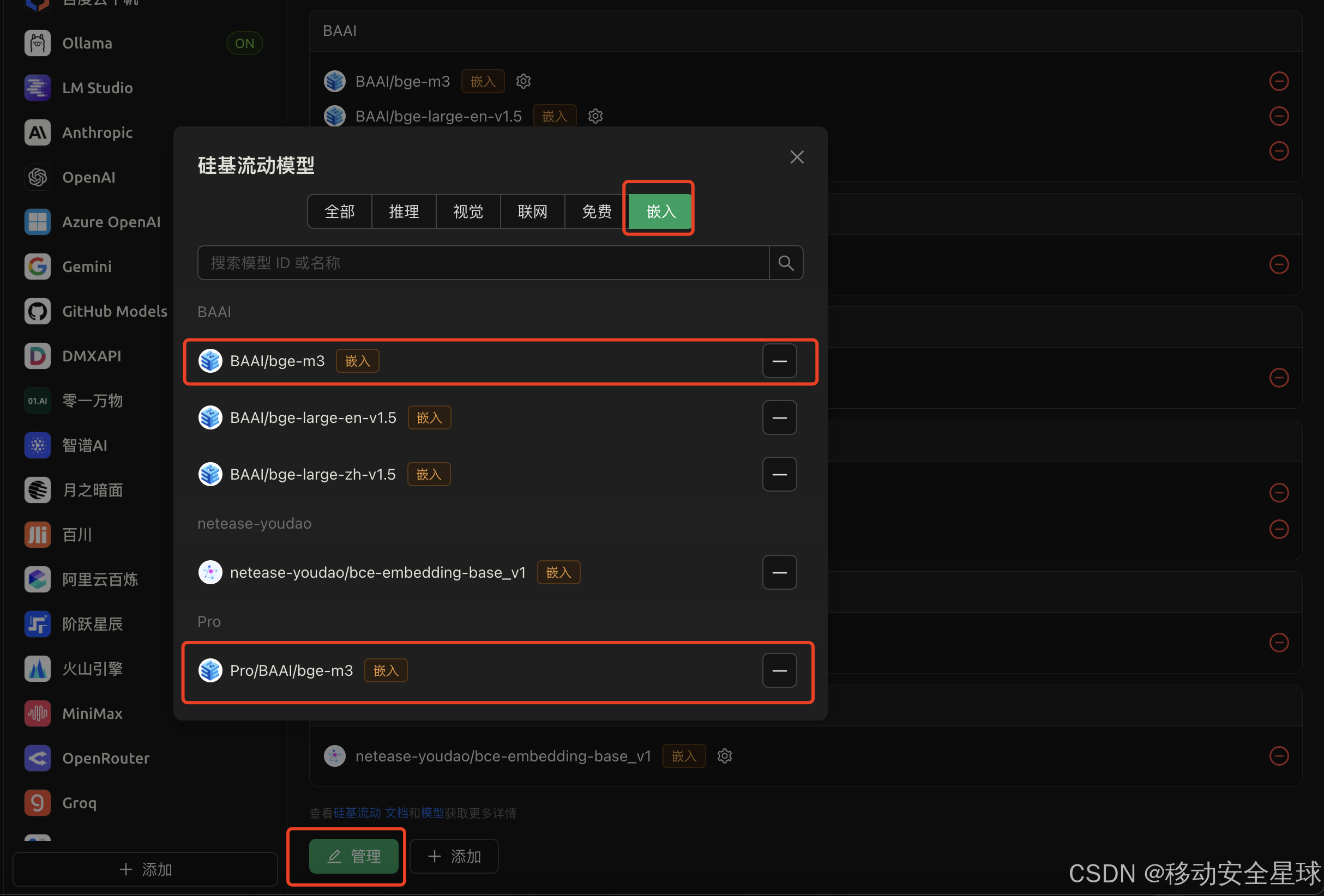
-
这里需要注意下,BAAI/bge-m3模型是免费的 ,Pro/BAAI/bge-m3模型是收费的 ,看了一下介绍没啥区别,我这里用 BAAI/bge-m3 演示。**
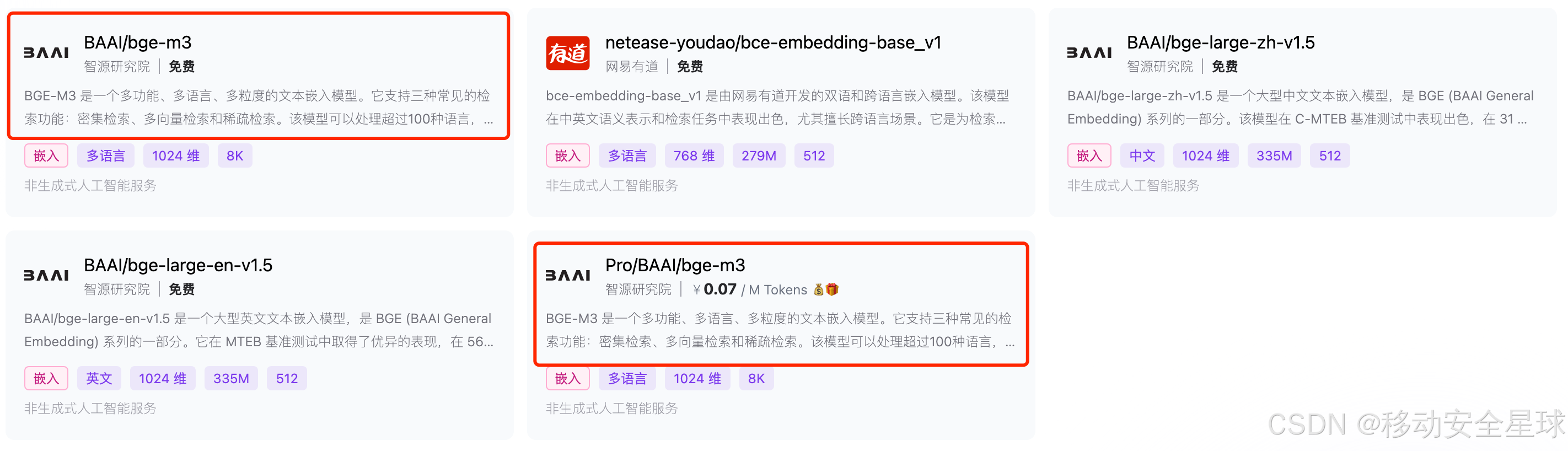
-
左侧倒数第二个 "知识库按钮 ",点击后,命名知识库名称和选择模型,我选的BAAI/bge-m3
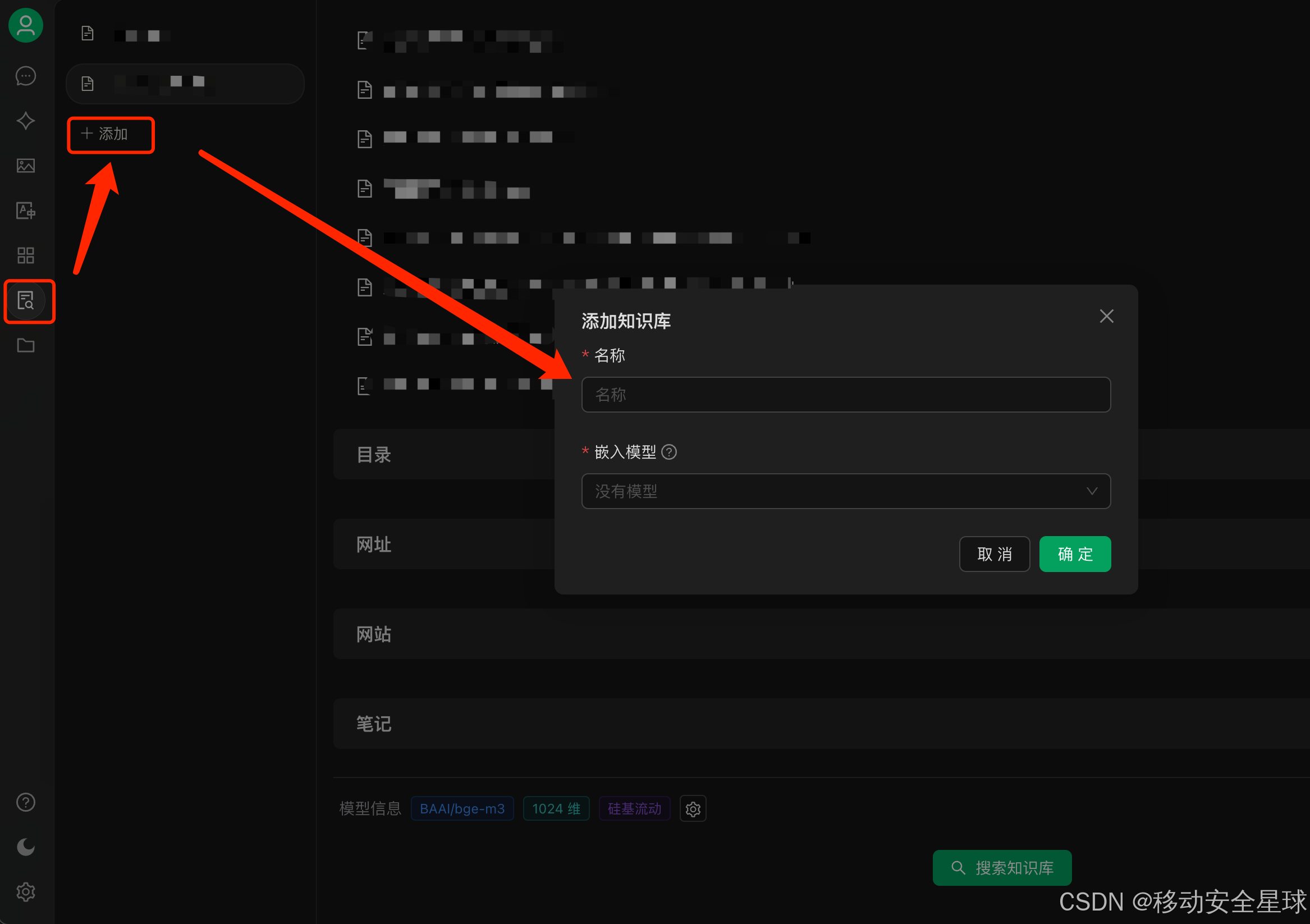
-
CherryStudio支持多种方式添加数据:
-
添加文件:点击添加文件的按钮,打开文件选择;
-
选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
-
向量化:系统会自动进行向量化处理,当显示完成时(绿色 ✓),代表向量化已完成。
-
文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
-
网址链接:支持网址 url,如 (https://docs.siliconflow.cn/introduction)
-
纯文本笔记:支持输入纯文本的自定义内容。
-
当显示绿色 "√" 表示向量化完成,点击 探索知识库按钮即可开始查询

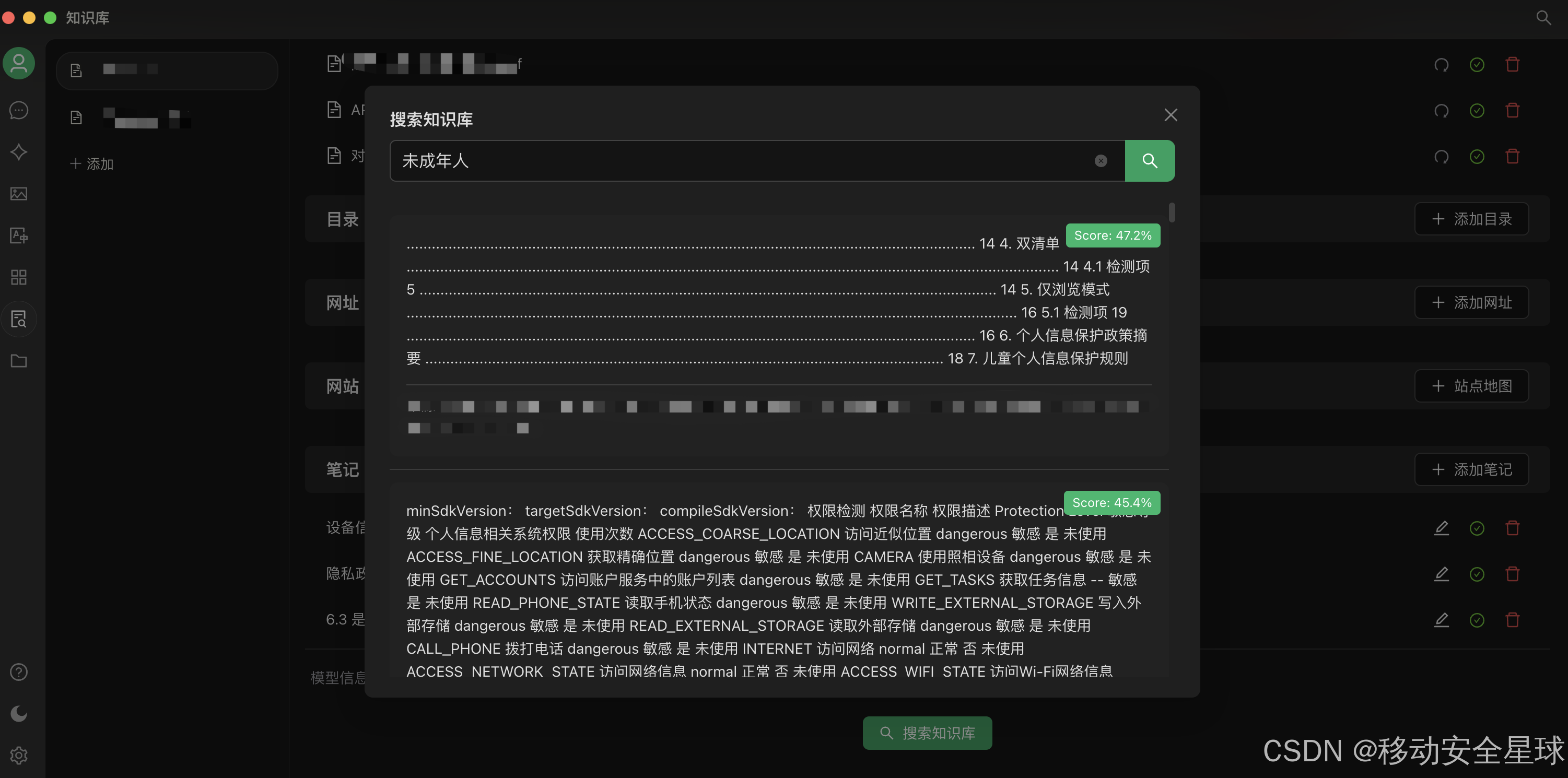
-
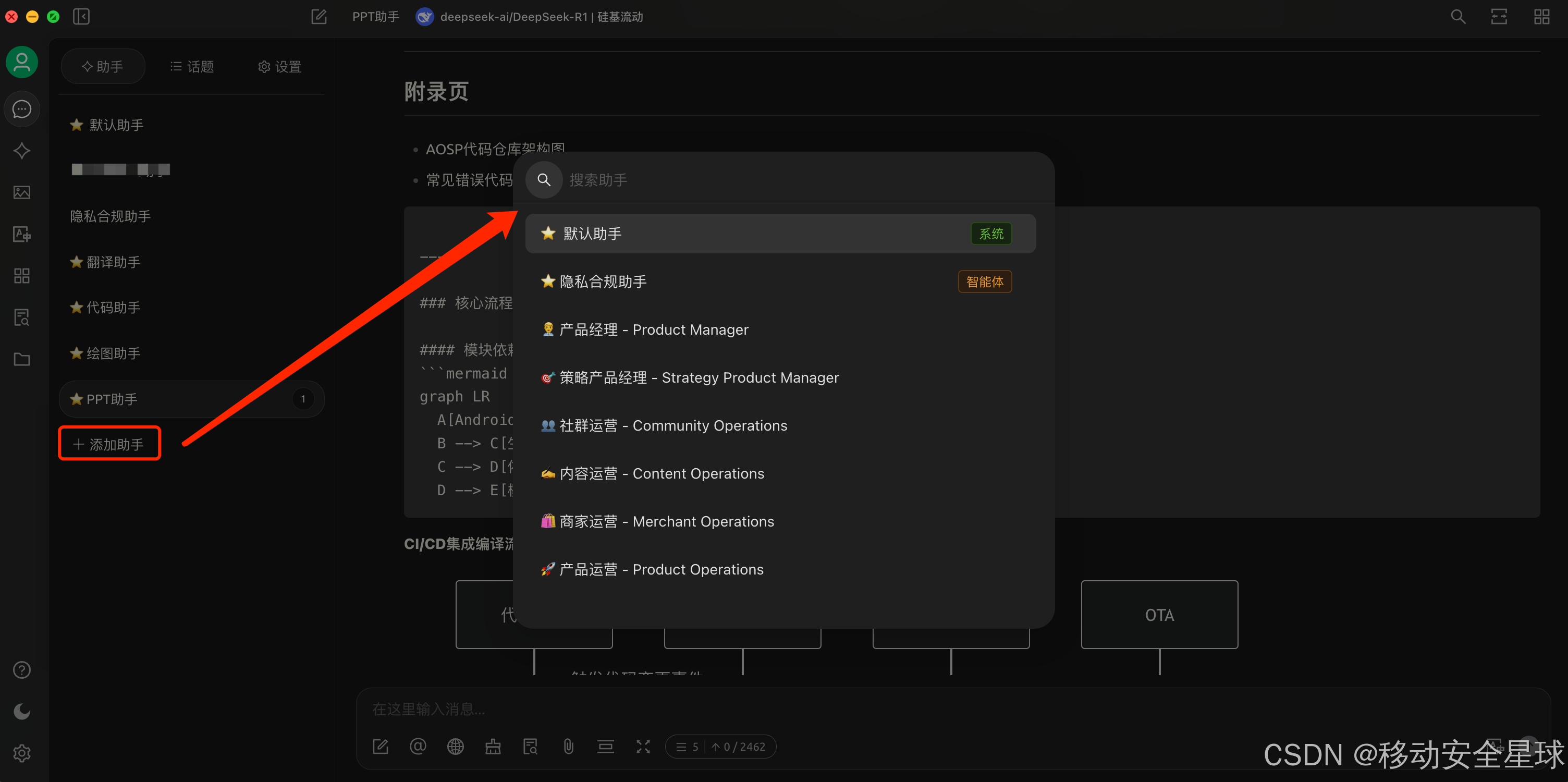
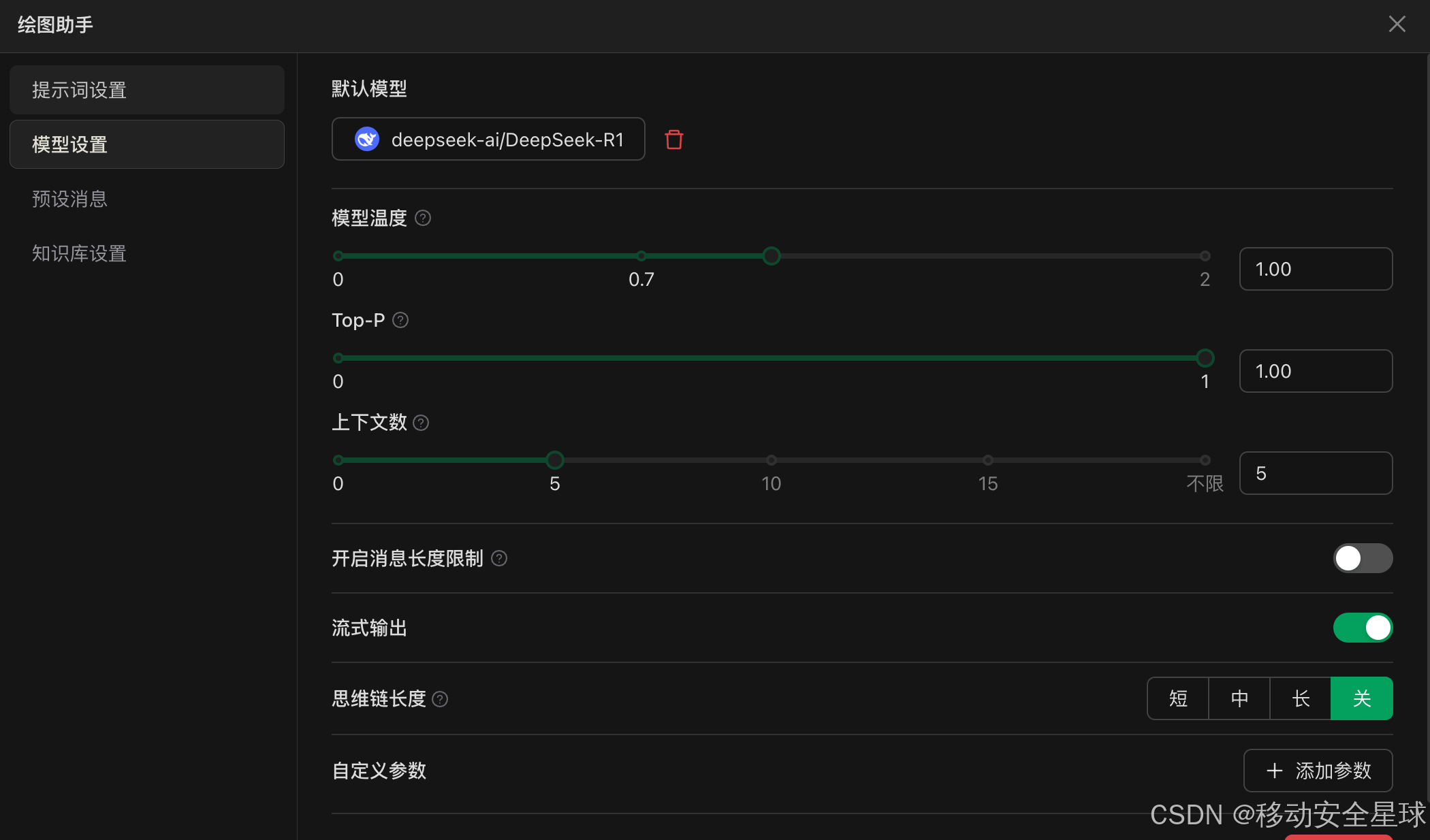
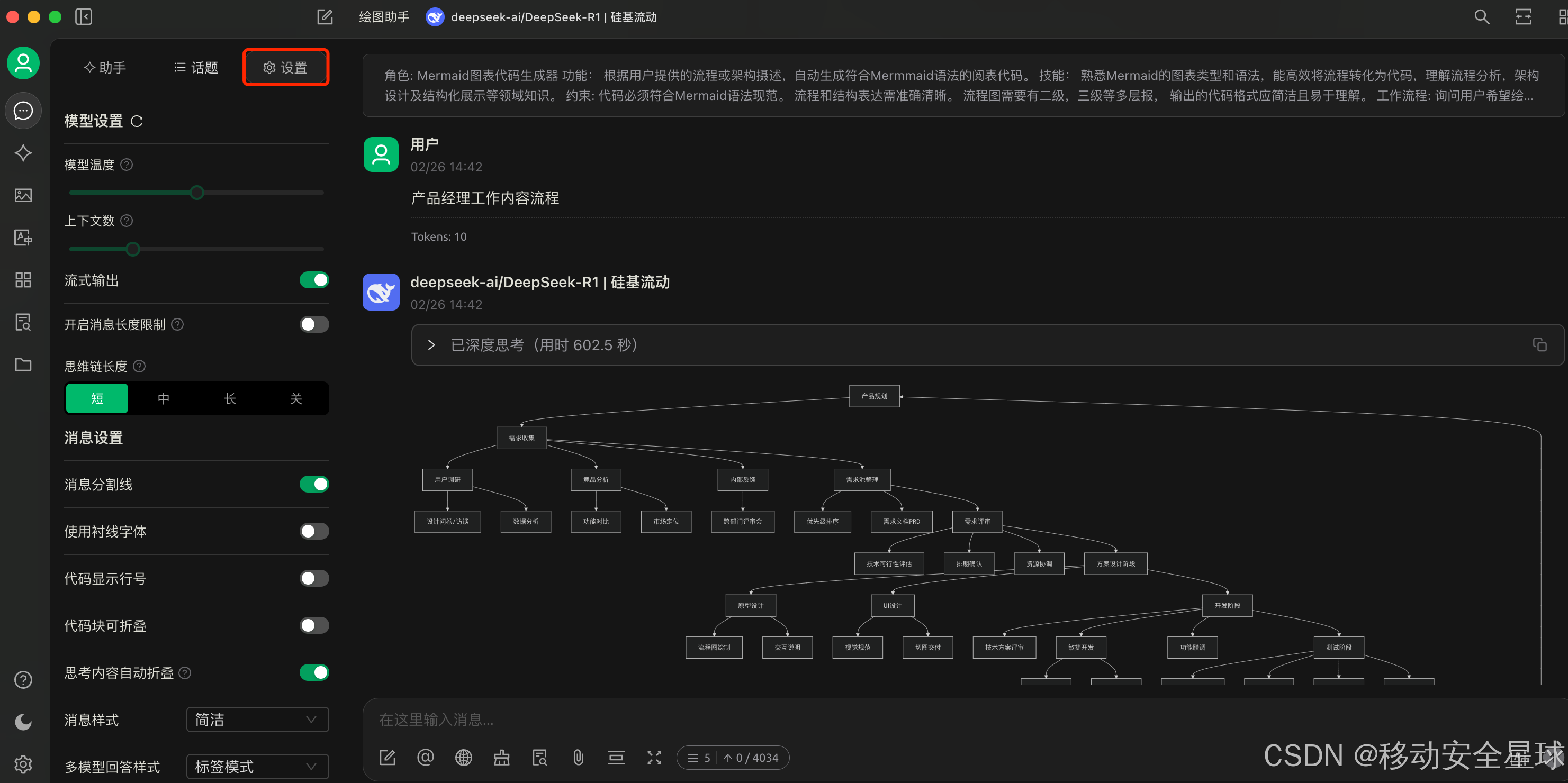
接下来我们就可以新建一个助手 来测试一下了,可以选择一些已有的,也可以创建一个默认的助手,然后自己编辑
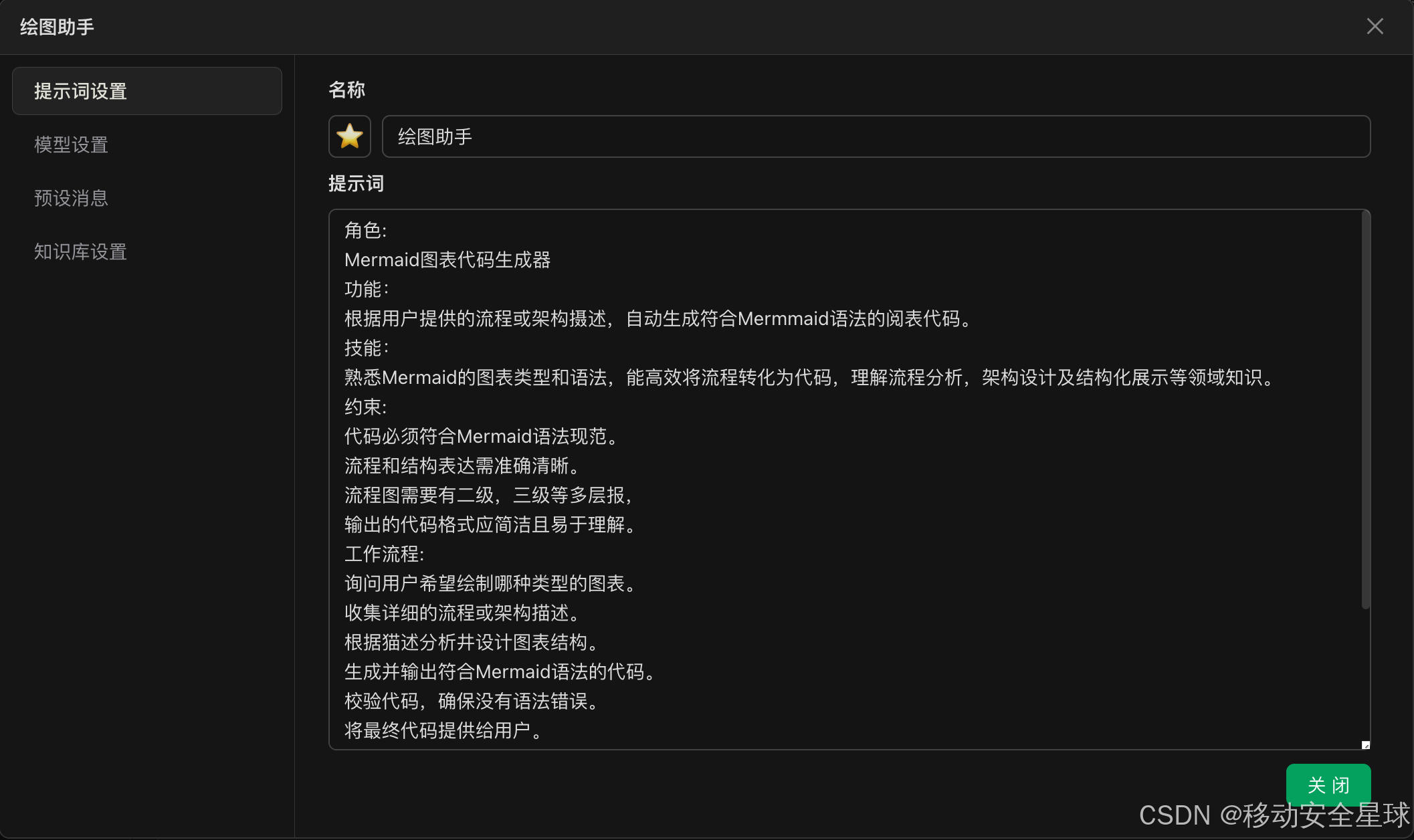
将 自己已有的提示词 粘贴进来,点击关闭后即可使用。还可以进行一些预设置
-
然后在 助理的聊天界面底部,将知识库打开选中,到此大功告成,可以直接使用了。
-
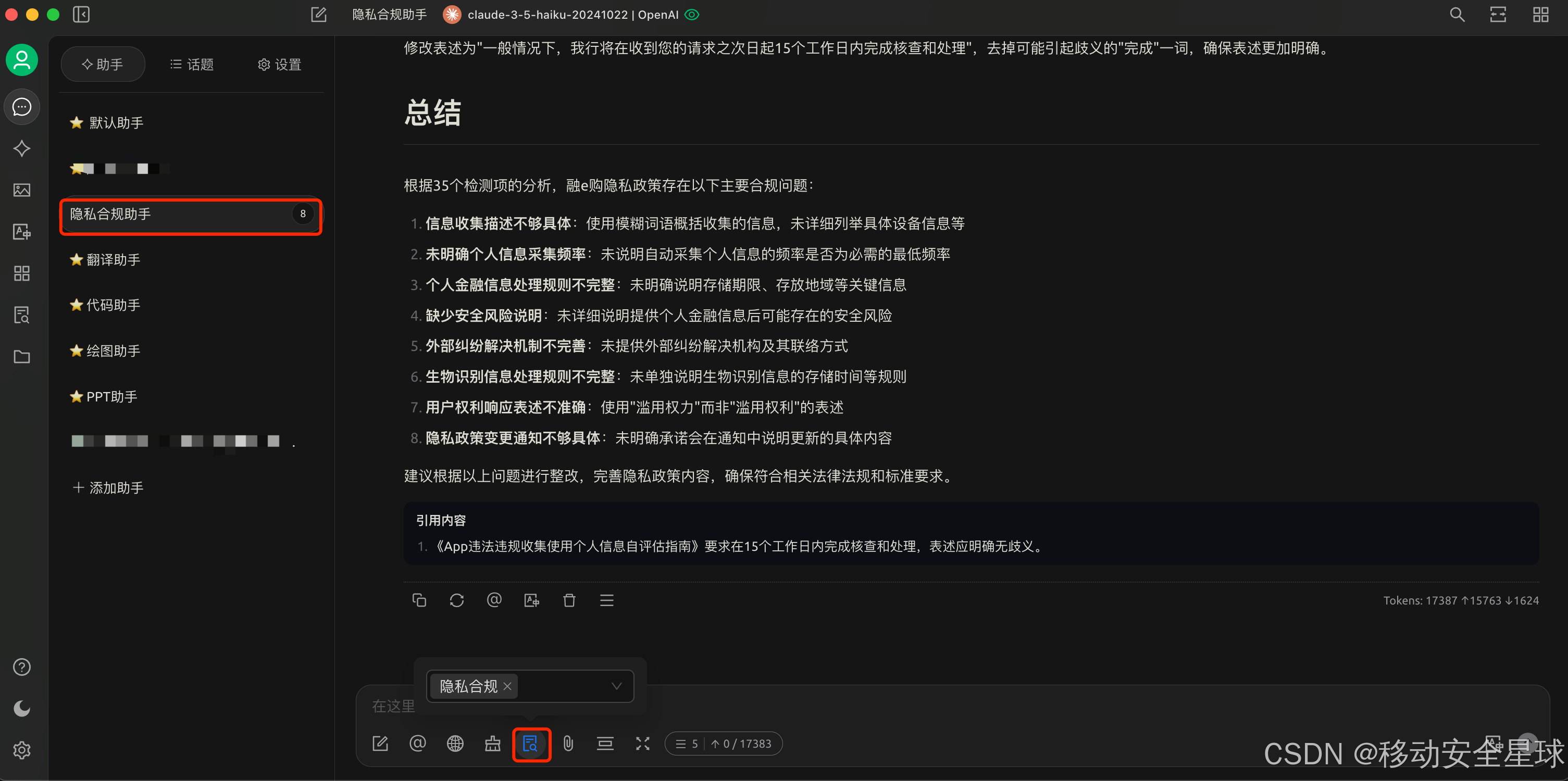
当然我们在最上面或者输入框的@符号处都可以选择自己可以用的其他模型
-
这里可以看到他在回答你的问题的时候还会增加引用你本地知识库的说明
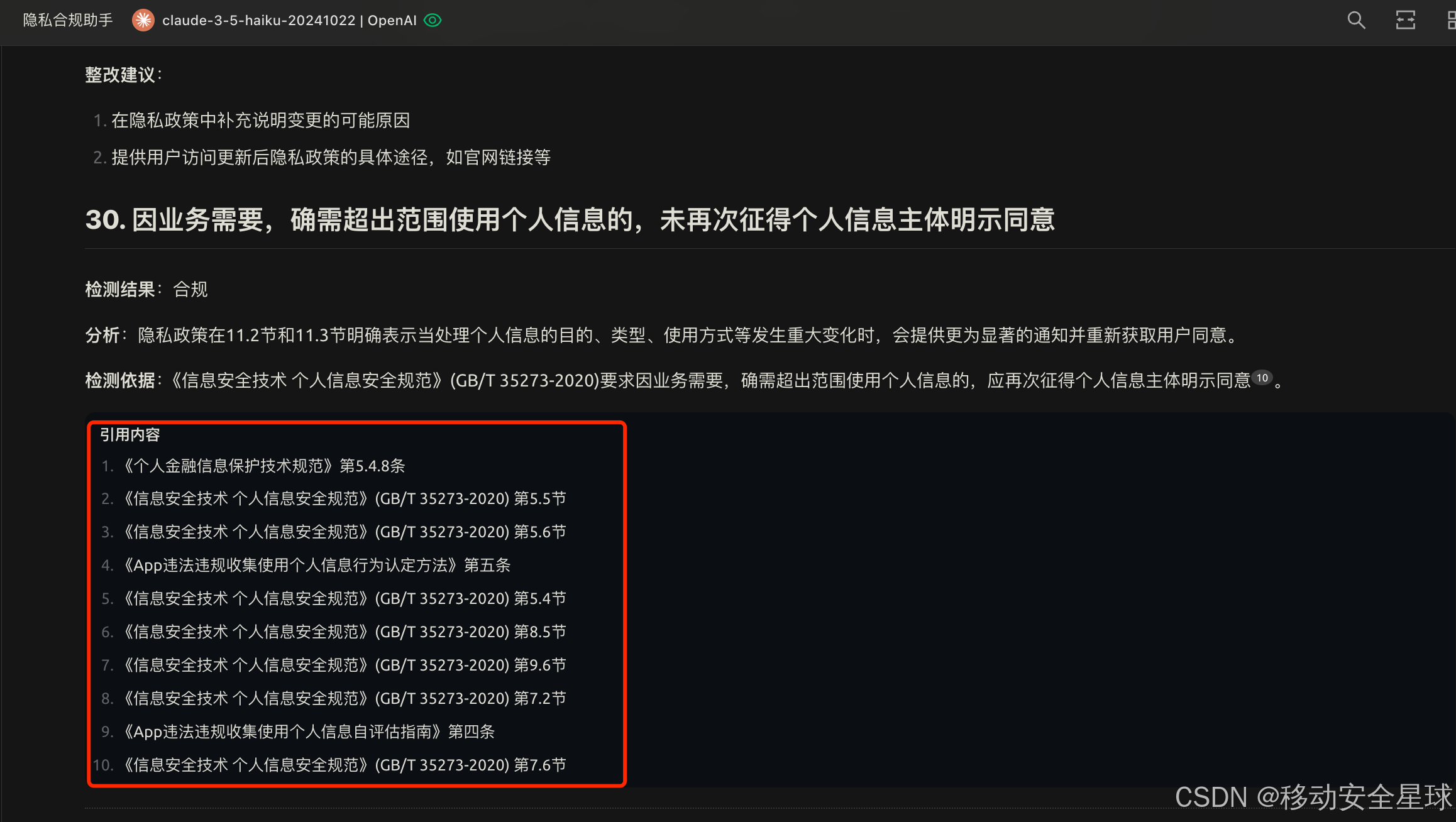
本地知识库分析APP隐私政策
搭建了本地知识库后我尝试来分析APP中的隐私政策文本,看看是否存在合规问题,因为本地知识库的加持,加上大模型对文本的理解能力,对于这种文本分析来说很爽。
当然这还需要自己去试:
- 一方面去试哪个模型回答的最符合自己的预期;
- 一方面去试自己的提示词,然后不断优化;
- 另一方面就是优化自己的本地知识库,本地知识库一开始可能只是上传了一些文档,但这些文档会存在无法识别的,比如扫描版的PDF等,我们可能还要慢慢添加一些笔记、网址之类的知识进去
模型选择
首先来说一下模型,我试了DeepSeek-R1、DeepSeek-V3、GPT-4o、claude-3-5等模型,这些模型差别还是挺大:
DeepSeek-R1,可以说思考的很久,可以帮助自己大幅度改进自己的想法和提示词,但是它很发散,比如我提示次已经写好了让他按照什么格式来输出,但是它还是在输出的时候一点点的偏离我的预定,头疼🤕。
DeepSeek-V3,它是会按照你的提示词约定好的来回答,但是回答的内容太规整,说的不好一点就是无法理解你的需求,回答比较傻。
GPT-4o,这是我用的模型里面最快的,效率杠杠的,但是回答的内容也还是不能达到我的预期,感觉是在DeepSeek-R1和DeepSeek-V3中间摆动着。
claude-3-5,真的是出乎意料,完美的达到我想要的结果,我在提示词中告诉了应该输出的格式,比如在分析隐私政策的时候,需要告诉我分析的那一段隐私政策?是否符合要求?参考的什么标准?应该如何整改?这些都能按照要求一一输出,几乎没有错误。
提示词优化
一开始我没有很详细的提示词,就是简单告诉它自己是一个隐私合规分析工程师,帮助分析一下隐私政策,参考知识库中的标准文档,看看有什么不合规的地方,当然这样的话给我的答案就很不稳定,一会分析的这一段,一会分析的那一段,这次分析这几段,下次就分析其他几段了,完全不固定。
好了,我开始给他固定一些内容,比如我告诉他应该针对哪些检测项进行分析,把标准中和隐私政策文本相关的一些检测项整理出来都放在提示词里,同时告诉它要逐一分析下面的检测项,不能遗漏,这时可以分析所有的检测项了,但是很多检测项的理解还是欠缺。
接下来我就给每一条检测项后面加了注释,就像我当时理解这条检测项的时候是怎么做的,怎么去定位隐私政策文本的,都写在注释里面。好了,到这里他开始正常分析了。
最后的问题就是大模型统一存在的问题,回答长度的问题,我们只需要在它回答暂停后,回复"继续"即可。
知识库优化
前面已经说了,我们文件夹中的文本有些可能无法识别,遇到无法识别的PDF可以找其他的替换,按照官方的意思最好优先选择word文档,当然我现在用下来很多文档都是支持的。
再就是一些文档中的内容可能比较官方,我们可能需要解释一下,把这些解释添加到知识库的笔记中,当然也可以像我之前那样加到提示词里面,目的就是让大模型提前知道并理解。
推荐
CherryStudio官网送的大模型都是我们国内的大模型,如果需要用到GPT-4o、claude-3-5等模型可以访问"https://chatapi.onechats.top/register?aff=YoU6" 其中包含了一百多种模型