在人工智能飞速发展的当下,大语言模型的性能表现备受关注。今天,我们就通过一份超详细的测试报告,深入探讨不同GPU在运行Deepseek-R1-70B模型时的表现,为大家揭开其中的奥秘。
01 测试背景与环境
本次测试由点动科技主导,对Deepseek-R1-70B模型在NVIDIA的RTX 4090、RTX A6000、L40 三款GPU上的推理性能进行了全面评估。测试选用VLLM作为推理框架,利用evalscope工具,在多样化的并发数、请求负载设定下,对模型的吞吐量、延迟、QPS以及Token生成效率等关键指标展开了细致的测试。
测试环境与设备参数:

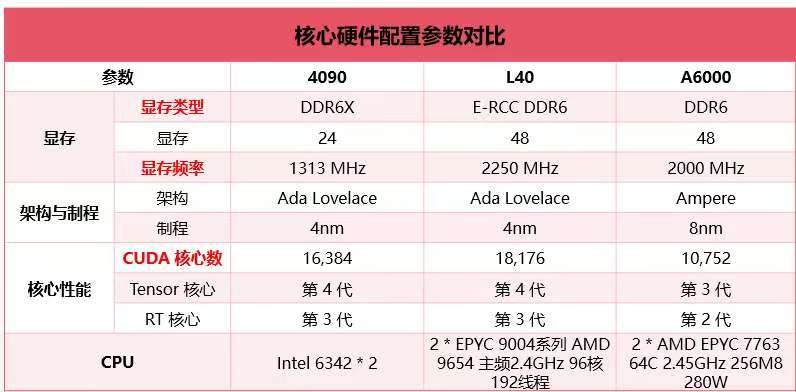
02********性能对比:三大GPU的高光时刻
吞吐量与延迟:总体速度谁更快?
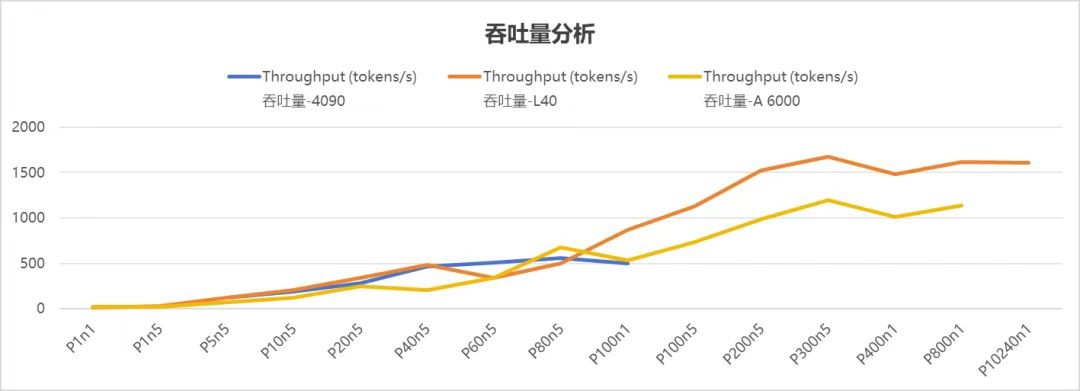
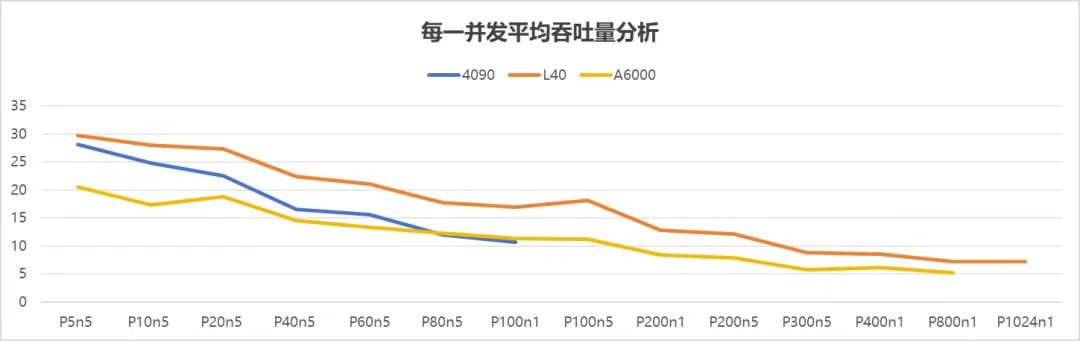
吞吐量是衡量GPU处理能力的关键指标,它代表着GPU每秒能处理的Token数量,数值越高,处理速度就越快,就像工厂里效率超高的生产线。
在低并发场景下(并发数 ≤ 20),4090 的总吞吐量与 L40、A6000 相比,差异并不显著。
当并发数≤40时,4090 在总吞吐量及平均吞吐量方面均超过 A6000。
当并发数>40,在总吞吐量和平均吞吐量上,呈现出 L40 设备性能最优,A6000 设备次之,4090 设备相对较弱。
通过吞吐量的数据分析:
4090运行DS-70B支持流畅并发≤40
A6000运行DS-70B支持流畅并发≤100
L40运行DS-70B支持流畅并发≤200
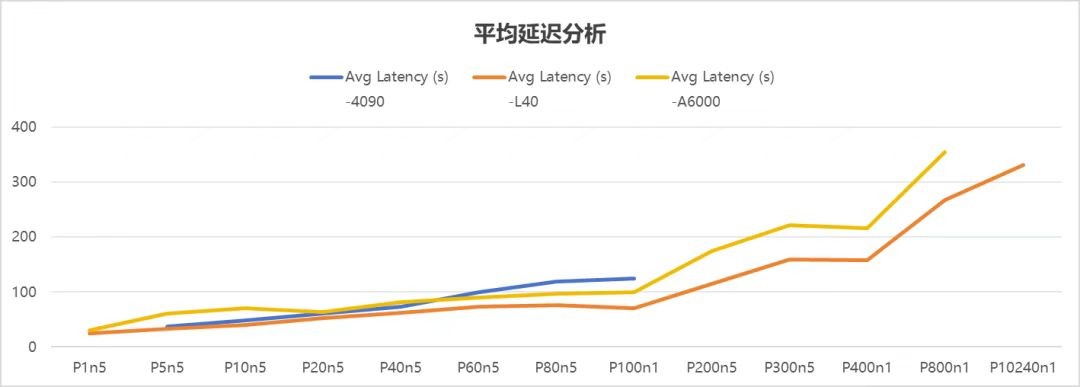
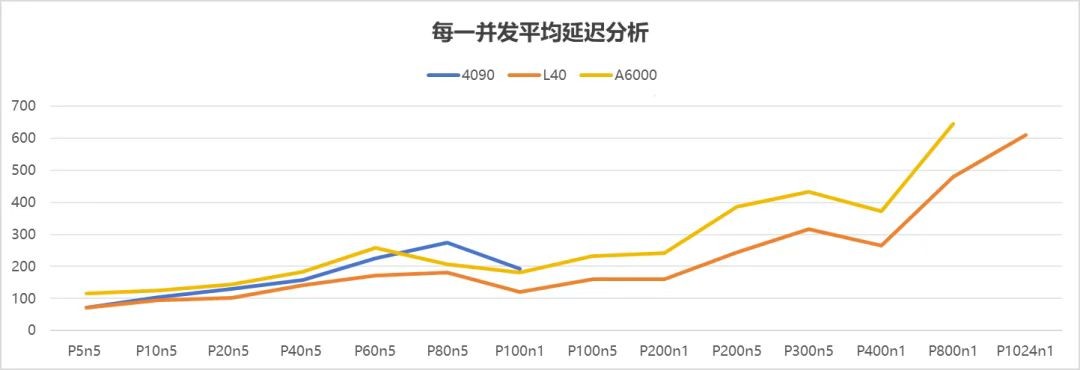
延迟直接关系到用户体验,它反映了从发出请求到收到响应的时间,就像你在餐厅点菜后等待上菜的时间,越短越好。
从上述图表可知,随着并发数增加,平均延迟呈上升趋势。其中,L40 的平均延迟增长态势整体更为平缓,表明其性能在并发数上升过程中相对稳定。A6000 的性能稳定性次之,4090 则相对较差 。
4090:在并发≤40时,延迟控制得很好,用户能获得流畅的体验,就像在快餐店能很快拿到餐食。但一旦超过80并发,延迟就像坐了火箭一样激增,出现明显卡顿,体验感开始下降。
A6000:相比4090,延迟控制更胜一筹,可在高并发的压力下,还是会出现波动,就像餐厅偶尔会出现上菜不及时的情况。
L40:它的延迟稳定性最强,即使在300并发的"大场面"下,仍能保持流畅,就像一家服务周到的高级餐厅,无论多忙都能及时响应顾客需求。
首Token延迟(TTFT):谁响应更快?
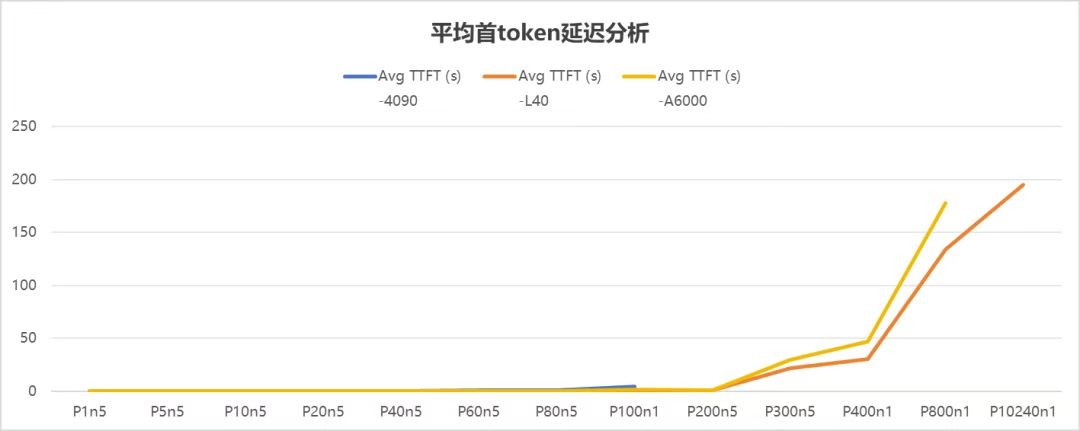 首Token响应时间决定了用户等待第一句回答的速度,是衡量GPU响应及时性的重要指标,好比你问别人问题,对方多久能给出第一个回应。
首Token响应时间决定了用户等待第一句回答的速度,是衡量GPU响应及时性的重要指标,好比你问别人问题,对方多久能给出第一个回应。
4090:在并发≤40时,响应迅速,能让用户快速得到反馈,仿佛对方立刻就回答了你的问题。但并发一旦超过这个范围,响应时间就会迅速拉长,等待变得漫长。
A6000、L40:这两款企业级GPU表现出色,在并发≤300时均能保持稳定响应,不会让用户等太久,沟通体验更流畅。
每Token生成时间(TPOT):谁更高效?
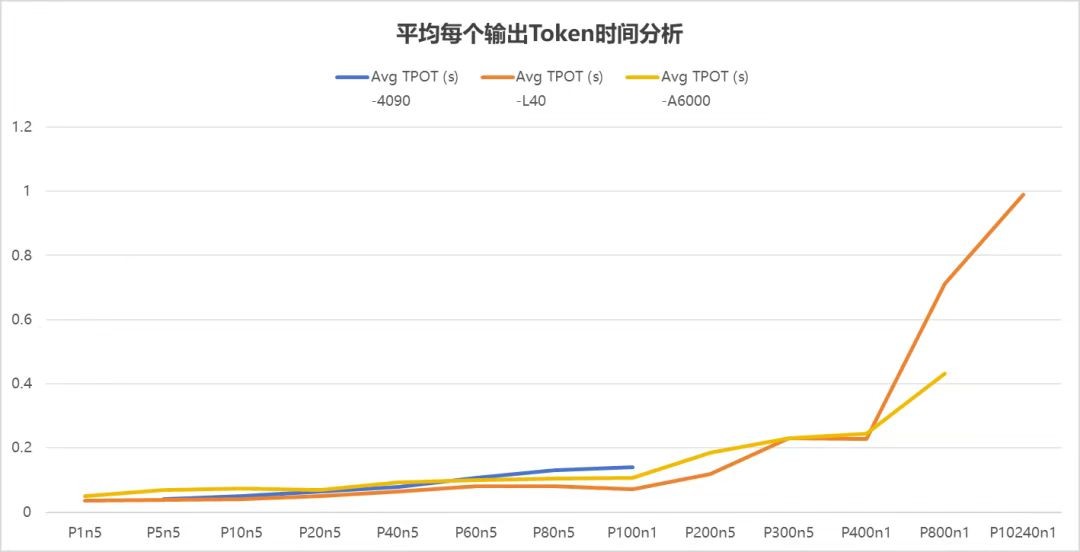 在生成每个token所需的平均时间(TPOT)这一衡量模型生成效率的重要指标上,同样是L40表现较为出色。较低的TPOT意味着模型能够更快速高效地逐词生成文本,反映出其在生成任务中的性能优势。
在生成每个token所需的平均时间(TPOT)这一衡量模型生成效率的重要指标上,同样是L40表现较为出色。较低的TPOT意味着模型能够更快速高效地逐词生成文本,反映出其在生成任务中的性能优势。
03
结论
响应速度影响因素
在运行 DS - R1 - 70B 模型过程中,4090、L40、A6000 的响应速度受多种因素制约,包括显存类型、CUDA 核心数、显卡级别、Tensor 核心、制程工艺等。此外,由于需通过互联网访问服务器,网络波动也极易对其产生影响。
显卡性能分析
A6000 作为企业级图形处理显卡,在本次 DS 推理模型测试中,其优势未能得到充分彰显。
****4090 单卡极限性能较高,在低并发场景下表现卓越。****然而,因其显存存在限制,在高并发时的表现逊于 A6000 与 L40 。
L40作为企业级显卡,在本次 DS 推理模型测试中,发挥超越的性能优势,并且在高并发的情况下表现非常稳定。
场景化推荐
低并发场景(<40) :建议优先选用 4090,因其具备出色的低延迟特性与高效能表现。
高并发场景(>200) :推荐使用 L40,其在吞吐量和稳定性方面显著优于其他配置。
高并发且注重性价比场景 :推荐 A6000,其并发量与效能和 L40 相近 。
04********结语
GPU选型并非简单的硬件参数对比,而是要综合考虑团队规模、预算以及业务需求,如果你正在为选择合适的GPU配置而烦恼,可关注点动科技!
我们根据不同GPU的特性和企业实际需求,量身定制了多种套餐方案 ,无论是低并发还是高并发场景,都能满足你的需求,帮助企业提升效率,降低成本,欢迎咨询!