一、推理系统分类
1. 按部署位置分类
(1) 云端推理
架构原理 :
云端推理依托分布式计算资源,采用微服务架构实现弹性扩展。核心组件包括API网关、负载均衡器和模型服务集群,通过Kubernetes实现自动扩缩容。典型场景如大规模推荐系统,需要处理高并发请求。
关键技术:
- 动态批处理:自动合并多个请求提升吞吐量
python
# TensorFlow Serving批处理配置
batching_parameters = tensorflow.serving.BatchingParameters(
max_batch_size=32,
batch_timeout_micros=10000)- 模型并行:将超大模型拆分到多个设备
python
# 使用PyTorch的Pipeline并行
model = nn.Sequential(
nn.Linear(1024, 2048).to('cuda:0'),
nn.ReLU(),
nn.Linear(2048, 1024).to('cuda:1'))(2) 边缘推理
硬件选型指南:
| 设备 | 算力 | 内存 | 适用场景 | 优化要点 |
|---|---|---|---|---|
| Jetson AGX | 32TOPS | 32GB | 自动驾驶 | TensorRT优化 |
| 昇腾310 | 16TOPS | 8GB | 工业质检 | 算子定制 |
| Coral TPU | 4TOPS | 1GB | 智能家居 | 量化压缩 |
部署实战:
bash
# 模型转换与优化全流程
python export.py --weights yolov5s.pt --include onnx # 导出ONNX
polygraphy convert yolov5s.onnx --fp16 -o engine.plan # TensorRT优化(3) 终端推理
移动端优化四步法:
1)模型转换:使用TFLite Converter
python
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()2)量化压缩:动态范围量化减小体积
3)硬件加速:调用NPU专用API
4)内存优化:预分配+内存池管理
2. 按实时性要求分类
(1) 硬实时系统(<10ms)
技术挑战:
-
必须保证严格时限
-
需要确定性执行
解决方案:
-
专用硬件(FPGA/ASIC)
-
静态内存分配
-
优先级调度
(2) 软实时系统(10-100ms)
优化技巧:
python
# ONNX Runtime低延迟配置
so = onnxruntime.SessionOptions()
so.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
so.intra_op_num_threads = 1 # 减少线程切换(3) 近实时系统(100ms-1s)
架构设计:

(4) 离线推理(>1s)
性能优化:
-
超大批次处理
-
计算与I/O重叠
-
分布式数据并行
3. 按模型更新频率分类
(1) 静态模型
安全机制:
python
# 模型完整性校验
import hashlib
def verify_model(model_path, expected_sha256):
with open(model_path, "rb") as f:
return hashlib.sha256(f.read()).hexdigest() == expected_sha256(2) 动态更新
热更新实现:
python
class ModelUpdater:
def __init__(self):
self.model = load_model()
self.lock = threading.Lock()
def update(self, new_model):
with self.lock:
if validate(new_model):
self.model = new_model
# 后台更新服务
def update_daemon():
while True:
new_model = check_update()
ModelUpdater().update(new_model)
time.sleep(3600)(3) 持续学习
联邦学习架构:
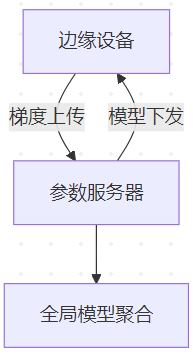
二、核心优化技术详解
1. 模型压缩技术
(1) 剪枝技术
算法原理 :
剪枝通过移除神经网络中的冗余连接或通道来减小模型大小。核心思想是基于重要性评分(如权重绝对值)移除对输出影响最小的参数。
三类剪枝方法:
1)非结构化剪枝:移除单个权重
python
# 权重剪枝实现
def weight_pruning(weight, prune_ratio):
threshold = torch.quantile(torch.abs(weight), prune_ratio)
return torch.where(torch.abs(weight) > threshold, weight, 0)2)结构化剪枝:移除整个通道
python
# 通道重要性评估
channel_importance = torch.norm(conv.weight, p=2, dim=(1,2,3))3)迭代式剪枝:交替训练与剪枝
数学原理 :
剪枝后的损失函数变化:
其中是剪枝后的权重
(2) 量化技术
量化过程:
-
范围校准:确定量化参数
-
量化反量化(QAT):模拟量化误差
-
整数计算:部署时使用INT8
精度分析:
| 量化类型 | 精度损失 | 加速比 | 硬件需求 |
|---|---|---|---|
| FP32→FP16 | <1% | 1.5-2x | GPU TensorCore |
| FP32→INT8 | 1-3% | 3-4x | NPU/TPU |
2. 计算图优化
(1) 算子融合
融合模式:
-
Conv+BN+ReLU融合 :
数学推导:
融合后等效权重:
-
线性层融合:
python
# 融合两个线性层
fused_weight = layer2.weight @ layer1.weight
fused_bias = layer2(layer1.bias) + layer2.bias(2) 内存优化
关键技术:
-
内存池:避免频繁分配释放
-
数据布局:NHWC vs NCHW
-
显存管理:CUDA内存池
优化示例:
python
# PyTorch内存优化
torch.backends.cudnn.benchmark = True # 自动优化卷积算法
with torch.cuda.amp.autocast(): # 混合精度
output = model(input)三、硬件加速深度解析
1. GPU优化全攻略
(1) TensorCore使用
最佳实践:
-
矩阵尺寸为8的倍数
-
使用FP16/INT8数据类型
-
内存地址对齐
python
# 确保TensorCore启用
x = torch.randn(64,32).half().cuda() # FP16
w = torch.randn(32,64).half().cuda()
y = torch.matmul(x,w) # 自动使用TensorCore(2) CUDA流优化
cpp
// 多流并行示例
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
// 在不同流上并行执行
kernel1<<<...,...,0,stream1>>>(...);
kernel2<<<...,...,0,stream2>>>(...);2. NPU专项优化
(1) 华为昇腾部署
cpp
// 加载模型
aclmdlDesc* modelDesc;
aclmdlLoadFromFile("model.om", &modelDesc);
// 创建输入输出
aclmdlDataset* input = aclmdlCreateDataset();
aclDataBuffer* inputBuffer = aclCreateDataBuffer(inputPtr, inputSize);
aclmdlAddDatasetBuffer(input, inputBuffer);(2) 高通DSP加速
bash
snpe-net-run --container model.dlc --input_list inputs.txt \
--use_dsp --enable_init_cache四、典型场景解决方案
1. 实时视频分析系统
边缘端架构:
python
class VideoAnalyzer:
def __init__(self):
self.model = load_tflite("model_quant.tflite")
self.buffer = np.zeros((8,256,256,3))
def process_frame(self, frame):
self.buffer[:-1] = self.buffer[1:] # 滑动窗口
self.buffer[-1] = preprocess(frame)
return self.model(self.buffer)优化要点:
-
帧率:30FPS → 每帧处理时间<33ms
-
模型大小:<15MB
-
功耗控制:<5W
2. 大规模推荐系统
云端架构:
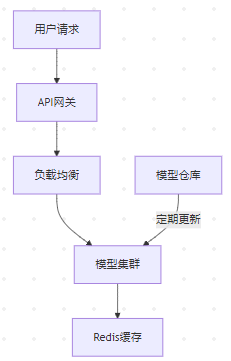
关键技术:
-
异步批处理
-
模型热更新
-
A/B测试分流
五、性能调优工具箱
1. 分析工具对比
| 工具 | 适用场景 | 关键功能 |
|---|---|---|
| PyTorch Profiler | 训练/推理 | 算子耗时分析 |
| NVIDIA Nsight | GPU内核 | 计算利用率 |
| ARM Streamline | 移动端 | 功耗分析 |
2. 优化检查清单
-
模型是否量化(INT8/FP16)
-
是否启用硬件加速
-
批处理大小是否优化
-
内存访问是否连续
-
计算/通信是否重叠