小米数据挖掘算法
一、核函数(Kernel Function)有什么用
核函数是一种 用来计算数据在高维空间中内积 的数学工具,不需要显式地进行维度变换,即可在原始空间中完成高维特征的计算。它是核技巧(Kernel Trick)的核心,使得某些线性模型(如 SVM)能在非线性空间中工作。
核技巧:将低维非线性问题映射到高维线性问题,并通过核函数避免显式映射。
1.1. 内积 vs 映射
设有两个向量:x = [x1, x2],我们希望用一个非线性函数映射到高维:
Φ(x) = [x1², √2 x1 x2, x2²]则内积为:
Φ(x) · Φ(y) = (x1²)(y1²) + 2(x1 x2)(y1 y2) + (x2²)(y2²)
= (x1 y1 + x2 y2)²即:
K(x, y) = (x · y)²这就是一个核函数(多项式核),用原始空间的点积就等价于高维空间的内积。
1.2. 常见核函数
| 名称 | 表达式 | 特点 |
|--------------|---------------------------------------------|----------------------------------|
| 线性核 | K(x, y) = x · y | 不做映射,等价于原始空间 |
| 多项式核 | K(x, y) = (x · y + c)^d | 模拟多项式特征组合 |
| RBF核(高斯核) | K(x, y) = exp(-||x - y||² / (2σ²)) | 类似局部影响,有无限维度映射能力 |
| Sigmoid核 | K(x, y) = tanh(α x · y + c) | 类似神经网络中的激活函数 |
| 拉普拉斯核 | K(x, y) = exp(-||x - y|| / σ) | 类似 RBF,适合某些噪声场景 |二、知道熵(Entropy)么?
熵是信息论中的一个核心概念,用于衡量随机变量的不确定性或信息量 。
在机器学习中,熵常用于分类任务中的 特征选择(如 ID3、C4.5 决策树),用于衡量一个集合的"纯度"。
2.1. 熵的定义公式(以离散分布为例)
对于一个类别分布 P = { p 1 , p 2 , . . . , p n } P = \{p_1, p_2, ..., p_n\} P={p1,p2,...,pn},熵的计算公式为:
H(P) = -∑(p_i * log₂(p_i))其中 p i p_i pi 表示第 i 类的概率,熵越大,表示分布越均匀(不确定性越高)。
2.2. 场景题:比较两个集合的熵
场景:
- 集合 A:{正样本 50%, 负样本 50%}
- 集合 B:{正样本 90%, 负样本 10%}
计算熵:
-
集合 A:
H_A = - (0.5 * log₂(0.5) + 0.5 * log₂(0.5)) = - (0.5 * -1 + 0.5 * -1) = 1.0 -
集合 B:
H_B = - (0.9 * log₂(0.9) + 0.1 * log₂(0.1)) ≈ - (0.9 * -0.152 + 0.1 * -3.32) ≈ 0.47
结论
集合 A 的熵更大(H=1),因为它更加"混乱"或"均匀",不确定性最大。
集合 B 的熵较小(H≈0.47),因为它更"纯",信息更确定。熵越大 → 不确定性越高
熵越小 → 趋向纯净(有助于分类)
三、决策树是怎么分裂特征的?
决策树在训练过程中需要不断选择最优特征进行"划分",也就是寻找哪个特征在哪个取值处划分最优,使得结果更"纯"。
选择一个特征,并找到该特征的某个划分方式,使得划分后的子集"纯度"尽可能高(即熵或不纯度尽可能低)。
3.1. 信息增益(ID3)
- 衡量的是熵的减少量。
- 信息增益公式:
G a i n ( D , A ) = E n t r o p y ( D ) − ∑ ( ∣ D i ∣ / ∣ D ∣ ) ∗ E n t r o p y ( D i ) Gain(D, A) = Entropy(D) - ∑( |Dᵢ| / |D| ) * Entropy(Dᵢ) Gain(D,A)=Entropy(D)−∑(∣Di∣/∣D∣)∗Entropy(Di)
其中: - D D D:当前样本集合
- A A A:某特征
- D i Dᵢ Di:按 A 的某取值划分得到的子集
选择信息增益最大的特征进行划分。
3.2. 信息增益率(C4.5)
- 为了解决信息增益偏向取值多的特征的问题,引入了归一化因子(分裂信息)。
G a i n R a t i o ( D , A ) = G a i n ( D , A ) / S p l i t I n f o ( A ) GainRatio(D, A) = Gain(D, A) / SplitInfo(A) GainRatio(D,A)=Gain(D,A)/SplitInfo(A)
其中:
- S p l i t I n f o ( A ) = − ∑ ( ∣ D i ∣ / ∣ D ∣ ) ∗ l o g 2 ( ∣ D i ∣ / ∣ D ∣ ) SplitInfo(A) = -∑( |Dᵢ| / |D| ) * log₂( |Dᵢ| / |D| ) SplitInfo(A)=−∑(∣Di∣/∣D∣)∗log2(∣Di∣/∣D∣)
选择信息增益率最大的特征进行划分。
3.3. 基尼指数(Gini)------用于 CART
- 衡量数据的不纯度(Gini 越小越纯)。
G i n i ( D ) = 1 − ∑ ( p k ) 2 Gini(D) = 1 - ∑(p_k)^2 Gini(D)=1−∑(pk)2 - 特征 A 在某个切分点 s 的基尼指数:
G i n i i n d e x ( D , A ) = ( ∣ D l e f t ∣ / ∣ D ∣ ) ∗ G i n i ( D l e f t ) + ( ∣ D r i g h t ∣ / ∣ D ∣ ) ∗ G i n i ( D r i g h t ) Gini_index(D, A) = (|D_left| / |D|) * Gini(D_left) + (|D_right| / |D|) * Gini(D_right) Giniindex(D,A)=(∣Dleft∣/∣D∣)∗Gini(Dleft)+(∣Dright∣/∣D∣)∗Gini(Dright)
选择使 Gini 最小的特征和切分点。
3.4. 离散特征 vs 连续特征
- 离散特征:直接按每个取值进行划分。
- 连续特征:先排序,尝试所有相邻值的中点作为候选切分点,再选最优。
3.4.1. 特征分裂过程总结
- 遍历每一个特征。
- 对每个特征尝试所有可能的划分方式(取值、切分点)。
- 根据分裂准则计算"划分优度"(如信息增益、信息增益率、Gini)。
- 选择最优特征和划分点进行分裂。
- 对子节点递归执行上述步骤,直到满足停止条件。
四、73. 矩阵置零(力扣hot100_矩阵)
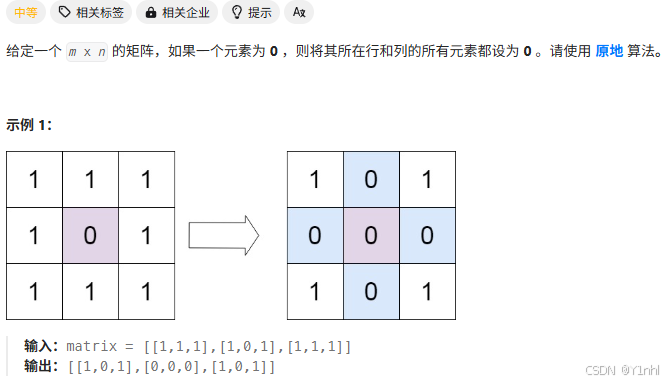
- py代码:
python
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
row_set = set()
col_set = set()
# 标记所有需要置零的行和列
for i in range(len(matrix)):
for j in range(len(matrix[0])):
if matrix[i][j] == 0:
row_set.add(i)
col_set.add(j)
# 将标记的行和列置零
for row in row_set:
for j in range(len(matrix[0])):
matrix[row][j] = 0
for col in col_set:
for i in range(len(matrix)):
matrix[i][col] = 0