目录
[1 HDFS数据迁移与备份概述](#1 HDFS数据迁移与备份概述)
[2 集群间数据迁移:DistCp工具详解](#2 集群间数据迁移:DistCp工具详解)
[2.1 DistCp工作原理架构](#2.1 DistCp工作原理架构)
[2.2 DistCp标准工作流程](#2.2 DistCp标准工作流程)
[2.3 DistCp性能优化方案](#2.3 DistCp性能优化方案)
[3 离线备份实施策略](#3 离线备份实施策略)
[3.1 HDFS到本地备份架构](#3.1 HDFS到本地备份架构)
[4 灾难恢复方案设计](#4 灾难恢复方案设计)
[4.1 基于快照的恢复流程](#4.1 基于快照的恢复流程)
[4.2 数据一致性校验方案](#4.2 数据一致性校验方案)
1 HDFS数据迁移与备份概述
HDFS作为大数据生态的核心存储系统,其数据迁移与备份能力直接关系到企业数据资产的安全性和可用性。本文将深入解析HDFS数据管理的三大关键场景:集群间数据迁移、离线备份实施以及灾难恢复方案,了解构建完整的数据保护体系。
2 集群间数据迁移:DistCp工具详解
2.1 DistCp工作原理架构
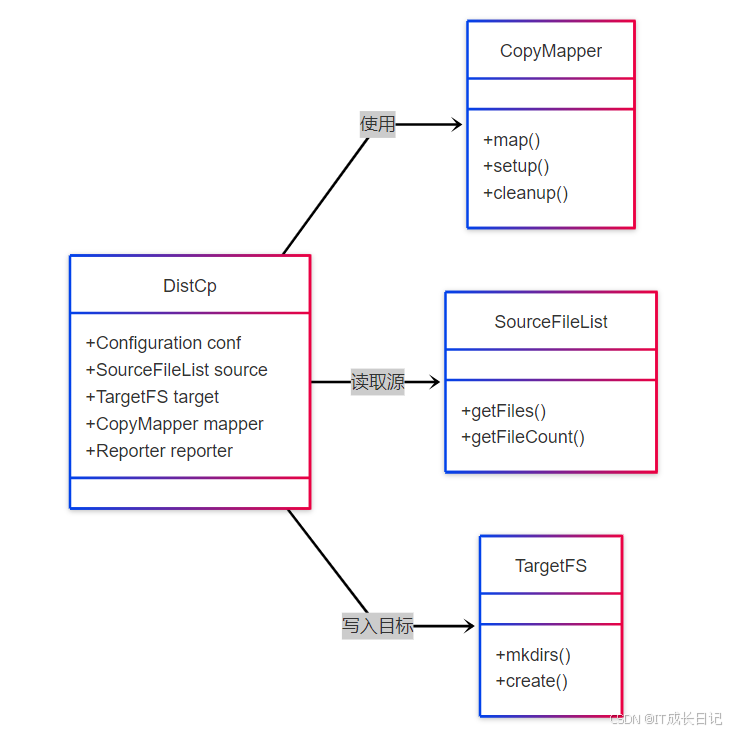
组件说明:
- SourceFileList:生成待复制文件列表(支持正则匹配)
- CopyMapper:实际执行复制的Map任务(可配置并行度)
- TargetFS:支持多种目标文件系统(HDFS、S3等)
- Reporter:进度报告与错误统计
2.2 DistCp标准工作流程
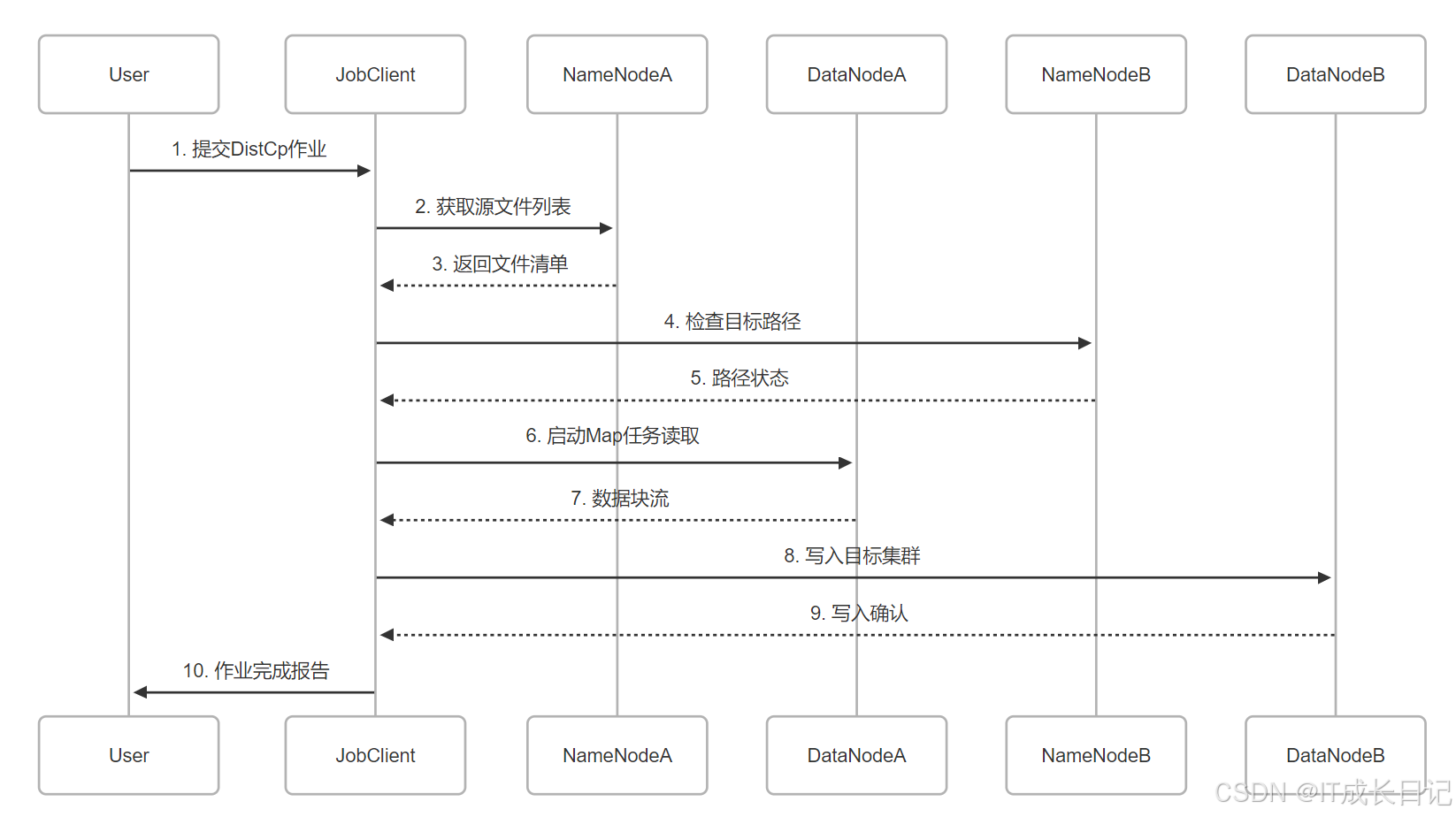
关键步骤:
- 文件列表生成阶段(避免小文件问题)
- 目标路径预检查(权限/空间验证)
- Map任务分布式执行(自动重试机制)
- 原子提交控制(避免部分写入)
- 完整性校验(可选字节比对)
2.3 DistCp性能优化方案
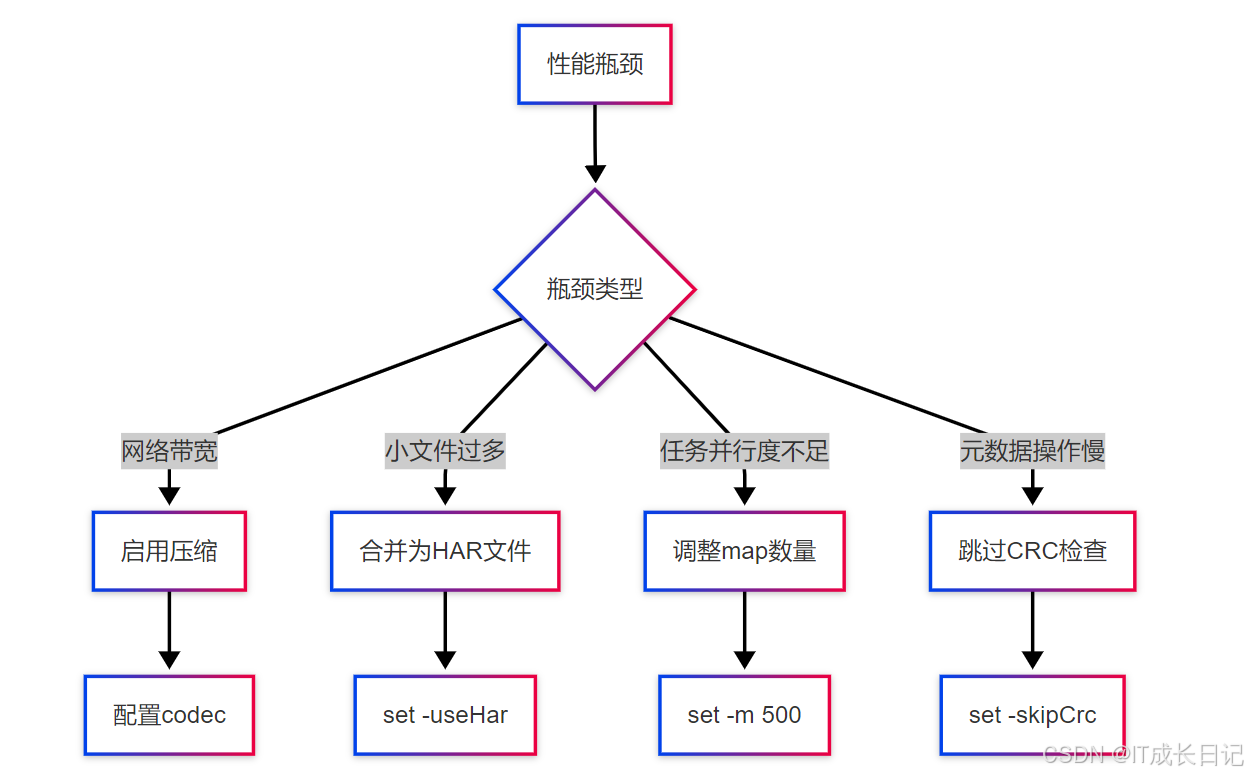
-
优化参数示例
hadoop distcp
-Dmapreduce.map.memory.mb=2048
-Dmapreduce.map.java.opts=-Xmx1800m
-bandwidth 50
-m 200
-strategy dynamic
/source/path /target/path
3 离线备份实施策略
3.1 HDFS到本地备份架构
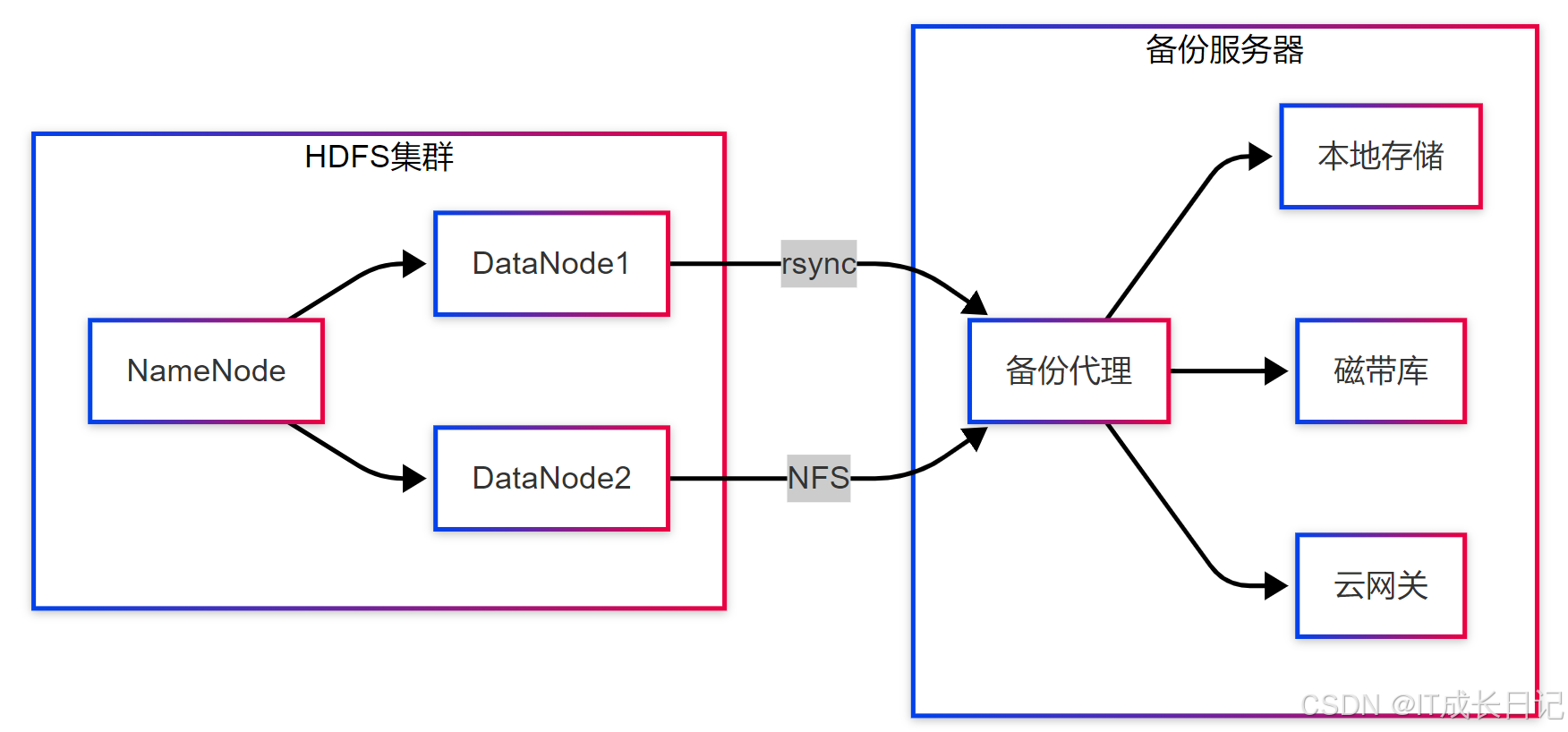
- 备份方案对比
|----------------|-------|-------|-------|
| 方案 | 优点 | 缺点 | 适用场景 |
| hadoop archive | 保留权限 | 需额外解压 | 长期归档 |
| hdfs dfs -get | 简单直接 | 单点瓶颈 | 小规模数据 |
| WebHDFS+REST | 可编程控制 | 性能较低 | 增量备份 |
4 灾难恢复方案设计
4.1 基于快照的恢复流程
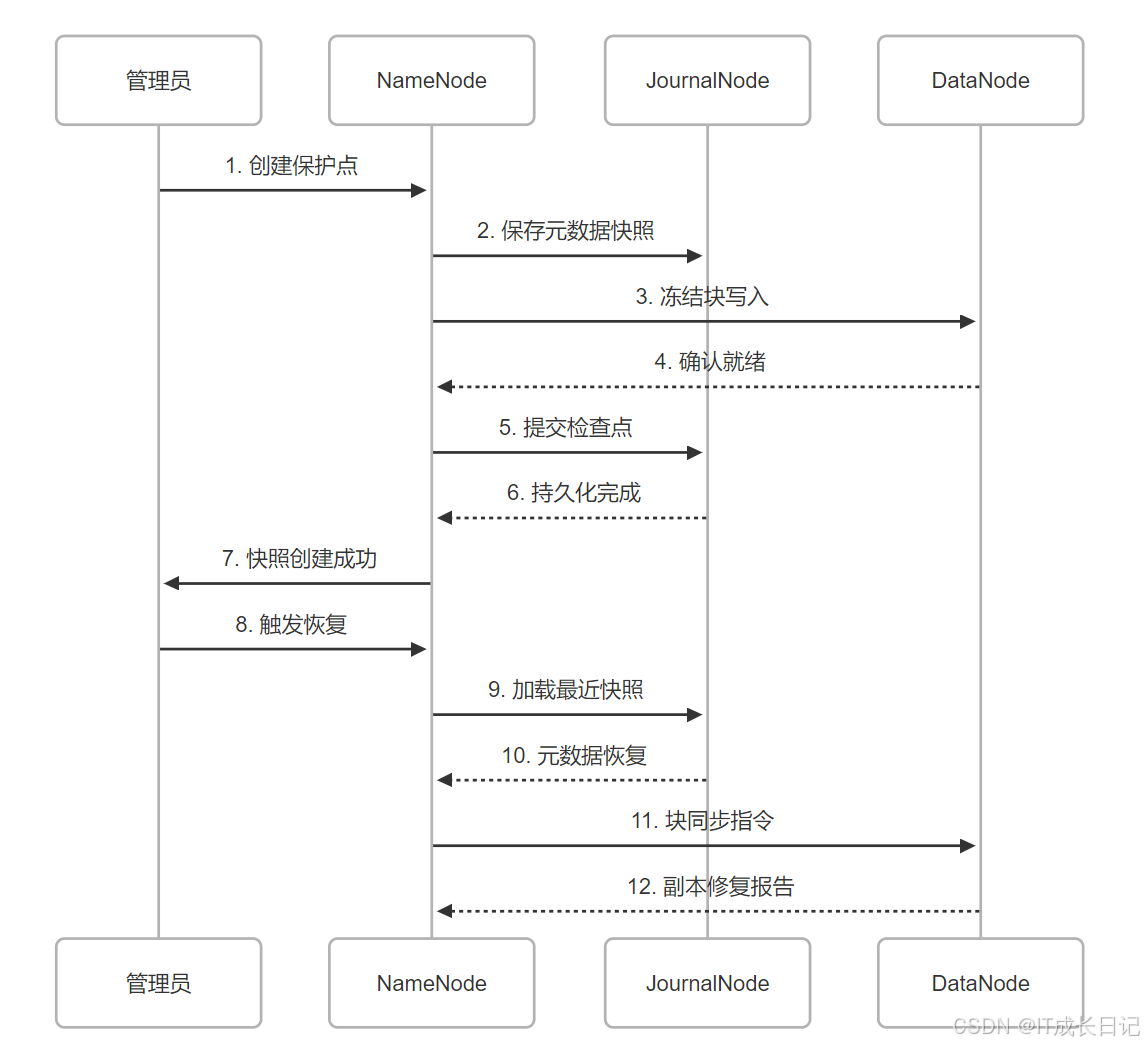
关键控制点:
- 快照创建频率(建议每日业务低峰期)
- 保留策略(按7天轮转)
- 恢复演练(每季度验证)
4.2 数据一致性校验方案
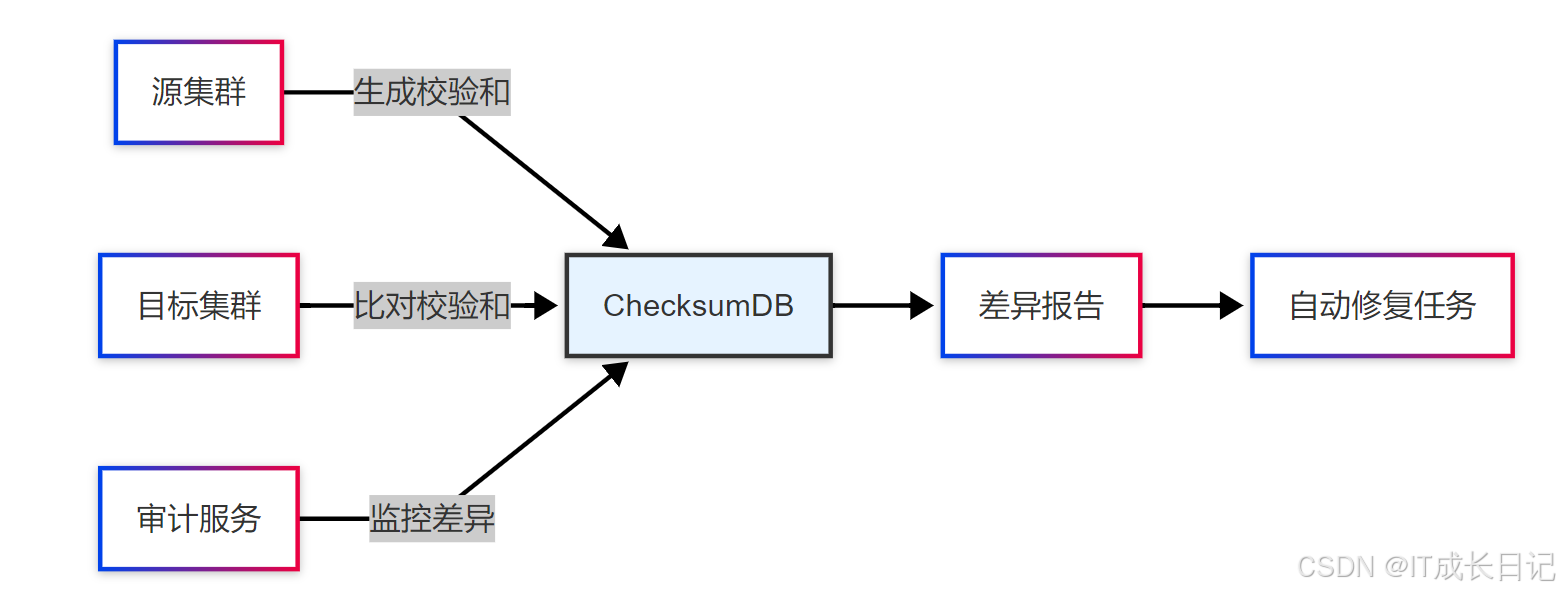
- 校验工具选择
- hdfs fsck:基础块完整性检查
- hadoop distcp -update -diff:精确到字节的差异比对
- 自定义MapReduce作业:大规模数据校验