一、数据处理
(一)数据集
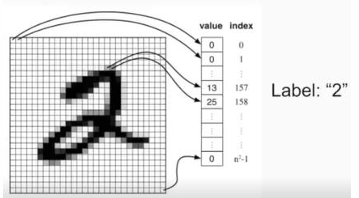
数据集是深度神经网络训练的基础,包含大量的样本,每一对样本由输入数据和标签(Label)组成。在计算机视觉任务中,输入的图像在计算机眼中表现为一个大型矩阵,矩阵中的每个元素取值范围通常为 0 , 255 0, 255 0,255,代表像素的灰度值或RGB通道值。例如,对于一张彩色图像,每个像素点包含R、G、B三个通道,每个通道的值均在 0 , 255 0, 255 0,255之间。
(二)归一化
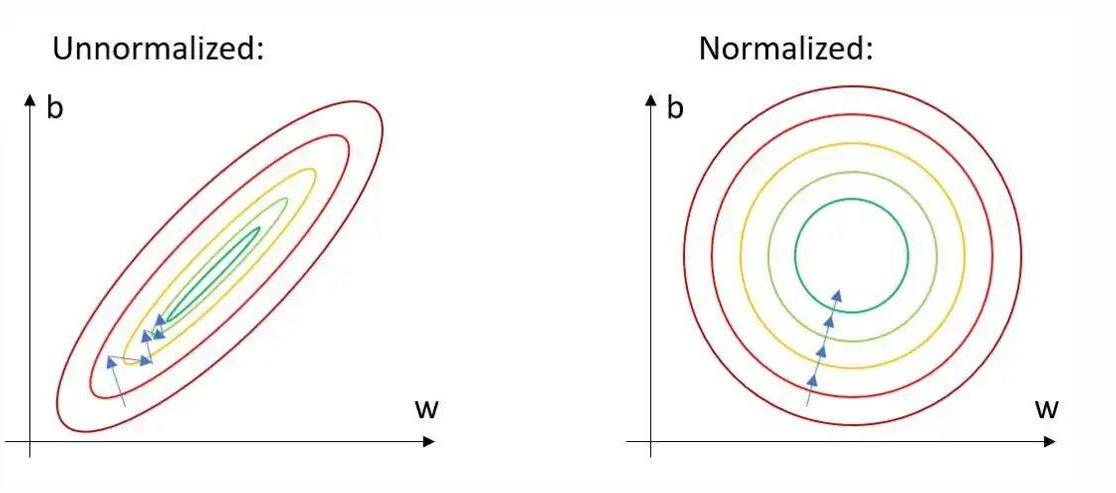
归一化是数据预处理中至关重要的步骤,通过调整输入数据的尺度,使数据具有相似的分布范围,从而提高模型的求解速度和泛化能力。常见的归一化方法包括以下几种:
1. Min-Max归一化
Min-Max归一化将数据线性变换到指定的区间(通常是 0 , 1 0, 1 0,1),公式为:
x norm = x − x min x max − x min x_{\text{norm}} = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}} xnorm=xmax−xminx−xmin
其中, x min x_{\text{min}} xmin和 x max x_{\text{max}} xmax分别是数据的最小值和最大值。该方法的优点是简单直观,保持数据的相对关系;缺点是对异常值敏感,若数据中存在极端值,会影响归一化效果。
2. 标准归一化
(1)标准化
标准化(Z-score Normalization)将数据转换为均值为0、方差为1的分布,公式为:
x norm = x − μ σ x_{\text{norm}} = \frac{x - \mu}{\sigma} xnorm=σx−μ
其中, μ \mu μ是数据的均值, σ \sigma σ是数据的标准差,计算方式为:
μ = 1 N ∑ n = 1 N x ( n ) , σ 2 = 1 N ∑ n = 1 N ( x ( n ) − μ ) 2 \mu = \frac{1}{N} \sum_{n=1}^{N} x^{(n)}, \quad \sigma^2 = \frac{1}{N} \sum_{n=1}^{N} (x^{(n)} - \mu)^2 μ=N1n=1∑Nx(n),σ2=N1n=1∑N(x(n)−μ)2
标准化适用于数据分布未知或存在较大波动的场景,尤其在神经网络中,可加速梯度下降的收敛速度。
(2)基于均值与方差派生归一化方法
这类方法在标准化的基础上引入可学习的参数,增强模型的灵活性,公式为:
y = γ ( x − μ ( x ) σ ( x ) ) + β y = \gamma \left( \frac{x - \mu(x)}{\sigma(x)} \right) + \beta y=γ(σ(x)x−μ(x))+β
其中, γ \gamma γ和 β \beta β是可学习的缩放和偏移参数, μ ( x ) \mu(x) μ(x)和 σ ( x ) \sigma(x) σ(x)是数据的均值和标准差。典型方法包括Batch Normalization、Layer Normalization等。
3. 批量归一化(Batch Normalization, BN)
Batch Normalization在训练过程中对每个批次的数据进行归一化,计算每个通道的均值和方差:
μ c ( x ) = 1 N H W ∑ n = 1 N ∑ h = 1 H ∑ w = 1 W x n c h w \mu_c(x) = \frac{1}{N H W} \sum_{n=1}^{N} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{nchw} μc(x)=NHW1n=1∑Nh=1∑Hw=1∑Wxnchw
σ c ( x ) = 1 N H W ∑ n = 1 N ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ c ( x ) ) 2 + ϵ \sigma_c(x) = \sqrt{\frac{1}{N H W} \sum_{n=1}^{N} \sum_{h=1}^{H} \sum_{w=1}^{W} (x_{nchw} - \mu_c(x))^2 + \epsilon} σc(x)=NHW1n=1∑Nh=1∑Hw=1∑W(xnchw−μc(x))2+ϵ
其中, N N N是批量大小, H H H和 W W W是特征图的高和宽, ϵ \epsilon ϵ是极小值避免除零。BN的作用是减少内部协变量偏移(Internal Covariate Shift),允许使用更大的学习率,提升模型训练的稳定性。
4. 层归一化(Layer Normalization, LN)
Layer Normalization与Batch Normalization的区别在于,它对单个样本的所有通道进行归一化,适用于循环神经网络(RNN)等动态长度输入的场景。均值和方差的计算方式为:
μ n ( x ) = 1 C H W ∑ c = 1 C ∑ h = 1 H ∑ w = 1 W x n c h w \mu_n(x) = \frac{1}{C H W} \sum_{c=1}^{C} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{nchw} μn(x)=CHW1c=1∑Ch=1∑Hw=1∑Wxnchw
σ n ( x ) = 1 C H W ∑ c = 1 C ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ n ( x ) ) 2 + ϵ \sigma_n(x) = \sqrt{\frac{1}{C H W} \sum_{c=1}^{C} \sum_{h=1}^{H} \sum_{w=1}^{W} (x_{nchw} - \mu_n(x))^2 + \epsilon} σn(x)=CHW1c=1∑Ch=1∑Hw=1∑W(xnchw−μn(x))2+ϵ
其中, C C C是通道数。LN避免了对批量大小的依赖,在处理序列数据时表现更优。
5. 组归一化(Group Normalization, GN)
Group Normalization将通道分成若干组,对每组内的特征进行归一化,适用于小批量训练或高分辨率图像。假设将通道分为 G G G组,则每组包含 C / G C/G C/G个通道,均值和方差的计算基于每组内的特征:
μ n g ( x ) = 1 ( C / G ) H W ∑ c = 1 C / G ∑ h = 1 H ∑ w = 1 W x n c h w \mu_{ng}(x) = \frac{1}{(C/G) H W} \sum_{c=1}^{C/G} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{nchw} μng(x)=(C/G)HW1c=1∑C/Gh=1∑Hw=1∑Wxnchw
σ n g ( x ) = 1 ( C / G ) H W ∑ c = 1 C / G ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ n g ( x ) ) 2 + ϵ \sigma_{ng}(x) = \sqrt{\frac{1}{(C/G) H W} \sum_{c=1}^{C/G} \sum_{h=1}^{H} \sum_{w=1}^{W} (x_{nchw} - \mu_{ng}(x))^2 + \epsilon} σng(x)=(C/G)HW1c=1∑C/Gh=1∑Hw=1∑W(xnchw−μng(x))2+ϵ
GN在目标检测等任务中广泛应用,尤其当批量大小较小时,性能优于BN。
6. 实例归一化(Instance Normalization, IN)
Instance Normalization对单个样本的每个通道独立进行归一化,适用于图像生成任务(如风格迁移),可保留图像的风格信息。均值和方差的计算仅基于单个样本的单个通道:
μ n c ( x ) = 1 H W ∑ h = 1 H ∑ w = 1 W x n c h w \mu_{nc}(x) = \frac{1}{H W} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{nchw} μnc(x)=HW1h=1∑Hw=1∑Wxnchw
σ n c ( x ) = 1 H W ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ n c ( x ) ) 2 + ϵ \sigma_{nc}(x) = \sqrt{\frac{1}{H W} \sum_{h=1}^{H} \sum_{w=1}^{W} (x_{nchw} - \mu_{nc}(x))^2 + \epsilon} σnc(x)=HW1h=1∑Hw=1∑W(xnchw−μnc(x))2+ϵ
IN在生成对抗网络(GAN)中常用,可减少风格信息的丢失。
(三)数据扩充
1. 目的
数据扩充通过对现有数据进行变换或引入噪声,增加训练样本的数量和多样性,防止模型过拟合,提升泛化能力。
2. 方法
(1)翻转
包括水平翻转和垂直翻转,以一定概率(如0.5)随机翻转图像,模拟不同视角的观察效果。例如,PyTorch中的RandomHorizontalFlip和RandomVerticalFlip函数可实现该操作。

(2)剪裁
通过随机剪裁图像的一部分,生成新的样本。常见方法包括随机剪裁(Random Crop)和中心剪裁(Center Crop)。例如,将256×256的图像随机剪裁为224×224,增加训练数据的多样性。

(3)旋转
按顺时针或逆时针方向随机旋转一定角度(如-10°到10°),模拟不同角度的拍摄场景。PyTorch中的RandomRotation函数可指定旋转范围和插值方法。

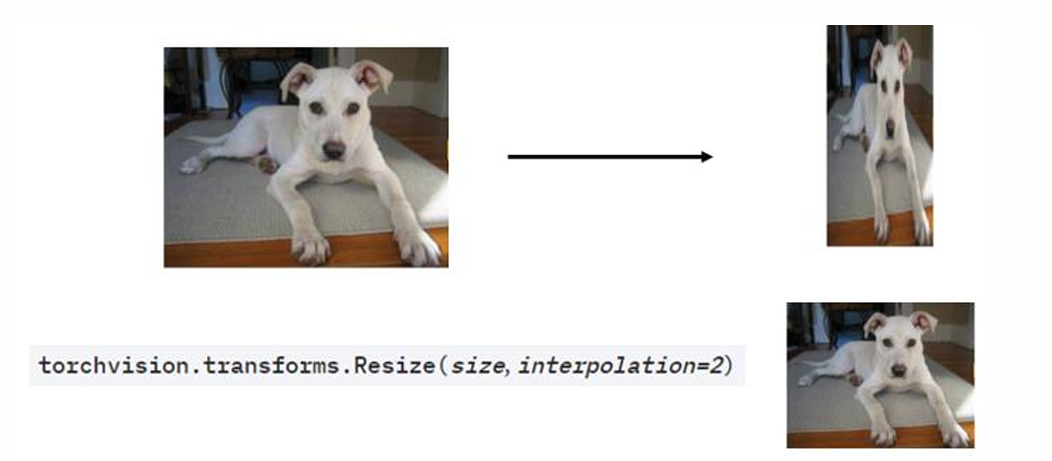
(4)缩放
将图像放大或缩小到指定尺寸,常用双线性插值或最近邻插值。缩放可模拟物体距离相机的远近变化,增强模型对尺度变化的鲁棒性。
3. 其他常用方法
- 加噪声:在图像中添加高斯噪声、椒盐噪声等,模拟真实场景中的噪声干扰。
- 颜色变换:调整图像的亮度、对比度、饱和度,或进行随机灰度化,增强模型对颜色变化的适应性。
- 弹性形变:对图像进行局部扭曲,模拟物体的形变,适用于医学图像等领域。
二、网络结构
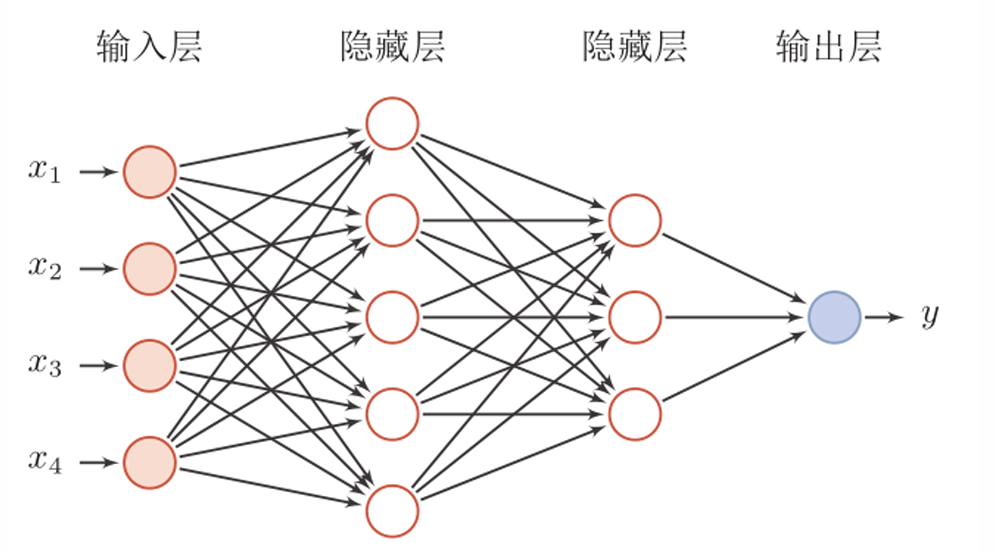
(一)全连接网络(Fully Connected Network)
全连接网络是最基础的神经网络结构,由输入层、隐藏层和输出层组成,每层神经元与下一层神经元全连接。输入层接收原始数据(如向量化的图像),隐藏层通过激活函数(如ReLU、Sigmoid)进行非线性变换,输出层根据任务类型(分类或回归)输出结果。全连接网络的优点是结构简单,易于实现;缺点是参数数量庞大,对高维输入(如图像)的处理效率低,且缺乏对空间结构的建模能力。
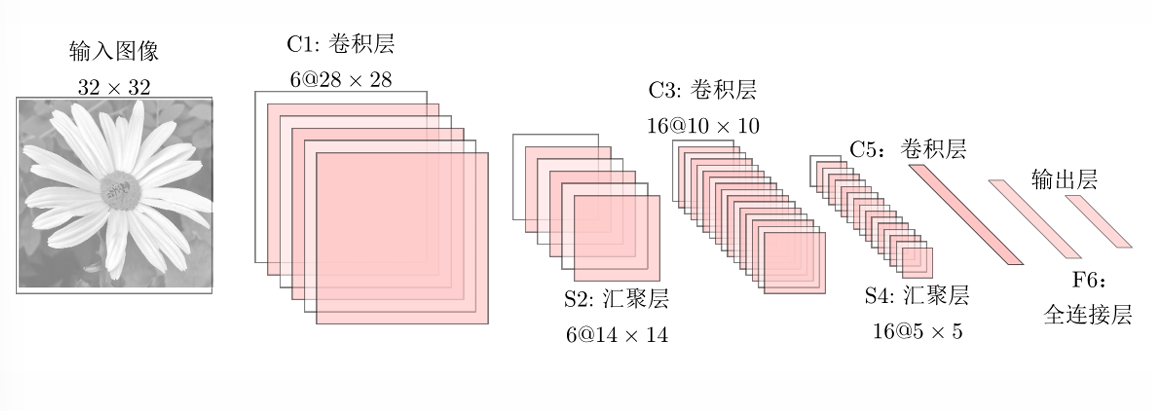
(二)卷积神经网络(Convolutional Neural Network, CNN)
CNN是处理图像数据的核心网络结构,通过卷积层、汇聚层(Pooling)和全连接层的组合,自动提取图像的层次化特征。
- 卷积层:使用卷积核(Filter)对输入特征图进行滑动窗口运算,提取局部空间特征(如边缘、纹理)。卷积核的权重共享机制大幅减少了参数数量,提升了模型效率。
- 汇聚层:对卷积层的输出进行下采样(如最大汇聚、平均汇聚),降低特征图的空间维度,增强特征的平移不变性。
- 典型结构 :如LeNet、AlexNet、VGGNet等,通过堆叠多层卷积和汇聚操作,逐步提取抽象特征,最终通过全连接层完成分类或回归任务。
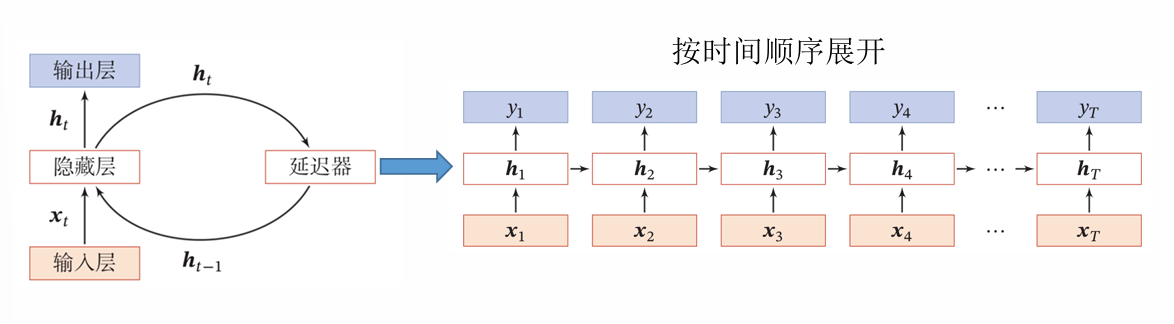
(三)循环神经网络(Recurrent Neural Network, RNN)
RNN适用于处理序列数据(如文本、语音),通过隐藏层的循环连接,捕捉数据中的时序依赖关系。隐藏层在每个时间步接收当前输入和上一时间步的隐藏状态,输出当前隐藏状态和预测结果。然而,传统RNN存在梯度消失问题,难以处理长距离依赖。改进版本如长短期记忆网络(LSTM)和门控循环单元(GRU),通过门控机制缓解了这一问题,广泛应用于自然语言处理(NLP)任务。
三、损失函数
损失函数用于衡量模型预测值与真实标签的差异,是模型优化的目标函数。以下是常见的损失函数:
(一)平方损失函数(Square Loss)
平方损失函数适用于回归任务,计算预测值与真实值的平方差之和,公式为:
L ( Y ∣ f ( X ) ) = ∑ N ( Y − f ( X ) ) 2 L(Y | f(X)) = \sum_{N} (Y - f(X))^2 L(Y∣f(X))=N∑(Y−f(X))2
优点是可导性好,易于梯度计算;缺点是对异常值敏感,且在分类任务中可能导致权重更新过慢。PyTorch中对应MSELoss类。
(二)绝对值损失函数(Absolute Loss)
绝对值损失函数计算预测值与真实值的绝对差之和,公式为:
L ( Y , f ( x ) ) = ∣ Y − f ( x ) ∣ L(Y, f(x)) = |Y - f(x)| L(Y,f(x))=∣Y−f(x)∣
相比平方损失,绝对值损失对异常值更鲁棒,但在零点处不可导,可能导致训练不稳定。适用于图像去噪等低层视觉任务,PyTorch中对应L1Loss类。
(三)交叉熵损失函数(Cross-Entropy Loss)
交叉熵损失函数用于分类任务,衡量预测概率分布与真实分布的差异,本质是对数似然函数。
1. 二分类
对于二分类问题,真实标签 y y y为0或1,预测概率 y ^ \hat{y} y^在 ( 0 , 1 ) (0, 1) (0,1)之间,损失函数为:
L = − y log y \^ + ( 1 − y ) log ( 1 − y \^ ) L = -y \\log \\hat{y} + (1 - y) \\log (1 - \\hat{y}) L=−ylogy\^+(1−y)log(1−y\^)
PyTorch中可使用BCEWithLogitsLoss,将Sigmoid激活函数与交叉熵损失结合,提高数值稳定性。
2. 多分类
多分类场景下,真实标签为one-hot向量,预测值通过Softmax函数转换为概率分布,损失函数为:
loss = − 1 n ∑ i y i ln a i \text{loss} = -\frac{1}{n} \sum_{i} y_i \ln a_i loss=−n1i∑yilnai
其中, y i y_i yi是真实标签的第 i i i类概率(0或1), a i a_i ai是模型预测的第 i i i类概率。PyTorch中对应CrossEntropyLoss类,自动处理Softmax操作。
(四)0-1损失函数(Zero-one Loss)
0-1损失函数直接判断预测值与真实值是否相等,相等为0,不等为1,公式为:
L ( Y , f ( X ) ) = { 1 , Y ≠ f ( X ) 0 , Y = f ( X ) L(Y, f(X)) = \begin{cases} 1, & Y \neq f(X) \\ 0, & Y = f(X) \end{cases} L(Y,f(X))={1,0,Y=f(X)Y=f(X)
该损失函数直观反映分类错误的个数,但由于非连续、非可导,实际中很少直接使用,通常通过代理损失函数(如交叉熵)进行优化。
(五)合页损失函数(Hinge Loss)
合页损失函数主要用于支持向量机(SVM)和分类任务,鼓励正确分类的样本与决策边界保持一定距离,公式为:
L ( y , f ( x ) ) = max ( 0 , 1 − y f ( x ) ) L(y, f(x)) = \max(0, 1 - y f(x)) L(y,f(x))=max(0,1−yf(x))
其中, y y y是真实标签(-1或1), f ( x ) f(x) f(x)是模型的预测值。若分类正确( y f ( x ) ≥ 1 y f(x) \geq 1 yf(x)≥1),损失为0;否则,损失为 1 − y f ( x ) 1 - y f(x) 1−yf(x)。合页损失对异常点鲁棒,且不鼓励分类器过度自信。
(六)指数损失函数(Exponential Loss)
指数损失函数是AdaBoost算法的核心,对错误分类的样本施加指数级惩罚,公式为:
L ( y , f ( x ) ) = exp ( − y ⋅ f ( x ) ) L(y, f(x)) = \exp(-y \cdot f(x)) L(y,f(x))=exp(−y⋅f(x))
其中, y ∈ { − 1 , 1 } y \in \{-1, 1\} y∈{−1,1}是真实标签, f ( x ) f(x) f(x)是模型的预测值。正确分类时( y ⋅ f ( x ) > 0 y \cdot f(x) > 0 y⋅f(x)>0),损失随预测置信度增加而指数下降;错误分类时,损失急剧上升,促使模型关注难分样本。
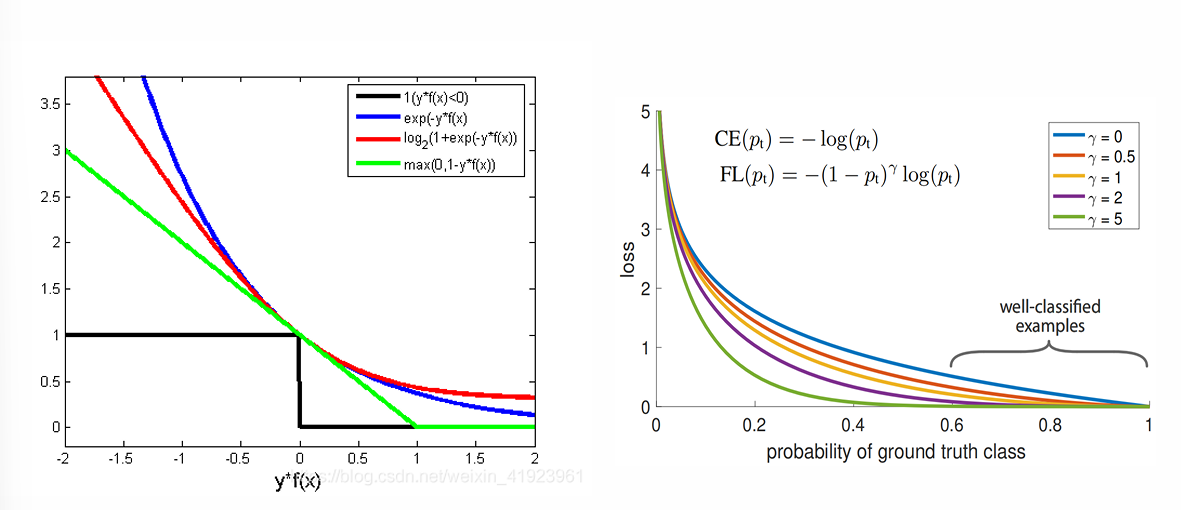
(七)聚焦损失函数(Focal Loss)
聚焦损失函数针对目标检测中的类别不平衡问题,在交叉熵基础上引入调制因子,降低易分类样本的权重,聚焦于难分类样本,公式为:
F L ( p t ) = − ( 1 − p t ) γ log ( p t ) FL(p_t) = -(1 - p_t)^\gamma \log(p_t) FL(pt)=−(1−pt)γlog(pt)
其中, p t p_t pt是样本的真实类别概率( p t = p p_t = p pt=p若标签为1,否则 p t = 1 − p p_t = 1 - p pt=1−p), γ \gamma γ是聚焦参数( γ ≥ 0 \gamma \geq 0 γ≥0)。当 p t p_t pt接近1时,调制因子趋近于0,减少对易分样本的关注,提升模型对少数类的检测能力。
四、参数初始化
参数初始化是神经网络训练的关键步骤,影响模型的收敛速度和最终性能。
(一)随机初始化
随机初始化通过给权重矩阵赋予随机值,打破神经元之间的对称性,确保每个神经元在初始阶段学习不同的特征。常用方法包括:
- 高斯初始化:权重服从均值为0、方差为0.01的高斯分布。
- 均匀分布初始化 :权重在特定区间(如 − 1 , 1 -1, 1 −1,1)内均匀随机取值。
偏置(bias)通常初始化为一个很小的常数(如0),避免激活函数饱和。
(二)预训练初始化
预训练初始化利用在大规模数据集上预训练好的模型权重,初始化当前模型的参数。优点包括:
- 加快模型收敛速度,减少训练时间;
- 降低梯度消失风险,尤其在深层网络中;
- 提高模型泛化能力,避免随机初始化导致的局部最优。
(三)Kaiming初始化(He初始化)
Kaiming初始化针对ReLU激活函数设计,通过保持输入方差与输出方差一致,避免梯度消失。对于ReLU激活函数,输出方差为输入方差的一半,因此权重的方差设为:
Var ( W ) = 2 n in \text{Var}(W) = \frac{2}{n_{\text{in}}} Var(W)=nin2
其中, n in n_{\text{in}} nin是输入神经元数量。PyTorch中可通过kaiming_uniform_或kaiming_normal_函数实现,需指定激活函数类型(如ReLU)。
(四)Xavier初始化(Glorot初始化)
Xavier初始化的核心思想是保持输入和输出的方差一致,适用于Sigmoid或Tanh激活函数。权重的方差计算为:
Var ( W ) = 2 n in + n out \text{Var}(W) = \frac{2}{n_{\text{in}} + n_{\text{out}}} Var(W)=nin+nout2
其中, n in n_{\text{in}} nin和 n out n_{\text{out}} nout分别是输入和输出神经元数量。Xavier初始化在浅层网络中表现良好,但在深层网络或ReLU激活函数下效果不如Kaiming初始化。
(五)问题思考
1. 为什么权重不能全都初始化为0
若所有权重初始化为0,在第一次前向传播时,所有隐藏层神经元的输入相同,导致激活值相同;反向传播时,所有权重的梯度也相同,使得神经元无法学习到不同的特征,即"对称权重问题"。因此,必须通过随机初始化打破对称性。
2. 偏置b通常用0来初始化
偏置的作用是调整激活函数的输入,使其更容易进入线性区域(如ReLU的非饱和区域)。初始化为0不会引入额外偏差,且偏置的梯度计算独立于权重,即使初始值为0,也能通过训练学习到合适的值。
五、模型优化
(一)学习准则
神经网络的训练可转化为优化问题,目标是最小化损失函数。损失函数通常包括数据拟合项和正则化项:
R ( W , b ) = 1 N ∑ n = 1 N L ( y ( n ) , y ^ ( n ) ) + 1 2 λ ∥ W ∥ F 2 \mathcal{R}(W, b) = \frac{1}{N} \sum_{n=1}^{N} \mathcal{L}(y^{(n)}, \hat{y}^{(n)}) + \frac{1}{2} \lambda \|W\|_F^2 R(W,b)=N1n=1∑NL(y(n),y^(n))+21λ∥W∥F2
其中,第一项是训练数据的损失,第二项是L2正则化项( λ \lambda λ是正则化系数),用于防止过拟合。
(二)梯度消失问题
梯度消失是深层神经网络训练中的常见问题,由于激活函数导数的连乘(如Sigmoid导数小于1),梯度在反向传播过程中逐渐衰减,导致底层参数更新缓慢。解决方法包括:
- 使用ReLU等非饱和激活函数,其导数在正数区域为1,缓解梯度衰减;
- 采用Batch Normalization,稳定中间层的输入分布;
- 设计残差连接(Residual Connection),通过跳跃连接直接传递梯度。
(三)梯度下降法
梯度下降法是神经网络优化的核心算法,通过计算损失函数对参数的梯度,沿着梯度反方向更新参数。
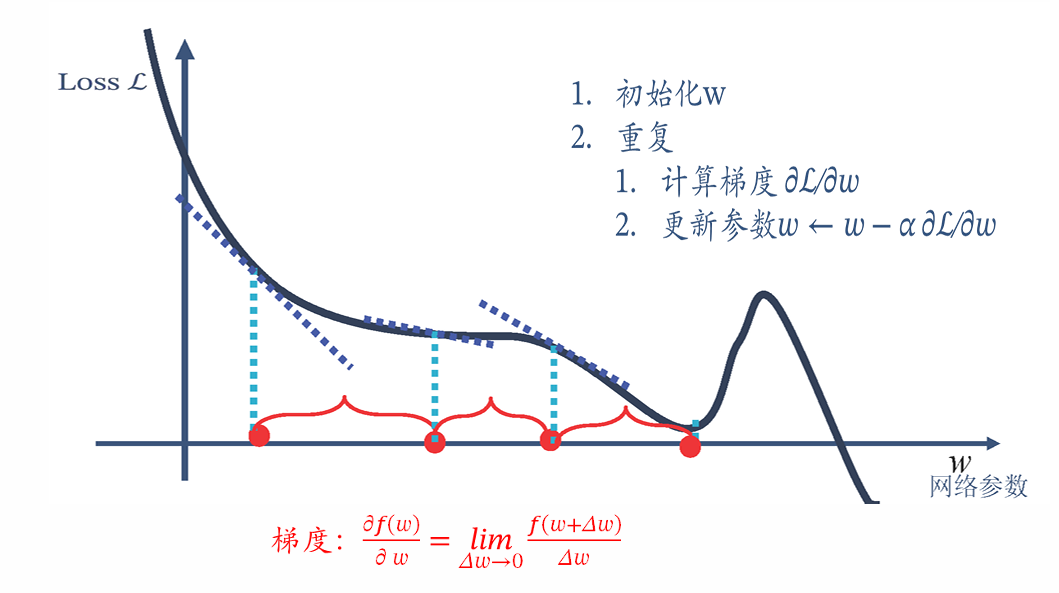
1. 优化算法
包括批量梯度下降(BGD)、随机梯度下降(SGD)、小批次梯度下降(Min-Batch GD)及其变体(如带动量的SGD、Adam等)。
2. 批量梯度下降(Batch Gradient Descent)
每次更新使用全部训练数据计算梯度:
θ = θ − η ⋅ ∇ θ J ( θ ) \theta = \theta - \eta \cdot \nabla_{\theta} J(\theta) θ=θ−η⋅∇θJ(θ)
优点是梯度方向准确,收敛到全局最优(凸函数)或局部最优(非凸函数);缺点是计算量巨大,不适用于大规模数据。
3. 随机梯度下降(Stochastic Gradient Descent)
每次更新仅使用一个样本计算梯度:
θ = θ − η ⋅ ∇ θ J ( θ ; x ( i ) , y ( i ) ) \theta = \theta - \eta \cdot \nabla_{\theta} J(\theta; x^{(i)}, y^{(i)}) θ=θ−η⋅∇θJ(θ;x(i),y(i))
优点是计算速度快,可在线学习;缺点是梯度噪声大,损失函数震荡明显,可能无法收敛到最优解。
4. 小批次梯度下降(Min-Batch Gradient Descent)
每次更新使用一个小批次(如32、64个样本)计算梯度,平衡了计算效率和梯度稳定性:
θ = θ − η ⋅ ∇ θ J ( θ ; x ( i : i + n ) , y ( i : i + n ) ) \theta = \theta - \eta \cdot \nabla_{\theta} J(\theta; x^{(i:i+n)}, y^{(i:i+n)}) θ=θ−η⋅∇θJ(θ;x(i:i+n),y(i:i+n))
小批次大小的选择影响训练速度和模型性能,通常设为2的幂次(如32、128)。
5. 带动量的随机梯度下降(Momentum+SGD)
引入动量项累积历史梯度,加速收敛并减少震荡:
v t = γ v t − 1 + η ∇ θ J ( θ ) v_t = \gamma v_{t-1} + \eta \nabla_{\theta} J(\theta) vt=γvt−1+η∇θJ(θ)
θ = θ − v t \theta = \theta - v_t θ=θ−vt
其中, γ \gamma γ是动量因子(通常取0.9),使梯度方向不变的维度加速,方向变化的维度减速。
6. 其他自适应学习率方法
- AdaGrad:根据参数的历史梯度平方和调整学习率,适用于稀疏数据,但可能导致学习率过早衰减。
- RMSprop:通过指数加权平均历史梯度平方,缓解AdaGrad的缺陷。
- Adam:结合动量和RMSprop,同时跟踪梯度的一阶矩和二阶矩,是目前最常用的优化器之一,具有良好的泛化性和鲁棒性。
(四)两种常见优化器
1. SGD+Momentum优化器
PyTorch中通过torch.optim.SGD实现,参数包括学习率、动量因子、权重衰减(L2正则化)等:
python
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)适用于简单模型或需要手动调整学习率的场景。
2. Adam优化器
Adam优化器自动调整学习率,参数包括学习率、一阶/二阶矩衰减率(betas)、防止除零的小常数(eps)等:
python
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999))在大多数情况下表现优异,尤其在深层网络和复杂任务中。
六、超参技巧
(一)超参数
超参数是模型训练前手动设定的参数,影响模型结构和优化过程,包括:
- 网络结构参数:层数、每层神经元个数、激活函数;
- 优化参数:学习率、批次大小、迭代次数;
- 正则化参数:正则化系数、Dropout率。
(二)网格搜索(Grid Search)
网格搜索通过枚举超参数的所有可能组合,在验证集上评估性能,选择最优组合。例如,学习率设置为 { 0.1 , 0.01 , 0.001 } \{0.1, 0.01, 0.001\} {0.1,0.01,0.001},批次大小设置为 { 32 , 64 } \{32, 64\} {32,64},共6种组合。优点是简单直观,缺点是计算成本高,适用于超参数较少的场景。
(三)随机搜索(Random Search)
随机搜索随机选择超参数组合,相比网格搜索,更高效地探索重要超参数的取值范围,尤其当某些超参数对性能影响较大时(如学习率)。例如,对学习率进行对数均匀采样( 1 0 − 4 10^{-4} 10−4到 1 0 − 1 10^{-1} 10−1),提高搜索效率。
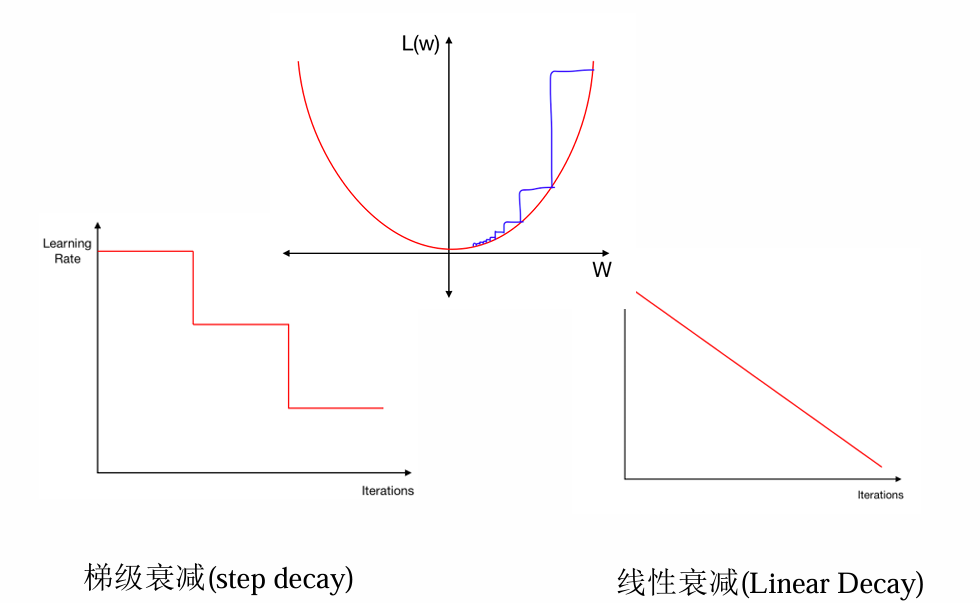
(四)学习率
学习率是最重要的超参数之一,过大导致训练不稳定,过小导致收敛缓慢。常用调整策略包括:
- 阶梯衰减(Step Decay):每隔一定迭代次数降低学习率(如乘以0.1)。
- 余弦衰减(Cosine Decay) :学习率随迭代次数呈余弦曲线下降,公式为:
KaTeX parse error: Extra } at position 130: ...T_{\text{cur}}}}̲{T_{\text{max}}...
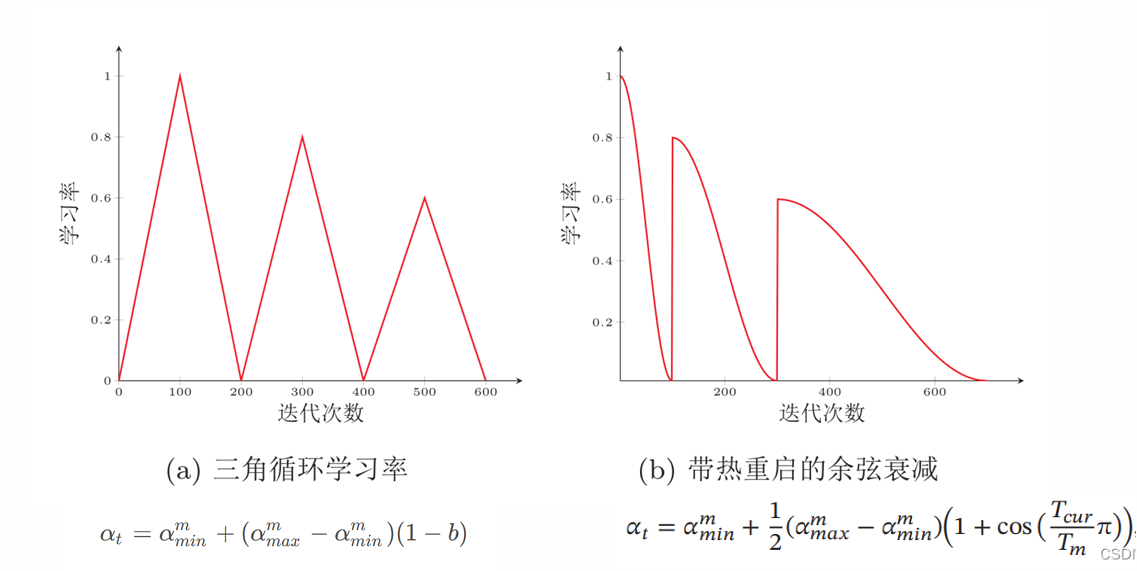
- 循环学习率(Cyclical Learning Rate):在一定范围内周期性调整学习率,帮助模型跳出局部最优。
(五)正则项系数
正则项系数(如L2正则化的 λ \lambda λ)用于控制模型复杂度,避免过拟合。调整策略:
- 初始设为0,确定合适的学习率后,再引入正则化;
- 固定学习率,通过验证集精度确定 λ \lambda λ的数量级(如0.01、0.1、0.001);
- 在最优数量级内细调(如0.005、0.015)。
七、模型泛化
(一)定义
模型泛化能力指模型对未知数据的预测能力,即从训练数据中学习到的模式能够推广到新样本。
(二)方法
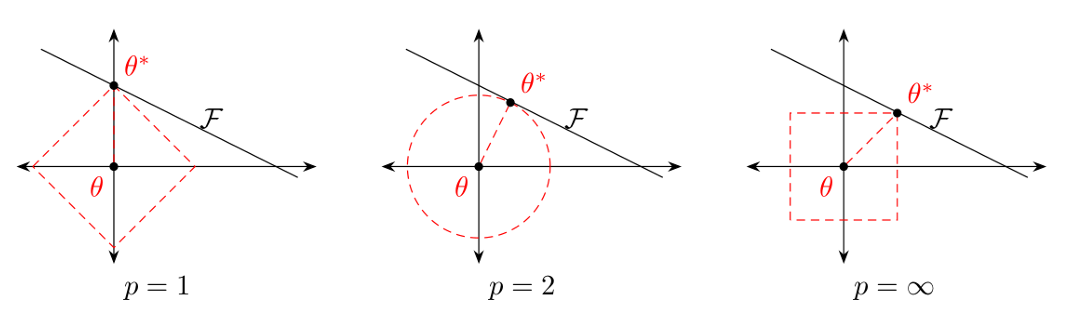
1. 权重正则化
通过在损失函数中添加正则项,约束权重的大小,避免模型过度拟合训练数据。常用方法包括:
- L2正则化:惩罚权重的平方和,使权重趋向于0,增强模型的简单性。
- L1正则化 :惩罚权重的绝对值和,导致权重稀疏化,可用于特征选择。
2. 随机失活(Dropout)
在训练过程中,以一定概率随机将神经元的激活值置0,模拟多个子网络的集成,减少神经元之间的依赖,提升泛化能力。测试阶段不应用Dropout,而是将输出乘以保留率(p)以保持期望一致。变体包括空间随机失活(Spatial Dropout)和随机失块(DropBlock),针对特征图的通道或区域进行失活。
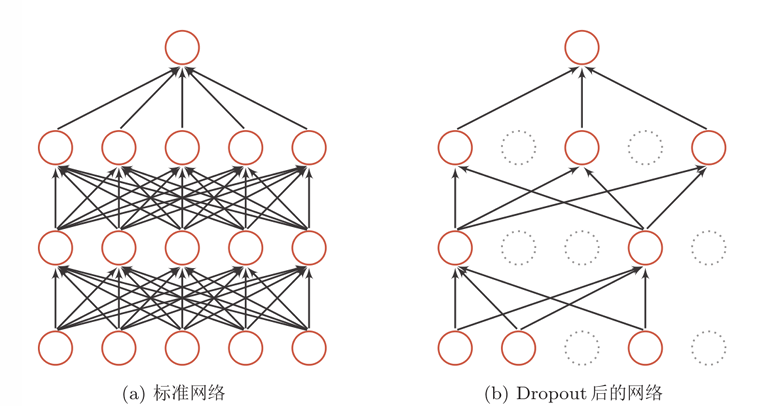
3. 数据扩增
如前所述,通过对训练数据进行变换(翻转、剪裁、旋转等),增加数据多样性,迫使模型学习更鲁棒的特征。
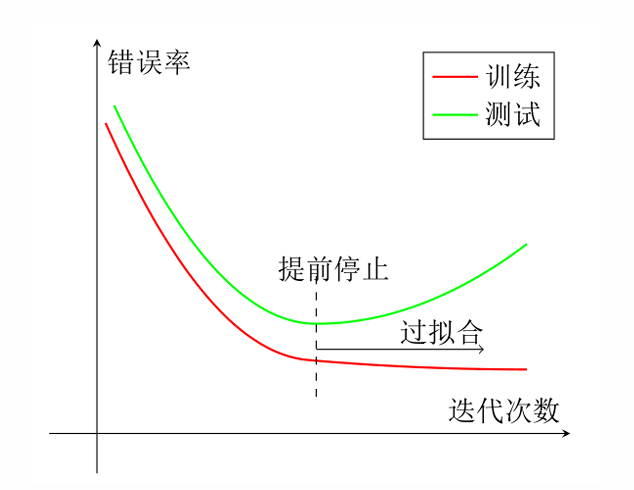
4. 提前停止(Early Stop)
在训练过程中,监测验证集上的性能,若验证损失不再下降或验证精度不再提升,则停止训练,避免过拟合。提前停止是一种简单有效的正则化方法,无需修改模型结构。