为什么划掉你的名字,为什么不敢与你对视
------ 25.4.21
一、R-BERT:基于BERT的关系抽取模型
R-BERT(Relation BERT)是一种用于关系抽取(Relation Extraction)任务的模型,它结合了预训练语言模型 BERT(Bidirectional Encoder Representations from Transformers)的强大语言理解能力,在关系抽取领域取得了较好的效果。
输入一段文本,在两个特殊的实体前后加上两对不同的token,用token强调不同的实体
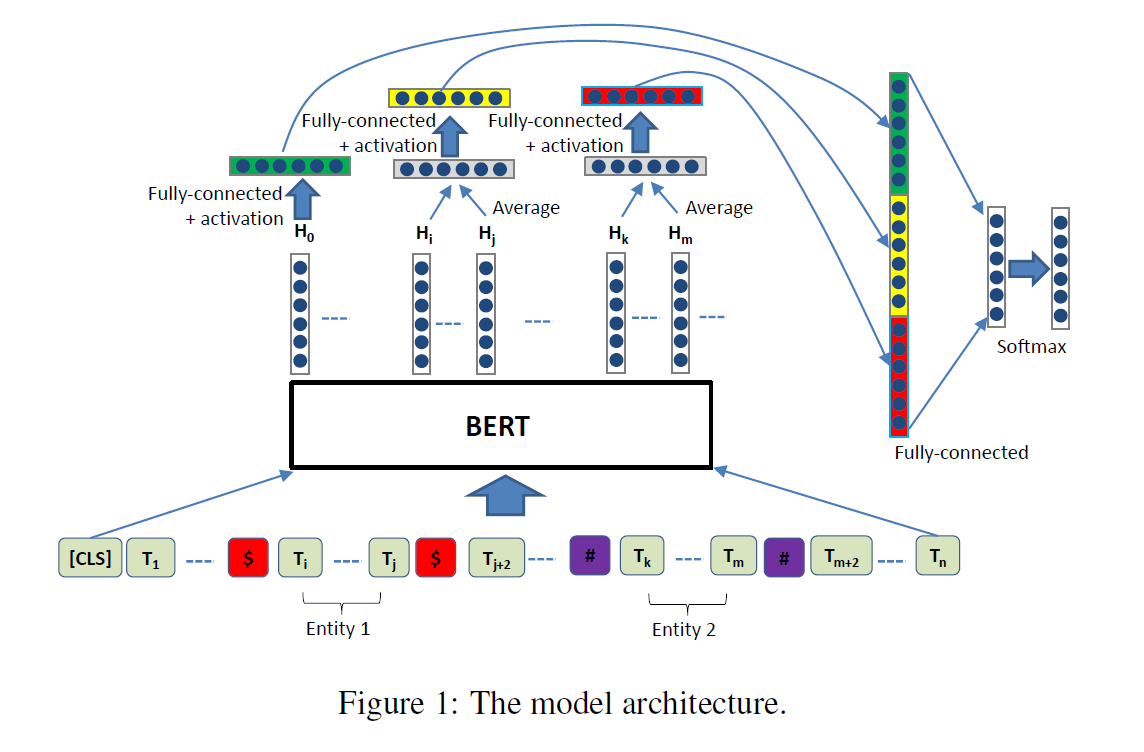 1.模型结构与设计
1.模型结构与设计
Ⅰ、核心思想:
在BERT基础上显式标记实体位置,结合句子全局信息和实体局部信息进行关系分类。
Ⅱ、输入设计:
① 实体标记:
在实体前后插入特殊符号(如 "实体1" 和 "#实体2#"),帮助BERT定位实体位置。
② 输出特征:
提取BERT输出的三部分向量------CLS句子向量、实体1的平均向量、实体2的平均向量。
Ⅲ、分类模块:
① 特征融合:
将三个向量分别通过Dropout、Tanh激活和全连接层,拼接后输入分类器。
② 共享权重:
实体1和实体2的特征处理层共享参数,减少模型复杂度。
2.计算方式与训练策略
Ⅰ、实体向量计算:
对实体对应的隐藏状态进行平均池化,生成实体表征。
Ⅱ、损失函数:
多类交叉熵损失,适用于关系分类任务(如SemEval-2010 Task 8数据集中的9类关系)。
Ⅲ、关键实验结论:
移除实体标记符会使F1值下降1.27%,仅使用CLS向量则下降1.26%,证明显式标记实体的重要性
3.应用场景
Ⅰ、人物关系分类:
例如识别"亲戚""上下级"等社会关系。
Ⅱ、医学文本分析:
提取疾病与症状之间的关联。
Ⅲ、事件抽取:
识别新闻中的实体间因果关系。
4.关键技术优势
Ⅰ、实体感知:
通过特殊符号和向量融合增强模型对实体的关注。
Ⅱ、高效微调:
基于预训练BERT快速适配关系分类任务,减少数据需求。
Ⅲ、高准确率:
在SemEval-2010 Task 8数据集上F1值达89.25%,接近当时SOTA水平。
二、模型对比与总结
| 维度 | KG-BERT | R-BERT |
|---|---|---|
| 核心任务 | 知识图谱补全(三元组分类、链接预测) | 关系抽取(实体间语义关系分类) |
| 输入设计 | 三元组序列化,融合实体描述文本 | 显式标记实体位置,提取实体向量 |
| 关键技术 | BERT+知识图谱融合、负样本生成 | 实体标记符、多特征融合 |
| 应用领域 | 问答系统、推荐系统、语义搜索 | 社交网络分析、医学文本挖掘、事件抽取 |
| 性能指标 | 在WN11、FB15K等数据集达到SOTA | SemEval-2010 Task 8的F1值89.25% |
三、代码示例
python
import torch
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和分词器,修改为bert-base-chinese
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
bert_model = BertModel.from_pretrained('bert-base-chinese')
# 示例输入
text = "苹果公司是一家科技公司,史蒂夫·乔布斯是其创始人。"
head_entity = "苹果公司"
tail_entity = "史蒂夫·乔布斯"
# 添加实体标记
text_with_entities = text.replace(head_entity, f"<e1>{head_entity}</e1>").replace(tail_entity, f"<e2>{tail_entity}</e2>")
# 分词
inputs = tokenizer(text_with_entities, return_tensors='pt')
# 通过BERT模型进行编码
outputs = bert_model(**inputs)
# 提取实体和上下文表示
e1_start = inputs['input_ids'][0].tolist().index(tokenizer.convert_tokens_to_ids('<e1>')) + 1
e1_end = inputs['input_ids'][0].tolist().index(tokenizer.convert_tokens_to_ids('</e1>'))
e2_start = inputs['input_ids'][0].tolist().index(tokenizer.convert_tokens_to_ids('<e2>')) + 1
e2_end = inputs['input_ids'][0].tolist().index(tokenizer.convert_tokens_to_ids('</e2>'))
e1_representation = torch.mean(outputs.last_hidden_state[0, e1_start:e1_end, :], dim=0)
e2_representation = torch.mean(outputs.last_hidden_state[0, e2_start:e2_end, :], dim=0)
context_representation = outputs.last_hidden_state[0, 0, :] # [CLS]标记的表示
# 拼接表示
combined_representation = torch.cat([e1_representation, e2_representation, context_representation], dim=0)
# 假设这里有一个全连接层进行关系分类
num_relations = 3 # 假设有3种关系
classification_layer = torch.nn.Linear(combined_representation.size(0), num_relations)
logits = classification_layer(combined_representation)
probs = torch.softmax(logits, dim=0)
# 预测的关系类别
predicted_relation = torch.argmax(probs).item()
print(f"预测的关系类别: {predicted_relation}")