完整内容请看文末最后的推广群
先展示问题一代码和结果、再给出四个问题详细的模型
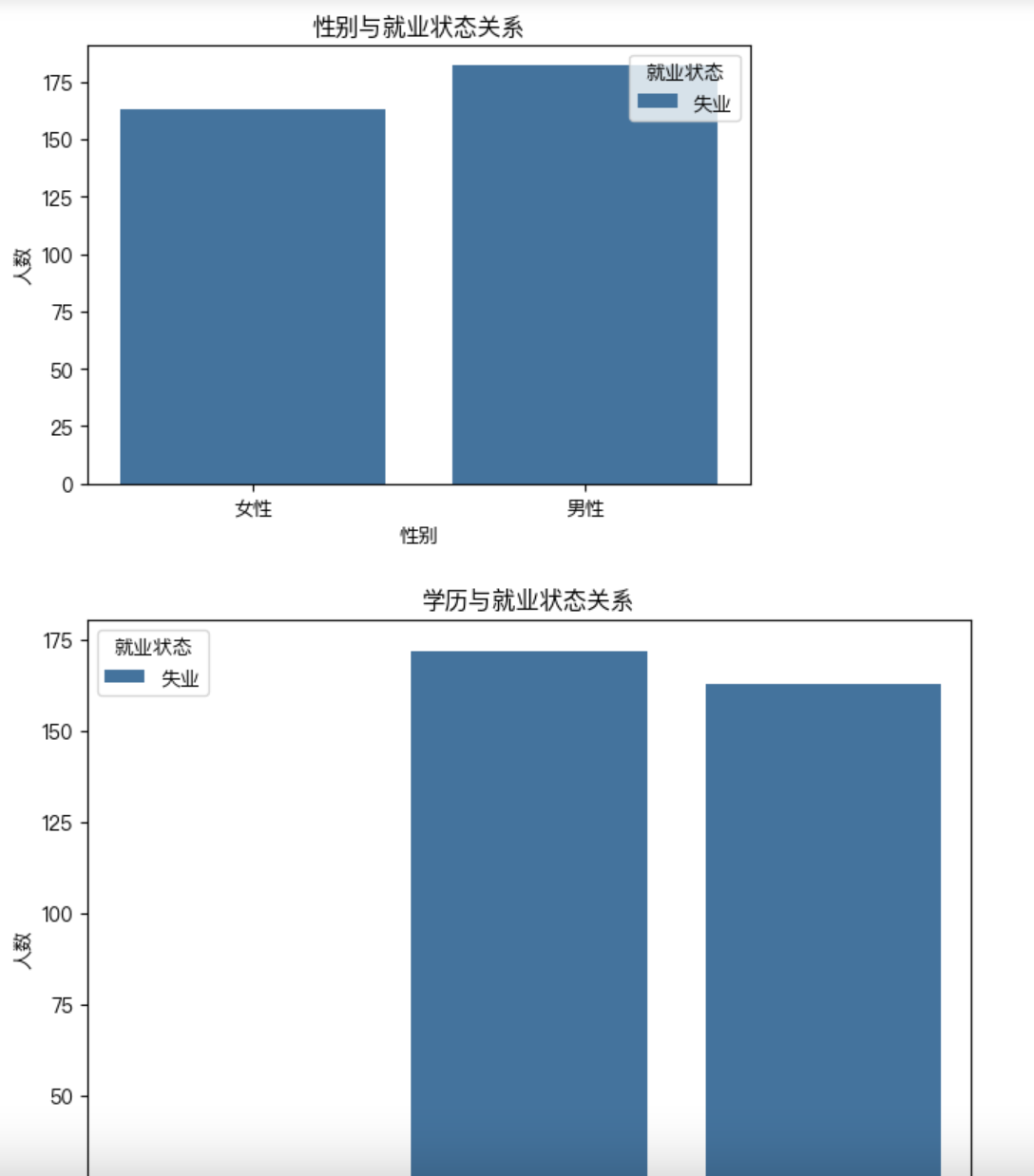
按性别分析就业与失业状态:
employment_status 失业
sex
0 182
1 163
按学历分析就业与失业状态:
employment_status 失业
edu_level
0 10
1 172
2 163
按年龄区间分析就业与失业状态:
employment_status 失业
age_group
18-25 6
26-35 252
36-45 69
46-55 13
56-65 5
按行业分析就业与失业状态:
employment_status 失业
profession
20000,20800 1
20000,29900 4
30000,30100 30
30000,39900 1
40000,40100 2
40000,40200 1
40000,40500 1
40000,40600 1
40000,41300 2
40000,41400 1
40000,49900 1
60000,69900 4
70000 1
80000 255
80000, 19
90000 1
90000,90001 20
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
# 处理缺失值(填充数值型缺失值,类别型通过众数填充)
data.fillna(data.mean(), inplace=True)
data['edu_level'].fillna(data['edu_level'].mode()[0], inplace=True)
# 对类别型数据进行编码
data['sex'] = data['sex'].map({1: '男', 2: '女'}) # 性别编码
data['edu_level'] = data['edu_level'].map({
10: '初中及以下',
20: '高中/中专',
30: '大专',
40: '本科',
50: '研究生及以上'
}) # 学历编码
data['employment_status'] = data['employment_status'].map({1: '就业', 0: '失业'}) # 就业状态编码
# 转换性别和学历为数值型
data['sex'] = data['sex'].map({'男': 1, '女': 0})
data['edu_level'] = data['edu_level'].map({
'初中及以下': 0,
'高中/中专': 1,
'大专': 2,
'本科': 3,
'研究生及以上': 4
})
# 2. 特征选择与目标变量
X = data[['age', 'sex', 'edu_level']] # 选择年龄、性别、学历作为特征
y = data['employment_status'] # 就业状态作为目标变量
# 3. 数据划分:训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. 标准化数据(对于逻辑回归,标准化有助于提升模型效果)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 5. 构建逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 6. 预测与评估模型
y_pred = model.predict(X_test)
# 输出准确率
print(f"准确率: {accuracy_score(y_test, y_pred)}")
# 输出分类报告(包含查准率、召回率、F1值等)
print("分类报告:")
print(classification_report(y_test, y_pred))
# 输出混淆矩阵
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
# 7. 特征重要性分析(使用模型的系数)
feature_importance = pd.DataFrame({
'Feature': X.columns,
'Importance': model.coef_[0]
})
# 按重要性排序并打印
feature_importance = feature_importance.sort_values(by='Importance', ascending=False)
print("\n特征重要性分析:")
print(feature_importance)下面是每一问的模型
这个问题是关于"就业状态分析与预测",目的是通过分析宜昌地区的部分就业数据,进行就业状态的分析和预测,进而为相关部门提供科学决策依据。
问题一:数据特征分析
任务要求:
就业现状分析:分析宜昌地区当前的就业状态,包括就业与失业的总体情况。
按特征划分:根据个人特征(如年龄、性别、学历、专业、行业等)对调查数据进行划分,分析这些特征如何影响就业状态(就业或失业)。
通过表格和图表的形式展示不同层面因素(如年龄、性别等)对就业状态的影响,给出就业和失业的数量统计。
问题二:就业状态预测
在问题二和问题三中,需要建立和优化一个就业状态预测模型。
任务要求:
特征选择:基于问题一的分析,选择与就业状态密切相关的特征。
模型构建:利用选择的特征构建就业状态预测模型。
评估模型:使用准确率、查准率、召回率、F1值等指标对模型进行评估。
特征重要性排序:对各特征的重要性进行排序,并绘制条形图展示。
预测结果:对给定的"预测集"进行就业状态预测,结果以表格形式呈现。
-
特征选择与数据预处理
对数据进行预处理,包括:
缺失值处理:对于缺失值,可以使用均值、中位数或者通过机器学习算法(如KNN)进行填充。
类别特征编码:对于类别型特征(如性别、教育水平、行业等),可以采用独热编码(One-Hot Encoding)或标签编码(Label Encoding)。
数据标准化:对数值型特征进行标准化(例如通过Z-score标准化),使得不同特征的尺度相同,避免在模型训练时某些特征主导模型训练过程。
-
构建预测模型
选择几种常见的分类模型来进行预测,包括逻辑回归、决策树、随机森林、支持向量机(SVM)等。选择两种常见的分类模型------逻辑回归和随机森林,并给出其公式和模型构建方式。
逻辑回归模型(Logistic Regression)
逻辑回归是一个二分类模型,用于预测"就业"与"失业"两种状态,模型假设每个特征与目标变量之间存在线性关系。
模型假设:假设就业状态 y∈{0,1},其中:
y=1 表示"就业"
y=0表示"失业"
假设我们有 m 个特征 X={x1,x2,...,xm} 和对应的权重 β1,β2,...,βm,逻辑回归的预测公式为:
p(y=1∣X)=11+e−(β0+β1x1+β2x2+⋯+βmxm)
其中,p(y=1∣X) 表示给定特征 X 的条件下,预测为"就业"的概率。
训练过程:使用最大似然估计(MLE)来优化模型的参数 β0,β1,...,βm,通过最小化损失函数来进行训练。损失函数通常使用对数损失函数(Log-Loss):
L(β)=−∑i=1nyilog(p(yi=1∣Xi))+(1−yi)log(1−p(yi=1∣Xi))
通过梯度下降算法来优化参数。
随机森林模型(Random Forest)
随机森林是一种集成学习方法,通过构建多个决策树来进行预测。每棵树是通过自助法(Bootstrap Sampling)从训练数据中随机抽取一部分样本进行训练的。
模型假设:随机森林由 N 棵决策树组成,每棵树 Tj 对应一个预测 y^j\。最终的预测通过所有树的投票结果(多数表决)来决定:
y=mode(y1,y2,...,yN)
其中,y^j 是第 j 棵树的预测,mode表示多数表决。
决策树构建:每棵树的构建是通过分裂节点来最小化基尼不纯度(Gini Impurity)或信息增益。基尼不纯度的计算公式为:
Gini(t)=1−∑i=1kpi2
其中,pi 是节点 t中类别 i的概率,k 是类别数量。
树的每个分裂节点选择使得基尼不纯度最小的特征和分裂点。
训练过程:通过多次构建决策树,每次使用不同的样本和特征进行训练,从而得到一组决策树。这些树通过投票方式对未知样本进行预测。
- 评估模型
使用以下指标评估模型的效果:
准确率(Accuracy):
Accuracy=TP+TNTP+TN+FP+FN
其中,TP、TN、FP、FN 分别表示真正例、真负例、假正例和假负例的数量。
查准率(Precision):
Precision=TPTP+FP
召回率(Recall):
Recall=TPTP+FN
F1 分数(F1 Score):
F1=2×Precision×RecallPrecision+Recall
问题三:就业状态预测模型优化
- 外部数据的引入
为了提高模型的准确性,除了个人特征外,还需要收集和引入宏观经济数据、政策信息、劳动力市场状况等因素。可以从以下几方面入手:
宏观经济数据:例如GDP增长率、通货膨胀率等,可能会影响就业率。
政策数据:例如就业相关的政府政策,可能会影响某些行业的招聘情况。
劳动力市场数据:例如行业招聘信息、薪资水平等,可能会影响特定群体的就业机会。
- 模型优化
特征工程:根据外部数据,提取新特征并结合到现有数据中,增加"宏观经济状况"作为新的特征。
算法优化:通过调节模型的超参数(例如随机森林的树数和深度、逻辑回归的正则化强度)来优化模型的表现。
问题三:就业状态预测模型优化
任务要求:
收集外部数据:除了个人层面的因素外,宏观经济、政策、劳动力市场状况、消费价格指数等也可能影响就业状态。需要收集相关数据,提取这些数据来进一步完善预测模型。
模型优化与评估:结合外部数据对预测模型进行优化,重新预测给定的"预测集",并再次使用准确率、查准率、召回率、F1值等指标评估优化后的模型。
问题四:人岗精准匹配
任务要求:
建立人岗匹配模型:利用赛题提供的数据,结合外部收集的数据(如招聘数据、社交媒体数据、薪资水平、行业动态等),建立人岗匹配模型。
失业人员推荐:根据建立的模型,为失业人员推荐合适的岗位。
模型构建思路:
数据预处理:首先对数据进行清洗和预处理,包括缺失值处理、异常值检测等。
特征工程:根据问题一分析出的特征,选择合适的特征进行建模,并可能需要进行特征编码(如类别特征编码)和标准化处理。
模型选择:
可以考虑使用逻辑回归、随机森林、支持向量机(SVM)等分类算法进行就业状态的预测。
对于问题三的优化,可以尝试集成方法(如XGBoost、LightGBM)或者使用深度学习模型。
评估指标:根据分类任务,使用准确率、查准率、召回率和F1值等指标来评估模型性能。
外部数据整合:收集相关的宏观经济、劳动力市场等外部数据,进一步完善模型。
数据分析与可视化:
利用直方图、箱线图、散点图等进行数据分布和趋势的可视化分析。
用条形图展示特征重要性排序,并通过热力图等手段分析特征间的相关性。