📌 一句话理解 MVCC(Multi-Version Concurrency Control):
MVCC 指的是多版本并发控制 ,MVCC 通过为每个事务提供数据的快照版本 ,让读取操作无需加锁,从而实现高并发的同时,又能维持一致性。
🔍 为什么需要 MVCC?
在没有 MVCC 的情况下,为保证事务隔离,读操作也需要加锁,容易产生如下问题:
- 加锁严重影响并发性能(尤其在高频读场景)
- 读写互相阻塞,导致悲观锁下事务吞吐量下降
而 MVCC 的目标是:
读操作不加锁,写操作也不阻塞读操作。
🛠️ MVCC 的实现原理(以 InnoDB 为例)
InnoDB 实现 MVCC 主要依赖于 Undo Log(回滚日志)+ 隐藏版本字段。
✅ 1. 每行记录背后其实还有两个隐藏字段(列):
text
• trx_id:创建/修改该行的事务ID
• roll_pointer:指向这行旧版本数据的 undo log(即回滚信息)这两个字段并不会在 SELECT * 里看到,但它们对 MVCC 至关重要。
正常的列:
text
• id: 用户 id
• name:用户名
• city:所在地✅ 2. Undo Log 回滚日志
当一个事务对某行进行 UPDATE 时:
- InnoDB 会生成一条 Undo Log,记录这行数据被修改前的内容;
- 并将这条 Undo Log 记录下来,通过
roll_pointer链接起来形成版本链(版本快照); - 这样,不同事务就可以根据自己的视角读取不同版本的数据。
假设有一张hero表,表中有一行记录 name 为张三,city 为帝都,插入这行记录的事务 id 是 80。此时,DB_TRX_ID的值就是 80,DB_ROLL_PTR的值就是指向这条 insert undo 日志的指针。
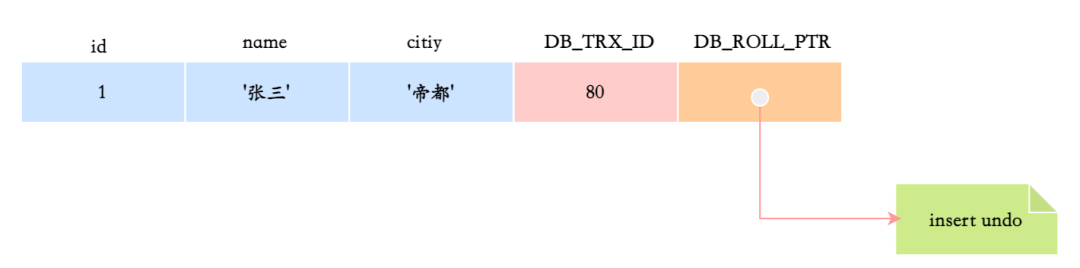
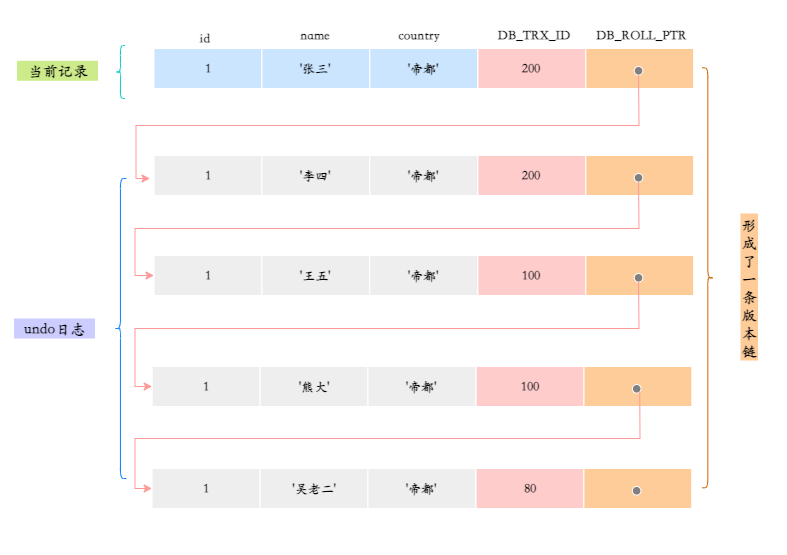
接下来,如果有两个DB_TRX_ID分别为100、200的事务对这条记录进行了update操作,那么这条记录的版本链就会变成下面这样:

当事务更新一行数据时,InnoDB 不会直接覆盖原有数据,而是创建一个新的数据版本,并更新 DB_TRX_ID 和 DB_ROLL_PTR,使得它们指向前一个版本和相关的 undo 日志。这样,老版本的数据不会丢失,可以通过版本链找到。
由于 undo 日志会记录每一次的 update,并且新插入的行数据会记录上一条 undo 日志的指针,所以可以通过这个指针找到上一条记录,这样就形成了一个版本链。
✅ 3. 读取时判断可见性(版本可见规则)
ReadView(读视图)是 InnoDB 为了实现一致性 读而创建的数据结构,它用于确定在特定事务中哪些版本的行记录是可见的。
ReadView 主要用来处理隔离级别为"可重复读"和"读已提交"的情况。因为在这两个隔离级别下,事务在读取数据时,需要保证读取到的数据是一致的,即读取到的数据是在事务开始时的一个快照。
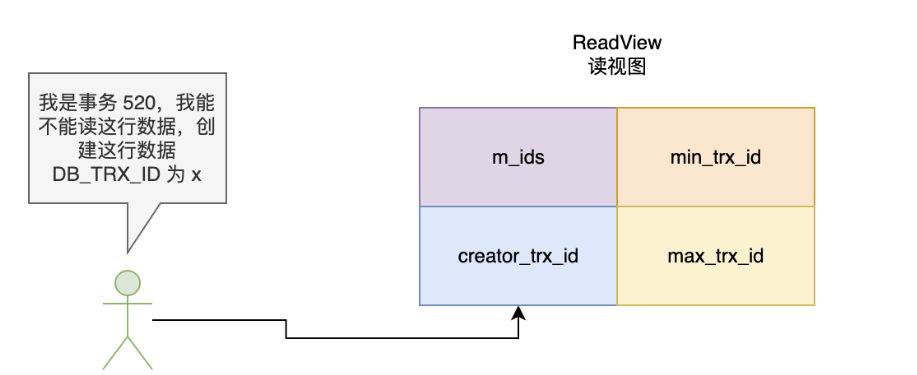
当事务开始执行时,InnoDB 会为该事务创建一个 ReadView,这个 ReadView 会记录 4 个重要的信息:
- creator_trx_id:创建该 ReadView 的事务 ID。
- m_ids:所有活跃事务的 ID 列表,活跃事务是指那些已经开始但尚未提交的事务。
- min_trx_id:所有活跃事务中最小的事务 ID。它是 m_ids 数组中最小的事务 ID。
- max_trx_id :事务 ID 的最大值加一。换句话说,它是下一个将要生成的事务 ID。
当一个事务读取某条数据时,InnoDB 会根据 ReadView 中的信息来判断该数据的某个版本是否可见:
1、如果某个数据版本的 DB_TRX_ID 小于 min_trx_id ,则该数据版本在生成 ReadView 之前就已经提交,因此对当前事务是可见的。
2、如果某个数据版本的 DB_TRX_ID 大于 max_trx_id ,则表示创建该数据版本的事务在生成 ReadView 之后开始,因此对当前事务是不可见的→ 找 Undo Log 回退版本 → 继续判断。
3、如果某个数据版本的 DB_TRX_ID 在 min_trx_id 和 max_trx_id 之间,需要判断 DB_TRX_ID 是否在 m_ids 列表中:
- 不在,表示创建该数据版本的事务在生成 ReadView 之后已经提交 ,因此对当前事务也是可见的。
- 在,则表示创建该数据版本的事务仍然活跃,或者在当前事务生成 ReadView 之后开始 ,因此对当前事务是不可见的 → 找 Undo Log 回退版本 → 继续判断。
举个例子
读事务开启了一个 ReadView,这个 ReadView 里面记录了当前活跃事务的 ID 列表(444、555、665),以及最小事务 ID(444)和最大事务 ID(666)。当然还有自己的事务 ID 520,也就是 creator_trx_id。
它要读的这行数据的写事务 ID 是 x,也就是 DB_TRX_ID。
- 如果 x = 110,显然在 ReadView 生成之前就提交了,所以这行数据是可见的。
- 如果 x = 667,显然是未知世界,所以这行数据对读操作是不可见的。
- 如果 x = 519,虽然 519 大于 444 小于 666,但是 519 不在活跃事务列表里,所以这行数据是可见的。因为 519 是在 520 生成 ReadView 之前就提交了。
- 如果 x = 555,虽然 555 大于 444 小于 666,但是 555 在活跃事务列表里,所以这行数据是不可见的。因为 555 不确定有没有提交。
可重复读和读已提交在 ReadView 上的区别是什么?
可重复读(REPEATABLE READ)和读已提交(READ COMMITTED)的区别在于生成 ReadView 的时机不同。
- 可重复读 :在第一次读取数据时生成一个 ReadView,这个 ReadView 会一直保持到事务结束,这样可以保证在事务中多次读取同一行数据时,读取到的数据是一致的。
- 读已提交 :每次读取数据前都生成一个 ReadView,这样就能保证每次读取的数据都是最新的。
如果两个 AB 事务并发修改一个变量,那么 A 读到的值是什么,怎么分析。
当两个事务 A 和 B 并发修改同一个变量时,A 事务读取到的值取决于多个因素,包括事务的隔离级别、事务的开始时间和提交时间等。
- 读未提交:在这个级别下,事务可以看到其他事务尚未提交的更改。如果 B 更改了一个变量但尚未提交,A 可以读到这个更改的值。
- 读提交:A 只能看到 B 提交后的更改。如果 B 还没提交,A 将看到更改前的值。
- 可重复读:在事务开始后,A 总是读取到变量的相同值(也就是更改前的值),即使 B 在这期间提交了更改。这是通过 MVCC 机制实现的。
- 可串行化:A 和 B 的操作是串行执行的,如果 A 先执行,那么 A 读到的值就是 B 提交前的值 ;如果 B 先执行,那么 A 读到的值就是 B 提交后的值。
💡 图示:MVCC 多版本读取流程(Mermaid)
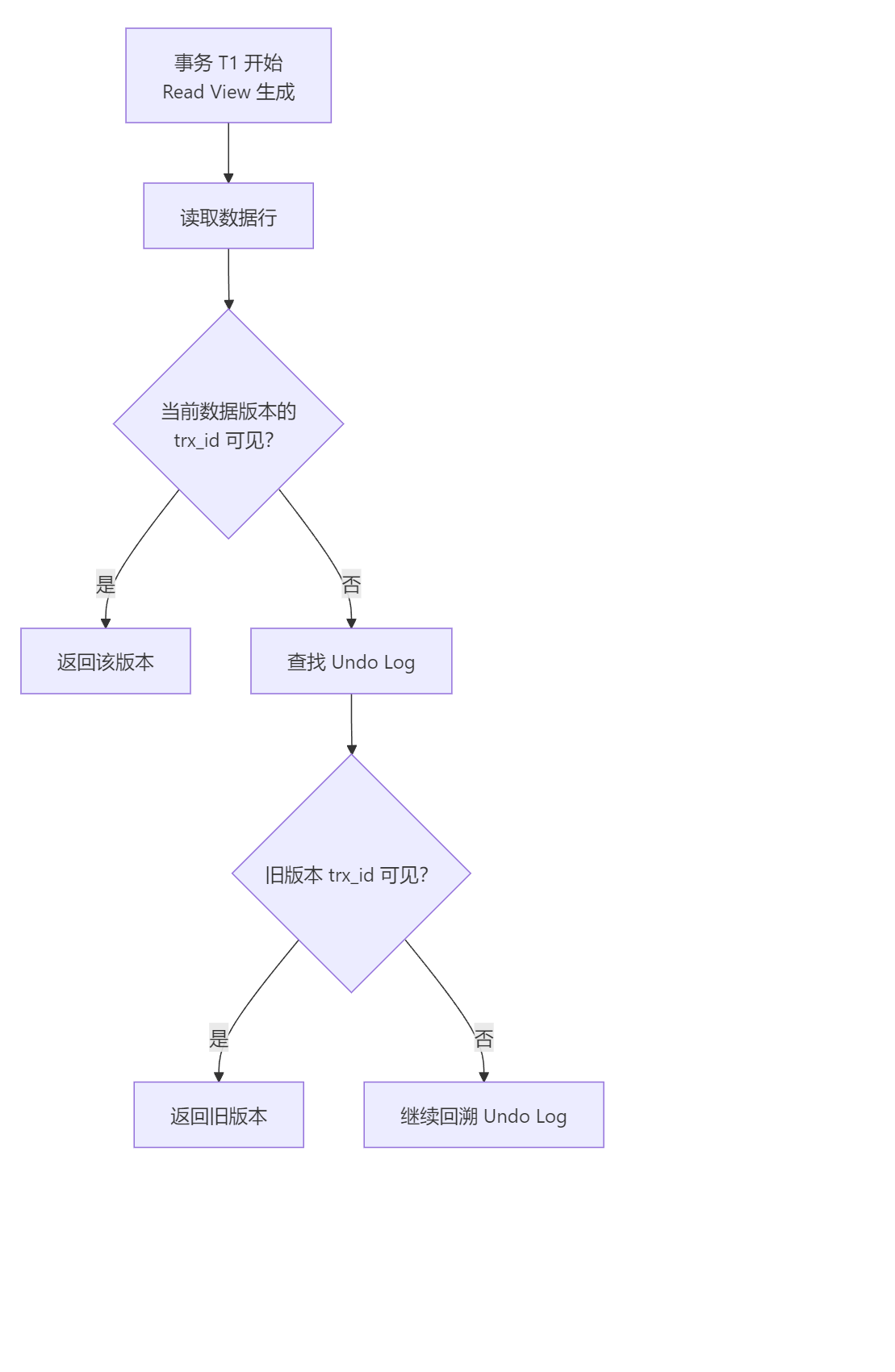
这个流程体现了:InnoDB 会不断回溯版本链,直到找到当前事务可见的数据版本为止。
📌 哪些语句使用 MVCC?
| SQL 类型 | 是否使用 MVCC |
|---|---|
SELECT (普通快照读) |
✅ 使用(无需加锁) |
SELECT ... LOCK IN SHARE MODE / FOR UPDATE |
❌ 不使用(加锁读) |
INSERT / UPDATE / DELETE |
❌ 不使用(直接修改最新版本) |
⚠️ MVCC 的前提条件
- 使用 InnoDB 存储引擎
- 使用 RC(Read Committed)或 RR(Repeatable Read) 隔离级别
- ✅ MySQL 默认是 RR,支持一致性读(Repeatable Read)
- ❌ Serializable 级别会强制加锁,不走 MVCC
🧠 类比记忆:MVCC 就像"版本历史"
可以把每条记录看作是一个文档的"历史版本":
- 每次编辑(UPDATE)都会产生一个快照(Undo Log)
- 每个人(事务)看到的文档版本,取决于他进入文档时系统展示的那一页(Read View)
✅ 总结重点
| 项目 | 内容 |
|---|---|
| 目的 | 解决高并发下的读写冲突,提高性能 |
| 核心机制 | Undo Log + trx_id + roll_pointer |
| 数据可见性 | 通过版本链 + Read View 判断 |
| 适用场景 | 快照读,不加锁 |
| 对应隔离级别 | Read Committed、Repeatable Read |