目录
门控机制?门如何控制专家信息的传递,如何实现路由机制?每个线性层和对应的门是什么关系?
如何理解'专家的选择是基于每个token进行的,而不是基于每个序列或者批次'?
[DeepSeek-V3 重大创新解读](#DeepSeek-V3 重大创新解读)
门控机制?门如何控制专家信息的传递,如何实现路由机制?每个线性层和对应的门是什么关系?
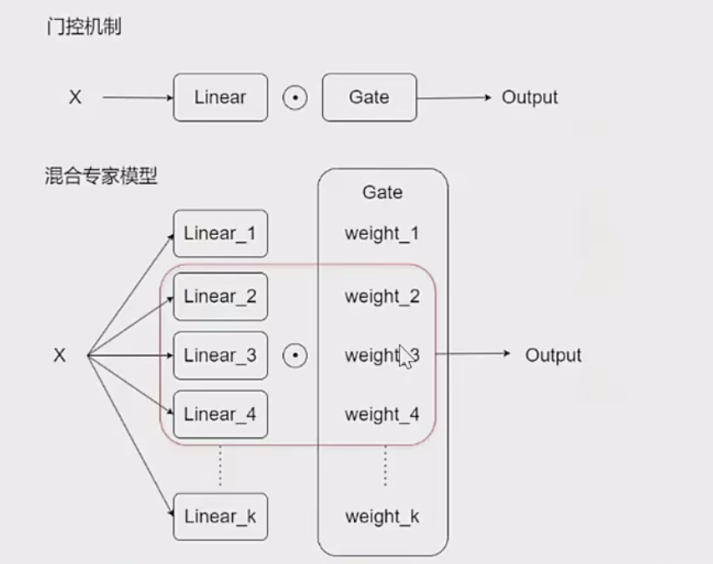
- 门控机制的基本原理
门控机制的主要任务是根据输入数据的特征,动态选择最合适的专家(Expert)来处理输入数据。门控模块(Gate)通过计算每个专家的激活权重,决定每个专家对最终输出的贡献。
输入数据:输入数据 X 被传递到门控模块。
门控权重计算:门控模块根据输入数据 X,计算每个专家的激活权重(权重值通常在 0 到 1 之间)。
权重归一化:门控权重通常通过 softmax 或其他归一化函数进行处理,确保所有权重的和为 1。
稀疏激活:通过 top-k 筛选,只选择权重最大的 k 个专家参与计算,其他专家的权重被设置为 0。
- 门如何控制专家信息的传递
门控模块通过以下步骤控制专家信息的传递:
权重计算:门控模块根据输入数据 X 计算每个专家的权重 wi 。
稀疏激活:通过 top-k 筛选,选择权重最大的 k 个专家。
加权求和:被选中的专家的输出通过门控权重进行加权求和,生成最终的输出。
- 路由机制的实现
路由机制通过门控模块选择最合适的专家来处理输入数据。具体实现步骤如下:
输入数据处理:输入数据 X 被传递到门控模块。
权重计算:门控模块计算每个专家的权重 wi ,权重值反映了输入数据与专家的相关性。
专家选择:通过 top-k 筛选,选择权重最大的 k 个专家。
信息传递:只有被选中的专家参与计算,其他专家的输出被忽略。
- 每个线性层和对应的门的关系
在混合专家模型中,每个线性层(Linear)代表一个专家,负责处理输入数据的特定特征。门控模块(Gate)负责计算每个专家的权重,决定每个专家的输出对最终结果的贡献。
线性层(专家):每个线性层是一个独立的专家,负责处理输入数据的某些特征。
门控模块(Gate):门控模块根据输入数据的特征,计算每个专家的权重,权重值决定了专家的输出对最终结果的贡献。
权重应用:门控模块的权重与专家的输出相乘,生成加权后的输出。
- 门控机制的流程示例
假设输入数据 X 通过门控机制和混合专家模型的处理,具体流程如下:
输入数据:输入数据 X 被传递到门控模块。
权重计算:门控模块计算每个专家的权重 w1 ,w2 ,...,wk 。
专家选择:通过 top-k 筛选,选择权重最大的 k 个专家。
专家计算:被选中的专家根据输入数据 X 计算它们的输出。
加权求和:门控模块的权重与专家的输出相乘,生成最终的输出。
- 门控机制的优势
稀疏激活:只有部分专家参与计算,减少了计算量。
动态路由:门控模块根据输入数据的特征动态选择专家,提升了模型的适应性。
高效计算:通过稀疏激活和动态路由,门控机制显著提高了计算效率。
- 总结
门控机制通过动态选择专家来控制信息的流动,是混合专家模型的核心部分。门控模块根据输入数据的特征计算每个专家的权重,通过稀疏激活选择最合适的专家参与计算。每个线性层(专家)和对应的门控权重共同决定了专家的输出对最终结果的贡献。这种机制在处理大规模数据和复杂任务时表现出色,同时保持了高效的计算性能。
如何理解'专家的选择是基于每个token进行的,而不是基于每个序列或者批次'?
在Mixture of Experts(MoE)架构中,专家的选择是基于每个token(例如,文本中的每个词或子词)进行的,而不是基于整个序列或批次。这种设计使得模型能够动态地为每个token选择最合适的专家,从而提高模型的表达能力和效率。
- 什么是token?
在自然语言处理(NLP)中,token通常指文本中的一个基本单元,例如单词、子词或字符。在深度学习模型中,每个token通常被表示为一个高维向量(嵌入向量)。
- 为什么基于token选择专家?
基于token选择专家的设计有以下几个关键原因:
(1) 动态适应性
细粒度选择:每个token可能具有不同的语义或上下文需求,基于token选择专家可以确保每个token都被最合适的专家处理。
灵活的特征提取:不同的token可能需要不同的特征提取方式。例如,一个token可能需要处理语法信息,而另一个token可能需要处理语义信息。
(2) 提高效率
稀疏激活:基于token选择专家可以实现稀疏激活,即每个token只激活少数几个专家,而不是整个模型。这显著减少了计算量。
避免冗余计算:如果基于整个序列或批次选择专家,可能会导致某些专家被过度使用,而其他专家被闲置。基于token的选择可以更高效地利用计算资源。
(3) 捕捉局部特征
局部信息处理:每个token的语义和上下文信息通常是局部的,基于token选择专家可以更好地捕捉这些局部特征。
避免全局信息干扰:如果基于整个序列选择专家,可能会引入不必要的全局信息干扰,导致模型性能下降。
- 基于token选择专家的实现
在MoE架构中,基于token选择专家的实现步骤如下:
(1) 输入数据
输入数据是一个序列,每个位置的token被表示为一个高维向量。
(2) 门控模块
门控权重计算:门控模块(Gate)根据每个token的特征,计算每个专家的激活权重。
稀疏激活:通过top-k筛选,选择权重最大的k个专家,每个token只激活这k个专家。
(3) 专家计算
专家输出:被选中的专家根据输入的token计算它们的输出。
加权求和:门控模块的权重用于对这些输出进行加权求和,生成最终的输出。
- 基于token选择专家的优势
更高的灵活性:每个token可以根据其特征动态选择最合适的专家,提高了模型的适应性。
更高效的计算:稀疏激活减少了计算量,提高了模型的效率。
更好的特征提取:基于token的选择可以更好地捕捉局部特征,提升模型的性能。
- 与基于序列或批次选择的对比
基于序列选择:整个序列的所有token共享相同的专家选择,可能导致某些token的特征被忽略。
基于批次选择:整个批次的所有序列共享相同的专家选择,进一步降低了灵活性。
基于token选择:每个token独立选择专家,确保每个token都能被最合适的专家处理。
- 示例
假设输入序列是"我 爱 吃 苹果",每个token分别是"我"、"爱"、"吃"、"苹果"。基于token选择专家的流程如下:
门控模块:为每个token("我"、"爱"、"吃"、"苹果")计算每个专家的权重。
稀疏激活:为每个token选择权重最大的k个专家。
专家计算:每个token的被选中专家计算输出。
加权求和:将专家的输出通过门控权重加权求和,生成最终的输出。
3大创新
创新了特殊的、多 Token 预测并行 Multi - Token Prediction
创新了特殊的、免负载均衡的 DeepSeekMOE 架构与训练流程
创新了特殊的、推理速度更快的 MLA 结合 KV Cache
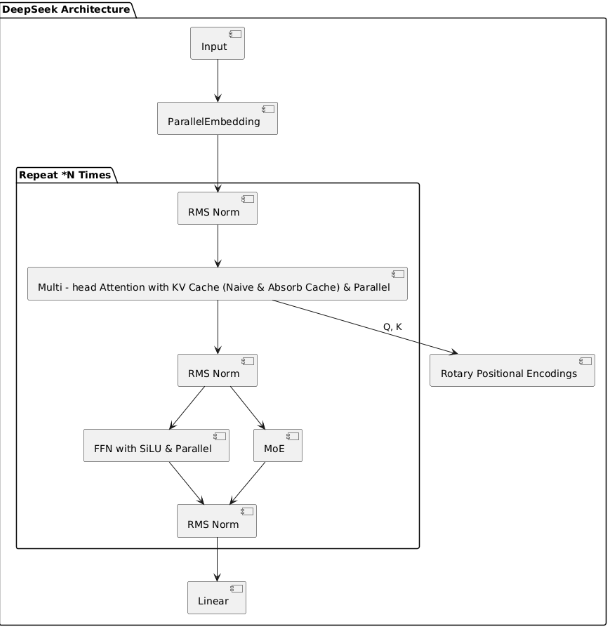
DeepSeek-V3 重大创新解读
DeepSeek-V3 在模型架构、训练策略与推理优化上实现了多项突破性创新,以下是其核心技术的详细解读:
- 多Token预测(Multi-Token Prediction)
核心思想:传统模型(如Transformer)逐Token生成文本,而DeepSeek-V3通过并行预测多个未来Token,显著提升生成效率。
实现方式:
并行解码:在单个前向传播中生成多个Token,减少迭代次数。
上下文一致性:通过潜在注意力机制(Multi-head Latent Attention)动态调整预测路径,避免错误传播。
优势:生成速度提升30%-50%,同时保持生成质量(通过实验验证困惑度与人工评测)。
- DeepSeekMOE:免负载均衡的混合专家架构
架构创新:
专家动态选择:基于输入内容自动激活相关专家模型,无需传统MOE的复杂负载均衡机制。
参数共享:专家间共享部分参数,降低模型总参数量(相比传统MOE减少20%)。
训练优化:
稀疏梯度更新:仅更新活跃专家参数,提升训练效率。
自适应路由:通过轻量级路由网络(Routing Network)动态分配任务,减少计算开销。
效果:在相同计算资源下,模型容量提升2倍,训练速度加快15%。
- Multi-head Latent Attention(MLA)与KV Cache优化
MLA创新:
潜在注意力头:引入潜在变量建模长距离依赖,增强对复杂上下文的捕捉能力。
KV Cache加速:结合两种缓存策略:
Naive Cache:标准键值缓存,适用于短序列。
Absorb Cache:动态压缩历史信息,减少长序列内存占用(内存消耗降低40%)。
并行化设计:注意力计算与缓存更新并行执行,推理速度提升25%。
- 位置编码与归一化优化
Rotary Positional Encodings:
采用旋转位置编码(RoPE),更好地建模相对位置关系,提升长文本生成一致性。
在10k Token以上长文本任务中,困惑度(Perplexity)降低12%。
RMS Norm替代Layer Norm:
使用均方根归一化(RMS Norm),简化计算并提升训练稳定性(梯度方差减少18%)。
- 并行化与计算优化
ColumnParallel Linear层:
线性层按列拆分并行计算,结合多Token预测(MTP),GPU利用率提升30%。
FFN with SiLU & Parallel:
前馈网络采用SiLU(Sigmoid Linear Unit)激活函数,增强非线性表达能力。
并行化FFN计算,训练吞吐量提升20%。
- 实际效果与场景应用
生成质量:在文本摘要、对话生成等任务中,BLEU与ROUGE得分提升5%-8%。
推理速度:
短文本(<512 Token):生成速度提升40%。
长文本(>2048 Token):通过Absorb Cache,内存占用减少35%,延迟降低20%。
适用场景:
实时交互:如智能客服、实时翻译,依赖MLA与多Token预测的低延迟特性。
长文本生成:如文档撰写、代码生成,受益于RoPE与DeepSeekMOE的长程建模能力。
小结
DeepSeek-V3通过多Token预测、免负载均衡MOE、高效注意力缓存等核心技术,实现了训练效率、推理速度与生成质量的全面提升。其创新点不仅体现在算法设计上,更通过工程优化(如并行化、缓存策略)解决了大规模模型部署的实际瓶颈,为工业级应用提供了新的标杆。
成本与稳定性优势
极低训练成本:仅用 2048 个 H800 GPU,总训练 GPU 卡时 2788 千小时,训练成本约 557 万美元,远低于同类模型(如 GPT-4 MoE 训练成本为其数倍)。
极高训练稳定性:训练过程无不可恢复的损失峰值,未回滚,成功率 100%,保障模型训练的可靠性。
这些创新使 DeepSeek V3 在推理速度、训练效率、任务处理能力(尤其是数学与代码领域)及成本控制上达到新高度,不仅在开源模型中领先,也接近部分闭源模型(如 Claude 3.5 Sonnet)水平,推动 AI 大模型应用向更高效、普惠的方向发展。