目录
[1 Hive架构全景图](#1 Hive架构全景图)
[2 核心组件运维职责详解](#2 核心组件运维职责详解)
[2.1 Metastore元数据中心](#2.1 Metastore元数据中心)
[2.2 Driver驱动组件](#2.2 Driver驱动组件)
[2.3 Executor执行引擎](#2.3 Executor执行引擎)
[3 与HDFS/YARN的协同关系](#3 与HDFS/YARN的协同关系)
[3.1 HDFS协同架构](#3.1 HDFS协同架构)
[3.2 YARN资源调度](#3.2 YARN资源调度)
[4 运维实战案例](#4 运维实战案例)
[4.1 Metastore连接泄露](#4.1 Metastore连接泄露)
[4.2 小文件合并](#4.2 小文件合并)
[5 最佳实践总结](#5 最佳实践总结)
[5.1 性能优化矩阵](#5.1 性能优化矩阵)
[6 总结](#6 总结)
1 Hive架构全景图
Hive作为Hadoop生态中的数据仓库工具,其架构设计完美融合了传统数据库概念与大数据技术栈。
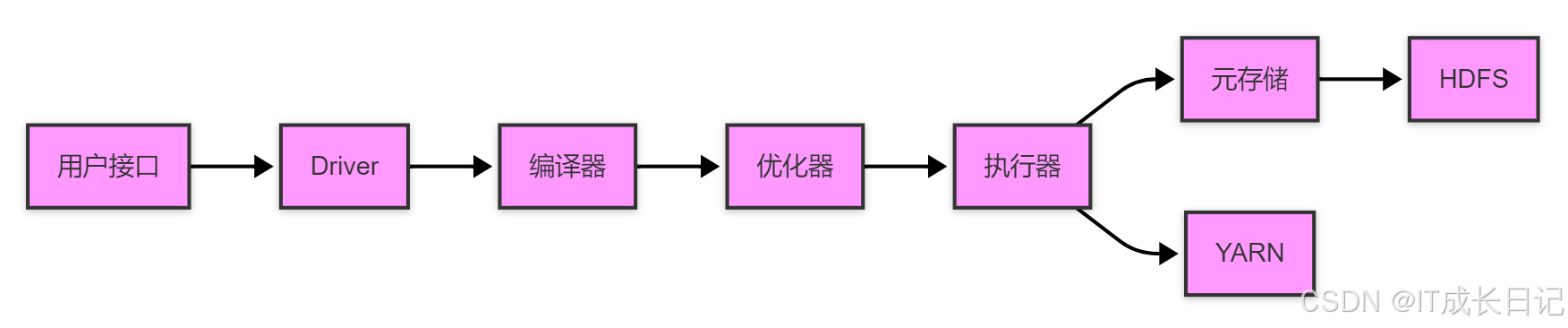
架构说明:
- 用户接口层:提供CLI、JDBC、WebUI等多种访问方式
- Driver驱动层:包含SQL解析、查询优化、执行计划生成等核心功能
- 执行引擎:将逻辑执行计划转为物理执行计划,提交到YARN运行
- 存储系统:元数据存储在Metastore,实际数据存储在HDFS
2 核心组件运维职责详解
2.1 Metastore元数据中心
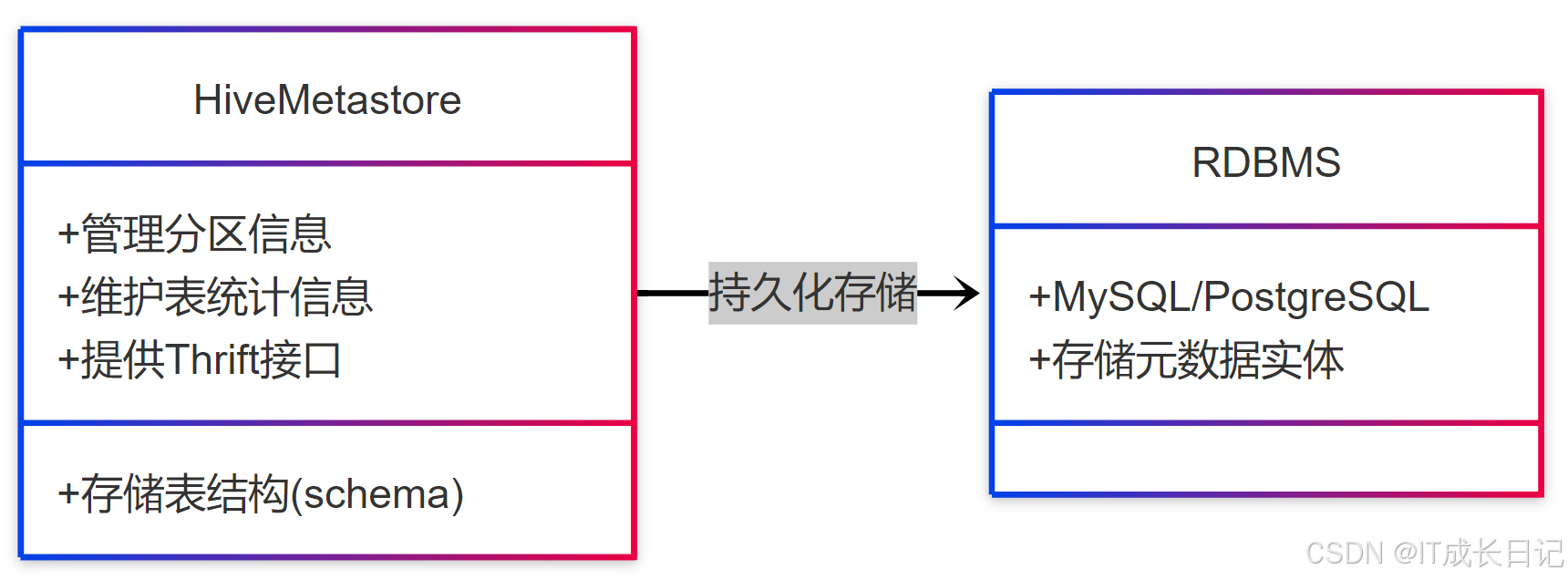
运维关键点:
- 高可用配置:建议部署Metastore的HA模式
- 定期备份:使用mysqldump定期备份元数据库
- 性能调优:优化hive.metastore.warehouse.dir参数
- 连接池管理:配置datanucleus.connectionPoolingType
2.2 Driver驱动组件

组件职责:
- Parser:SQL词法/语法解析
- Semantic Analyzer:验证表/列是否存在
- Optimizer:执行谓词下推、列裁剪等优化
-
Physical Plan:生成MapReduce/Tez/Spark任务
-
运维建议
-- 查看执行计划(调试优化)
EXPLAIN FORMATTED
SELECT * FROM table WHERE dt='2025-04-19';
2.3 Executor执行引擎
<!-- 选择执行引擎 -->
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>3 与HDFS/YARN的协同关系
3.1 HDFS协同架构
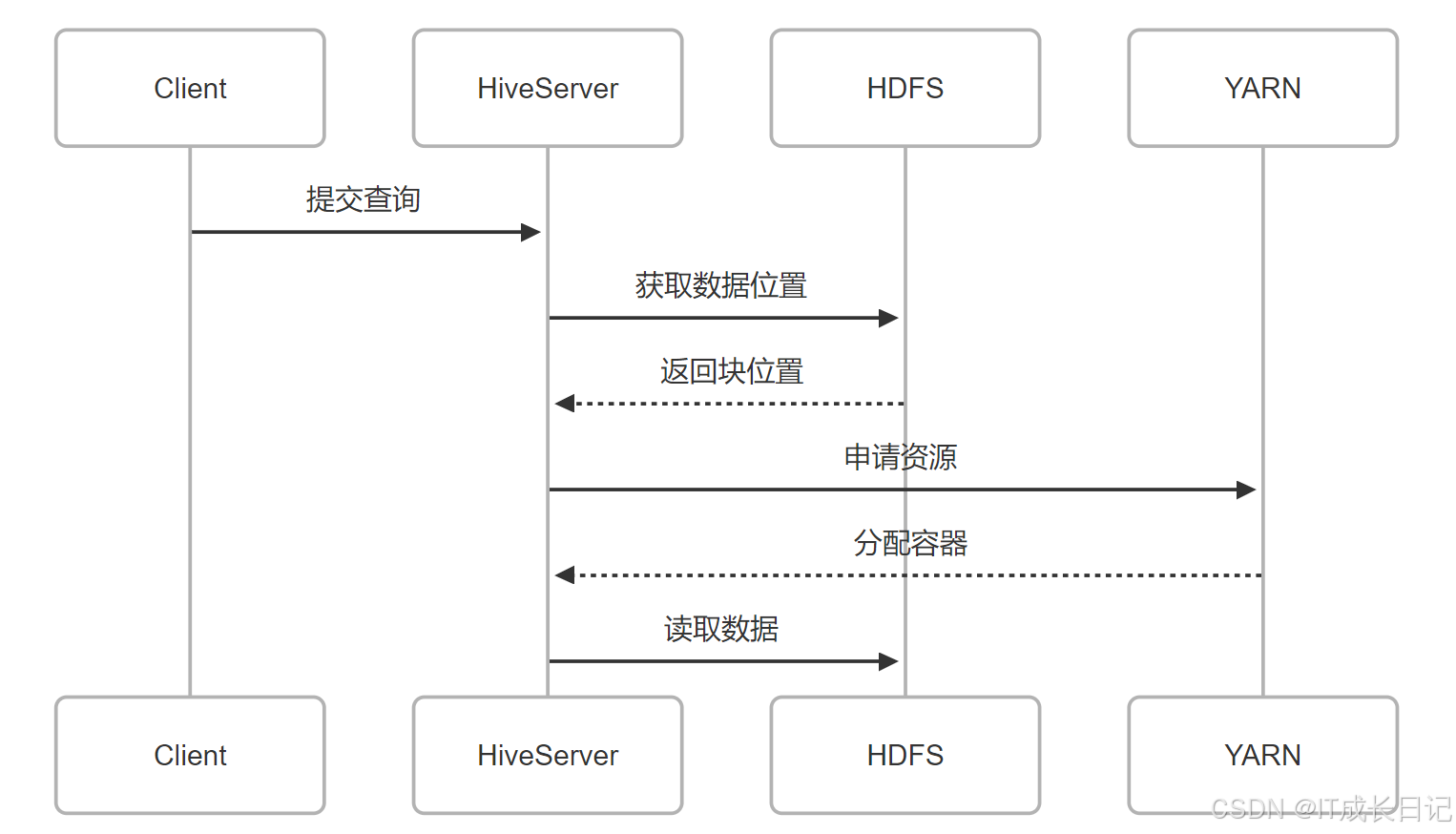
-
关键配置
dfs.replication 3
3.2 YARN资源调度

-
调优参数
-- 设置容器内存
SET hive.tez.container.size=8192;
SET hive.tez.java.opts=-Xmx6144m;
4 运维实战案例
4.1 Metastore连接泄露
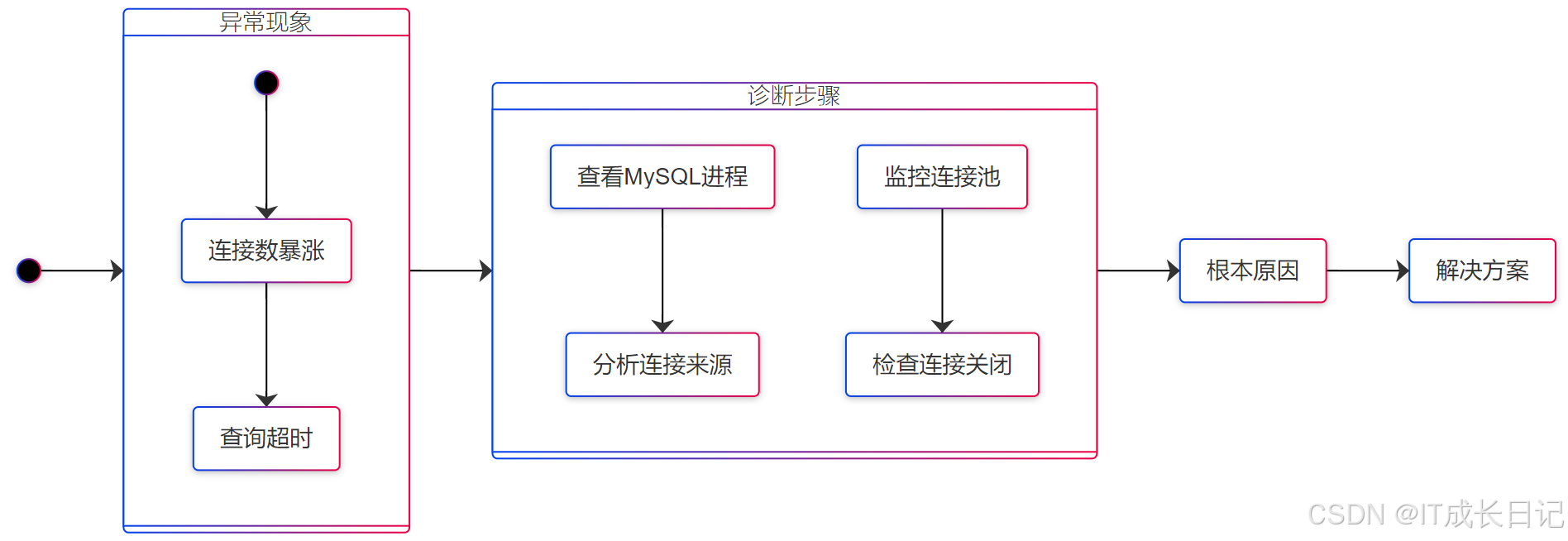
-
解决方案
// 确保代码中关闭连接
try (Connection conn = getConnection()) {
// 业务逻辑
} // 自动关闭
4.2 小文件合并
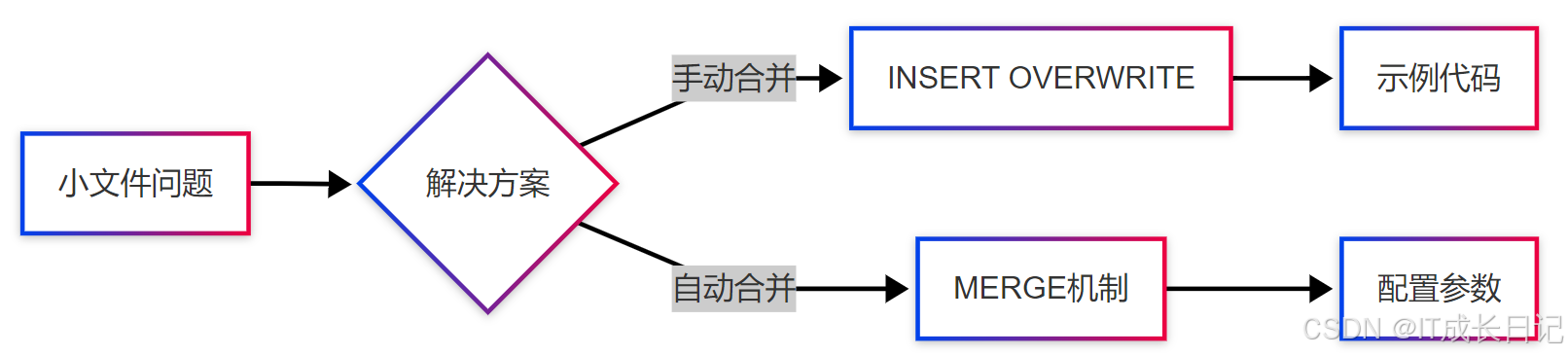
-
合并命令
-- 手动合并分区文件
INSERT OVERWRITE TABLE target PARTITION(dt='2025-04-19')
SELECT * FROM source WHERE dt='2025-04-19';
5 最佳实践总结
5.1 性能优化矩阵
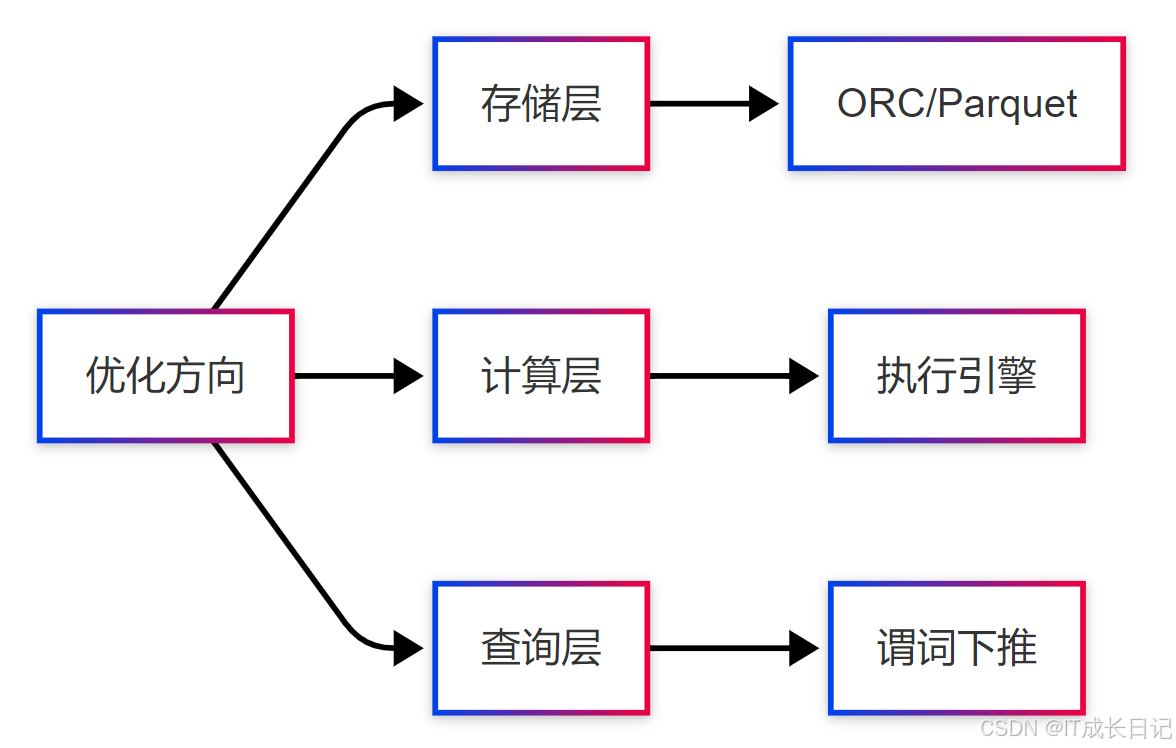
6 总结
通过本文的系统解析,您应该已经掌握Hive各组件的运维要点以及与HDFS/YARN的协同原理。良好的Hive运维=合理的架构设计+适当的参数调优+持续的监控告警。建议定期进行组件健康检查,保持Hive服务的最佳状态。