【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件yolo.py解读
文章目录
- 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件yolo.py解读
- 前言
- Detect类
- Model类
- parse_model函数
- [if name == 'main'](#if name == 'main')
- 总结
前言
在详细解析YOLOV3网络之前,首要任务是搭建Ultralytics--YOLOV3【Windows11下YOLOV3人脸检测】所需的运行环境,并完成模型的训练和测试,展开后续工作才有意义。
本博文对models/yolo.py代码进行解析,yolo.py文件根据yaml网络配置文件来搭建YOLOV3网络模型。其他代码后续的博文将会陆续讲解。
这里只是主要的代码解析,后续会补全。
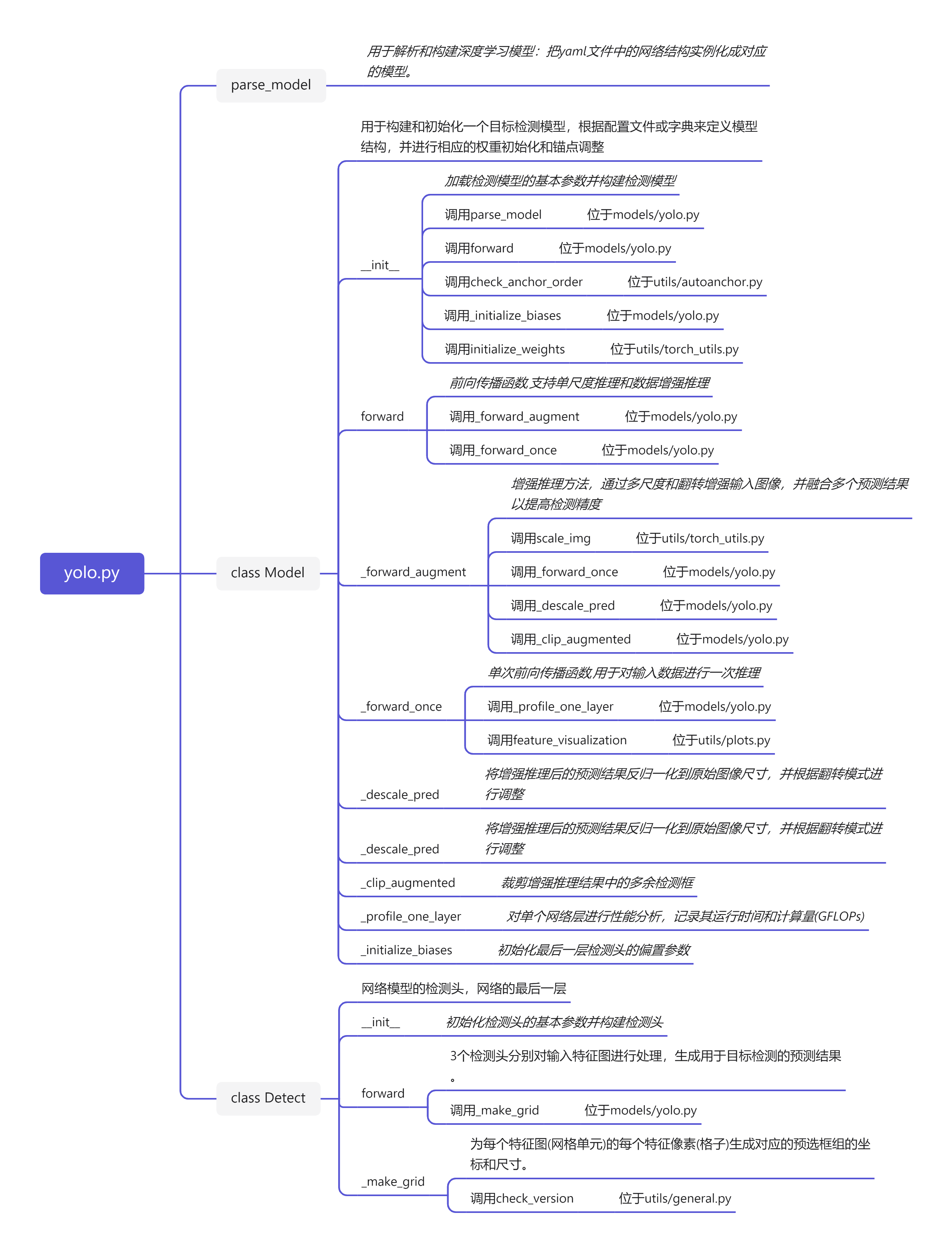
Detect类
__init__成员函数
初始化检测头的基本参数并构建检测头。
python
def __init__(self, nc=80, anchors=(), ch=(), inplace=True):
"""
初始化检测头的基本参数并构建检测头
:param nc:类别数量
:param anchors:预选框信息
:param ch:输入通道数
:param inplace:
"""
super().__init__()
self.nc = nc # 类别数量
self.no = nc + 5 # 每个预选框的输出维度:5表示置信度,预选框中心坐标,预选框尺寸
self.nl = len(anchors) # 表示检测头的个数(通常3个)
self.na = len(anchors[0]) // 2 # 特征图上每个特征点的预选框数量(3个),除以2是因为列表中一对宽高算一个框
# grid是网格单元的x,y坐标(整数),左上角为(1,1),右下角为(input.w//stride,input.h//stride)
self.grid = [torch.zeros(1)] * self.nl # 初始化网格单元预选框组坐标列表
self.anchor_grid = [torch.zeros(1)] * self.nl # 初始化网格单元预选框组尺寸列表
# self.register_buffer()是一种将张量注册为模型缓冲区的方法:不会被优化器更新(即不会参与梯度计算);被保存到模型的状态字典中(state_dict)并在加载模型时恢.
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # 注册常量anchor并将预选框尺寸存入,shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # 检测头都是1×1卷积(输出是框数*框的维度数)
# inplace:一般都是True,使用原地操作:可以通过减少内存分配来提高效率.
self.inplace = inplace # 原地操作直接修改张量的数据而不是创建新的张量,这可以节省内存并加快运算速度,但原地操作可能会对自动求导过程产生影响Detect模块为下图中的红色标记区域:
forward成员函数
三个检测头分别对输入特征图进行处理,生成用于目标检测的预测结果。调用了_make_grid成员函数。
python
def forward(self, x):
"""
3个检测头分别对输入特征图进行处理,生成用于目标检测的预测结果
:param x:分别输入到3个检测头的特征图
:return:根据训练或推断阶段返回不同的预测结果
"""
z = [] # 推断输出
# 对三个特征图分别进行处理,原始图像尺寸(640,640)下采样8/16/32倍==>(n, no, 80, 80),(n, no, 40, 40),(n, no, 20, 20)
for i in range(self.nl):
# 经过检测1*1卷积,通道数变成5+分类数:(n, c, ny, nx)-->(n, 3×no, ny, nx)
x[i] = self.m[i](x[i])
# 维度重排列: (n, 3×no, ny, nx)-->(n, 3, no, ny, nx)-->(n, 3, ny, nx, no) (bs, 先验框组数, 特征图宽, 特征图高, 预测框基本信息+分类数)
bs, _, ny, nx = x[i].shape
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 推断阶段
if not self.training:
# 网格单元的尺寸和特征图尺寸不一致
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
# 特征图(网格单元的尺寸)每个像素(特征点)重新生成对应的预选框组的坐标和尺寸
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
# sigmoid激活函数来转换坐标 (n, 3, ny, nx, no)
y = x[i].sigmoid()
if self.inplace: # 原地操作直接修改张量,节省内存并加快运算速度
# 预测边界框位置(中心点)在所属网格单元左上角位置(grid[i])进行相对偏移值(y[..., 0:2] * 2 - 0.5)
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy (n, 3, ny, nx, 2)
# 预测边界框尺寸基于所对应的预选框宽高(anchor_grid[i])进行相对缩放((y[..., 2:4] * 2) ** 2) 缩放范围0~4
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh (n, 3, ny, nx, 2)
else: # 创建新的张量,不节省内存和加快运算速度
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy (n, 3, ny, nx, 2)
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh (n, 3, ny, nx, 2)
# 更新输出数据 (n, 3, ny, nx, 2)+(n, 3, ny, nx, 2)+(n, 3, ny, nx, 2+2+no-4)==>(n, 3, ny, nx, no)
y = torch.cat((xy, wh, y[..., 4:]), -1)
# 存储后处理了3个检测头输出的列表,每个检测头的数据(n, 3, ny, nx, no)==>(n, 3×ny×nx, no) 3×ny×nx代表检测头数量
z.append(y.view(bs, -1, self.no))
# 训练阶段直接返回检测头的输出x,预测阶段额外附带了3个检测头的后结果: 3个(n, 3×ny×nx, no)拼接成(n, m, no) m表示预测框总数
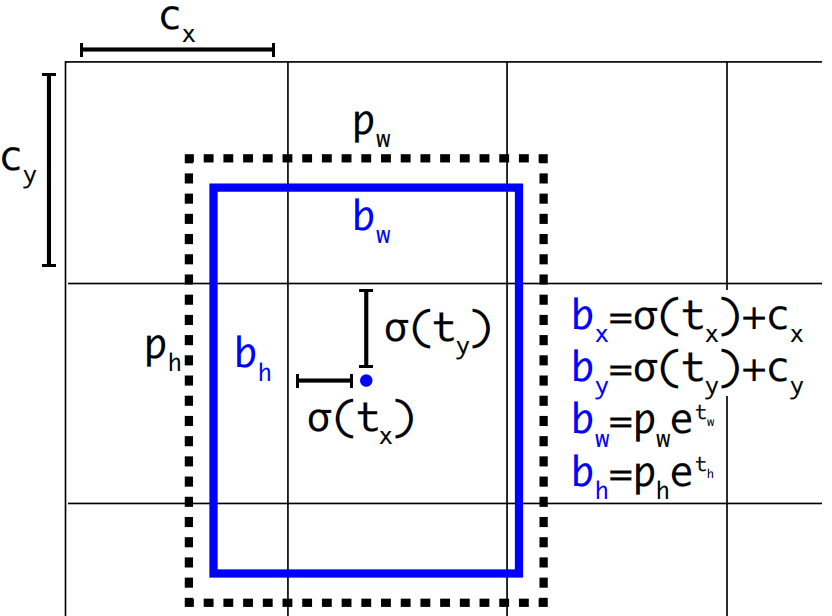
return x if self.training else (torch.cat(z, 1), x)测试阶段,根据预选框计算出预测框中心点的坐标和尺寸的示意图参考:
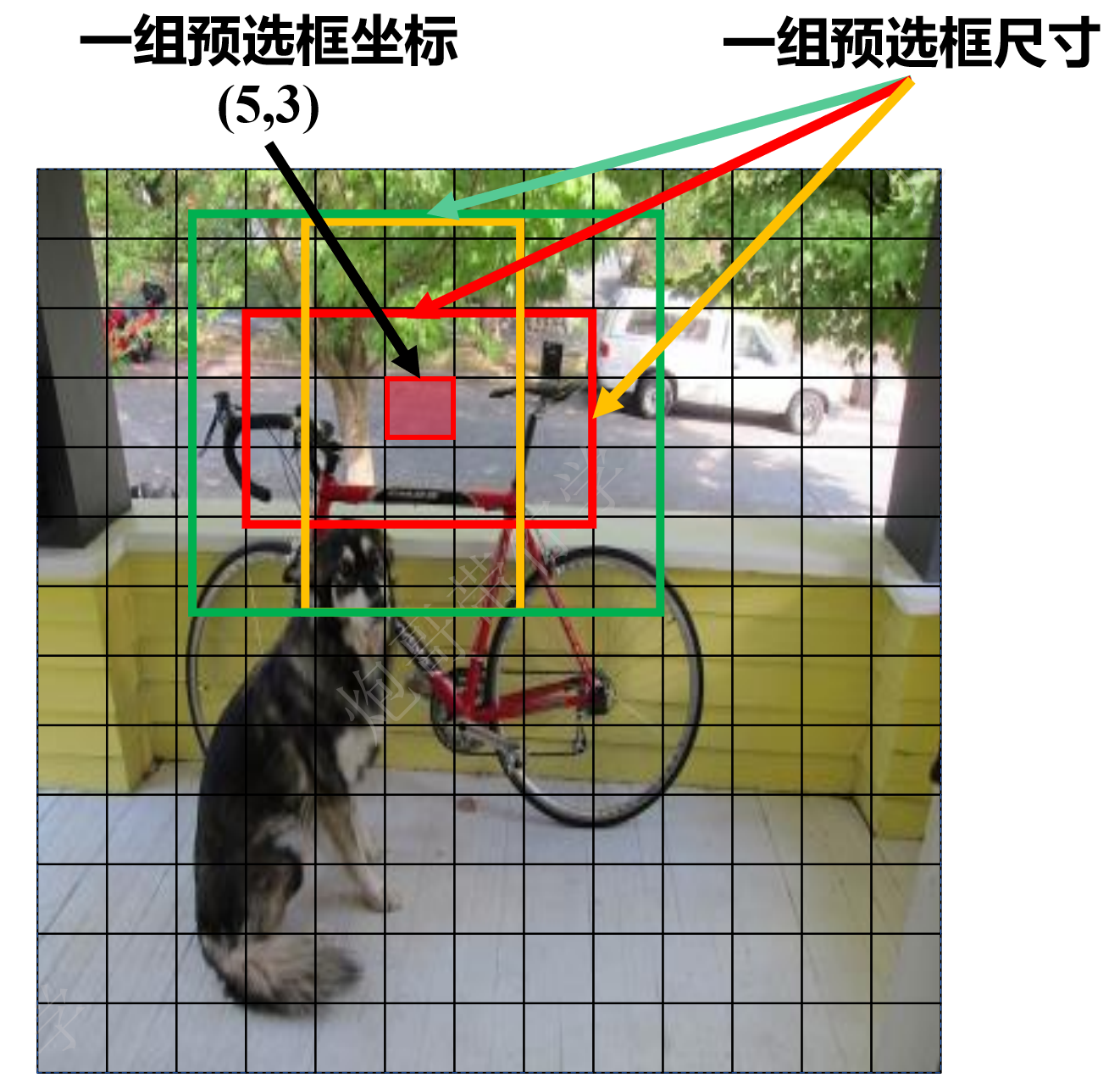
_make_grid成员函数
为每个特征图(网格单元)的每个特征像素(格子)生成对应的预选框组的坐标和尺寸。调用了【utils/general.py】的check_version函数。
python
def _make_grid(self, nx=20, ny=20, i=0):
"""
为每个特征图(网格单元)的每个特征像素(格子)生成对应的预选框组的坐标和尺寸
:param nx:特征图宽度
:param ny:特征图高度
:param i:当当前处理的特征图索引((检测头索引)
:return:对应的预选框组的坐标和尺寸
"""
d = self.anchors[i].device # 获取预选框所在的设备
if check_version(torch.__version__, '1.10.0'): # PyTorch版本是否满足某个最低要求,目的是兼容旧版本
# 新版生成网格坐标:允许用户指定索引的顺序是'ij'(矩阵索引)还是'xy'(笛卡尔索引)
# indexing='ij':i是同一行,j表示同一列;indexing='xy':x是同一列,y表示同一行.
# yv:网格的行索引;xv:网格的列索引
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')
else:
# 旧版生成网格坐标
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
# grid即网格单元每个格子对应的预选框组的坐标::(ny, ny, 2)-->(1, 3, ny, ny, 2) 2代表坐标x和y
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
# anchor_grid即网格单元每个格子对应的预选框组的宽高: (1, 3, ny, ny, 2) 2代表尺寸w和h
# stride是下采样率,三个征图相对于原始图像的下采样率分别是8,16,32
# 因为在外面预选框尺寸除了对应的下采样率,所以这需要再乘回来
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid特征图(网格单元)的每个像素(网格)都有一组3个预选框:其中像素坐标就是预选框的坐标(由grid保存),3个预选框所以坐标复制3份,对应到原始图像上的坐标只需要再乘以原始图像到当前特征图的下采样率即可;3个预选框的尺寸(由anchor_grid 保存)是在当前特征图上的尺寸,对应到原始图像上的尺寸同样需要再乘以下采样率。
Model类
__init__成员函数
加载检测模型的基本参数并构建检测模型。调用了【models/yolo.py】的parse_model函数、forward成员函数、【utils/autoanchor.py】的check_anchor_order函数、_initialize_biases成员函数和【utils/torch_utils.py】的initialize_weights函数。
python
def __init__(self, cfg='yolov3.yaml', ch=3, nc=None, anchors=None):
"""
加载检测模型的基本参数并构建检测模型
:param cfg:模型配置文件的路径或一个包含模型配置的字典
:param ch:输入图像通道数,默认为3
:param nc:类别数量,如果提供则覆盖配置文件中的值
:param anchors:预选框,如果提供则覆盖配置文件中的值,一般是None
"""
super().__init__() # 父类的构造方法
# ===================1. 加载模型配置信息===========================
# 读取cfg文件中的模型结构配置文件
if isinstance(cfg, dict): # 检查传入的参数cfg格式:是否是字典类型
self.yaml = cfg # cfg是字典类型则直接赋值给self.yaml
else: # 不是字典类型(yaml文件路径)
import yaml # 导入yaml库,用于处理YAML文件
self.yaml_file = Path(cfg).name # 获取yaml文件名
with open(cfg, encoding='ascii', errors='ignore') as f:
# 将yaml文件加载为字典
self.yaml = yaml.safe_load(f) # 使用yaml安全加载:解析文件内容,获取文件中每条的信息(除了注释内容)
# ============================================================
# =======================2. 更新模型配置信息===========================
# 定义模型超参数
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # 输入通道数,优先使用配置文件中的值否则使用默认值
if nc and nc != self.yaml['nc']: # 如果提供了类别数量且与配置文件中的值不同
# 输出日志信息:覆盖配置文件中的类别数量
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # 覆盖配置文件中的类别数量
if anchors: # 如果提供了锚点框
# 输出日志信息:覆盖配置文件中的锚点框
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # 覆盖配置文件中的锚点框
# ==================================================================
# 解析模型并生成模型对象和特定输出层索引列表
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch])
# 默认类别名称序号列表(从0到nc-1)
self.names = [str(i) for i in range(self.yaml['nc'])]
# 从配置字典中获取inplace值,如果不存在则默认设为True
self.inplace = self.yaml.get('inplace', True)
# ===================3. 调整Detect预选框尺寸============================
# 构建步长和锚点
m = self.model[-1] # 获取模型的最后一层,通常是Detect层
if isinstance(m, Detect): # 模型最后一层为Detect
s = 256 # 模型输入图像的大小
m.inplace = self.inplace
# 通过前向传播一个大小为(1, ch, s, s)的零张量,计算每个检测层的步长(输入图像宽高与特征图宽高的比值),计算结果转换为PyTorch张量赋值给m.stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))])
# 原始定义的预选框尺寸匹配的是原始图片,现在将其缩放适合对应的特征图的尺寸
m.anchors /= m.stride.view(-1, 1, 1)
# 检查anchor顺序与stride顺序是否一致
check_anchor_order(m)
# 将保存步长
self.stride = m.stride
# 初始化bias
self._initialize_biases()
# ===============================================================
# 初始化权重
initialize_weights(self)
# 打印模型结构信息
self.info()
LOGGER.info('')forward成员函数
模型前向传播函数,支持单尺度推理和数据增强推理。调用了_forward_augment成员函数或者_forward_once成员函数。
python
def forward(self, x, augment=False, profile=False, visualize=False):
"""
前向传播函数,支持单尺度推理和数据增强推理
:param x:输入图像数据
:param augment: 是否启用数据增强推理
:param profile:是否启用性能分析
:param visualize:是否可视化特征图
:return:模型的输出结果
"""
if augment:
return self._forward_augment(x) # 使用数据增强推理
return self._forward_once(x, profile, visualize) # 使用单尺度推理_forward_augment成员函数
增强推理方法,通过多尺度和翻转增强输入图像,并融合多个预测结果以提高检测精度。调用了【utils/torch_utils.py】的scale_img函数、_forward_once成员函数、_descale_pred成员函数和_clip_augmented成员函数。
python
def _forward_augment(self, x):
"""
增强推理方法,通过多尺度和翻转增强输入图像,并融合多个预测结果以提高检测精度
:param x:输入图像张量
:return:增强推理的结果(多个预测结果的拼接)以及None
"""
img_size = x.shape[-2:] # 获取输入图像的高度和宽度
s = [1, 0.83, 0.67] # 定义缩放比例列表
f = [None, 3, None] # 定义翻转模式列表(2-上下翻转,3-左右翻转)
y = [] # 用于存储每个增强版本的输出
for si, fi in zip(s, f): # 遍历缩放比例和翻转模式
# 根据缩放比例和翻转模式生成增强后的输入图像
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # 对增强后的图像进行单次前向传播 [0]是取Detect在非训练模式时额外附带的3个检测头的后结果
yi = self._descale_pred(yi, fi, si, img_size) # 将预测结果反归一化到原始图像尺寸
y.append(yi) # 将处理后的预测结果添加到输出列表
y = self._clip_augmented(y) # 裁剪增强推理结果中的多余检测框
# 将多个数据增强预测的(n, m, no)在m上拼接; n:批量数;m:检测框数量;no:预测框信息
return torch.cat(y, 1), None # 增强推理的预测结果 训练阶段的预测结果数据增强是在一个图像进行多种旋转缩放组合方式生成多个图像。源码中,三种增强方式分别是:第一种是保持原始状态,第二种是缩小然后水平翻转,第三种只缩小。

_forward_once成员函数
单次前向传播函数,用于对输入数据进行一次推理。调用了_profile_one_layer成员函数和【utils/plots.py】的feature_visualization函数。
python
def _forward_once(self, x, profile=False, visualize=False):
"""
单次前向传播函数,用于对输入数据进行一次推理
:param x:输入图像数据
:param profile:是否启用性能分析
:param visualize:是否可视化特征图
:return:模型的输出结果
"""
y, dt = [], [] # 始化输出列表和时间记录列表
for m in self.model:
if m.f != -1: # 当前层不是从上一层获取输入
# 根据m.f的值确定输入来源:可能是某个指定层,或者指定层的列表
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f]
if profile:
# 启用性能分析,记录当前层的运行时间和计算量
self._profile_one_layer(m, x, dt)
x = m(x) # 执行当前层的前向传播
y.append(x if m.i in self.save else None) # 当前层是指定层则保存输出,否则保存None
if visualize:
# 启用可视化,保存当前层的特征图
feature_visualization(x, m.type, m.i, save_dir=visualize)
# 返回最终的输出 (n, m, no) n是批量数,即数据增强的次数,默认3次;m是3个特征图上的总预测框数;no预测框的信息
return x_descale_pred成员函数
将增强推理后的预测结果反归一化到原始图像尺寸,并根据翻转模式进行调整。
python
def _descale_pred(self, p, flips, scale, img_size):
"""
将增强推理后的预测结果反归一化到原始图像尺寸,并根据翻转模式进行调整
:param p:预测结果张量
:param flips:翻转模式(None-未翻转、2-上下翻转 或3-左右翻转)
:param scale:缩放比例(在增强推理时使用的缩放比例)
:param img_size:原始图像的尺寸(高度, 宽度)
:return:反归一化后的预测结果张量
"""
# 原地操作则直接修改预测结果
if self.inplace:
p[..., :4] /= scale # 对边界框的坐标和尺寸进行反缩放
if flips == 2: # 上下翻转,调整位置中心点的y坐标
p[..., 1] = img_size[0] - p[..., 1]
elif flips == 3: # 左右翻转,调整位置中心点的x坐标
p[..., 0] = img_size[1] - p[..., 0]
else:
# 创建新的张量修改预测结果
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale
if flips == 2:
y = img_size[0] - y
elif flips == 3:
x = img_size[1] - x
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p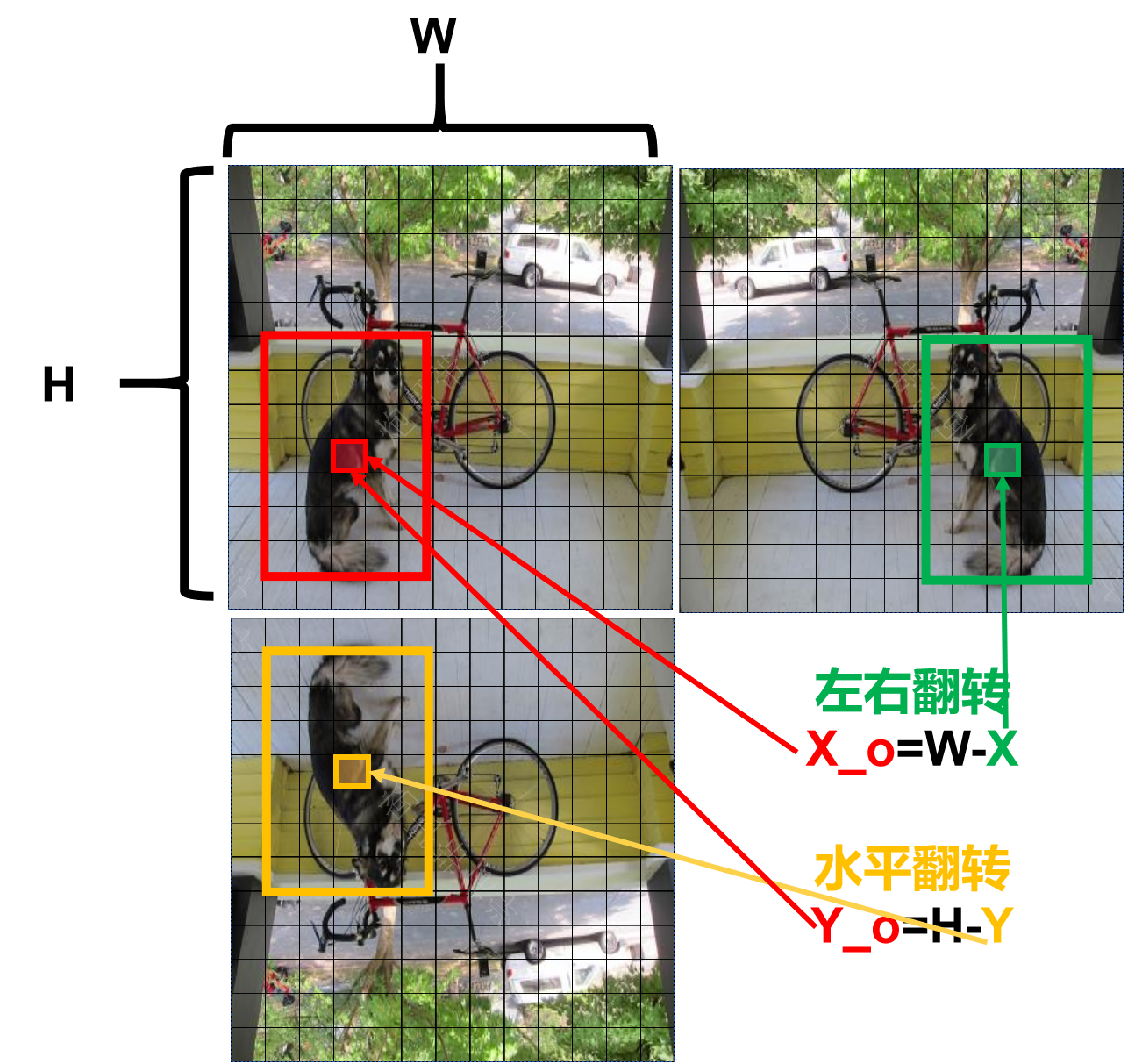
_clip_augmented成员函数
同一图像经过数据增强再模型推理之后,会有多个预测结果,裁剪增强推理结果中的多余预测框。
python
def _clip_augmented(self, y):
"""
裁剪增强推理结果中的多余检测框
:param y:增强推理后的预测结果列表
:return:裁剪后的预测结果列表
"""
nl = self.model[-1].nl # 检测头的数量(P3-P5层)
g = sum(4 ** x for x in range(nl)) # 网格点总数(基于检测层的网格大小)
e = 1 # 排除的层数
# y:(n, m, no) n:批量数,即数据增强的次数,默认3次;m:3个特征图上的总预测框数;no:预测框的信息
# y[0].shape[1] // g)是计算出的是小特征图预测框的数量
# 小特征图预测框的数量就是y[0].shape[1] // g)*1
# 中特征图预测框的数量就是y[0].shape[1] // g)*4
# 大特征图预测框的数量就是y[0].shape[1] // g)*4*4
# y的预测框数量拼接顺序是大/众/小
# 当前排除层数是1
# y[0]是第一种数据增强方式(即保持数据不变) 从末尾拿掉了小特征图预测框的数量
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # 计算小特征图预测框开始的序号
y[0] = y[0][:, :-i] # 从末尾拿掉了小特征图预测框
# y[-1]是第三种数据增强方式(数据尺寸缩小) 从开头拿掉了大特征图预测框的数量
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # 计算中特征图预测框开始的序号
y[-1] = y[-1][:, i:] # 从开始拿掉了大特征图预测框
return y网格点总数的含义: 在 YOLOv3 中,每个检测头的特征图被视作若干网格(每个特征像素就是一网格),这些网格的总数取决于特征图的大小和层数。假设原始图像尺寸为640×640,特征图大小通常是按照2倍的比例缩小的,P3~P5层分别是8/16/32倍下采样,那么:
- P3 层:80×80的网格,共有80×80=6400个网格点,即 4 2 × 20 × 20 {4^2} \times 20 \times 20 42×20×20个网格点。
- P4 层:40×40的网格,共有40×40=1600个网格点,即 4 1 × 20 × 20 {4^1} \times 20 \times 20 41×20×20个网格点。
- P5 层:20×20的网格,共有20×20=400个网格点,即 4 0 × 20 × 20 {4^0} \times 20 \times 20 40×20×20个网格。
实际网格点数是按平方增长的,因此比例关系是4倍的增长,使 "4**x"可以方便地表示不同检测层之间的网格点数量比例。
这段代码的含义如下图所示,一张图像经过数据增强后生成三张图像,并且全都输入到模型进行推理得到预测结果,每个数据增强图都有三个检测头的输出。源码中,第一种数据增强后的图像是去除了小特征上的预测框结果;第三种数据增强后的图像是去除了大特征上的预测框结果;第二种数据增强后的图像则保留了所有特征图上的预测结果。

复习一下,图中网格不是预测框,注意不要搞混了。这里图像上的网格代表的就是对应特征图在原图上的映射,网格越少越小说明特征图尺寸越小,并且每个网格是有3个预测框,博主在图中没有体现。
_profile_one_layer成员函数
对单个网络层进行性能分析,记录其运行时间和计算量(GFLOPs)。
python
def _profile_one_layer(self, m, x, dt):
"""
对单个网络层进行性能分析,记录其运行时间和计算量(GFLOPs)
:param m:当前网络层
:param x:输入数据张量
:param dt:时间记录列表,用于存储每一层的运行时间(以毫秒为单位)
:return:None
"""
c = isinstance(m, Detect) # 判断是否是最后的检测头
# thop.profile是一个常用的工具函数(通常来自thop库),用于分析模型的计算复杂度(FLOPs和参数量)
# thop.profile计算当前层的FLOPs(每秒浮点运算次数);/ 1E9转换为 GFLOPs;verbose=False 不输出详细信息
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # 计算当前层的GFLOPs
t = time_sync() # 测量当前层的运行时间
for _ in range(10): # 运行 10 次以减少误差
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100) # 将平均运行时间添加到dt列表中 *100=*1000/10
# 打印日志信息
if m == self.model[0]: # 第一层打印表头
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
# 打印当前层的性能信息
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c: # 最后一层打印总运行时间
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")_initialize_biases成员函数
初始化最后一层检测头的偏置参数。
python
def _initialize_biases(self, cf=None):
"""
初始化最后一层检测头的偏置参数
参考论文 https://arxiv.org/abs/1708.02002 section 3.3
:param cf: 类别频率(class frequency):用于调整分类偏置,如果未提供则使用默认值
:return:None
"""
m = self.model[-1] # 获取模型的最后一层检测头模块
for mi, s in zip(m.m, m.stride): # 遍历每个检测头及其对应的步长
b = mi.bias.view(m.na, -1) # 将卷积层的偏置reshape为(anchor数量,anchor信息维度):conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # 置信度偏置(每张640x640图像中有8个目标)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # 类别偏置
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True) # 更新卷积层的偏置这部分代码的数学逻辑是参考论文【Focal Loss for Dense Object Detection】
- 置信度偏置公式: 假设每张图像中有 N N N个目标,输入图像尺寸为 I I I,特征图尺寸为 F F F,特征图的步长(缩放比例)为 s = I / F s = I / F s=I/F,目标性偏置的初始值为: b i a s = log e ( N F 2 ) = log e ( N ( I / S ) 2 ) bias = {\log _{\rm{e}}}\left( {\frac{N}{{{F^2}}}} \right) = {\log _{\rm{e}}}\left( {\frac{N}{{{{\left( {I/S} \right)}^2}}}} \right) bias=loge(F2N)=loge((I/S)2N)。
- 类别偏置公式: 未提供类别频率则使用默认公式,类别个数是 K K K: b i a s = log e ( p K − p ) bias = {\log {\rm{e}}}\left( {\frac{{\rm{p}}}{{K - {\rm{p}}}}} \right) bias=loge(K−pp);提供了类别频率 c f cf cf则使用归一化的频率: b i a s = log e ( c f i ∑ j = 1 K c f i ) bias = {\log {\rm{e}}}\left( {\frac{{{\rm{c}}{{\rm{f}}{\rm{i}}}}}{{\sum\nolimits{{\rm{j = 1}}}^K {{\rm{c}}{{\rm{f}}_{\rm{i}}}} }}} \right) bias=loge(∑j=1Kcficfi)。
parse_model函数
parse model函数在Model类的__init__ 函数被调用中,主要作用是解析模型yaml,通过读取文件中的配置找到common.py中找到相对于的模块,然后组成一个完整的模型解析模型文件(字典形式),并搭建网络结构。调用了【models/common.py】的Conv类和Bottleneck类。
-
获取模型相关超参数: 获取配置字典里面模型配置的超参数,打印最开始展示的网络结构表的表头。
python# ===================1. 获取模型相关超参数============================ # logging模块日志输出:打印表头,用于记录每一层的信息 LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}") # 锚框信息,类别数,深度倍率,宽度倍率 anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'] # 特征图上每个特征点的预选框数量(一组) na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # 特征图上每个特征点的输出维度:anchors*(classes + 5) no = na * (nc + 5) # ============================================================yaml配置文件中对应内容部分:

-
网络搭建前准备: 找到每个网络层实际对应的函数或类,以及函数或类所需的传入参数。
python# f:输入来自哪一层的输出;n:模块重复次数;m:模块类型(字符串或类名);args:模块的参数 for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # 遍历模型的backbone和head中的网络单元 # =======================2. 网络搭建前准备=========================== # 动态加载模块: m = eval(m) if isinstance(m, str) else m # 利用eval函数动态加载字符串实际对应的类或函数 # 处理参数 for j, a in enumerate(args): try: args[j] = eval(a) if isinstance(a, str) else a # 利用eval函数将字符串转换为实际的变量 except NameError: pass # ================================================================yaml配置文件中对应内容部分:
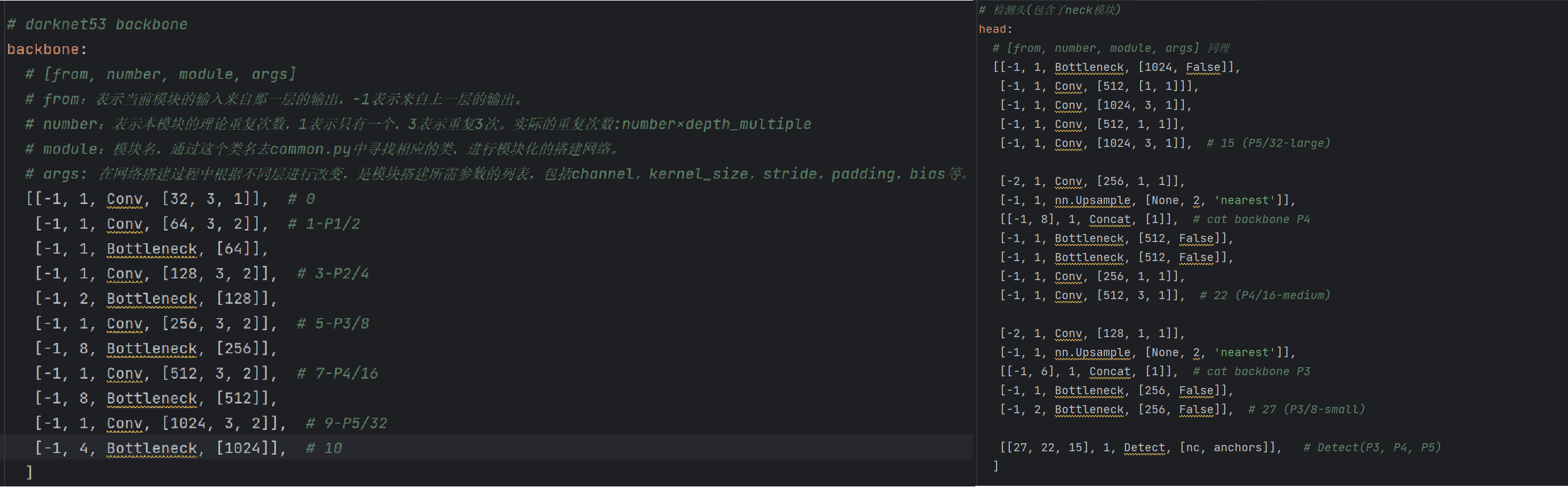
-
更新当前网络层的参数并搭建网络层: 计算网络层的重复次数和输出通道数,更新当前网络层参数,并使用当前网络层参数搭建网络层。调用了【utils/general.py】的make_divisible函数。
python# ===================3. 更新当前网络层的参数并搭建网络层============================ # 调整模块深度:根据深度倍率gd调整模块的重复次数 n = n_ = max(round(n * gd), 1) if n > 1 else n # 卷积类模块 # 当该网络单元的参数含有: 输入通道数, 输出通道数 if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]: # ch:记录着所有层的输出通道数;c1:当前层的输入通道数(指定层的输出通道数);c2:当前层的输出通道数; c1, c2 = ch[f], args[0] # c2 = no时是网络的最后一层,输出通道数必须是no if c2 != no: # 不是网络最后一层 # 根据宽度倍率gw调整输出通道数 c2 = make_divisible(c2 * gw, 8) # 更新当前层参数列表:在初始参数列表上加入当前网络层的输入通道数 args = [c1, c2, *args[1:]] if m in [BottleneckCSP, C3, C3TR, C3Ghost]: # 这些都不是YOLOV3原的网络结构 args.insert(2, n) # 参数列表第三个位置参数,插入模块的重复次数n n = 1 # 重置重复次数,默认值1 # 归一化模块 elif m is nn.BatchNorm2d: args = [ch[f]] # BN层的输入\输出通道数就是指定网络层的输出通道数 # 拼接模块 elif m is Concat: c2 = sum(ch[x] for x in f) # 输出通道数为所有输入通道数之和 # 检测头模块 elif m is Detect: args.append([ch[x] for x in f]) # 附加3个检测头的输入通道数 if isinstance(args[1], int): # 锚框数量是整数,没有指定锚框(几乎不执行) args[1] = [list(range(args[1] * 2))] * len(f) # 将其转换为范围列表,并复制检测头个数次 eg [[1,2,...,39,40], ... ,[1,2,...,39,40]] # 收缩模块(Contract) elif m is Contract: # 输出通道数是输入通道数乘以参数args[0]的平方 c2 = ch[f] * args[0] ** 2 # 扩展模块(Expand) elif m is Expand: # 输出通道数是输入通道数除以参数args[0]的平方 c2 = ch[f] // args[0] ** 2 # 直连模块 else: # 输出通道数是输入通道数 c2 = ch[f] # 构建模块组:当前网络层层模块重复n次 m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # =============================================================================实例化成同名模块过程中,YOLOV3目前只用到Conv,SPP,Bottleneck。SPP结构是YOLOV4中提出的,在yolov3-spp.yaml配置中使用到。
-
打印和保存网络层基本信息: 打印网络层的一些基本信息并保存,保留特定的网络层序号列表。
python# ===================4. 打印和保存网络层基本信息============================ # 获取模块m的类型名称并将其转换为字符串,这里通过截取和替换来清理字符串移除不必要的部分,如模块的完整路径和__main__.前缀 t = str(m)[8:-2].replace('__main__.', '') # 模块名称 # numel()方法返回参数中元素的总数 np = sum(x.numel() for x in m_.parameters()) # 模块参数总量 # 附加额外信息到模块上:模块层号(序号);模块来源索引;模块类型(名称);模块参数数量 m_.i, m_.f, m_.type, m_.np = i, f, t, np # 打印日志 LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # 保存特定的网络层序号列表:所有from(当前层输入)不是来自-1(上一层输出)的的网络层 save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # 将当前模块添加到layers layers.append(m_) # 更新记录每层通道数的列表 if i == 0: ch = [] # 去除最开始的RGB通道 ch.append(c2) # 更新网络输出通道数列表:加入当前层的输出通道数 # =====================================================================
完整代码:
python
def parse_model(d, ch): # model_dict, input_channels(3)
"""
用于解析和构建深度学习模型:把yaml文件中的网络结构实例化成对应的模型
:param d:yaml网络模型配置,通常包含模型结构信息的字典
:param ch:记录模型所有网络层的输出通道数,初始输入[3],即RGB
:return:整体网络模型和特定的网络层序号列表
"""
# ===================1. 获取模型相关超参数============================
# logging模块日志输出:打印表头,用于记录每一层的信息
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
# 锚框信息,类别数,深度倍率,宽度倍率
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
# 特征图上每个特征点的预选框数量(一组)
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors
# 特征图上每个特征点的输出维度:anchors*(classes + 5)
no = na * (nc + 5)
# ============================================================
# 网络层列表:存储生成的每一层模块;指定网络层输出列表:存储需要保存输出特征图的层索引;当前网络层的输出通道数
layers, save, c2 = [], [], ch[-1]
# f:输入来自哪一层的输出;n:模块重复次数;m:模块类型(字符串或类名);args:模块的参数
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # 遍历模型的backbone和head中的网络单元
# =======================2. 网络搭建前准备===========================
# 动态加载模块:
m = eval(m) if isinstance(m, str) else m # 利用eval函数动态加载字符串实际对应的类或函数
# 处理参数
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # 利用eval函数将字符串转换为实际的变量
except NameError:
pass
# ================================================================
# 处理不同类型的模块:根据模块类型m分别处理不同的情况
# ===================3. 更新当前网络层的参数并搭建网络层============================
# 调整模块深度:根据深度倍率gd调整模块的重复次数
n = n_ = max(round(n * gd), 1) if n > 1 else n
# 卷积类模块 # 当该网络单元的参数含有: 输入通道数, 输出通道数
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
# ch:记录着所有层的输出通道数;c1:当前层的输入通道数(指定层的输出通道数);c2:当前层的输出通道数;
c1, c2 = ch[f], args[0]
# c2 = no时是网络的最后一层,输出通道数必须是no
if c2 != no: # 不是网络最后一层
# 根据宽度倍率gw调整输出通道数
c2 = make_divisible(c2 * gw, 8)
# 更新当前层参数列表:在初始参数列表上加入当前网络层的输入通道数
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost]: # 这些都不是YOLOV3原的网络结构
args.insert(2, n) # 参数列表第三个位置参数,插入模块的重复次数n
n = 1 # 重置重复次数,默认值1
# 归一化模块
elif m is nn.BatchNorm2d:
args = [ch[f]] # BN层的输入\输出通道数就是指定网络层的输出通道数
# 拼接模块
elif m is Concat:
c2 = sum(ch[x] for x in f) # 输出通道数为所有输入通道数之和
# 检测头模块
elif m is Detect:
args.append([ch[x] for x in f]) # 附加3个检测头的输入通道数
if isinstance(args[1], int): # 锚框数量是整数,没有指定锚框(几乎不执行)
args[1] = [list(range(args[1] * 2))] * len(f) # 将其转换为范围列表,并复制检测头个数次 eg [[1,2,...,39,40], ... ,[1,2,...,39,40]]
# 收缩模块(Contract)
elif m is Contract:
# 输出通道数是输入通道数乘以参数args[0]的平方
c2 = ch[f] * args[0] ** 2
# 扩展模块(Expand)
elif m is Expand:
# 输出通道数是输入通道数除以参数args[0]的平方
c2 = ch[f] // args[0] ** 2
# 直连模块
else:
# 输出通道数是输入通道数
c2 = ch[f]
# 构建模块组:当前网络层层模块重复n次
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args)
# =============================================================================
# ===================4. 打印和保存网络层基本信息============================
# 获取模块m的类型名称并将其转换为字符串,这里通过截取和替换来清理字符串移除不必要的部分,如模块的完整路径和__main__.前缀
t = str(m)[8:-2].replace('__main__.', '') # 模块名称
# numel()方法返回参数中元素的总数
np = sum(x.numel() for x in m_.parameters()) # 模块参数总量
# 附加额外信息到模块上:模块层号(序号);模块来源索引;模块类型(名称);模块参数数量
m_.i, m_.f, m_.type, m_.np = i, f, t, np
# 打印日志
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}')
# 保存特定的网络层序号列表:所有from(当前层输入)不是来自-1(上一层输出)的的网络层
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1)
# 将当前模块添加到layers
layers.append(m_)
# 更新记录每层通道数的列表
if i == 0:
ch = [] # 去除最开始的RGB通道
ch.append(c2) # 更新网络输出通道数列表:加入当前层的输出通道数
# =====================================================================
return nn.Sequential(*layers), sorted(save)if name == 'main'
Python脚本入口点:使用argparse库来解析命令行参数,并设置了模型配置、设备选择、性能测试和所有yolo配置文件测试。
训练、验证和测试时候不是该入口点了,有相应的新的入口点。
python
# Python脚本入口点:使用argparse库来解析命令行参数,并设置了模型配置,设备选择,性能测试和所有yolo配置文件测试
if __name__ == '__main__':
# 新建ArgumentParser对象,用于处理命令行参数
parser = argparse.ArgumentParser()
# cfg:用于指定模型配置文件,默认值为yolov3.yaml
parser.add_argument('--cfg', type=str, default='yolov3.yaml', help='model.yaml')
# device:执行的设备cuda(单卡0或者多卡0,1,2,3)或者cpu
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# profile:用于启用模型速度分析
parser.add_argument('--profile', action='store_true', help='profile model speed')
# test:用于测试所有yolo配置文件
parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
# 解析命令行参数,并将结果存储在opt对象中
opt = parser.parse_args()
# 解析和检查参数文件(通常是YAML格式)
opt.cfg = check_yaml(opt.cfg)
# 打印参数信息
print_args(FILE.stem, opt)
# select_device获取设备信息
device = select_device(opt.device)
# 创建一个模型实例,将其移动到指定的设备
model = Model(opt.cfg).to(device)
# 模型设置为训练模式
model.train()
# 启用模型性能分析
if opt.profile:
# 创建一个随机生成的图像张量,准备将其传递给模型进行推理
img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
# 传递profile=True参数以启用性能分析,记录模型性能(速度)
y = model(img, profile=True)
# 测试所有yolo配置文件
if opt.test:
# 遍历指定目录中的所有符合特定模式的配置文件
for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
try:
# 使用这些配置文件来实例化模型
_ = Model(cfg)
except Exception as e:
# 发生异常则将打印出错误信息。
print(f'Error in {cfg}: {e}')调用了【utils/general.py】的check_yaml函数和【utils/torch_utils.py】的select_device函数。
总结
尽可能简单、详细的介绍了核心文件yolo.py文件的作用:根据yaml网络配置文件来搭建YOLOV3网络模型。