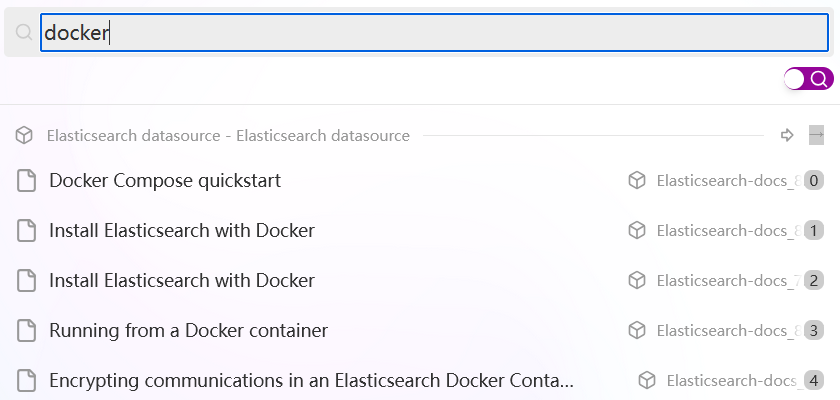
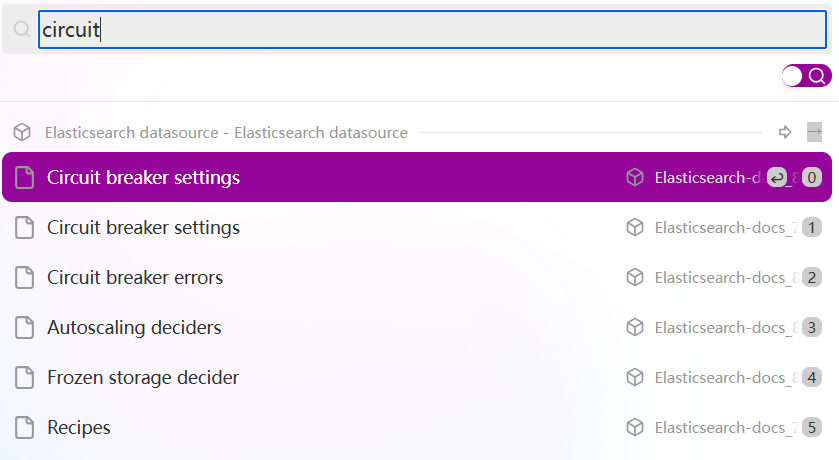
相信经常使用 Elasticsearch 的小伙伴,难免要到 ES 官网查找资料,文档内容多难以查找不说,还有很多个版本,加上各种生态工具如 Filebeat、Logstash 头就更大了。今天我来介绍如何使用 Coco AI 快速搜索 Elasticsearch 官方文档。在之前的文章中,我们介绍了如何将 MongoDB 数据摄入到Coco AI 中实现检索,感兴趣的小伙伴可以点这里查看。
在之前的文章中,我们介绍过通过爬虫程序爬取 Blog 数据写入 Easysearch 集群的方法,详情请戳这里。这次我们在原来的框架下,新建立一个 es-docs 爬虫,修改下原来的代码就行了。
建立新爬虫
cd infini_spiders/spiders
scrapy genspider es-docs www.elastic.co会创建新的 es-docs.py 文件。
Connector & Datasource
之前用 Coco AI 管理平台创建过 Connector 和 Datasource,这次我们直接放到爬虫程序中,通过 Easyearch 的 API 创建,不是 Coco AI 的 API 大家不要混淆了,以后有机会再介绍通过 Coco AI 的 API 创建。
程序开始,我们先检查 Easysearch 集群 coco_connector 索引中是否已经存在 doc_id 为 elasticsearch 的文档,如果不存在就创建相应的 Connector 和 Datasource。如果你之前通过管理平台创建了 elasticsearch 的 Connector 和 Datasource,就改下查询判断条件。
import scrapy
from pprint import pprint
from elasticsearch import Elasticsearch
import sys
def doc_exists(index, doc_id):
return es.exists(index=index, id=doc_id)
# 连接到Elasticsearch
with Elasticsearch("https://192.168.56.102:9200",
http_auth=('admin', '56939c1f6527d1a0d51c'),
use_ssl=True,
verify_certs=False,
ssl_show_warn=False) as es:
# 检查连接是否成功
if not es.ping():
print("Elasticsearch连接失败!")
sys.exit(1)
else:
print("Elasticsearch连接成功!")
# 示例:检查 ID=elasticsearch 的文档是否存在
if not (doc_exists("coco_connector", "elasticsearch")):
connector = {
'name': 'elasticsearch connector',
'category': 'website',
'icon': 'font_hugo-web'
}
pprint("创建 elasticsearch connector...")
response = es.create(index='coco_connector',
body=connector,
id='elasticsearch')
if response['result'] == 'created':
print("创建成功")
#pprint(response['_id'])
datasource = {
'name': 'elasticsearch datasource',
'id': 'elasticsearch',
'type': 'connector',
'connector': {
'id': 'elasticsearch',
},
'sync_enabled': False,
'enabled': True
}
pprint("创建 elasticsearch datasource...")
response = es.create(index='coco_datasource',
body=datasource,
id='elasticsearch')
if response['result'] == 'created':
print("创建成功")Elasticsearch Docs
创建完 Connector 和 Datasource 后,我们就可以去爬取 Elasticsearch 官方文档了。通过变量 version 定义要爬取的版本,从 start_url 开始,把所有的页面的文本都提取回来,形成 Coco AI 需要的格式,写入 Easysearch。
class EsDocsSpider(scrapy.Spider):
name = "es-docs"
allowed_domains = ["www.elastic.co"]
version = "7.10"
base_url = "https://www.elastic.co/guide/en/elasticsearch/reference/" + version + "/"
start_urls = [base_url + "index.html"]
tags = ["elastic-docs"]
type_ = "elastic docs"
category = "Elasticsearch-docs" + '_' + version
def parse(self, response):
chapter_links = response.css('span.chapter a::attr(href)').getall()
yield from response.follow_all(chapter_links, self.parse_blog)
section_links = response.css('span.section a::attr(href)').getall()
yield from response.follow_all(section_links, self.parse_blog)
part_links = response.css('span.part a::attr(href)').getall()
return response.follow_all(part_links, self.parse_blog)
def parse_blog(self, response):
title = response.css('h1.title::text').get()
url = response.url
all_text = response.css(
'h2::text,p:not([class]) ::text,li ::text').getall()
text = ' '.join(all_text)
content = text.replace('\n', '')
yield {
'title': title,
'tags': self.tags,
'url': url,
'type': self.type_,
'content': content,
'source': {
"type": "connector",
"name": "Elasticsearch datasource",
"id": "elasticsearch"
},
'category': self.category
}ScrapyElasticSearch
继续使用上次的插件把数据写入 Easysearch 集群。修改 scrapy 配置文件 settings.py
ELASTICSEARCH_SERVERS = ['http://192.168.56.102:8000']
ELASTICSEARCH_INDEX = 'coco_document'
# ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '56939c1f6527d1a0d51c'修改对应的连接信息和 INDEX 名称,这里我使用 INFINI Gateway 代理 Easysearch。
搜索数据
我已经爬取了 7.10 和 8.17 的官方文档。