Kafka命令行的使用
创建 topic
kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3
分区数量,副本数量,都是必须的。

数据的形式:
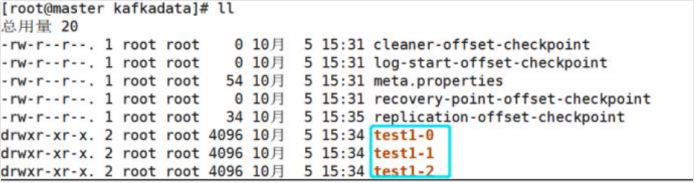
主题名称-分区编号。
在Kafka的数据目录下查看
设定副本数量,不能大于broker的数量。
查看所有的topic(list)
kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181

查看某个topic的详细信息(describe)
kafka-topics.sh --describe --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
删除topic(delete)
kafka-topics.sh --delete --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
生产数据
使用 Kafka 生产数据的命令
指定broker

指定topic

写数据的命令:
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test1
**注意:**写数据,实际上就是写log, 追加日志。
可在kafka的/root/kafkadata目录下查看分区中log。
每一条数据,只存在于当前主题的一个分区中,所有的副本中,都有数据。
消费数据
使用 Kafka 消费数据的命令
kafka-console-consumer.sh --topic test1 --bootstrap-server node01:9092,node02:9092,node03:9092
**注意:**此命令会从日志文件中的最后的位置开始消费。
如果想从头开始消费:

kafka-console-consumer.sh --topic test1 --bootstrap-server node01:9092,node02:9092,node03:9092 --from-beginning
会从头(earliest)开始读取数据。
读取数据时,分区间的数据是无序的,分区中的数据是有序。
如果想指定groupid,可以通过参数来指定:

kafka-console-consumer.sh --topic test1 --bootstrap-server node01:9092,node02:9092,node03:9092 --from-beginning --consumer-property group.id=123
一个topic中的数据,只能被一个groupId所属的consumer消费一次。(记录偏移量)
DStream创建
Kafka数据源:
DirectAPI:是由计算的 Executor 来主动消费 Kafka 的数据,速度由自身控制。
Kafka 0-10 Direct 模式
需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
导入依赖

编写代码


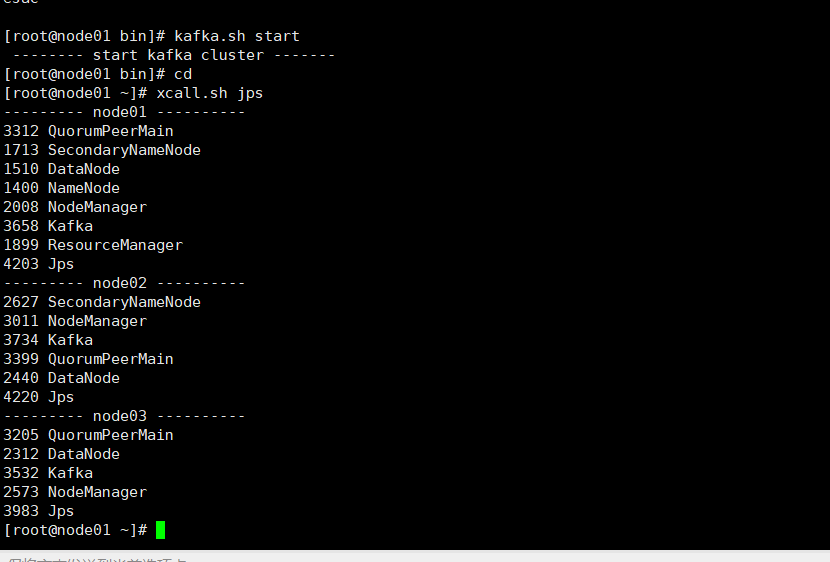
开启Kafka集群
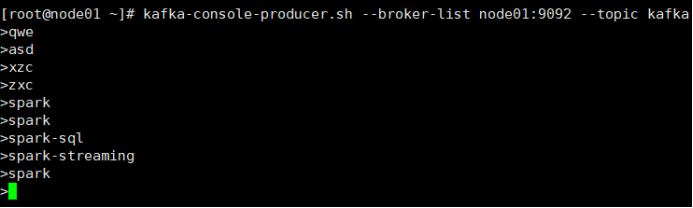
开启Kafka生产者,产生数据
最后运行程序,接收Kafka生产的数据并进行相应处理。