摘要:本文整理自京东物流高级数据开发工程师梁宝彬先生在 Flink Forward Asia 2024 论坛中的分享。内容主要为以下四个部分:
1、实时湖仓探索与建设
2、实时湖仓应用
3、问题与思考
4、未来展望
今天,将分享的主题大纲包括:首先,从京东物流的湖仓建设出发,探讨其整体思路与建设过程;其次,介绍京东物流实时湖仓的应用,以及实时团队在场景和业务支持方面的实践;第三,对遇到的问题进行思考;最后,讲解一下团队的下一步规划与未来展望。
01 实时湖仓探索与建设

接-下来,将深入探讨实时湖仓的探索与建设。这一页展示了京东物流下的具体业务场景,以及实时团队在京东物流实时业务中支持的业务场景。可以看到业务场景相当复杂,涵盖了整个物流行业中的常见业务。实时团队支持所有这些业务实时化的技术实现,包括一些未列出的,如销售服务业务和扩展业务,京东主站上的业务等。京东物流目前在国内运营的仓库数量已达到 1700 家,这些数据仅更新至 2022 年。预计到 2024 年,这一数字将增长至 2000 家。京东物流庞大的业务体系每天处理的厂商数据量也是巨大的。
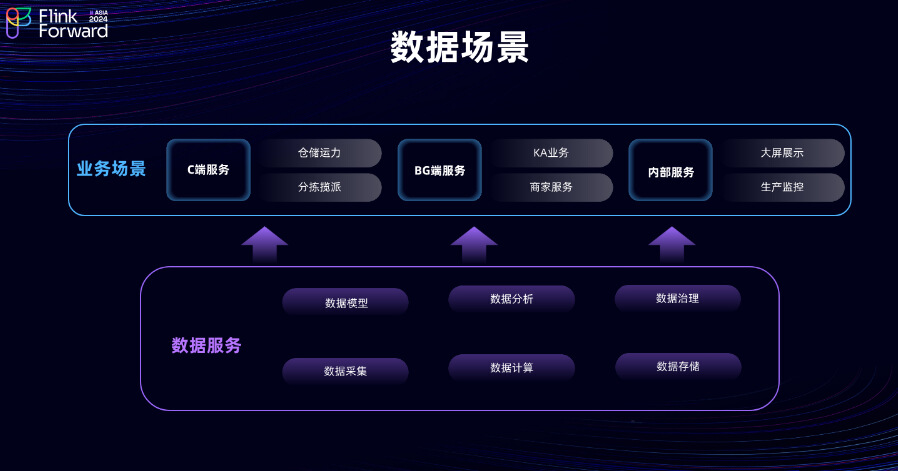
在这些业务场景下,实时团队提供的数据服务包括数据分析、计算和存储等这些业界常见的服务。不过,实时化的数据分析支持仍是一项重大挑战。这些业务场景涵盖了包括京东主站在内的 C 端业务,以及面向商家B 端服务和政府机关的 G 端服务,还有团队内部的数据分析服务,但主要压力来自于对内部服务的支持。
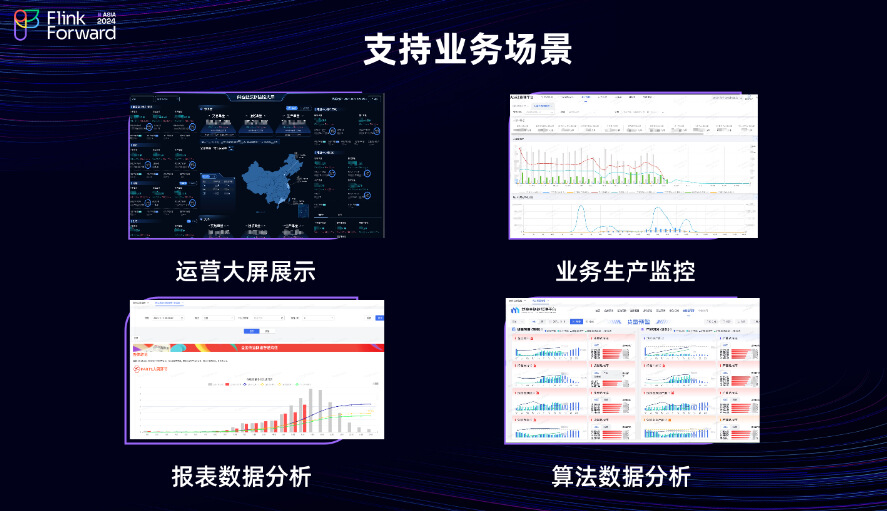
如图展示的是团队在实时场景中对内部业务的支持,例如运营大屏的展示,在双11 和 618 等大型促销活动中,这个场景最为常见,且对时效性的要求非常高。此外,业务生产监控、仓库货物上架和分拣、运输流程的时效监控等业务都需要进行实时分析和报表展示,这些业务对团队而言也颇具压力。因此,在面对复杂场景时,实时团队进行了类似于湖仓探索的实践。

基于当前业务规模的分析,实时团队目前的业务量概况:作业总数大约在 2700 +左右,资源量使用超过 10 万+CU,单个任务的最大状态量能够达到 15+TB,这也是团队面临压力较大的业务之一。它主要应用于路由和智能网络分析场景,这些场景下的业务分析计算规模十分庞大。
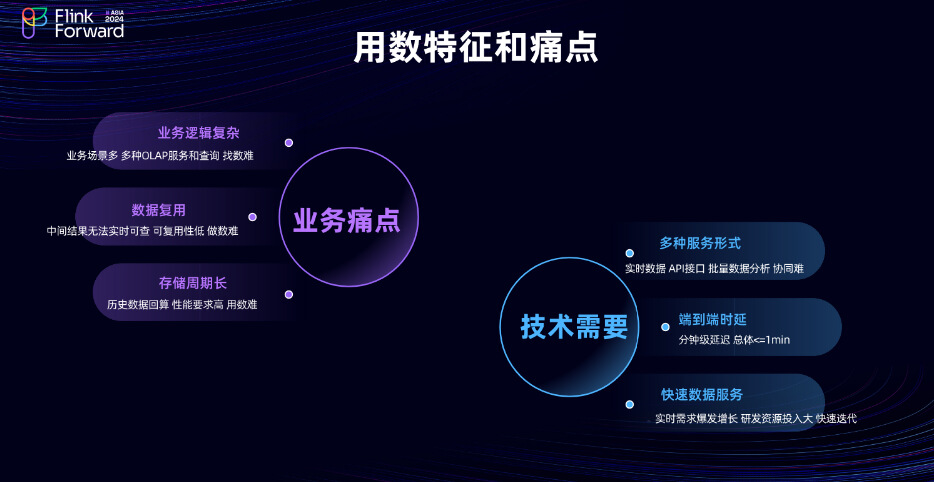
基于上述展示和业务分析,实时团队目前面临挑战和主要特征包括:
- 业务逻辑复杂性。例如,实时团队服务的客户众多,包括外部的 B 端和 C 端用户,分析场景也多种多样,如多维 OLAP 分析、大屏监控、生产监控、算法支持和业务分析等。在这些业务场景中,各种数据需求都需要准确找到所需数据。然而,京东物流数据量庞大,用户不清楚如何获取所需数据。
- 数据复用性挑战。目前实时团队使用的数据主要用于支持特定业务场景,但若要将其应用于其他业务场景,可能没有直接或便捷的途径来查找和复用数据。
- 存储周期长问题。因为物流场景特殊性的原因,数据存储周期可能较长,如简单的 B 端和 C 端业务单据可能需要存储至少30天的数据,而用于的数据分析的数据,可能需要存储长达一年或两年的周期。举例来说,在一般的物流场景中,数据存储可能仅需一到七天,商品就能完成从仓库到用户手中的整个路由过程。然而在一些特殊场景中,如之前业务介绍中提到的国际业务场景,或者在遇到不可控因素,如恶劣天气原因,商品可能会在某个站点、端点或分拣中心滞留的场景,监控数据面临存储周期更大的问题。
- 以上都是源自业务的痛点,目前还有业务技术上的实时技术挑战。实时数据用户期望以多种形式获得数据服务支持,例如实时数据 API 支持,用户可能不想通过任何界面,而是希望通过调用接口直接获取所需数据。例如,实时大屏需要实时刷新,批量数据分析可能需要调用接口获取数据,以满足特定业务的需求。此外,实时数据用户期望端到端的延迟小于一分钟,尤其是在双 11 大屏项目中,期望数据延迟能在在一分钟内,甚至达到秒级。通过内部调研,发现很少有系统能够达到这种分钟级别或秒级的数据刷新速度。因此,提供满足时效的实时数据服务确实是一个挑战。目前实时业务量庞大,面临的需求增长也是显著的。这导致团队在研发资源上的投入较大,成本显著上升。
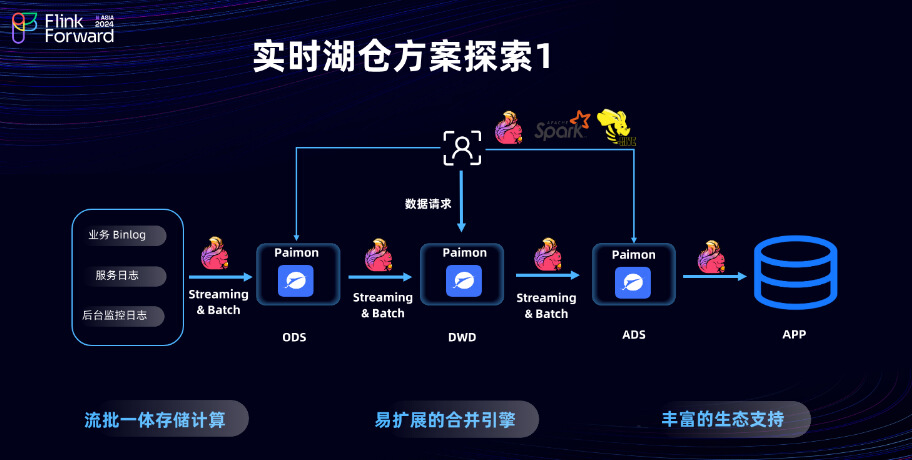
基于以上挑战,实时团队进行了一系列探索。首次尝试是通过结合 Flink 和 Paimon 的流式处理方案来解决上述问题。选择 Paimon 的原因在于实时湖仓的特性,例如流处理和批处理一体化的存储计算能力,以及其强大的扩展性和合并引擎。 Paimon 拥有丰富的生态系统支持,与 Flink、Spark 等技术的整合也做得相当出色。在Flink 社区也积极推广 Paimon 作为流式湖仓建设方案。基于这一方案,团队也开展了一些MVP(最小可行产品)的构建和探索。然而,在实施过程中,也遇到了一些挑战。
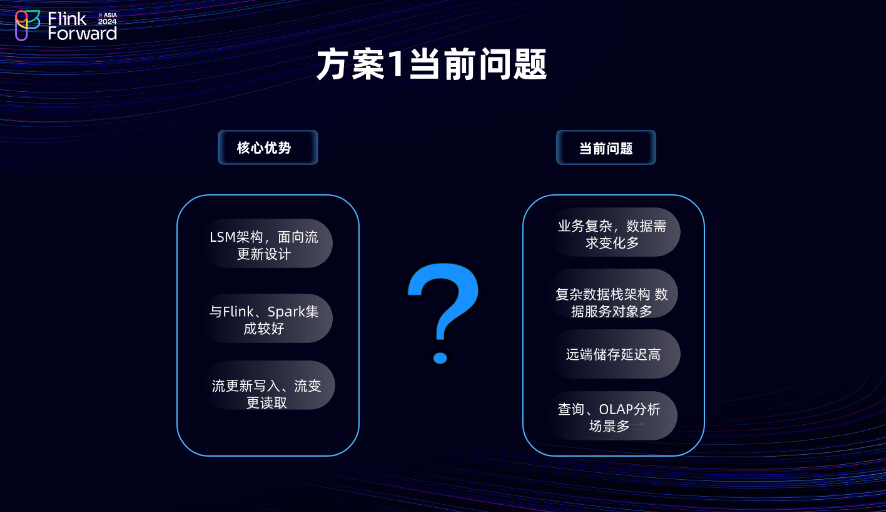
虽然 Paimon 流式湖仓建设方案具有很多优势,如友好的业务架构、面向流式设计的更新,以及强大的生态系统支持,其核心优势在于采用了 LSM(日志结构合并树)架构,面向流更新设计,使其能够较好地与 Flink、Spark 等大数据处理工具集成。这种设计提供了流更新写入和流读取的能力,优化了复杂数据架构中的数据服务对象。但是当这套方案应用于当前的业务场景时,问题就显现出来了。由于目前京东物流的业务比较复杂,业务复杂导致的多变数据需求、复杂数据架构、众多的数据服务对象、较高远端储存查询延迟和多样化 OLAP分析场景都带来非常大的挑战。这些问题使得数据管理和处理变得更加困难和低效。

因此,实时团队重新启动了第二个方案的探索,也就是目前团队正在实施的方案。我们对 StarRocks 的一些特性进行了调研,特别是 3.0 以上版本中推出的物化视图增强功能。此外,还研究了其存算分离的场景,这对于京东物流当前长周期数据存储的优化以及对业务查询的支持是非常有帮助的,可以为我们带来非常大的成本节约。这一点将在后面分析案例中重点探讨一下。StarRocks 的 Spilldown 过程对于数据优化查询的帮助也相当大。最重要的是,联邦查询的引入。联邦查询之所以重要,是因为在京东物流复杂的业务场景下,它能提供多样化的数据服务。例如,团队可以通过联邦查询快速迭代满足外部存储或业务方的数据构建需求。业务方的原始数据可能存储在 MySQL、Oracle 甚至其他非关系型数据库中,我们不可能迅速将这些数据进行实时化数据支持。联邦查询在在我们这里应用最广的是我们内部的 UData平台,它基于 StarRocks 的联邦查询功能,实现了数据平台化的数据服务,支持业务人员进行报表分析和业务分析。根据团队内部的统计,全国所有省份及地区的报表业务分析人员总数大约在万人级别,即大约有一万多人从事数据分析工作,包括站点分拣、仓库运营中心以及京东总部等大量运营人员,都是通过这种方式进行数据分析。
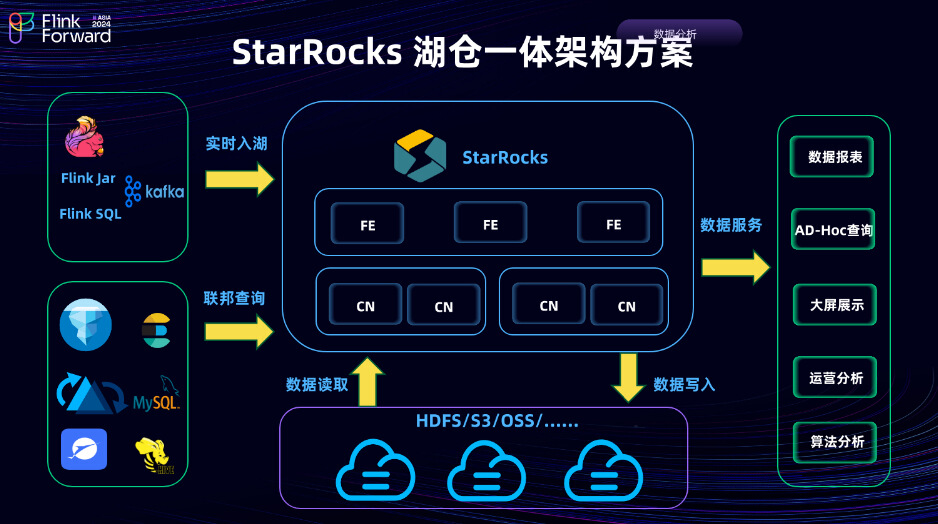
基于图中架构,我们探索了 StarRocks 湖仓一体建设的整体架构方案,通过 Flink 或 Kafka 的流式处理,数据实时写入到 StarRocks 中,实现数据的实时入湖。然后通过联邦查询进行外部数据链接,以满足业务方对快速数据模型构建和数据分析的需求。此外,我们还提供了基于当前建设的 Udata 平台的数据服务,像数据报表、AdHoc 查询、大屏展示、运营分析、算法分析等一站式服务,利用存算分离的方法,进行了StarRocks 云上部署,大幅降低了目前的存储成本,实现了可观的成本节约。

以上的展示就是我们从当前数据技术栈架构转到数据湖整体架构方案。它利用了基于Flink 实时计算服务的JRC平台(这是京东内部开发的实时数据平台)和基于 StarRocks 联邦查询构建的数据服务平台Udata。基于这两个服务平台,我们实现了基于 Flink & StarRocks 数据湖的建设方案。
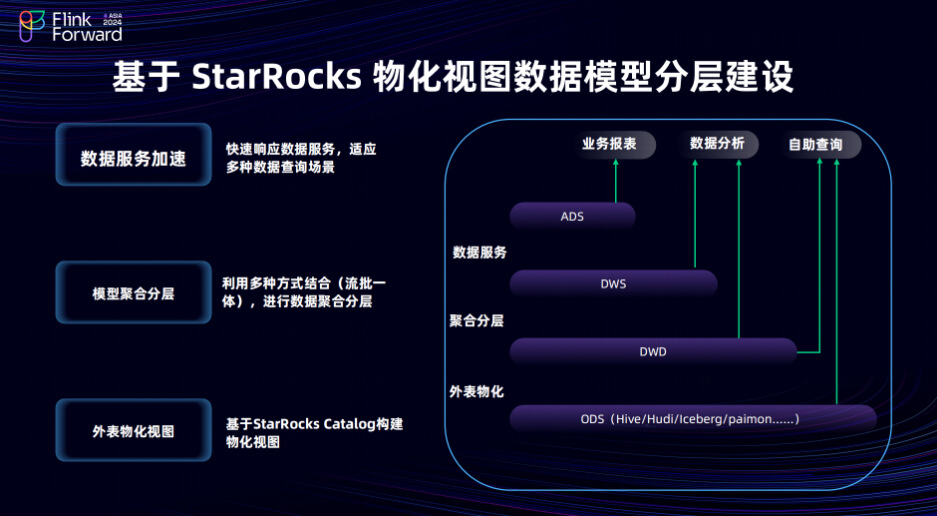
基于之前提到的架构,我们从 StarRocks 的物化视图基础出发,构建了一个分层架构设计,该设计基于 StarRocks Catalog 构建物化视图。分层建设主要分为外表物化、聚合服务和数据服务三层架构。数据服务层主要负责快速响应外部数据的查询需求,并适应多种数据分析场景。至于模型聚合分层下文也会简要分享如何实现模型聚合分层,以及如何实现分钟级的数据分层建设方案,这里使用多种方式结合,例如流批一体进行数据聚合、定时调度等方案设计。
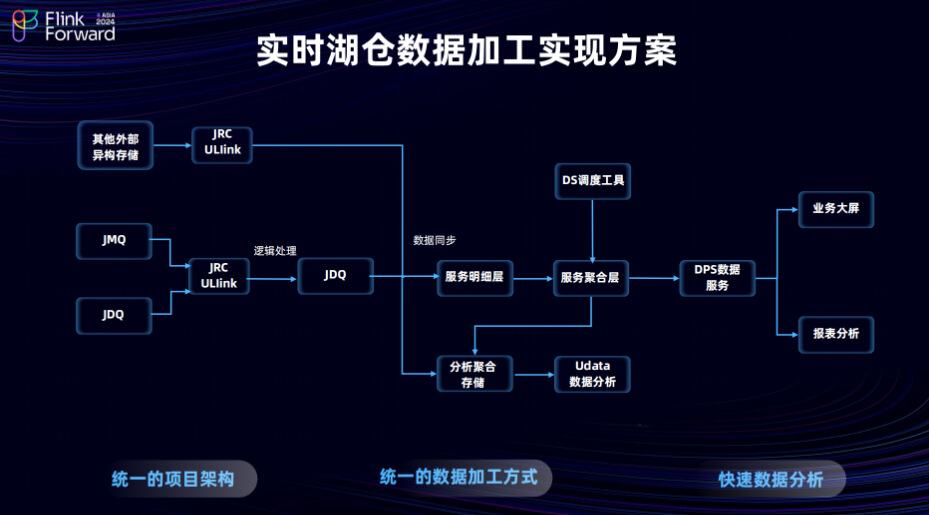
这里介绍一下整个数据加工以及分层建设的数据流程。从外部异构存储进入的数据,通过团队的 ULink 平台同步至明细服务层,或者通过 JRC 或 ULink,消费JDQ(Kafka)或 JMQ(RocketMq) 等实时数据流,进行维度扩展或逻辑加工。在进行宽表建设时,不得不提逻辑加工的重要性。京东物流业务场景的复杂性意味着宽表建设将涉及大量底层明细数据的加工,包括来自不同数据库、不同数据表、不同数据维度以及不同时间周期的数据。强调这一点因为在京东物流数据业务场景中,构建业务宽表不仅非常必要,而且充满挑战。在处理来自不同数据源的数据时,我们面临着实际操作中的多种困难。例如,从 JRC 任务到数据流的逻辑加工,再到数据同步,每一个环节都要求精确的逻辑处理。数据聚合层是我们实现分钟级别湖仓数据服务的核心,它不仅对外提供多维度的数据查询的服务,还支持京东物流业务大屏和报表分析的常态化场景。
通过数据聚合层,数据可以同步到外部的物化视图或分析聚合存储中,以支持 Udata 的数据分析过程。Udata 是面向全国近一万多数据分析人员的报表平台,其底层数据主要来源于我们的分析聚合层。通过支持业务的长期数据分析,我们逐步完善了京东物流实时湖仓数据的实现方案。这一方案具备统一的项目架构,从数据源头到中间存储层,再到业务支持层,以及对外的数据分析平台支持,都采用了统一的架构和数据加工方式,实现了快速的数据分析。正如之前所述,若采用传统方案,团队在进行数据支持时,尤其是使用 Paimon 数据库存储方式,将无法实现数据服务的快速响应和高效开发。采用基于当前的实时湖仓的存储方案,才能同时满足业务大屏和内部报表分析的需求。未来我们将逐步向 B 端客户和政府部门开放数据分析功能,包括帮助优化仓库库存管理数据分析,解决当前数据分析场景中的弊端。
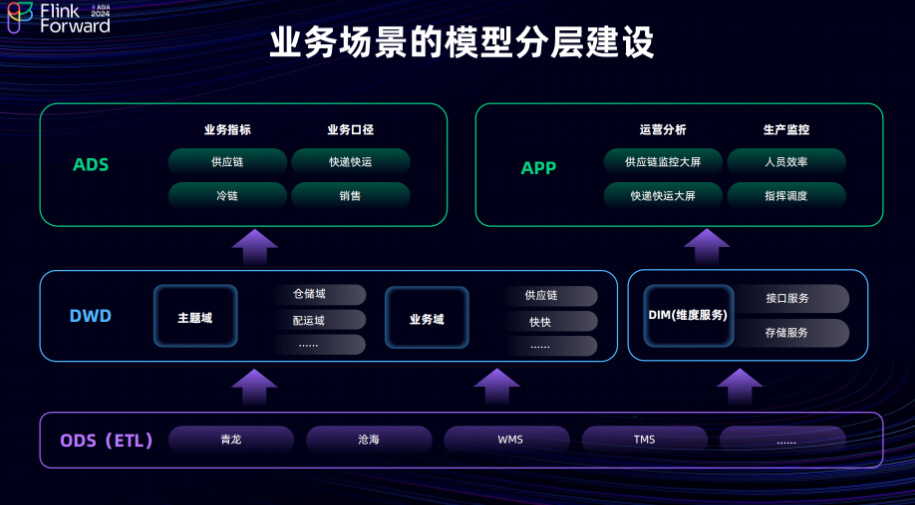
当前京东物流基于整体业务场景的模型分层建设如上所示。基于 JRC平台的 DTS 服务,我们从物流生产系统中抽取数据同步到数据摄入层 ODS 层,再经过维度扩展将数据加工至数据明细层 DWD 层,然后基于数据明细层进行数据汇总层ADS层和数据应用层APP层建设。DWD 层包括仓储配送域在内主题域数据,而 ADS层和APP层包括对应的业务域数据,如供应链、快递快运服务、金融服务,以及对外的主站服务数据等。实时数据团队还提供了基于京东物流全场景的主数据的维度服务,主要是通过 API 接口提供维度扩展服务,而维度服务底层存储主要使用 HBase。API 接口服务主要响应实时数据场景中的快速数据流维度扩展请求。目前京东物流实时数据场景基本上是基于 Flink API 和 Kafka 进行开发的, 虽然 Flink SQL 也能支持部分业务场景,但在面对团队复杂的业务流程时,Flink SQL 可能在状态处理和中间逻辑处理方面不够友好。因此,在京东物流中,80%以上的数据处理都是通过 Flink API 完成的。
02 实时湖仓应用
接下来,将分享京东物流目前主要的实时湖仓应用案例。首先,以商家云配数据监控业务为例,介绍在实施湖仓架构前的数据应用架构。
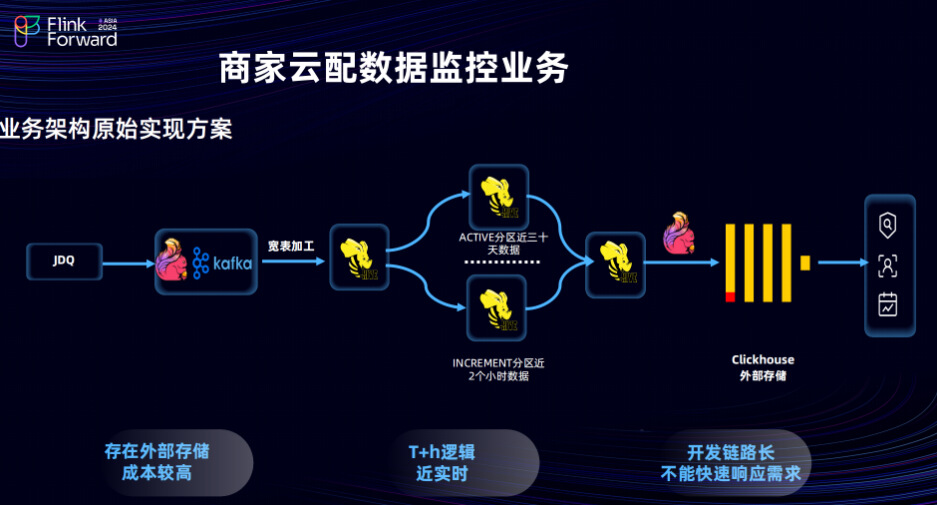
在这个架构中,通过将消息流数据写入 Kafka 中,并通过 Flink API 进行多表关联和维度拓展,加工成宽表。加工后的宽表会同步到 Hive 中。Hive 表会进行分区处理,其中活跃分区ACTIVE分区存储近 30 天的最新有效数据,增量分区INCREMENT分区存储最近两小时的数据。通过 Flink SQL 批任务将两个数据分区合并,形成去重后的业务宽表,并将其写入外部存储系统 Clickhouse 中。Clickhouse 面向商家或业务人员提供数据分析服务。在未采用 Flink & StarRocks 的实时湖仓场景下,这种流批架构存在许多弊端。例如,外部存储成本较高,尤其是 Clickhouse 这类存储系统,其存储成本和系统消耗都相对较大。此外,这种流批架构尽管实现了近实时逻辑,即存储了近 30 天的数据和近两小时的增量数据,并进行了排序、去重合并处理后形成最终的宽表供外部使用,但这种时效性并不能满足当前用户高时效的要求,用户希望能够提供分钟级的数据分析,以便进行库存数据报表处理和当前业务状态快速回刷。因此,我们对当前数据架构进行了改造。
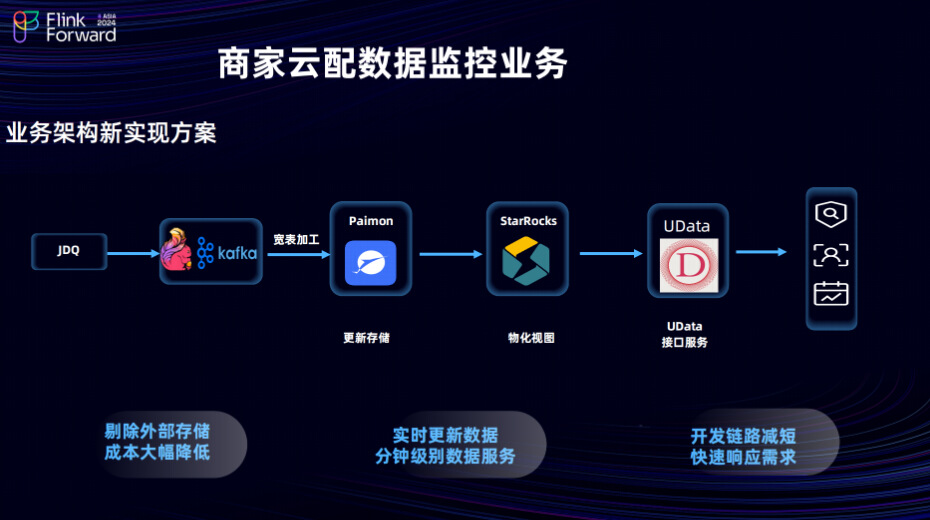
一开始,我们利用 Paimon 存储和 StarRocks 的物化视图替换了上图中间部分,并利用Udata平台以接口服务的形式将数据提供给外部用户。经过这样的架构升级,我们不再需要将部分数据推送给外部存储,而是直接调用数据接口,进行数据查询和报表展示。外部商家的开发人员可以调用接口,直接访问我们底层存储的数据。这不仅缩短了数据加工的链路,也大幅降低了数据服务的开发成本,缩短了开发迭代周期,快速响应需求。这种模式的优势在于能够以天为单位的响应速度甚至更快地满足数据需求,能够及时对接外部服务。
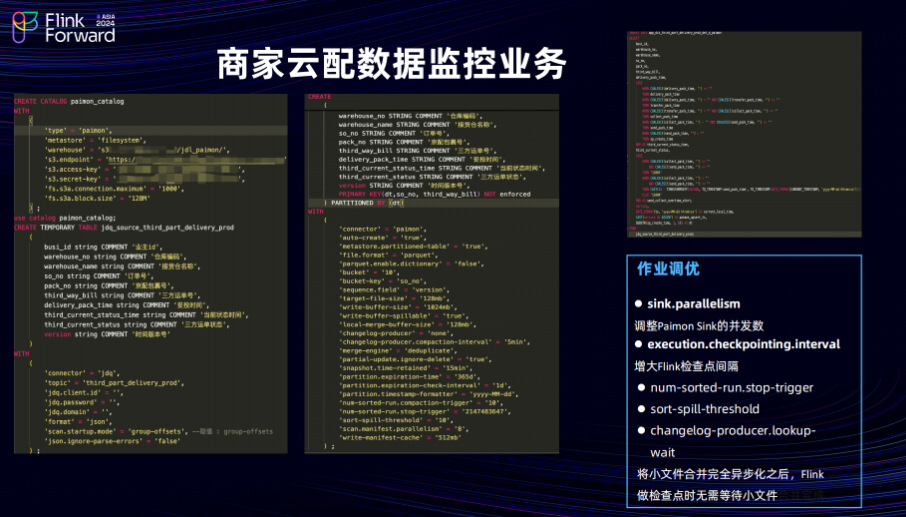
基于目前改进的架构,团队进行了旧有任务的架构升级,使得 80%的任务能够通过 API 提供对外的数据服务。不过,对于一些例如数据同步、批量处理以及一些简化的双流关联的场景,仍然通过 Flink SQL 来实现业务逻辑。在商家云配数据监控业务中,完成宽表加工后将数据同步至已构建好的 Paimon 的主键表,并在 Udata平台构建这张外 Paimon 表的外表,通过 UData 数据 API 的能力对外提供服务。在开发流程中,遇到一些问题,比如在使用 Flink 同步 Paimon 时,需要调整 Checkpoint 的设定,处理 Paimon 小文件的合并时机的合理性,以及将 Paimon 小文件合并异步化的过程等。解决小文件异步合并过程中遇到过一个问题,在执行检查点时,如果小文件过多,可能会导致底层合并或查询操作的延迟很大,甚至产生长尾效应,对 Flink 任务产生反压。在与 Paimon 社区讨论过后,在这方面,Paimon 也会进行后续优化,预计在 1.0 版本中会有大的改善。
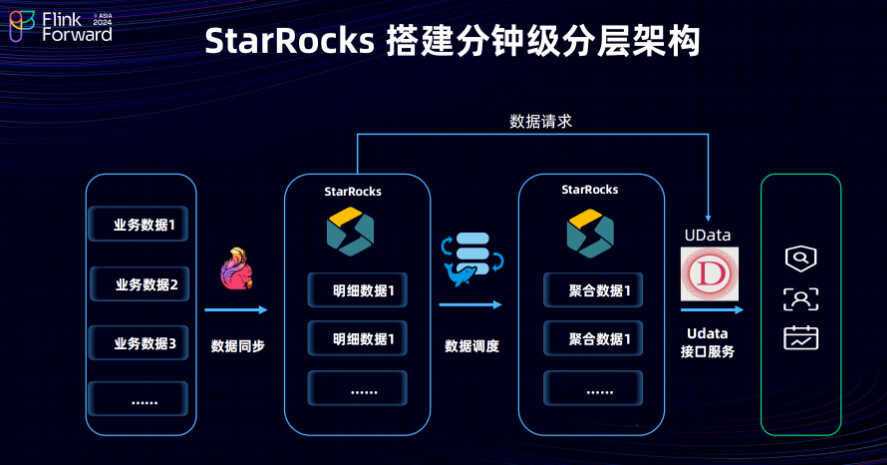
第二个方案是我们基于 StarRocks 搭建分钟级的湖仓分层架构。上游业务数据通过 DTS 工具同步到我们数据服务对应的的 StarRocks 表中,通过数据调度平台生成对应的聚合数据,也就是聚合数据表或者物化视图表,再通过Udata平台对外提供数据服务。这样的架构的特点是既可以保留中间明细数据,也可以保留中间的聚合数据。在这种情况下,用户既可以查询聚合数据的结果,也可以验证聚合数据的准确性,同时还可以查询明细数据。在计算和分析的数据时,用户可以直接在业务逻辑上进行数据的准确性或数据同步的时效性的验证。此外在数据同步过程中,既可以进行宽表维度的扩展,也可以进行单表同步。基于 StarRocks 的 partial update功能,可以在 StarRocks 中进行明细宽表的扩展,这样就有了既可以使用 Flink API 进行也可以使用 StarRocks 进行宽表扩展的两种场景。在数据流量较大的场景中,通常会采用 Flink API 进行特定的逻辑处理实现宽表加工。对于数据量较小的表,例如之前提到的销售服务,或是京东主站平台提供的服务,以及类似上门维修这样的服务,可以通过调度平台使用StarRocks实现数据聚合和数据宽表的构建。

这种架构允许为外部商家和用户提供分钟级的数据分析服务,并且数据能够迅速入库,重点任务也能快速备份,提供了分钟级的数据聚合服务和低延迟的数据响应,支持明细查询和汇总查询。

举一个利用StarRocks实现宽表加工、聚合查询的例子。当前案例有订单表、出库表、运输表以及订单状态表,利用DTS实时进行数据的更新存储。由于这些表的数据量较小,非常适合使用 StarRocks行更新方式写入数据库,实现分钟级的快速表宽化。通过结合团队调度平台,能够实现分钟级甚至秒级的数据聚合服务。

接下来,将分享 StarRocks 在京东物流业务场景下存算分离的应用实目前,我们使用的 StarRocks 实时组件能够满足大部分用户在七天到 15 天内的数据需求,占比达到大约 80%到 70%。然而,仍有一部分用户需要频繁访问存储周期长达半年甚至一年的历史数据,以进行数据统计和数据分析。正如之前提到的,在京东物流业务场景下拥有超过一万名数据分析人员,他利用物流业务场景的数据进行分析,持续优化物流服务,并且他们对历史数据有强烈诉求,希望快速进行当前数据和历史数据的数据分析,这一点离线数据分析不能达到他们的要求。其中,京东物流使用最广泛是路由数据,这些数据访问量最大,对物流时效数据分析帮助非常大。为了便于既能快速数据分析又能查询较久以前的历史数据,我们采用了存算分离的措施进行数据存储。访问频次较高的数据即热数据,我们缓存在本地磁盘,而访问频次较低的数据即冷数据,我们存在云端。底层存储方面,我们直接选用京东云的 OSS,即对象存储,它支持标准的 S3 协议,这大大降低了团队的存储成本。

我们在存算分离集群上,创建了长周期存储的实时表,和存算一体的集群不同的点在于,我们可以进行分钟级的长周期表更新,更新量非常大,往往需要横跨多个分区。因此,团队必须对主键进行持久化的存储,并建议将主键索引存储到本地盘中。
在存算分离的场景下,由于 OSS 已经采取了多副本策略,指定额外的副本数量是不必要的。但是,在使用云存储时,必须指定存储卷,例如在京东云上指定 Bucket 的数量或存储卷。
此外,应避免自动创建存储卷,而应选择手动创建,以防止认证问题和数据交互中可能出现的 Bug。重要的是,应确保开启数据缓存功能。如果启用了数据缓存,存放分离场景下的数据查询效率与团队存算一体集群的效率在参数优化合理的情况下,基本上是相当的。
03 问题与思考
关于存算分离场景的一些思考和问题总结,在存算分离的场景中,我们可以进行一些优化。

首先对内存、系统设置以及全局变量的配置要设置合理,主要是为了保障存储集群的稳定性,避免无限制的查询导致缓存污染和系统崩溃。写入数据时,首先写入的是 CN 节点的本地盘存储,然后刷新到对象存储中。如果刷新频率设置得太频繁,可能会导致系统崩溃或缓存污染。因为在大批量数据更新对存算分离的压力比较大,所以会采取慢查询快速失败的策略。此外,为了防止磁盘空间耗尽,磁盘要进行空间预留,这些都是类似于经验总结的设置。

在存算分离的场景下,Flink 的数据同步也是常见的。在Flink集群设置上,通常会设置每次 Flush 的最大数量大约为 1GB,最大行数大约为百万级别,每次Flush最大的时间间隔大约为几分钟,比如 5 分钟。再有,对于写入存储的任务控制,由于对象存储擅长大批量低频次的吞吐,所以应尽量攒批要更大,比如每次大约 1GB 的数据量,Flush时间间隔应设置得长一些,比如设定的间隔大约为 3 到 5 分钟,或者稍微再长一些。在数据量和刷新间隔的设置上,需要参考经验值。此外,建议FE上配置批量的 publish version,我们基于现有的开源 3.0版本,会做一些批量的 Publish Version 设置,以减少 Meta 的数量。

最后,关于存算分离的 Compaction 和 Vacuum 的设置,这个也需要着重考虑。因为在数据写入过程中,会产生不同的历史版本,对于这些历史版本的 Compaction 处理,主要采取的措施是基于当前的存储类型采用垂直的 Compaction 策略进行数据的压缩操作,以防止数据膨胀。不过 Vacuum 操作过于频繁,可能会错误地删除数据,这将导致查询失败或数据缺失,从而影响用户体验和时效性。
04 未来展望

对于我们数据服务的未来展望,我们计划通过 StarRocks 替代现有的离线数据存储,并构建原生数据湖。在分析场景中,还计划推广数据长周期存储服务,快速实现历史数据分析,解决当前在长周期数据存储中可能面临数据时效问题。我们将把长周期数据存储服务推广到不仅仅是路由数据场景,还包括其他如智慧网数据、快递数据以及仓储数据的存储,以提供更多的分析场景,将探索聚合数据层搭配 Cache,以实现存算一体的性能体验。
以上就是本次的分享,谢谢大家。