一般我们手机中常用的ocr库有,Tesseract,paddle ocr,EasyOCR, ocrLite等等,这些ocr库中百度的paddle ocr效果最好,但是再好的效果也会偶尔识别错几个汉字。当我们在做自动化脚本过程中,如果识别错的汉字刚好是我们要"抓"的汉字就尴尬了,我们的自动化脚本就会出错,到不到预期效果。今天给大家介绍一种免费的,带增量学习的汉字识别率接近100%的ocr,可以大大提升自动化脚本的正确率。
一、准备开发环境
不需要安装任何软件,所有一切都在浏览器上完成, 详细请见文档说明,新建脚本,编写一段简单的ocr代码如下代码:
javascript
function main() {
var r = ocr();
console.log('r', r);
}二、开启awesome功能
如果上述代码识别的汉字有个别不对,我们可以开启awesome功能,开启后系统会更给出更精确的识别结果,代价就是会多话费0.5秒左右,不同的手机时间会略有不同。
javascript
function main() {
var r = ocr({awesome:{threshold: 0.9, count: 3}});
console.log('r', r);
}threshold为阈值,一般取之范围为0.5-0.9之间,count取值范围为2-6,一般取0.9和3就够用了。
三、增量学习
如果开启awesome后还是有个别汉字识别出错,则我们可以使用增量学习,把正确的文本添加到ocr文本库中,在线训练模型,模型训练成功后,打包进冰狐apk,就可以正确识别所有汉字了。
例子:正确句子:冰狐智能辅助,识别错误句子:冰弧智能辅助。
1.我们可以将正确的句子"冰狐智能辅助"添加到ocr文本库中,进行增量学习,如下图所示:
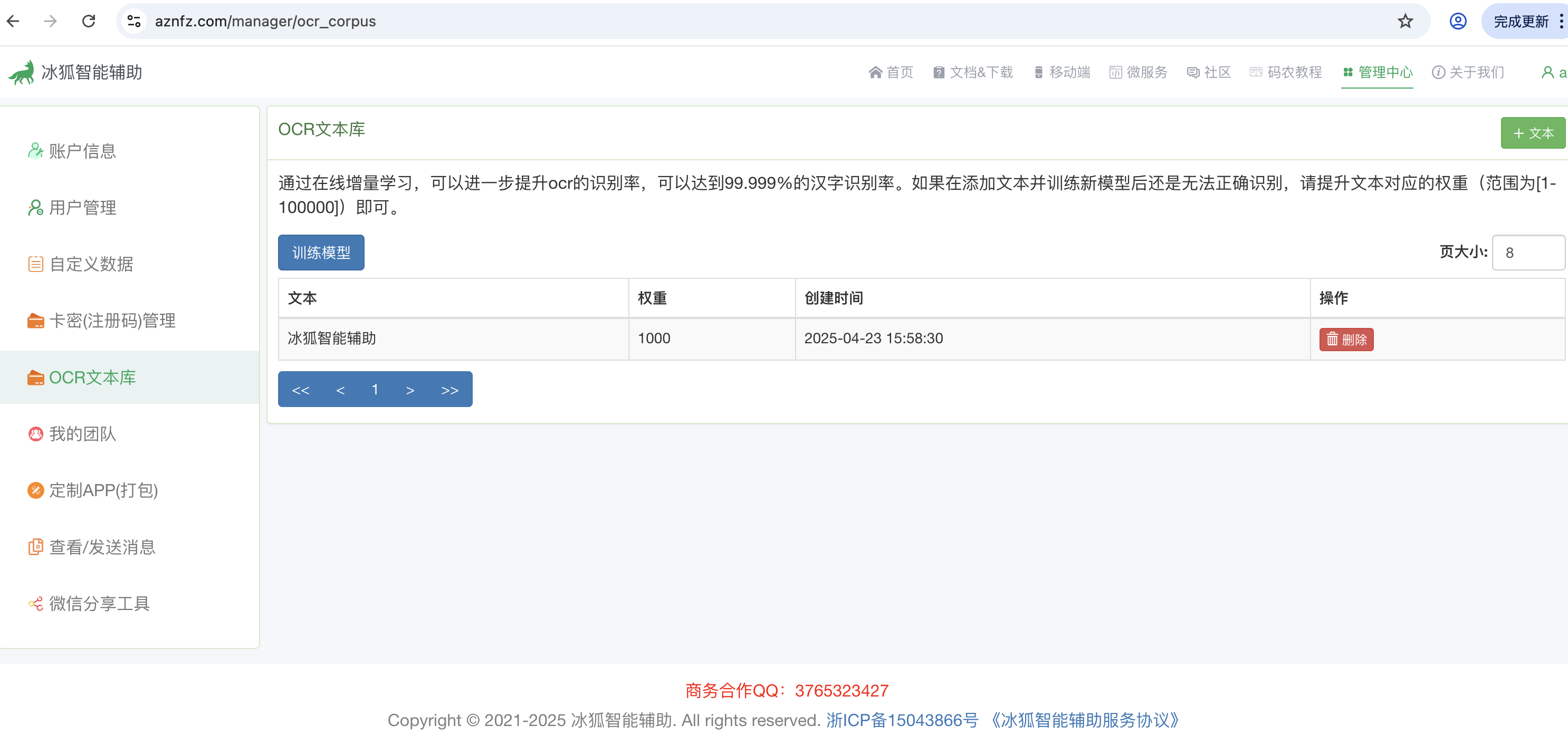
2.然后点击训练模型,根据文本多少,一般几秒中会训练完成,完成后会弹出下载模型连接,如下图所示:
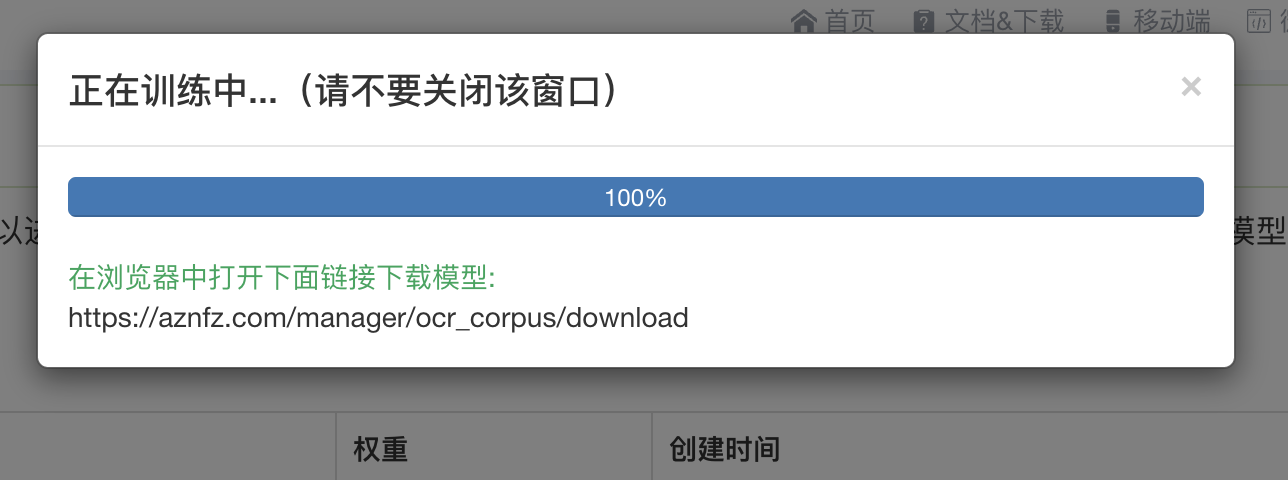
3.将下载下来的model.bin文件打包进冰狐apk中
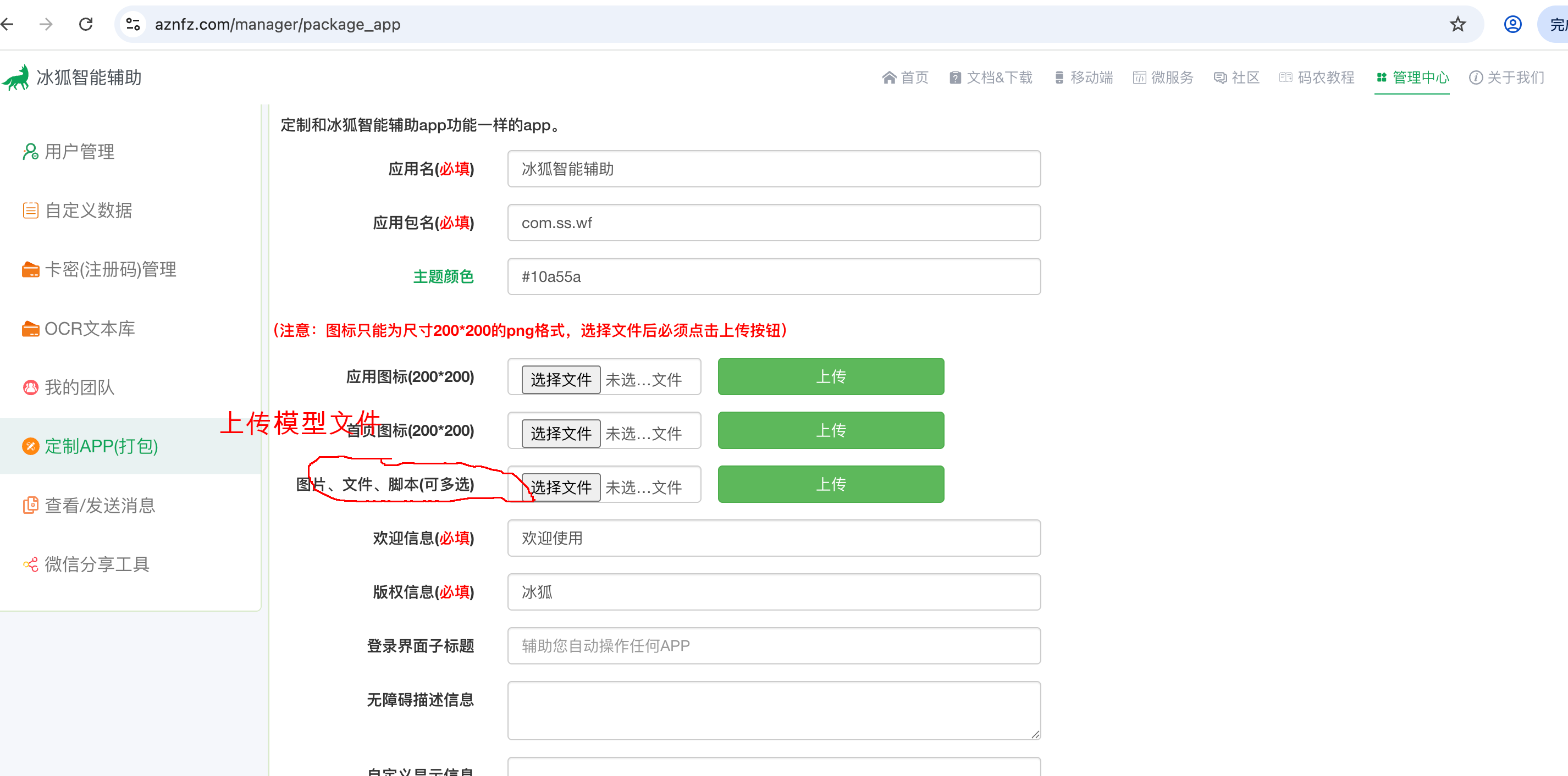
在红色圈圈的地方上传刚才下载model.bin文件,并点击上传。然后确认打包,打包后,可以直接下载apk,此时新的模型就在apk中了,安装新版本apk,即可实现100%汉字识别。
四、调优
如果增量学习后还是无法识别,请按如下方法调试:
- 请增加权重值,再次学习
- 将count值调大,最大到6
- 将threshold值调小
通过以上几步可以实现100%汉字识别率
五、总结
本文介绍了一种免费的、离线的可以实现100%汉字识别率的带增量学习的ocr,比市面上已知的任何ocr效果都要好,关键还是免费,识别时间一般在1秒左右,非常适合在手机中使用ocr实现自动化脚本的场景。