提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、查询连接
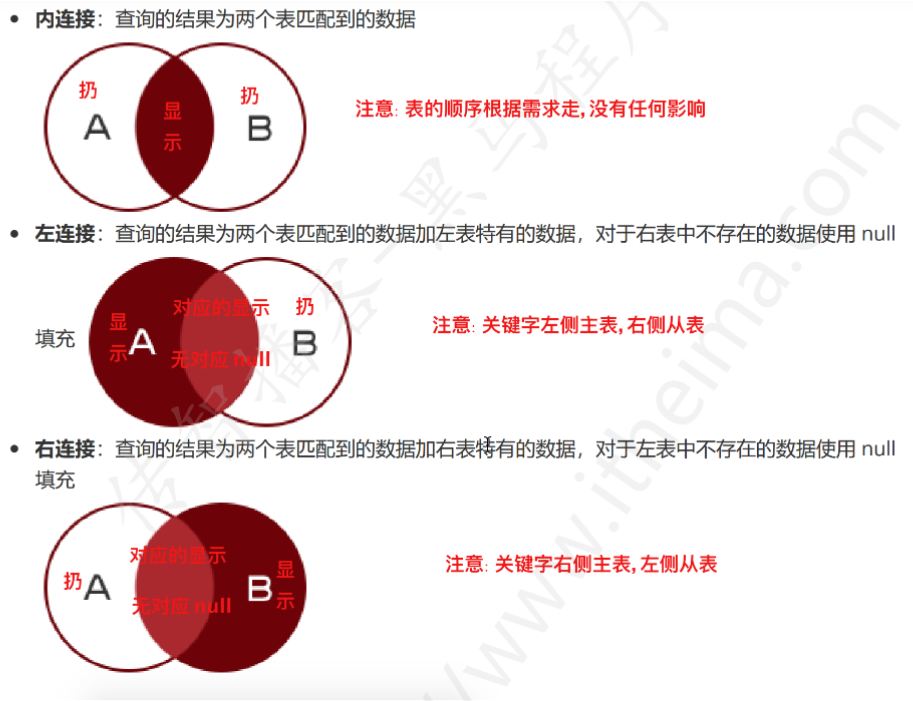
1.内连接
-- 需求1: 查询所有存在商品分类的商品信息
select * from goods;
select * from category;
-- 内连接: select * from 表1 inner join 表2 on 表1.列=表2.列
-- 显示效果: 两张表中有对应关系的数据都会显示出来, 没有对应关系的数据
均不再显示
select * from goods
inner join category on goods.typeId=category.typeId;
-- 扩充: 给表起别名(1> 缩短表名利于编写 2> 用别名给表创建副本)
select * from goods go
inner join category ca on go.typeId=ca.typeId;
-- 扩展: 内连接的另一种写法(旧式写法)
-- select * from 表1, 表2 where 表1.字段名=表2.字段名;
select * from goods, category where
goods.typeId=category.typeId;
2.左连接
-- 需求2: 查询所有商品信息,包含商品分类
-- 左连接: select * from 表1 left join 表2 on 表1.列=表2.列
-- 注意: 如果要保证一张数据表的全部数据都存在, 则一定不能选择内连接,
可以选择左连接或右连接
-- 说明:
-- 以 left join 关键字为界, 关键字左侧表为主表(都显示), 而关键字右侧的表为从表(对应内容显示, 不对应为 null)
select * from goods go
left join category ca on go.typeId=ca.typeId;
-- 扩充需求: 以分类为主展示所有内容(以哪张表为主表, 显示结果上是有区别
的!)
select * from category ca
left join goods go on ca.typeId=go.typeId;
3.右连接
-- 需求3: 查询所有商品分类及其对应的商品的信息
-- 右连接: select * from 表1 right join 表2 on 表1.列=表2.列
-- 说明:
-- 以 right join 关键字为界, 关键字右侧表为主表(都显示), 而关键字左侧的表为从表(对应内容显示, 不对应为 null)
select * from goods go
right join category ca on go.typeId=ca.typeId;
-- 扩充需求: 查询所有商品信息及其对应分类信息
select * from category ca
right join goods go on ca.typeId=go.typeId;
4.左右连接的必要性
- 说明: 能够体现左右连接必要性的场景为: 至少为三张表进行连接查询
- 注意: 实际工作中, 最多也就三张表连接查询
5.自关联
- 前提: 1> 数据表只有一张 2> 数据表中至少有两个字段之间有某种联系
- 方式: 通过给表起别名的形式, 将原本只有一张的数据表变为两张, 然后通过对应字段实现连接查
6.普通查询
-- 需求4: 查询河南省所有的市
-- 说明: 无论是使用内连接还是左连接, 都只影响中间数据表的内容多少, 由于最终的过滤条件相同, 因此查询结果一致
-- 使用内连接
select * from areas a1
inner join areas a2 on a1.aid=a2.pid
where a1.atitle='河南省';
-- 使用左连接
select * from areas a1
left join areas a2 on a1.aid=a2.pid
where a1.atitle='河南省';
7.子查询
- 子查询: 在一个 select 语句句中,嵌入了另外一个 select 语句,那么嵌入的select 语句称之为子查询语句
作用: 子查询是辅助主查询的,要么充当条件,要么充当数据源
8.子查询充当数据源
-- 需求7: 查询所有来自并夕夕的商品信息, 包含商品分类
-- 子查询语句充当数据源:
-- select * from goods go
-- left join category ca on go.typeId=ca.typeId;
-- select * from (select * from goods go left join category ca
on go.typeId=ca.typeId) new
-- where new.company='并夕夕';
-- 问题: 连接查询的结果中, 表和表之间的字段名不能出现重复, 否则无法直接使用
-- 解决: 将重复字段使用别名加以区分(表名.* : 当前表的所有字段)
select * from (select go.*, ca.id cid, ca.typeId ctid,
ca.cateName from goods go left join category ca on
go.typeId=ca.typeId) new
where new.company='并夕夕';
二、数据库高级扩展内容
- E 表示 entry,实体: 描述具有相同特征事物的抽象数据表
- 属性: 每个实体的具有的各种特征称为属性数据(表内的字段)
- R 表示 relationship,联系: 实体之间存在各种关系,关系的类型包括包括一对一、一对多、多对
多表和表之间的联系
1.外键
- 说明: 通过外部数据表的字段, 来控制当前数据表的数据内容变更, 以避免单方面移除数据, 导致关联表数据产生垃圾数据的一种方法
- 注意: 如果大量增加外键设置, 会严重影响除数据查询操作以外的其他操作(增/删/改)的操作效率, 因此在实际项目中很少会被采用, 但是在面试中容易被问到.
2.索引
- 说明: 可以大幅度提高查询语句的执行效率
- 注意: 如果⼤大量量增加索引设置, 会严重影响除数据查询操作以外的其他操作(增/删/改)的操作效率, 不方便过多添加.
3.验证索引效果案例实现步骤
-- 开启运行时间监测
set profiling=1;
-- 查找第一万条数据 10000
select * from test_index where num='10000';
-- 查看执行的时间
show profiles;
-- 为表 text_index 的 num 列创建索引
create index test_index on test_index(num);
-- 执行查询语句
select * from test_index where num='10000';
-- 再次查看执行的时间
show profiles;